







身份证识别的项目,这是对项目的一个总结,如果身份证放的正的话,准确率有90+。
文章目录
前言
本项目基于Docker容器,后续模型部署需有Docker环境
提示:以下是本篇文章正文内容,下面案例可供参考
一、什么是关键信息抽取?
深度学习模型已经在OCR领域,包括文本检测和文本识别任务,获得了巨大的成功。而关键信息提取技术,作为OCR的下游任务,存在非常多的实际应用场景。使用人力来从这些文档中提取信息,是重复且费时费力的。如何通过深度学习模型来从文档图片中自动化地提取出关键信息成为一项亟待解决的挑战,受到学术界和工业界的广泛关注。
关键信息提取(KIE)是指从文本或图像中提取关键信息。作为OCR(光学字符识别)技术的下游任务,文档图像的关键信息提取任务具有许多实际应用场景,如表单识别、票务信息提取、身份证信息提取等。
二、OCR文本检测微调
1.安装标注工具,标注位置信息
点这里->官方安装链接:
(1)步骤一:安装PPOCRLabel
为了避免环境冲突,如果有安装anaconda的话,建议首先创建一个新的虚拟环境。,没有的话可以直接跳过这步,去步骤二
conda create -n ppocrlabel python=3.7
conda activate ppocrlabel
(2)步骤二:如果没有anaconda,直接输入如下指令安装
paddlepaddle 与 ppocrlabel,。若要采用ppocrlabel自带的自动标注功能,需要安装paddlepaddle-gpu。
#安装paddlepaddle
pip3 install --upgrade pip
# 若安装了cuda,运行以下命令安装
python3 -m pip install paddlepaddle-gpu -i https://mirror.baidu.com/pypi/simple
# 若采用cpu,运行以下命令安装
python3 -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
#Ubuntu Linux 安装ppocrlabel
pip3 install PPOCRLabel
pip3 install trash-cli
#Windows 安装ppocrlabel
pip3 install PPOCRLabel # 安装
(2)启动paddlelabel
# 选择标签模式来启动
PPOCRLabel --lang ch # 启动【普通模式】,用于打【检测+识别】场景的标签
PPOCRLabel --lang ch --kie True # 启动 【KIE 模式】,用于打【检测+识别+关键字提取】场景的标签
这边用于标注文本检测,采用 PPOCRLabel --lang ch
