







TensorFlow的Session对象是支持多线程的,可以在同一个会话(Session)中创建多个线程,并行执行。在Session中的所有线程都必须能被同步终止,异常必须能被正确捕获并报告,会话终止的时候, 队列必须能被正确地关闭。
tf.train.Coordinator是tensorflow的一个多线程管理器,Coordinator类用来管理在Session中的多个线程,可以用来同时停止多个工作线程并且向那个在等待所有工作线程终止的程序报告异常,该线程捕获到这个异常之后就会终止所有线程。使用 tf.train.Coordinator()来创建一个线程管理器(协调器)对象。
tf中的数据读取机制如下图:
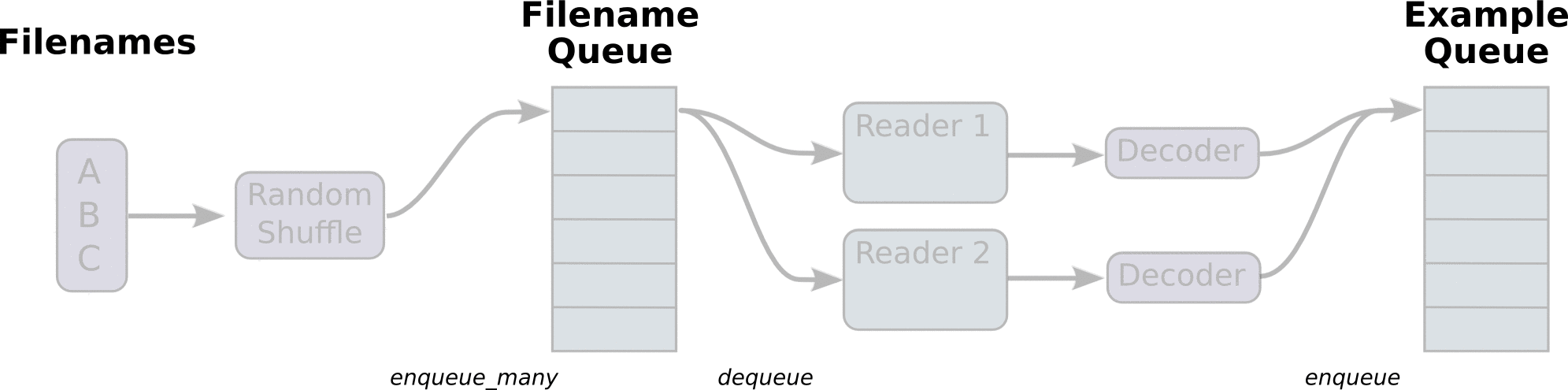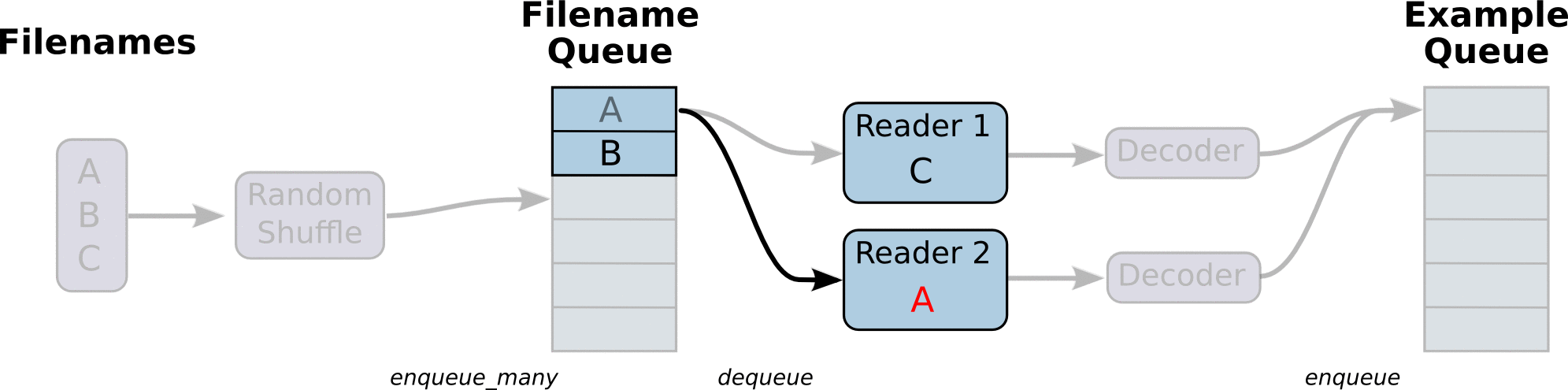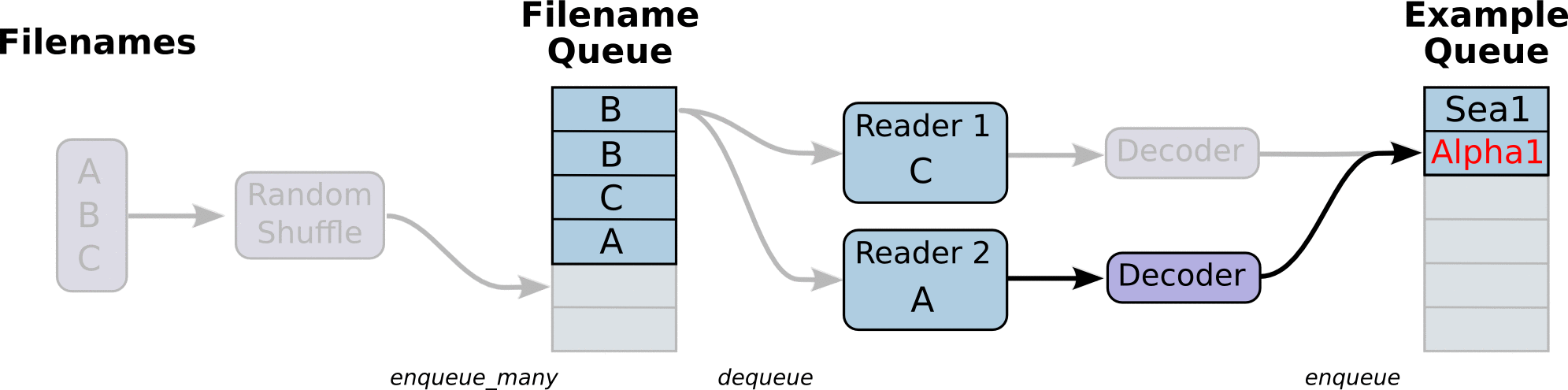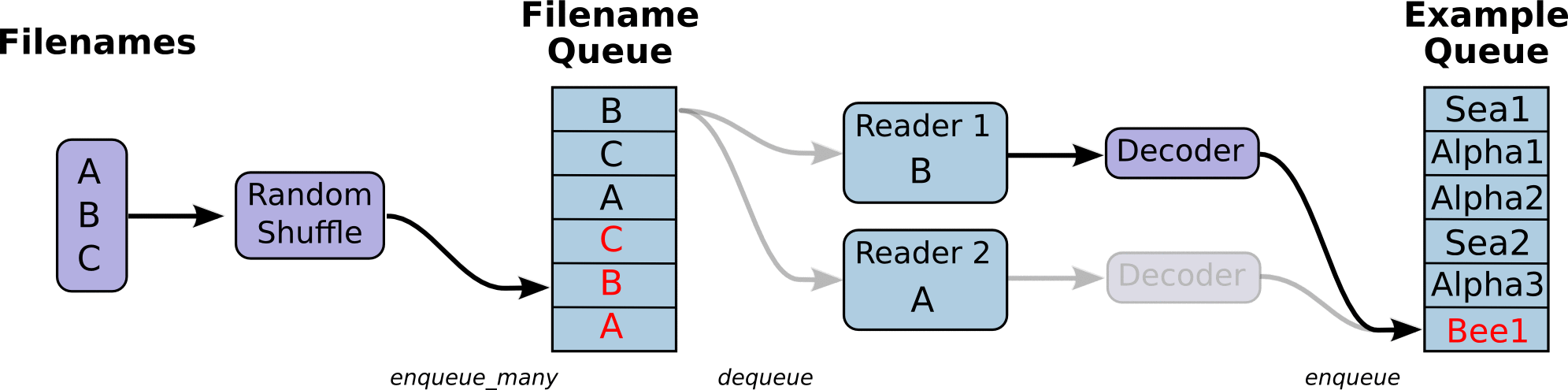
- 调用 tf.train.slice_input_producer,从 本地文件里抽取tensor,准备放入Filename Queue(文件名队列)中;
- 调用 tf.train.batch,从文件名队列中提取tensor,使用单个或多个线程,准备放入文件队列;
- 调用 tf.train.Coordinator() 来创建一个线程协调器,用来管理之后在Session中启动的所有线程;
