











今天,将推出最新的基础模型 Rerank 3,该模型旨在增强企业搜索和检索增强生成 Retrieval Augmented Generation (RAG) 系统。
模型与任何数据库或搜索索引兼容,也可以插入任何具有本机搜索功能的遗留应用程序中。 只需一行代码,Rerank 3 就可以提高搜索性能或降低运行 RAG 应用程序的成本,而对延迟的影响可以忽略不计。
Rerank 3 为企业搜索提供最先进的功能,包括:
- 4k 上下文长度可显着提高较长文档的搜索质量
- 能够搜索多方面和半结构化数据,例如电子邮件、发票、JSON 文档、代码和表格
- 多语言覆盖100+语言
- 改善延迟并降低总体拥有成本 (TCO)
具有长上下文的生成模型具有执行 RAG 的能力。 然而,为了优化准确性、延迟和成本,RAG 解决方案需要结合生成模型和我们的 Rerank 模型。 Rerank 3 的高精度语义重新排序可确保仅将最相关的信息馈送到生成模型,从而提高响应准确性并保持较低的延迟和成本,特别是在从成千上万的文档中检索信息时。
增强的企业搜索 Enhanced Enterprise Search
企业数据通常很复杂,当前的系统很难搜索多方面和半结构化的数据源。 公司中最有用的数据通常不是简单的文档格式,半结构化数据格式(例如 JSON)在企业应用程序中很常见。 Rerank 3 能够根据所有相关元数据字段(包括其新近度)对复杂、多方面的数据(例如电子邮件)进行排名。
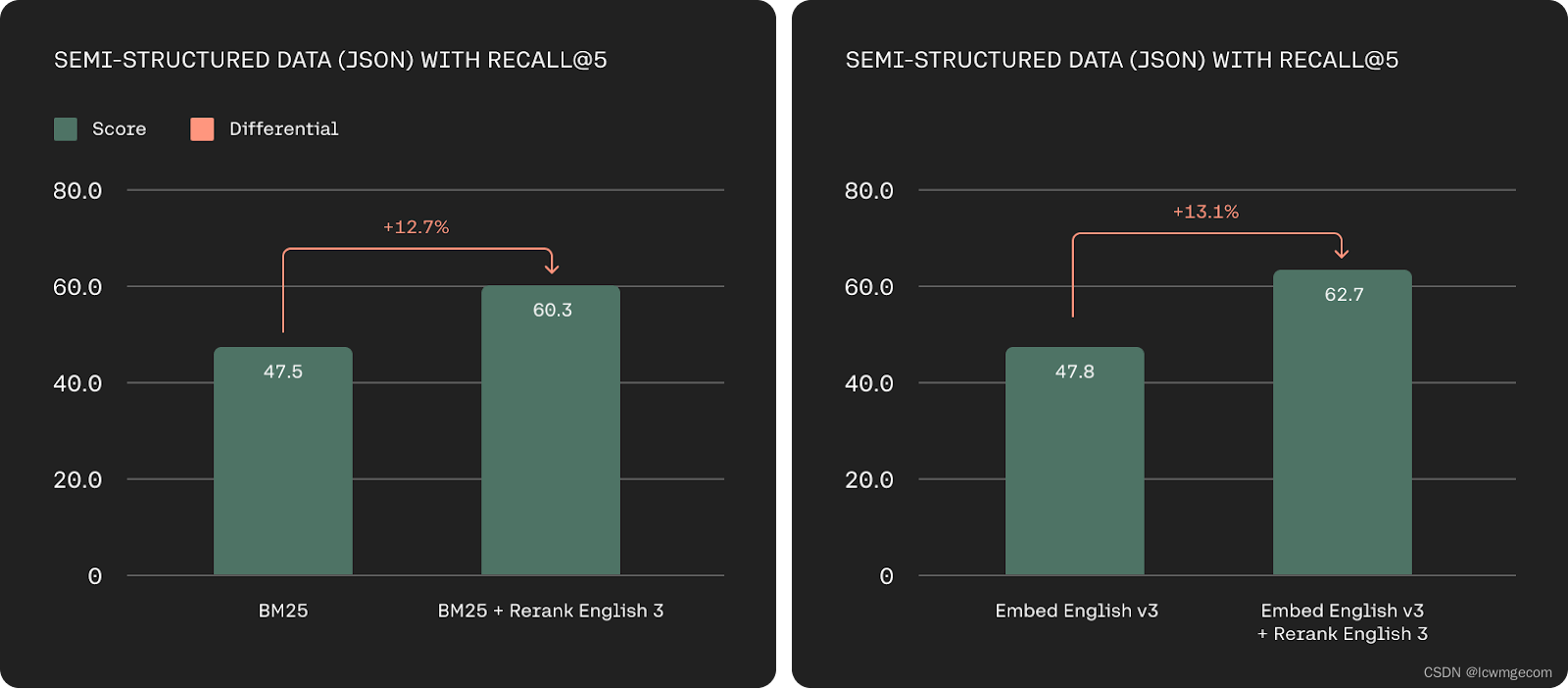
基于 Recall@5 在 TMDB-5k-Movies、WikiSQL、nq-table 和 Cohere 带注释数据集上的半结构化检索精度(越高越好)。
Rerank 3 还展示了代码检索能力的显着改进。 这可能包括检索企业的专有代码存储库以提高其工程团队的生产力,或检索大量文档。
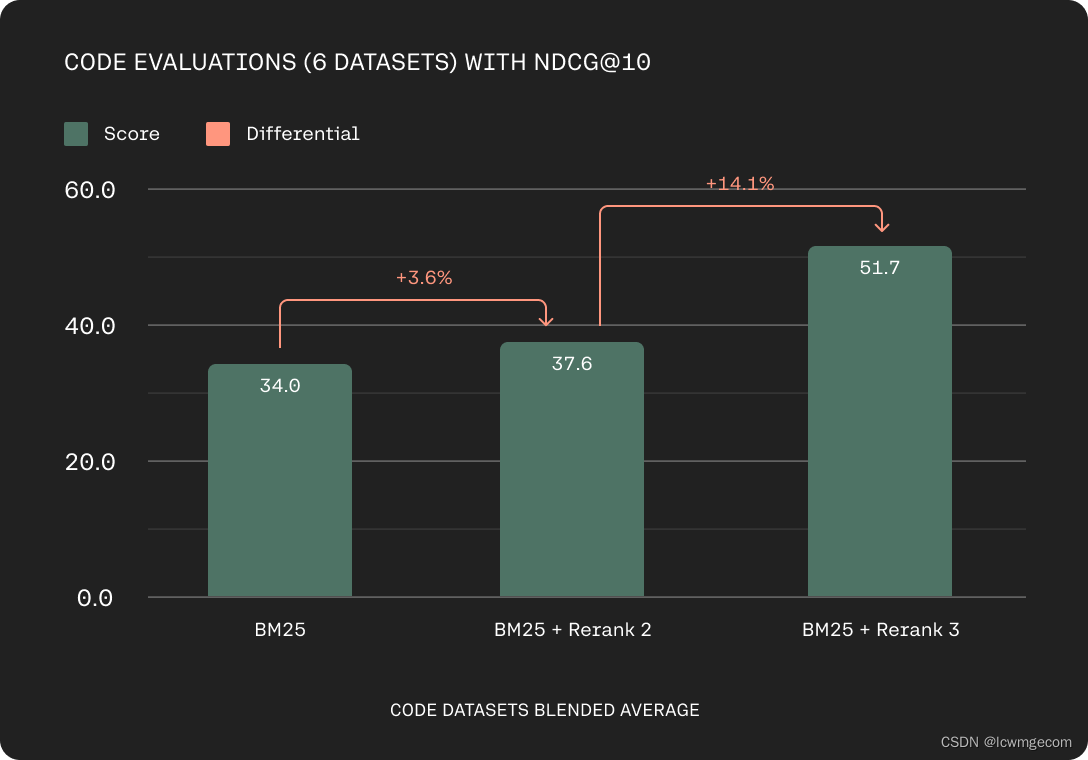
基于 Codesearchnet、Stackoverflow、CosQA、Human Eval、MBPP、DS1000 上的 nDCG@10 的代码评估准确性(越高越好)。
全球组织还处理多语言数据源,并且历史上多语言检索一直是基于关键字的方法的挑战。 我们的 Rerank 3 模型在 100 多种语言中提供强大的多语言性能,简化非英语客户的检索。
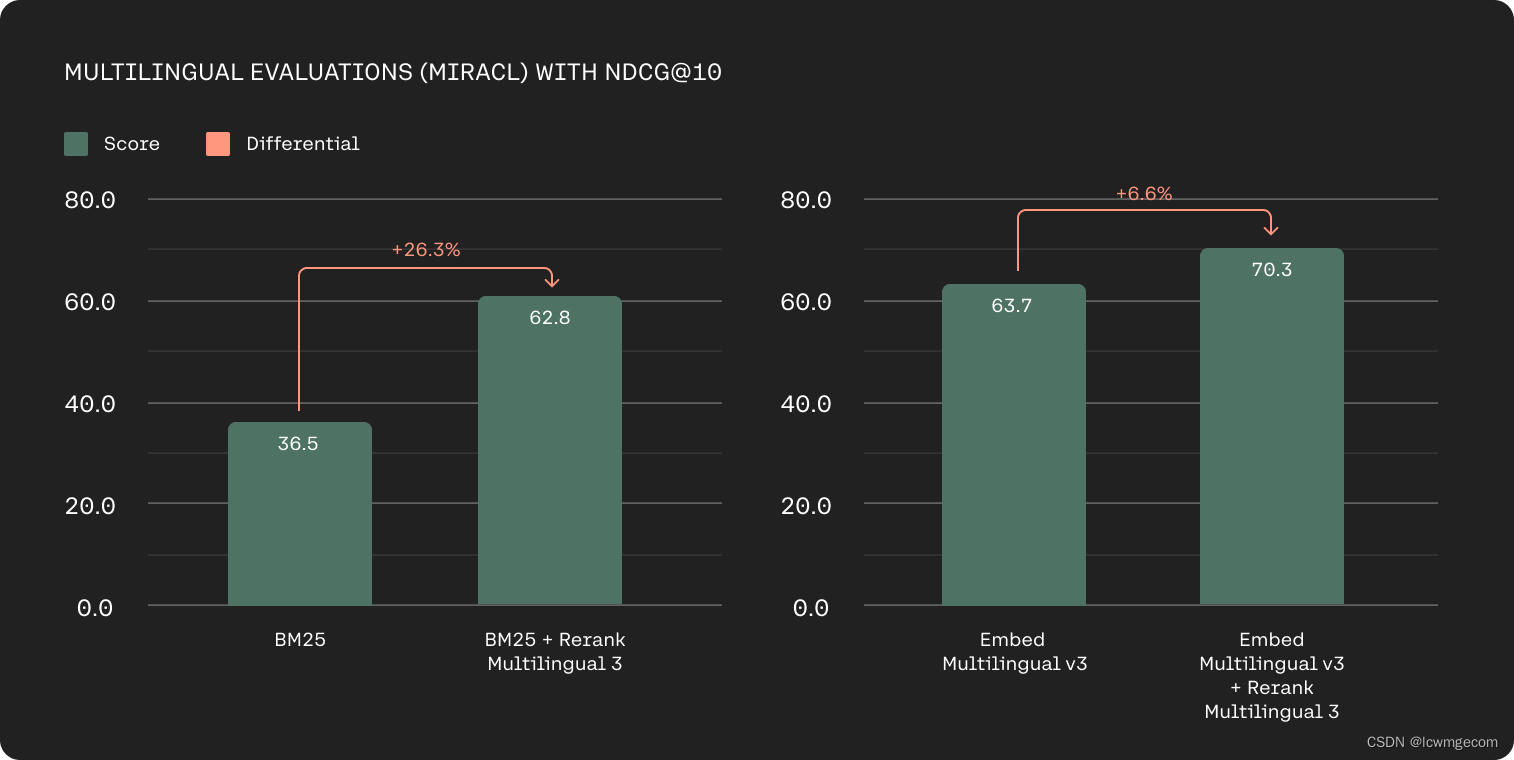