ch 为中文,–lang en 为英文
选择数据集文件位置后,先通过自动标注。标注完成后,再进行手动微调。
主要快捷键操作:
backspace: 删除框
A:上一张
D:下一张
Ctrl + X: --kie 模式下,修改 Box 的关键字种类
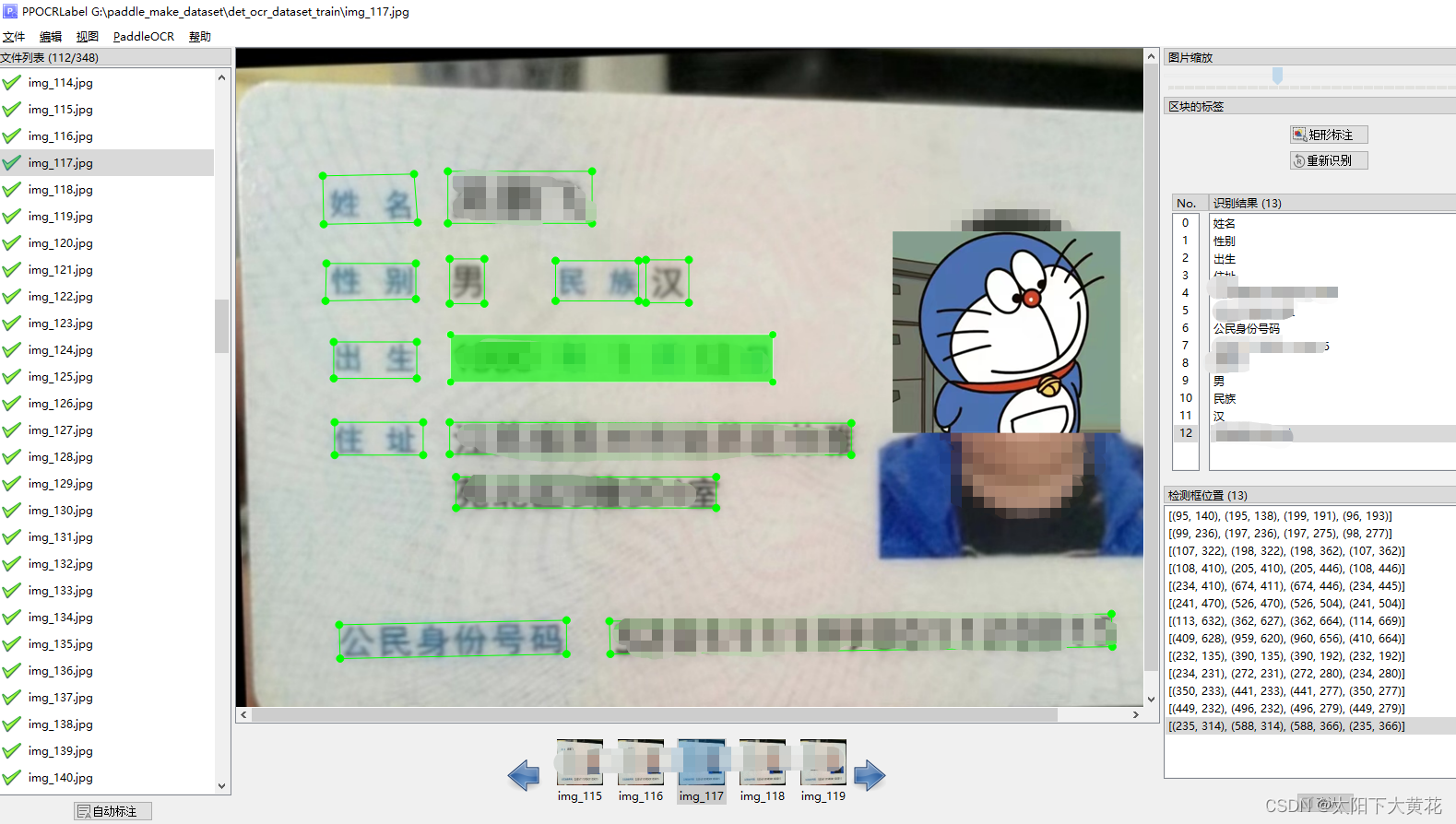
需要注意的是: 标注软件好像有点bug,会自动复制一遍表格,标注完返回检查下所有标注信息数量是否正确
错误如下,标注软件就多复制了一遍。

退出后会在该文件下会自动保存Label.txt文件
 v
v
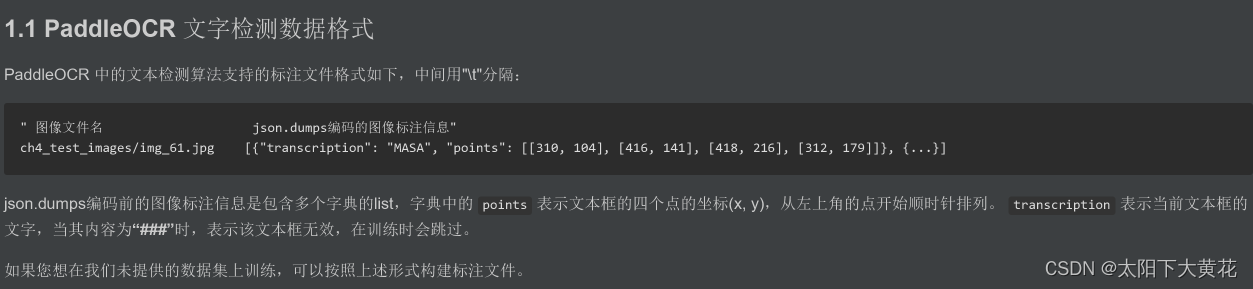
2.通过转换脚本,转换训练所需格式
该脚本可以将ppcorlabel生成的label.txt中内容,转为paddle ocr_detv3所支持的训练格式。
import json
# 文本检测格式转ocr_det格式
def det_trans(det_gt_file='./det_ocr_dataset_train/Label.txt', normalize_file='train_ocr_det_label.txt'):
file = open(det_gt_file, encoding='utf-8')
lines = ""
while True:
line = file.readline()
if not line:
break
image_path,ocr_info = line.split("\t")
ocr_infos = json.loads(ocr_info)
result = []
for i in ocr_infos:
single_dict = {
"transcription": i["transcription"],
'points': i['points'],
}
result.append(single_dict)
lines += image_path +"\t" +json.dumps(result, ensure_ascii=False) + "\n"
with open(normalize_file, 'w+', encoding='utf-8') as f2:
# file2.seek(0) # 移动指针到开头
f2.writelines(lines)
# 生成ocr_det可训练的格式
det_trans()
将训练集和验证集的图片全部标注后,并应用转换脚本,处理为如下顺序。
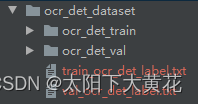
3.模型训练与预测
(1)下载paddleocr, 对运行环境配置
