






MHA的基础:SDPA
上面的MHA是Multi Head Attention的缩写,即多头注意力机制,SDPA是Scale Dot Product Attention的缩写,即缩放点积注意力
SDPA干了什么
涉及一些关于MHA的部分在这里先列清楚:
首先MHA接收到的张量形状是(batch_size, seq_len, embedding_dim),MHA会对这个张量进行分头行动,进行一步split的操作,之后的张量形状是(batch_size, head, seq_len, embedding_dim // head),我们这里将embedding_dim // head简化成splited_dim,这里分头行动的是embedding_dim,将上述形状简写成(batch_size, head, seq_len, splited_dim),这个就是SDPA的输入形状.
接下来我们看到SDAP的公式
其中的D取自qkv矩阵里的splited_dim
其中的形状变化如下图所示
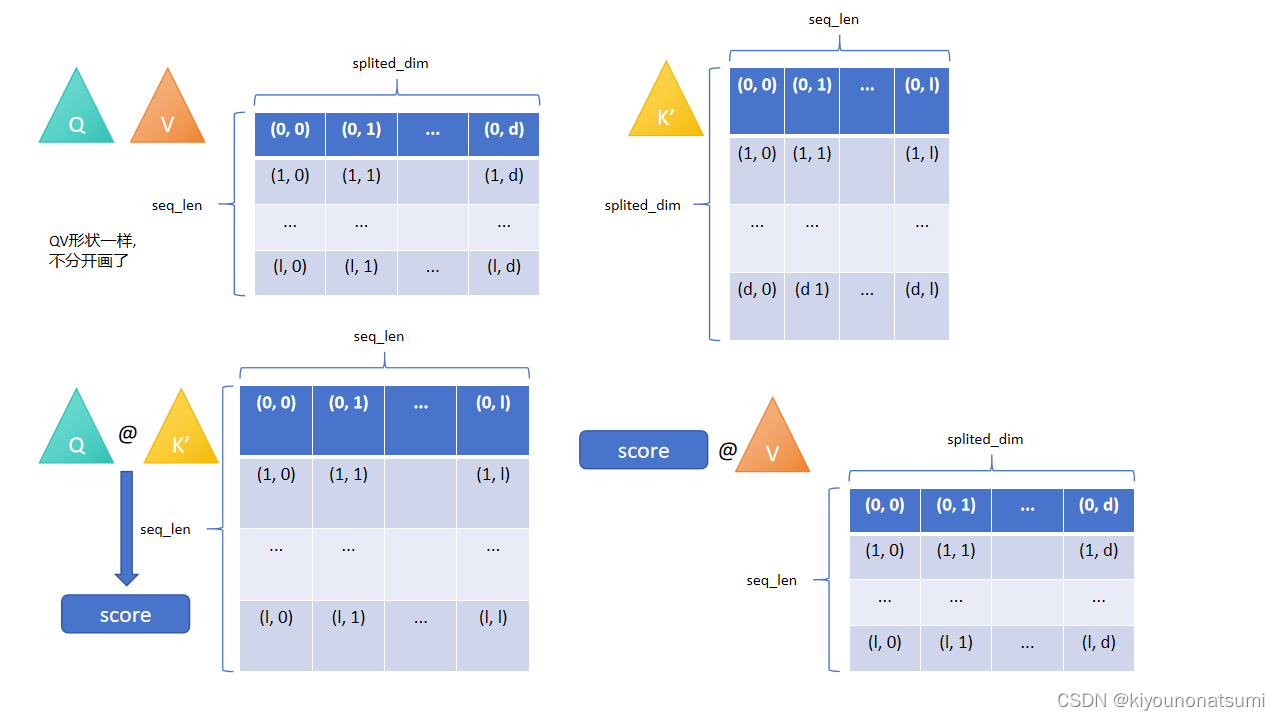
SDPA的含义
我们着重看score的得出,因为score才是这个ATT存在的意义
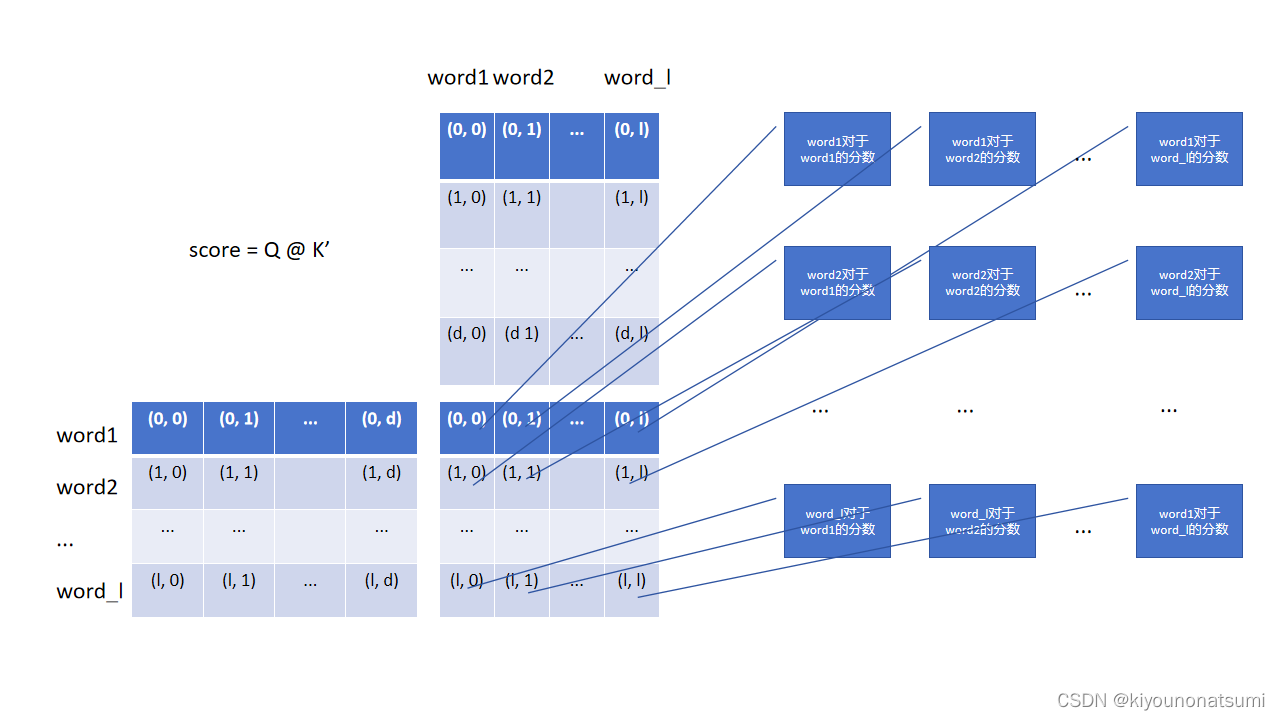
可以看到,score的计算方式是每个单词对于其余所有单词(包括这个单词自己)的点积.
