







统计特性
- 30定律:出现频率最高的30%的词在书面文本占用了30%的出现比例
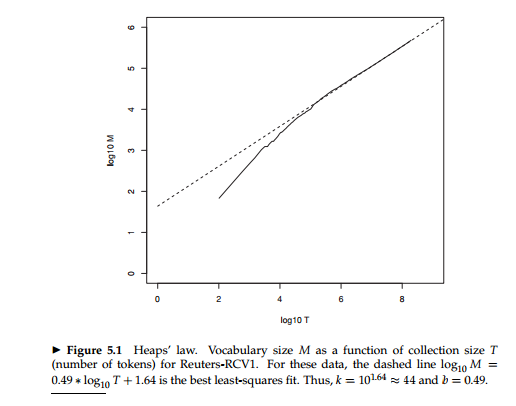
Heaps定律:词项数目的估计。 M=kTb
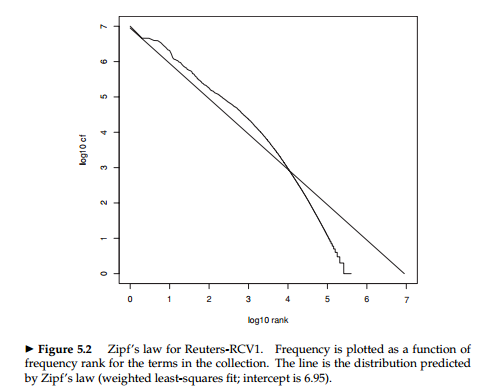
M是文档集的distinct词汇的大小, T是文档集中所有的token。Zipf定律:对词项的分布建模: cfi∝1i
cfi 是文档集频率排名为i的词汇,
词典压缩
Naive方法
每个词20B,文档频率4B(32位的数字),地址指针4B(32位的系统可访问4G地址空间)
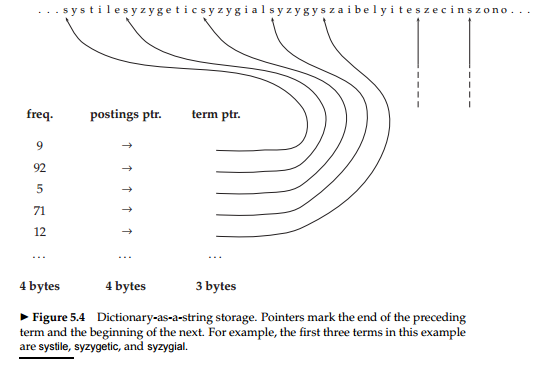
总共占用的存储空间为 M×(20+4+4)词典看成单一字符串
英语中term的平均长度是8B。如上图,所有term变成一个长的字符串,使用位置指针,在term的存储上节省了12B,额外使用一个指针。
假如数据库中有400 000 个term, 地址空间为 400000×8=3.2×106 ,用一个指针 Log23.2×106=22bit=3B
文档频率/倒排记录表指针/词项指针 = 4B/4B/3B。
故需要的空间是 400000×(4+4+3+8)=7.6MB ,比原来节省了很多。- 按块存储
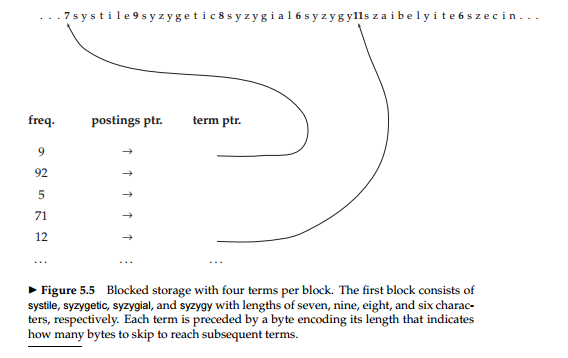
为了减少词项指针, 选择 k 个词项共用一个指针,并且用一个数字记录每个词项的大小,故对于每个块,可以减少k−1 个词项指针,但需要 k B的空间来存储词项长度。
如前面的数据库,可以每个块可以减少(k−1)×3=9B ,但需要增加 k=4B 来存储词项长度,所以一个块能节省 5B 。总共能节省下的空间是 400000×1/4×5=0.5MB 。
实际上就是在压缩大小和查询速度之间权衡。















 1772
1772

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