基于 MIRACL 上的 nDCG@10 的多语言检索准确率(越高越好)。
构建语义搜索和 RAG 系统时的主要挑战是确定如何最好地对数据进行分块。 我们的 Rerank 3 模型现在拥有 4k 上下文长度,允许客户传递更大的文档进行排名。 这使得我们的模型在确定相关性分数时可以考虑文档中的更多上下文,并减少为了适应模型的上下文窗口而对文档进行分块的需要。
长上下文准确度基于 TREC 2019-2022、Conditional QA、NQ-Hard、Qasper、Genomics、QMSum、FinanceBench 上的 nDCG@10(越高越好)。
从今天开始,Elastic 的 Inference API 原生支持 Rerank 3。 Elasticsearch拥有广泛采用的搜索技术,Elasticsearch平台中的关键字和向量搜索功能是为了处理复杂的企业数据而构建的。 要开始使用 Cohere 和 Elastic 构建企业搜索系统,请在此处查看最新指南。
即使上下文较长,也能改善延迟
在电子商务或客户服务等许多业务领域,低延迟对于提供优质体验至关重要。 在构建 Rerank 3 时牢记了这一点,与 Rerank 2 相比,对于较短的文档长度,延迟降低了 2 倍,对于较长的上下文长度,延迟提高了 3 倍。