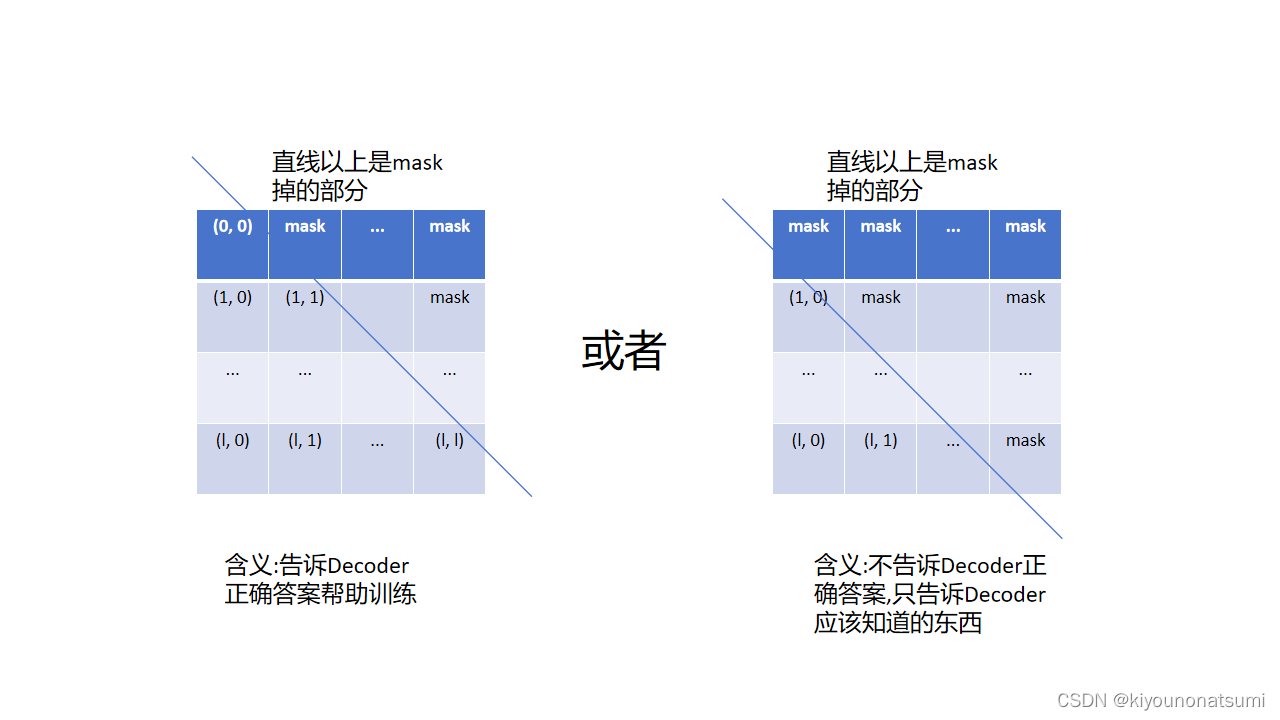
SDPA里的mask操作
后续要进行的mask操作就是对score的操作,比如在Decoder的时候score第一行的单词1能看到的理应只有它自己,或者什么都看不到,第二行的单词2理应只能看到它自己及其以前的单词,或者只有他以前单词.即计算分数的时候我们要手动遮挡住一些不应该被看到的单词.这种遮挡方式被称为上三角mask.后话:训练的时候采用并行训练时要对Decoder的self-att进行mask操作,使得Decoder的输出就是完整的翻译完的句子,后面会详细地描述这一过程.
遮挡后的score矩阵如下图所示,一般采用右边的.
