







 本文是关于LDA主题模型的学习笔记,介绍了LDA的基本原理、共轭先验分布和Gibbs采样求解LDA的过程。LDA是一种无监督学习算法,用于找出文档集中的主题分布。文章详细阐述了LDA模型的生成过程,以及Gibbs采样在求解LDA中的应用,包括蒙特卡洛方法、马尔科夫链和MCMC采样。
本文是关于LDA主题模型的学习笔记,介绍了LDA的基本原理、共轭先验分布和Gibbs采样求解LDA的过程。LDA是一种无监督学习算法,用于找出文档集中的主题分布。文章详细阐述了LDA模型的生成过程,以及Gibbs采样在求解LDA中的应用,包括蒙特卡洛方法、马尔科夫链和MCMC采样。
本博客原文
本文为学习LDA主题模型的笔记,主要是对LDA主题模型进行一个简单的概括,具体的细节及推导可以参见:
一、问题提出
什么是主题模型?什么是LDA?
将文档集中,每篇文档的主题按照概率分布的形式给出,属于无监督的学习算法。需要的输入仅仅是文档集和指定的文档主题数量K
隐含狄利克雷分布(Latent Dirichlet allocation)简称LDA。LDA是一种典型的词袋模型,词与词之间没有顺序及先后关系。一篇文档可以包含多个主题,文档中的每个词都由其中一个主题生成。
二、必备知识
- 蒙特卡洛方法、马尔科夫链、MCMC采样和M-H采样,Gibbs采样 。参考资料
- EM算法。参考资料:统计学习方法EM算法
- 概率论相关知识以及一些优化算法(如牛顿法等)
三、概述
LDA模型中,一篇文档的生成方式如下
- 从狄利克雷分布中取样生成文档i的主题分布 θi
- 从主题的多项式分布 θi 中取样生成文档i第j个词的主题 zi,j
- 从狄利克雷分布 β 中取样生成主题 Zi,j 的词语分布 Φzi,j
- 从词语的多项式分布 Φzi,j 中采样最终生成词语 ωi,j
即:主题分布–> 主题–>词语分布–>词语
共轭先验分布
在贝叶斯统计中,如果后验分布与先验分布属于同类,则先验分布与后验分布被称为共轭分布,而先验分布被称为似然函数的共轭先验
Beta分布是二项分布的共轭先验分布,Dirichlet分布是多项分布的共轭先验分布
LDA主题模型
目标:找到每一篇文档中的主题分布和每一个主题中词的分布
LDA的模型图如下(图片来自pinard博客)
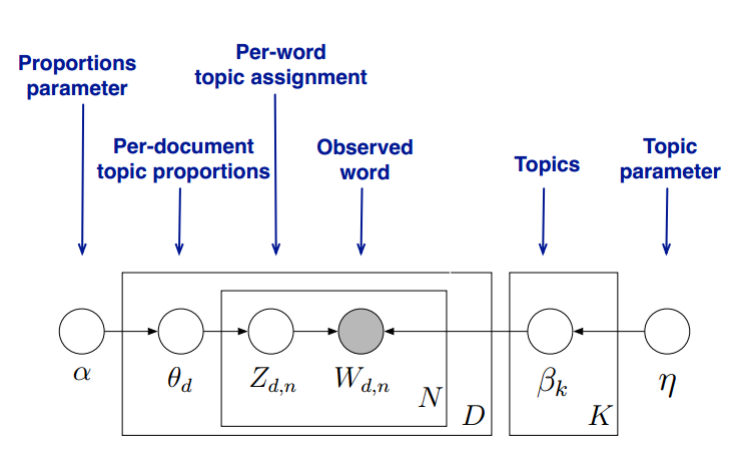
LDA假设主题中词的先验分布是Dirichlet分布,即对任一文档d,其主题分布 θd 为
θd=Dirichlet(α⃗ ) , α⃗ 是K维(主题数)向量
LDA假设主题中词的先验分布是Dirichlet分布,即对任一主题k,其词分布为
βk=Dirichlet(η⃗ ) , η⃗ 是V维(词汇表中词数)向量
对任一文档d中第n个词,可以从主题分布 θd 中获得它的主题编号 zdn 的分布为
zdn=multi(θd)
而对于该主题,得到我们看到的词 Wdn 的概率为
Wdn=multi(βzdn)
设在文档d中,第k个主题的次数为 n(k)d ,则对应多项分布的计数为 nd→=(n(1)d,n(2)d,...,n(k)d)
根据Dirichlet-Multi共轭,有 θd 的后验分布为
Dirichlet(θd|nd→+α⃗ ) (新的文档-主体分布)
同理,设第k个主题中,第v个词的个数为 n(v)k ,则对应的多项分布的计数为 nk→=(n(1)k,n(2)k,...,n(V)k)
根据Dirichlet-Multi共轭,有 βk 的后验分布为
Dirichlet(βk|nk→+η⃗ )
主题产生词不依赖具体文档,这说明文档-主题分布和主题-词分布是独立的。
以上是LDA基本原理,剩下需要解决的问题是
基于一个LDA模型,如何求解每一篇文档的主题分布和每个主题的词分布,即如何求解 θd 和 βk
求解LDA的方法有Gibbs采样和变分推断EM两种
四、Gibbs采样求解LDA
Gibbs采样解决的是使采样数据符合指定分布的问题。在了解Gibbs采样之前,先了解一下蒙特卡洛方法。
蒙特卡洛方法
蒙特卡洛方法是一种随机的方法。我们在中小学时学习过使用投针实验估计圆周率的问题就是属于蒙特卡洛方法。一般地,蒙特卡洛方法可用来解决定积分(投针实验可以看作是求解0~r上圆形曲线的定积分问题)。
对于 ∫baf(x)dx ,若f(x)的原函数较难求解,则可以使用蒙特卡洛方法近似
在[a,b]上随机采样n个点, x1,x2,...,xn
∫baf(x)dx≈b−an
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5733
5733

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