比较计算为对各种文档标记长度配置文件中的 50 个文档进行排名的时间; 每次运行均假设一批 50 个文档,每个文档的标记长度均一致。
性能更高、效率更高的 RAG
检索步骤在 RAG 中至关重要。 Rerank 3 支持强大 RAG 性能的关键因素:响应质量和延迟。 模型可帮助您隔离最相关的文档来回答用户的问题,并提高整个 RAG 系统的响应准确性。 这使得大型企业能够从其专有数据中释放巨大价值,并获取相关信息来支持客户支持、法律、人力资源、财务等一系列业务职能中的任务。

(左)无需重新排序的检索增强生成工作流程。 文档从现有的搜索系统中检索,并直接传递给法学硕士进行接地生成。 (右)使用 Rerank 检索增强生成工作流程。 从现有搜索系统检索文档并直接传递到 Rerank。 高精度语义重新排序允许将更少、更高质量的文档传递给法学硕士进行接地生成。
当与高效的 RAG Command R 系列模型相结合时,Rerank 3 进一步降低了客户的总拥有成本 (TCO)。 在 RAG 系统中添加 Rerank 可以让用户将更少、更相关的文档传递给 LLM 进行基础生成,同时保持整体准确性且不会增加延迟。 其最终效果是,在 Command R+ 上运行带有 Rerank 的 RAG 比市场上其他生成式 LLM 便宜 80-93%,并且使用 Rerank 和 Command R 可以节省高达 98% 的费用。

独立成本基于 1M RAG 提示的推理成本,其中包含 50 个文档,每个文档包含 250 个令牌,以及 250 个输出令牌。 Rerank 的成本基于 1M RAG 提示的推理成本,其中包含 5 个文档,每个文档 250 个令牌,以及 250 个输出令牌。
RAG 越来越常见的方法是使用 LLM 作为文档检索的重新排序器。 Rerank 3 在排名准确性方面优于行业领先的法学硕士,同时成本便宜 90-98%。

准确度基于 TREC 2020 数据集上的 nDCG@10(越高越好)。 法学硕士按照 RankGPT 中使用的方法以列表方式进行评估(Sun 等人,2023)。
Rerank 3 不仅有助于降低端到端 TCO,还提高了 LLM 响应的质量。 重新排序通过剔除不太相关的文档并仅对一小部分相关文档进行排序来得出答案来实现这一点。
如何开始
从今天开始,开发人员和企业可以在 Cohere 托管的 API 和AWS Sagemaker 上访问 Rerank 3。 您还可以直接通过 Elasticsearch 中的推理 API 访问模型,对现有 Elasticsearch 索引执行语义重新排名。
通过 JSON 搜索
Rerank 3 引入了搜索以 JSON 表示的半结构化数据的选项。 您可以简单地获取 JSON 文档,例如 来自 Elasticsearch 或 MongoDB,并将其传递给 Rerank 3 模型。 通过设置排名字段,您可以选择模型应考虑哪些字段进行排名。