SDPA的代码实现
class ScaleDotProductAttention(nn.Module):
def __init__(
self,
device,
):
super().__init__()
self.softmax = nn.Softmax(dim=-1).to(device)
def forward(self, q, k, v, mask=None, e=1e-12):
"""
:param q:
:param k:
:param v:
:param mask: (batch_size, n_head, seq_len, seq_len)
:param e:
:return:
"""
batch_size, head, length, d_tensor = k.size()
k_t = k.transpose(2, 3)
score = (q @ k_t) / math.sqrt(d_tensor)
if mask is not None:
score = score.masked_fill(mask == 0, -10000)
score = self.softmax(score)
v = score @ v
return v, scoreMHA
MHA很好理解就是对输入进行分头后再交给SDPA处理,然后再把分出来的头合并就行了
代码如下所示
Encoder部分
import torch
from torch import nn
import math
import dataset
import time
class TransformerEmbedding(nn.Module):
"""
token embedding + positional encoding (sinusoid)
positional encoding can give positional information to network
"""
def __init__(
self,
vocabulary_size,
embedding_dim,
seq_len,
dropout_prob,
device
):
"""
class for word embedding that included positional information
:param vocabulary_size: size of vocabulary
:param embedding_dim: dimensions of model
"""
super().__init__()
# 这里的TokenEmbedding使用的就是nn.Embedding,所以在这里我把它改回nn.Embedding
# self.tok_emb = TokenEmbedding(vocabulary_size, embedding_dim)
self.tok_emb = nn.Embedding(vocabulary_size, embedding_dim).to(device)
self.pos_emb = PositionalEncoding(embedding_dim, seq_len, device).to(device)
self.drop_out = nn.Dropout(p=dropout_prob).to(device)
def forward(self, x):
"""
:param x: (batch_size, seq_len)
:return: (batch_size, seq_len, embedding_dim)
"""
tok_emb = self.tok_emb(x)
# tok_emb: (batch_size, seq_len, embedding_dim)
pos_emb = self.pos_emb(x)
# pos_emb: (seq_len, embedding_dim)
# temp = pos_emb + tok_emb
# print(temp[:5, :3, :3])
# 运用了广播机制竟然给他加上去了神奇
return self.drop_out(tok_emb + pos_emb)
class PositionalEncoding(nn.Module):
"""
compute sinusoid encoding.
"""
def __init__(
self,
embedding_dim,
seq_len,
device
):
"""
constructor of sinusoid encoding class
:param embedding_dim: dimension of model
:param seq_len: max sequence length
:param device: hardware device setting
"""
super().__init__()
# same size with input matrix (for adding with input matrix)
self.encoding = torch.zeros(seq_len, embedding_dim, device=device)
self.encoding.requires_grad = False # we don't need to compute gradient
# encoding: (seq_len, embedding_dim)
pos = torch.arange(0, seq_len, device=device)
# pos: (seq_len,)
# print(pos.shape)
pos = pos.float().unsqueeze(dim=1)
# pos: (seq_len, 1)
# print(pos.shape)
# 1D => 2D unsqueeze to represent word's position
_2i = torch.arange(0, embedding_dim, step=2, device=device).float()
# 'i' means index of embedding_dim (e.g. embedding size = 50, 'i' = [0,50])
# "step=2" means 'i' multiplied with two (same with 2 * i)
self.encoding[:, 0::2] = torch.sin(pos / (10000 ** (_2i / embedding_dim)))
self.encoding[:, 1::2] = torch.cos(pos / (10000 ** (_2i / embedding_dim)))
# self.encoding: (seq_len, embedding_dim)
# print(self.encoding)
# compute positional encoding to consider positional information of words
def forward(self, x):
# self.encoding
# [seq_len = 512, embedding_dim = 512]
batch_size, seq_len = x.size()
# [batch_size = 128, seq_len = 30]
return self.encoding[:seq_len, :]
class TokenEmbedding(nn.Embedding):
"""
Token Embedding using torch.nn
they will be dense representation of word using weighted matrix
"""
def __init__(self, vocabulary_size, embedding_dim):
"""
class for token embedding that included positional information
:param vocabulary_size: size of vocabulary
:param embedding_dim: dimensions of model
"""
super().__init__(vocabulary_size, embedding_dim, padding_idx=1)