- 调用tf.train.start_queue_runners, 启动入队线程,由多个或单个线程,按照设定规则,把文件读入Filename Queue中。函数返回线程ID的列表,一般情况下,系统有多少个核,就会启动多少个入队线程(入队具体使用多少个线程在tf.train.batch中定义);
- 文件从 Filename Queue中读入内存队列的操作不用手动执行,由tf自动完成;
- 调用sess.run 来启动数据出列和执行计算;
- 使用 coord.should_stop()来查询是否应该终止所有线程,当文件队列(queue)中的所有文件都已经读取出列的时候,会抛出一个 OutofRangeError 的异常,这时候就应该停止Sesson中的所有线程了;
- 使用coord.request_stop()来发出终止所有线程的命令,使用coord.join(threads)把线程加入主线程,等待threads结束。
如果顺利执行的话,你现在可以执行你的训练步骤,同时队列也会被后台线程来填充。如果设置了最大训练迭代数,在某些时候,样本出队的操作可能会得到一个tf.OutOfRangeError的错误。这其实是TensorFlow的“文件结束”(EOF) ———— 这就意味着已经达到了最大训练迭代数,已经没有更多可用的样本了。
还有一个因素是Coordinator。这是负责在收到任何关闭信号的时候,让所有的线程都知道。最常用的是在发生异常时这种情况就会呈现出来,比如说其中一个线程在运行某些操作时出现错误(或一个普通的Python异常)。
那么,在达到最大训练迭代数的时候如何清理关闭线程?