以下代码片段演示了电子邮件搜索的情况:
# Make sure to have the newest Cohere SDK installed:
# pip install -U cohere
# Get your free API key from: www.cohere.com
import cohere
cohere_key = "<<YOUR_API_KEY>>"
co = cohere.Client(cohere_key)
# Lets define some JSON with our documents. Here we use a JSON to represent emails
# with different fields. In the call to co.rerank we can specify which
emails = [
{
"from": "Paul Doe <paul_fake_doe@oracle.com>",
"to": ["Steve <steve@me.com>", "lisa@example.com"],
"date": "2024-03-27",
"subject": "Follow-up",
"text": "We are happy to give you the following pricing for your project."
},
{
"from": "John McGill <john_fake_mcgill@microsoft.com>",
"to": ["Steve <steve@me.com>"],
"date": "2024-03-28",
"subject": "Missing Information",
"text": "Sorry, but here is the pricing you asked for for the newest line of your models."
},
{
"from": "John McGill <john_fake_mcgill@microsoft.com>",
"to": ["Steve <steve@me.com>"],
"date": "2024-02-15",
"subject": "Commited Pricing Strategy",
"text": "I know we went back and forth on this during the call but the pricing for now should follow the agreement at hand."
},
{
"from": "Generic Airline Company<no_reply@generic_airline_email.com>",
"to": ["Steve <steve@me.com>"],
"date": "2023-07-25",
"subject": "Your latest flight travel plans",
"text": "Thank you for choose to fly Generic Airline Company. Your booking status is confirmed."
},
{
"from": "Generic SaaS Company<marketing@generic_saas_email.com>",
"to": ["Steve <steve@me.com>"],
"date": "2024-01-26",
"subject": "How to build generative AI applications using Generic Company Name",
"text": "Hey Steve! Generative AI is growing so quickly and we know you want to build fast!"
},
{
"from": "Paul Doe <paul_fake_doe@oracle.com>",
"to": ["Steve <steve@me.com>", "lisa@example.com"],
"date": "2024-04-09",
"subject": "Price Adjustment",
"text": "Re: our previous correspondence on 3/27 we'd like to make an amendment on our pricing proposal. We'll have to decrease the expected base price by 5%."
},
]
#Define which fields we want to include for the ranking:
rank_fields = ["from", "to", "date", "subject", "body"]
#To get all fields, you can also call: rank_fields = list(docs[0].keys())
# Define a query. Here we ask for the pricing from Mircosoft (MS).
# The model needs to combine information from the email (john_fake_mcgill@microsoft.com>)
# and the body
query = "What is the pricing that we received from MS?"
#Call rerank, pass in the query, docs, and the rank_fields. Set the model to 'rerank-english-v3.0' or 'rerank-multilingual-v3.0'
results = co.rerank(query=query, documents=emails, top_n=2, model='rerank-english-v3.0', rank_fields=rank_fields)
print("Query:", query)
for hit in results.results:
email = emails[hit.index]
print(email)
# Now we ask for the pricing from Oracle
query = "Which pricing did we get from Oracle"
#Call rerank, pass in the query, docs, and the rank_fields. Set the model to 'rerank-english-v3.0' or 'rerank-multilingual-v3.0'
results = co.rerank(query=query, documents=emails, top_n=2, model='rerank-english-v3.0', rank_fields=rank_fields )
print("Query:", query)
for hit in results.results:
email = emails[hit.index]
print(doc)搜索表格
关系数据库、CSV、Excel 等表格数据对许多企业起着至关重要的作用。 检索模型以前很难搜索此类数据,这限制了企业连接到最有价值的 RAG 数据源。
以下是使用嵌入模型搜索“克里斯蒂安·贝尔主演的动作电影”时的结果示例:

排名最高的结果是关于电影《战争》,这是一部动作片,但没有克里斯蒂安·贝尔。 Rerank 3 擅长表格数据搜索,从而显着改善搜索结果:

查看此“在表格数据上搜索”笔记本,了解 Rerank 3 如何将表转换为 JSON,然后在选定的列上进行搜索。















 4383
4383











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