class MultiHeadAttention(nn.Module):
def __init__(
self,
embedding_dim,
n_head,
device,
):
super().__init__()
self.n_head = n_head
self.attention = ScaleDotProductAttention(device).to(device)
self.w_q = nn.Linear(embedding_dim, embedding_dim).to(device)
self.w_k = nn.Linear(embedding_dim, embedding_dim).to(device)
self.w_v = nn.Linear(embedding_dim, embedding_dim).to(device)
self.w_concat = nn.Linear(embedding_dim, embedding_dim).to(device)
def forward(self, q, k, v, mask=None):
"""
:param q: (batch_size, seq_len, embedding_dim)
:param k: (batch_size, seq_len, embedding_dim)
:param v: (batch_size, seq_len, embedding_dim)
:param mask:
:return:
"""
# 1. dot product with weight matrices
# 线性变换
q, k, v = self.w_q(q), self.w_k(k), self.w_v(v) # [N, seq_len, embedding_dim]
# 2. split tensor by number of heads
q, k, v = self.split(q), self.split(k), self.split(v) # [N, head, seq_len, embedding_dim]
# q, k, v: (batch_size, n_head, seq_len, embedding_dim // n_head)
# print(q.shape, k.shape, v.shape)
# 3. do scale dot product to compute similarity
out, attention = self.attention(q, k, v, mask=mask) # out:[N, head, seq_len, embedding_dim]
# 4. concat and pass to linear layer
out = self.concat(out) # [N, seq_len, embedding_dim]
# out: (batch_size, seq_len, embedding_dim)
# print(out.shape)
out = self.w_concat(out)
# 5. visualize attention map
# TODO : we should implement visualization
return out
def split(self, tensor):
"""
split tensor by number of head
:param tensor: [batch_size, length, embedding_dim]
:return: [batch_size, head, length, d_tensor]
"""
batch_size, length, embedding_dim = tensor.size()
d_tensor = embedding_dim // self.n_head
tensor = tensor.view(batch_size, length, self.n_head, d_tensor).transpose(1, 2)
# it is similar with group convolution (split by number of heads)
return tensor
def concat(self, tensor):
"""
inverse function of self.split(tensor : torch.Tensor)
:param tensor: [batch_size, head, length, d_tensor]
:return: [batch_size, length, embedding_dim]
"""
batch_size, head, length, d_tensor = tensor.size()
embedding_dim = head * d_tensor
tensor = tensor.transpose(1, 2).contiguous().view(batch_size, length, embedding_dim)
return tensor
class ScaleDotProductAttention(nn.Module):
"""
compute scale dot product attention
Query : given sentence that we focused on (decoder)
Key : every sentence to check relationship with Qeury(encoder)
Value : every sentence same with Key (encoder)
"""
def __init__(
self,
device,
):
super().__init__()
self.softmax = nn.Softmax(dim=-1).to(device)
def forward(self, q, k, v, mask=None, e=1e-12):
"""
:param q:
:param k:
:param v:
:param mask: (batch_size, n_head, seq_len, seq_len)
:param e:
:return:
"""
# input is 4 dimension tensor
# [batch_size, head, length, d_tensor]
batch_size, head, length, d_tensor = k.size()
# 1. dot product Query with Key^T to compute similarity
k_t = k.transpose(2, 3) # transpose
score = (q @ k_t) / math.sqrt(d_tensor) # scaled dot product
# print(score.shape)
# 2. apply masking (opt)
if mask is not None:
score = score.masked_fill(mask == 0, -10000)
# TODO: 搞明白这个mask怎么工作
# 3. pass them softmax to make [0, 1] range
score = self.softmax(score)
# 4. multiply with Value
v = score @ v
return v, score
class LayerNorm(nn.Module):
def __init__(self, embedding_dim, eps=1e-12):
"""
使用该层的时候记得.cuda()
:param embedding_dim:
:param eps:
"""
super().__init__()
self.gamma = nn.Parameter(torch.ones(embedding_dim))
self.beta = nn.Parameter(torch.zeros(embedding_dim))
self.eps = eps
def forward(self, x):
mean = x.mean(-1, keepdim=True)
var = x.var(-1, unbiased=False, keepdim=True)
