







回归问题的条件/前提:
1) 收集的数据
2) 假设的模型,即一个函数,这个函数里含有未知的参数,通过学习,可以估计出参数。
然后利用这个模型去预测/分类新的数据。
1. 线性回归
线性模型函数,向量表示形式:
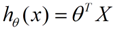
一个含未知参数的线性模型,一堆观测数据,其模型与数据的误差最小的形式,模型与数据差的平方和最小:
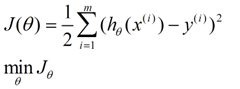
这就是损失函数的来源。接下来,就是求解这个函数的方法,有最小二乘法,
不过它要求X是列满秩的,
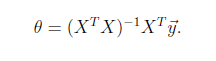
梯度下降法。
梯度下降法:负梯度方向,步长,更新,收敛
2. 逻辑回归
广义线性模型
形式基本上都差不多,不同的就是因变量不同
:
- 如果是连续的,就是多重(多元)线性回归;
- 如果是二项分布(离散型的),就是Logistic回归;
- 如果是Poisson分布,就是Poisson回归;
- 如果是负二项分布,就是负二项回归。
Regression问题的常规步骤为:
- 寻找h函数(即hypothesis预测函数);
- 构造J函数(损失函数);
- 想办法使得J函数最小并求得回归参数(θ)
Logistic函数(或称为Sigmoid函数),函数形式为:
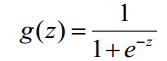
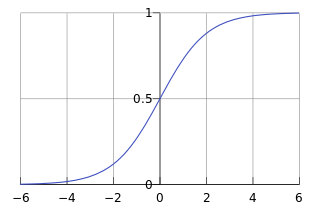
对于线性边界的情况,边界形式如下:
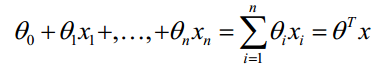
构造预测函数为:
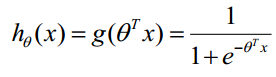
函数的值有特殊的含义,它表示结果取1的概率,因此对于输入x分类结果为类别1和类别0的概率分别为:
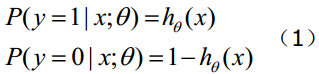
构造损失函数J
Cost函数和J函数如下,它们是基于最大似然估计推导得到的。
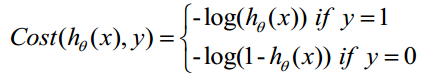
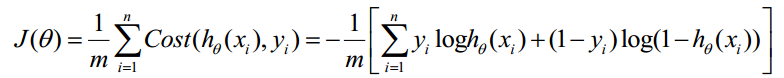
下面详细说明推导的过程:
(1)式综合起来可以写成:
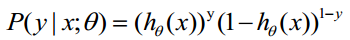
取似然函数为:
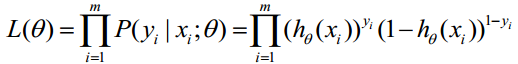
对数似然函数为:
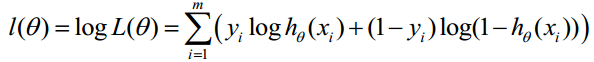
即:
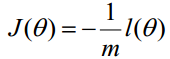
梯度下降法求的最小值
θ更新过程:
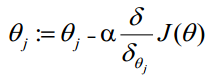
θ更新过程可以写成:
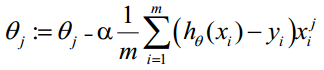
应用举例:
是否垃圾邮件分类?
是否肿瘤、癌症诊断?
是否金融欺诈?
Logistic回归的主要用途:
- 寻找危险因素:寻找某一疾病的危险因素等;
- 预测:根据模型,预测在不同的自变量情况下,发生某病或某种情况的概率有多大;
- 判别:实际上跟预测有些类似,也是根据模型,判断某人属于某病或属于某种情况的概率有多大,也就是看一下这个人有多大的可能性是属于某病。
过拟合问题的主因
过拟合问题往往源自过多的特征。
解决方法
1)减少特征数量(减少特征会失去一些信息,即使特征选的很好)
- 可用人工选择要保留的特征;
- 模型选择算法;
2)正则化(特征较多时比较有效)
- 保留所有特征,但减少θ的大小
正则化:
为防止过度拟合的模型出现(过于复杂的模型),在损失函数里增加一个每个特征的惩罚因子。这个就是正则化。
正则项可以取不同的形式,在回归问题中取平方损失,就是参数的L2范数,也可以取L1范数。取平方损失时,模型的损失函数变为:
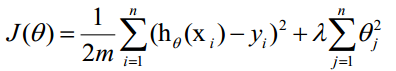
lambda是正则项系数
















 9780
9780

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











