







1、Transformer 结构
模型由三个模块组成:
Linear Projection of Flattened Patches(Embedding层)
Transformer Encoder(图右侧有给出更加详细的结构)
MLP Head(最终用于分类的层结构)
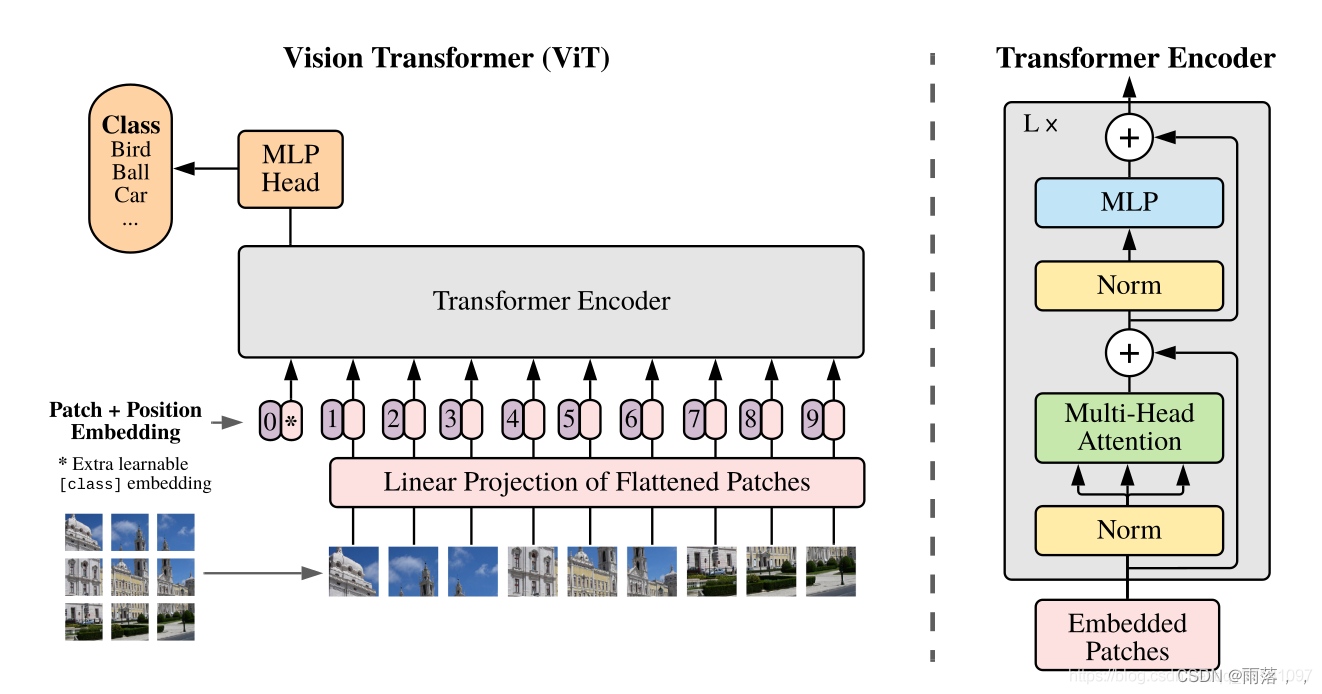
参考文章:
Vision Transformer详解
2、Embedding层中cls_token和Positional Encoding
对于标准的Transformer模块,要求输入的是token(向量)序列,即二维矩阵[num_token, token_dim],在对图形进行变换后,输入TE模块前需要加上[class]token以及Position Embedding。
cls_token作用:
若将图片化分为9个小图像块,无cls_token时,输入9个类别向量,输出9个类别向量,无法判别用哪个输出变量进行分类,设置cls_token放在首位置,经过训练,考虑所有的patch feature,得到image feature, 也就是对所有的token做了信息汇聚,用于后续分类。
**另:**对n个token做平均作为要分类的特征,也是一种全局特征聚合的方式,但它相较于采用attention机制来做全局特征聚合而言表达能力较弱。
参考文章:
vit 中的 cls_token 与 position_embed 理解
ViT为何引入cls_token
Positional Encoding:
对于传统CNN、RNN模型,因其处理机制模型本身已经具备很强的捕捉位置信息的特性,所以position embedding属于锦上添花;
使用attention机制取代cnn、rnn的如transformer、bert模型,本身是一个n*n不包含任何位置信息的词袋模型;
所以需要和字embedding 相加。














 5739
5739











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









