







支持向量机,其含义是通过
支持向量运算的分类器。支持向量机是一个
二类分类器。
在求解的过程中,会发现只根据部分数据就可以确定分类器,这些数据称为
支持向量。
见下图,在一个二维环境中,其中点R,S,G点和其它靠近中间黑线的点可以看作为
支持向量,它们可以决定分类器,也就是黑线的具体参数。

线性分类:可以理解为在2维空间中,可以通过一条直线来分类。在p维空间中,可以通过一个p-1维的
超平面来分类。
线性分类
在训练数据中,每个数据都有
n个的属性和一个
二类类别标志,我们可以认为这些数据在一个n维空间里。我们的目标是找到一个n-1维的超平面(hyperplane),这个超平面可以将数据分成两部分,每部分数据都属于同一个类别。
其实这样的超平面有很多,我们要找到一个
最佳的。因此,增加一个
约束条件:这个超平面到每边最近数据点的距离是最大的。也成为
最大间隔超平面(maximum-margin hyperplane)。这个分类器也成为
最大间隔分类器(maximum-margin classifier)。
优势是
不需要样本数据。

非线性分类
SVM的一个优势是支持非线性分类。它结合使用
拉格朗日乘子法和
KKT条件,以及
核函数可以产生非线性分类器。
支持线性分类和非线性分类,需要部分样本数据(支持向量)。
f(x)=∑ni=1αiyiK(xi,x)+b
here
xi : training data i
yi : label value of training data i
αi : Lagrange multiplier of training data i
K(x1,x2)=exp(−∥x1−x2∥22σ2) : kernel function

首先通过两个分类的最近点,找到f(x)的
约束条件。
有了约束条件,就可以通过
拉格朗日乘子法和KKT条件来求解,这时,问题变成了
求拉格朗日乘子αi 和 b。
核函数有很多种, 一般可以使用
高斯核

线性核(Linear Kernel)
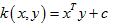
多项式核(Polynomial Kernel)
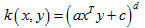
















 4785
4785

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