git clone https://github.com/PaddlePaddle/PaddleOCR.git
python -m pip install paddlepaddle-gpu==2.4.1.post112 -f https://www.paddlepaddle.org.cn/whl/linux/mkl/avx/stable.html
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
(2)下载文本检测模型的预训练模型
训练则是采用paddleocr里的推荐的DB模型。
首先下载模型backbone的pretrain model,PaddleOCR的检测模型目前支持两种backbone,分别是MobileNetV3、ResNet_vd系列,选MobileNetV3。
cd PaddleOCR/
wget -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/pretrained/MobileNetV3_large_x0_5_pretrained.pdparams

(3)修改v3的yml文件,我是重新新建了一个。det_mv3_dv_gai.yml (避免与原文件混淆)
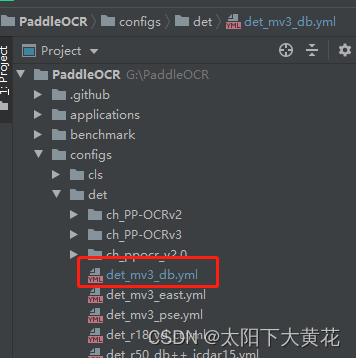
修改如下:
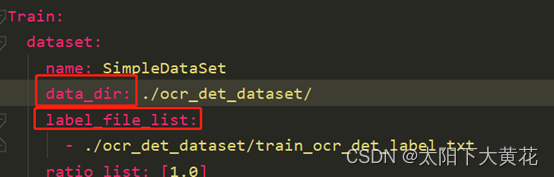
修改数据集中训练集的路径和需要的label.txt的路径。
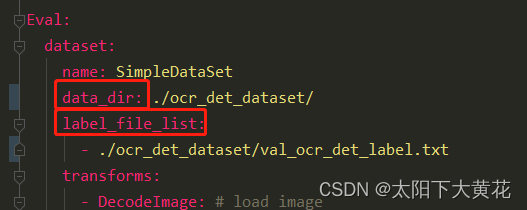
修改数据集中验证集的路径和需要的label.txt的路径。
(4)模型训练
#DB文本检测算法
#单卡直接训练 configs选择对应的yml文件,如果跟我一样重建文件,需对应更改
python3 tools/train.py -c configs/det/det_mv3_db.yml \
-o Global.pretrained_model=./pretrain_models/MobileNetV3_large_x0_5_pretrained
#单机多卡训练
python3 -m paddle.distributed.launch --gpus '0,1' tools/train.py -c configs/det/det_mv3_db.yml -o Global.pretrained 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1679
1679











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