QueueRunner在捕获到OutOfRange错误后,关闭文件名的队列,最后退出线程。关闭队列做了两件事情:
(1)如果还试着对文件名队列执行入队操作时将发生错误。任何线程不应该尝试去这样做,但是当队列因为其他错误而关闭时,这就会有用了。
(2)任何当前或将来出队操作要么成功(如果队列中还有足够的元素)或立即失败(发生OutOfRange错误)。它们不会防止等待更多的元素被添加到队列中,因为上面的一点已经保证了这种情况不会发生。
关键是,当在文件名队列被关闭时候,有可能还有许多文件名在该队列中,这样下一阶段的流水线(包括reader和其它预处理)还可以继续运行一段时间。 一旦文件名队列空了之后,如果后面的流水线还要尝试从文件名队列中取出一个文件名(例如,从一个已经处理完文件的reader中),这将会触发OutOfRange错误。在这种情况下,即使你可能有一个QueueRunner关联着多个线程。如果这不是在QueueRunner中的最后那个线程,OutOfRange错误仅仅只会使得一个线程退出。这使得其他那些正处理自己的最后一个文件的线程继续运行,直至他们完成为止。 (但如果你用的是tf.train.Coordinator,其他类型的错误将导致所有线程停止)。一旦所有的reader线程触发OutOfRange错误,然后才是下一个队列,再是样本队列被关闭。
同样,样本队列中会有一些已经入队的元素,所以样本训练将一直持续直到样本队列中再没有样本为止。如果样本队列是一个RandomShuffleQueue,因为你使用了shuffle_batch 或者 shuffle_batch_join,所以通常不会出现以往那种队列中的元素会比min_after_dequeue 定义的更少的情况。 然而,一旦该队列被关闭,min_after_dequeue设置的限定值将失效,最终队列将为空。在这一点来说,当实际训练线程尝试从样本队列中取出数据时,将会触发OutOfRange错误,然后训练线程会退出。一旦所有的培训线程完成,tf.train.Coordinator.join会返回,你就可以正常退出了。
看看协调器(Coordinator)操作具体示例:
# -*- coding:utf-8 -*-
import tensorflow as tf
import numpy as np
# 样本个数
sample_num=5
# 设置迭代次数
epoch_num = 2
# 设置一个批次中包含样本个数
batch_size = 3
# 计算每一轮epoch中含有的batch个数
batch_total = int(sample_num/batch_size)+1
# 生成4个数据和标签
def generate_data(sample_num=sample_num):
labels = np.asarray(range(0, sample_num))
images = np.random.random([sample_num, 224, 224, 3])
print('image size {},label size :{}'.format(images.shape, labels.shape))
return images,labels
def get_batch_data(batch_size=batch_size):
images, label = generate_data()
# 数据类型转换为tf.float32
images = tf.cast(images, tf.float32)
label = tf.cast(label, tf.int32)
#从tensor列表中按顺序或随机抽取一个tensor准备放入文件名称队列
input_queue = tf.train.slice_input_producer([images, label], num_epochs=epoch_num, shuffle=False)
#从文件名称队列中读取文件准备放入文件队列
image_batch, label_batch = tf.train.batch(input_queue, batch_size=batch_size, num_threads=2, capacity=64, allow_smaller_final_batch=False)
return image_batch, label_batch
image_batch, label_batch = get_batch_data(batch_size=batch_size)
with tf.Session() as sess:
# 先执行初始化工作
sess.run(tf.global_variables_initializer())
sess.run(tf.local_variables_initializer())
# 开启一个协调器
coord = tf.train.Coordinator()
# 使用start_queue_runners 启动队列填充
threads = tf.train.start_queue_runners(sess, coord)
try:
while not coord.should_stop():
print '************'
# 获取每一个batch中batch_size个样本和标签
image_batch_v, label_batch_v = sess.run([image_batch, label_batch])
print(image_batch_v.shape, label_batch_v)
except tf.errors.OutOfRangeError: #如果读取到文件队列末尾会抛出此异常
print("done! now lets kill all the threads……")
finally:
# 协调器coord发出所有线程终止信号
coord.request_stop()
print('all threads are asked to stop!')
coord.join(threads) #把开启的线程加入主线程,等待threads结束
print('all threads are stopped!')输出如下:
************
((3, 224, 224, 3), array([0, 1, 2], dtype=int32))
************
((3, 224, 224, 3), array([3, 4, 0], dtype=int32))
************
((3, 224, 224, 3), array([1, 2, 3], dtype=int32))
************
done! now lets kill all the threads……
all threads are asked to stop!
all threads are stopped!
转自https://blog.csdn.net/weixin_42052460/article/details/80714539















 598
598











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









