






语义通信

通信的三个级别:
Level A:语法通信,解决技术问题,即通信符号如何确保正确传输
Level B:语义通信,解决语义问题,即发送的符号如何传递确切的含义
Level C:语用通信,解决有效性问题,即接收的含义如何以期望的方式影响系统行为
长期以来,经典信息论局限在语法信息传输层次,即Level A。也就是说,我们一直在研究怎么把数据传过去。如今,在传统通信已经进入瓶颈的情况下,我们就可以考虑一下——是不是可以在语义通信上,寻找突破点。
语义通信的特点:
以任务为主体,“先理解,后传输”,对原始信号进行有选择的特征提取、压缩和传输,然后再利用语义层面信息进行通信。传统信源编码是对信息本身的压缩,他寻找数据的规律,通过算法进行数据精简;而语义通信重在“理解和消化”,讲究的是智能。
语义通信系统架构:
早期的一种模型,是在传统经典通信系统上叠加语义通信。在发送端,信源产生的信息首先送入语义提取模块,产生语义表征序列;接着,送入语义信源编码器,对语义特征压缩编码,然后送入信道编码器,最后进入传输信道。
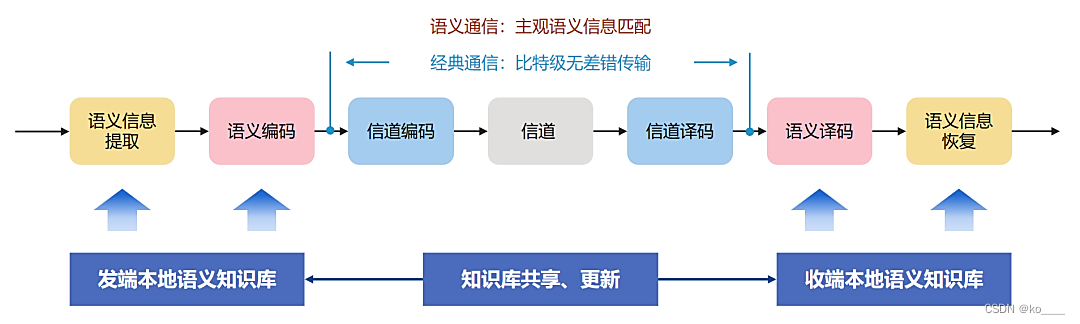
在接收端,先信道译码,再语义译码。得到的语义表征序列,送入语义恢复与重建模块,最终得到信源数据。
另一种现在比较有代表的模型,是信源信道联合编码,这种方式更有整体性。
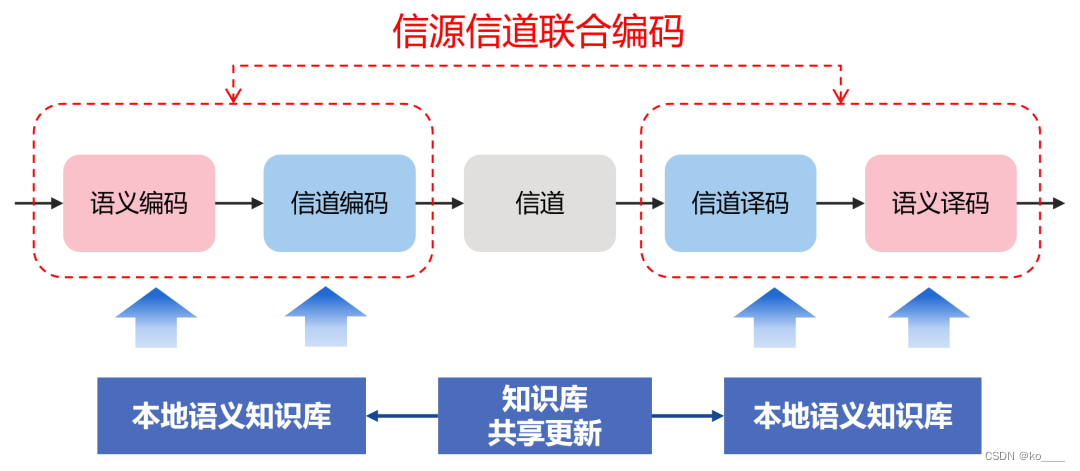
相比传统通信,语义通信多了一个知识库。系统模型的性能和准确性高度依赖于知识库,如果两端知识库不同,那么语义通信无法正常工作。基于知识库进行语义理解,就需要前面所说的“智能”。那显然AI人工智能最适合这份工作。
简单来说,就是让AI来完成语义理解的工作。语义编码与译码模块基于海量数据训练的知识库,通过深度学习网络来拟合语义的特征,可以高效提取和重建语义信息。
语义通信个人理解:
比如打电话,我说一段话,对方要知道表达的含义,这段话的内容可以作为公共部分,那么由谁说出来的,这就包含了用户的专有部分,类似于音色的特征。那我们可以用AI来进行模拟,就不再需要传递原始信号。
扩展:面向语义通信的模型划分多址接入
1G:时分多址 (TDMA)
2G:频分多址 (FDMA)
3G:码分多址 (CDMA)
4G:正交频分多址(OFDMA)
5G:非正交多址 (NOMA)
为进一步提高频谱效率,多址技术在功率域分配资源向非正交多址方向发展,每个用户的信息杯分配不同的功率然后叠加传输。在接收端,采用干扰消除技术来分离不同用户的信号。
6G:候选多址技术(RSMA)
速率分割多址接入,在发射端将发送消息拆分为两个部分,分别称为“专有部分”和“公有部分”,将“公有部分”合并为一个整体,与专有部分在相同的时频资源内传输,在接收端,每个用户除了解码由两部分组成的自己的消息外,还解码部分干扰。
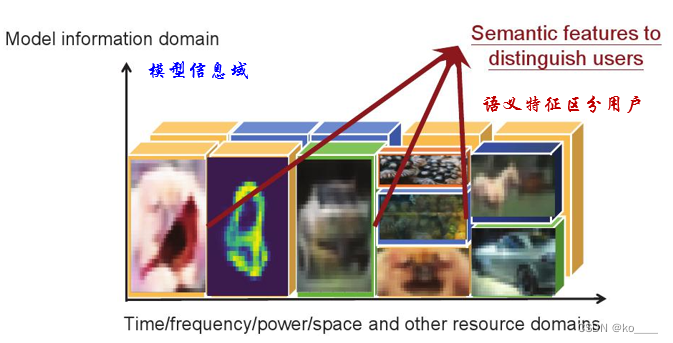
模分多址技术定义:
模分多址技术是一种基于语义域的多址技术,定义了名为模型信息空间的高维空间,皆在从模型信息空间中挖掘语义信息的共享信息和个性化信息,然后将共享信息的信号叠加复用,达到多址的效果,减少传输带宽。
从语义的角度,基于模型的人工智能方法从信号源中提取高维特征,并为信号源和信道特征构建模型信息空间。
MDMA ( Model Division Multiple Access ),一种新型MA方法,从更高的信息维度利用源语义域的特性,借助人工智能模型从信息源中提取语义特征,对用户的个性特征进行建模,以区分多用户语义信息。
结合传统物理和模型信息空间,信道容量可以表示为:
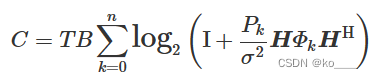
其中T、B、P、H和 ϕ![]() 分别表示时域资源、频域资源、功率域资源、空间域资源和模型信息空间资源,I为单位矩阵,σ2