# '-1' means last dimension.
out = (x - mean) / torch.sqrt(var + self.eps)
out = self.gamma * out + self.beta
return out
class PositionwiseFeedForward(nn.Module):
def __init__(
self,
embedding_dim,
hidden,
dropout_prob,
device
):
super().__init__()
self.linear1 = nn.Linear(embedding_dim, hidden).to(device)
self.linear2 = nn.Linear(hidden, embedding_dim).to(device)
self.relu = nn.ReLU().to(device)
self.dropout = nn.Dropout(p=dropout_prob).to(device)
def forward(self, x):
"""
:param x: (batch_size, seq_len, embedding_dim)
:return: (batch_size, seq_len, embedding_dim)
"""
x = self.linear1(x)
x = self.relu(x)
x = self.dropout(x)
x = self.linear2(x)
return x
class EncoderLayer(nn.Module):
def __init__(
self,
embedding_dim,
ffn_hidden,
n_head,
dropout_prob,
device,
):
super().__init__()
self.attention = MultiHeadAttention(embedding_dim=embedding_dim, n_head=n_head, device=device).to(device)
self.norm1 = LayerNorm(embedding_dim=embedding_dim).to(device)
self.dropout1 = nn.Dropout(p=dropout_prob).to(device)
self.ffn = PositionwiseFeedForward(embedding_dim=embedding_dim, hidden=ffn_hidden, dropout_prob=dropout_prob, device=device).to(device)
self.norm2 = LayerNorm(embedding_dim=embedding_dim).to(device)
self.dropout2 = nn.Dropout(p=dropout_prob).to(device)
def forward(self, x, s_mask):
"""
:param x: (batch_size, seq_len, embedding_dim)
:param s_mask:
:return: (batch_size, seq_len, embedding_dim)
"""
# 1. compute self attention
_x = x
x = self.attention(q=x, k=x, v=x, mask=s_mask)
# 2. add and norm
x = self.dropout1(x)
x = self.norm1(x + _x)
# 3. positionwise feed forward network
_x = x
x = self.ffn(x)
# 4. add and norm
x = self.dropout2(x)
x = self.norm2(x + _x)
return x
class Encoder(nn.Module):
def __init__(
self,
encoder_vocabulary_size,
seq_len,
embedding_dim,
ffn_hidden,
n_head,
n_layers,
dropout_prob,
device
):
super().__init__()
self.embedding = TransformerEmbedding(
embedding_dim=embedding_dim,
seq_len=seq_len,
vocabulary_size=encoder_vocabulary_size,
dropout_prob=dropout_prob,
device=device
).to(device)
self.layers = nn.ModuleList(
[
EncoderLayer(
embedding_dim=embedding_dim,
ffn_hidden=ffn_hidden,
n_head=n_head,
dropout_prob=dropout_prob,
device=device
)
for _ in range(n_layers)
]
).to(device)
def forward(self, x, s_mask):
"""
:param x: (batch_size, seq_len)
:param s_mask: ?
:return: ?
"""
x = self.embedding(x)
# x: (batch_size, seq_len, embedding_dim)
for layer in self.layers:
x = layer(x, s_mask)
return x
if __name__ == '__main__':
BATCH_SIZE = 128
SEQ_LEN = 16
VOCABULARY_SIZE = 2500
EMBEDDING_DIM = 32
N_HEAD = 8
N_LAYERS = 6
FFN_HIDDEN = 64
DEVICE = torch.device('cuda')
DROPOUT_P = 0.2
E = Encoder(
encoder_vocabulary_size=VOCABULARY_SIZE,
seq_len=SEQ_LEN,
embedding_dim=EMBEDDING_DIM,
ffn_hidden=FFN_HIDDEN,
n_head=N_HEAD,
n_layers=N_LAYERS,
dropout_prob=DROPOUT_P,
device=DEVICE
).cuda()
input_tensor = torch.zeros(
(BATCH_SIZE, SEQ_LEN),
device=DEVICE,
).int()
a = E(input_tensor, None)
print(a.shape)Decoder部分后面会更新















 1674
1674











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