分别表示时域资源、频域资源、功率域资源、空间域资源和模型信息空间资源,I为单位矩阵,σ2![]() 为噪声方差。
为噪声方差。
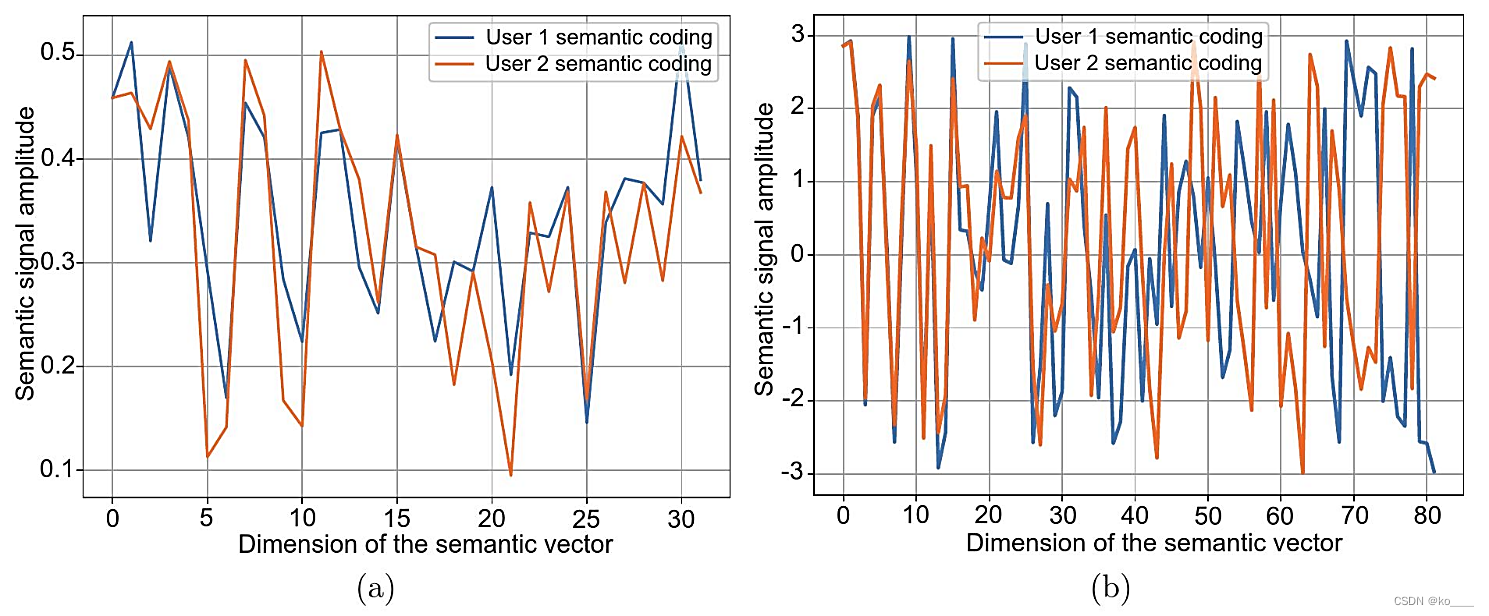
LSCI系统用于从MNIST和OpenImage数据集中提取语义信息。如图 (a) 所示,蓝色和橙色线分别表示用户1和用户2提取的不同图像相关语义信息集。我们观察到用户1和用户2的语义信息集非常相似,尽管信号图是从不同编号的图像中提取的;此外,振幅和相位只有微小的变化。图 (b) 显示了两个更复杂的图像的语义信号。在前30个维度中,两个信号之间存在显著的相似性。值得注意的是,在尺寸60–80中,信号振幅相似,但极性相反,这表明两个信号之间共享的信息量也是最小的。
为了进一步说明不同用户之间共享和个性化信息的存在,给出了从MNIST测试集中提取的每个语义特征维度的统计分布,如图所示。在红框中的统计分布表明,共享信息不是随机现象,而是普遍存在于某些特征维度上。
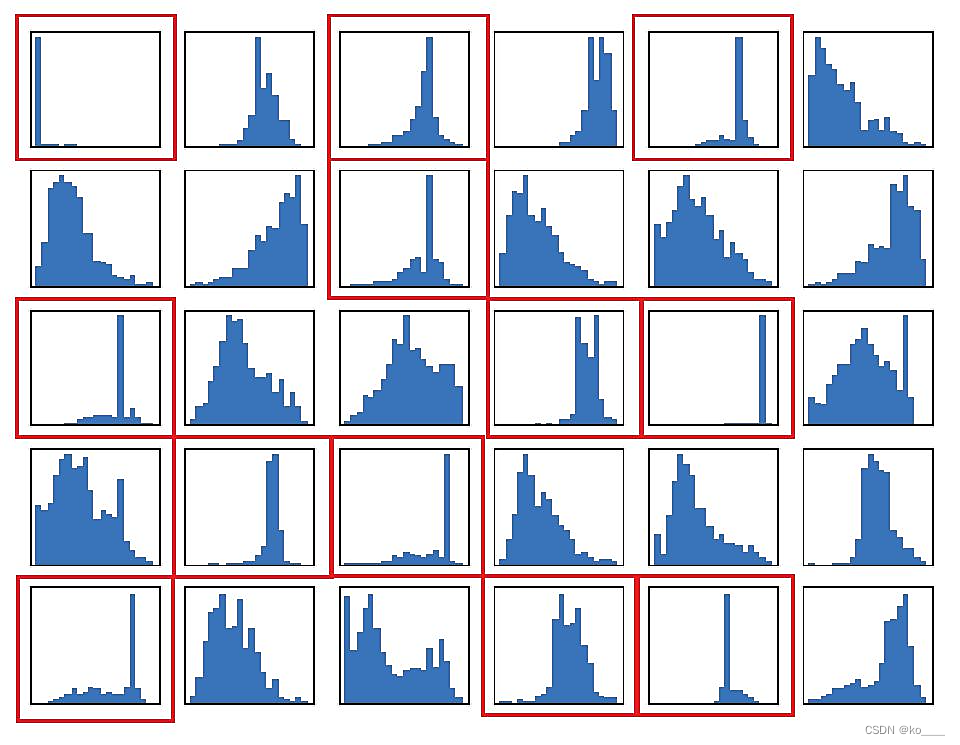
在多个用户的语义信号之间存在大量的共享信息。所提出的MDMA技术旨在利用这种共享信息来防止由于冗余传输而造成的带宽浪费。通过比较两个语义向量的每个维度的方差,并设置共性百分比的阈值,来提取公共信息。共享语义信息是在相同的时频资源内传输的,而个性化语义信息是单独传输的。与其他MA技术相比,MDMA的收益主要来自于模型信息空间中不同用户之间共享信息的重用。
基于MDMA的上行信道设计:
多个用户同时向基站传输语义信息的 上行场景。基站端使用无信息的解码器对原始信源 进行重构。首先,基站匹配两个已经发起上行传输指令的用户。用户1和用户2分别提取其源语义信息 Sx和Sy,具体如下:
![]()
其中Sx和Sy分别表示从X和Y中提取的语义信息。
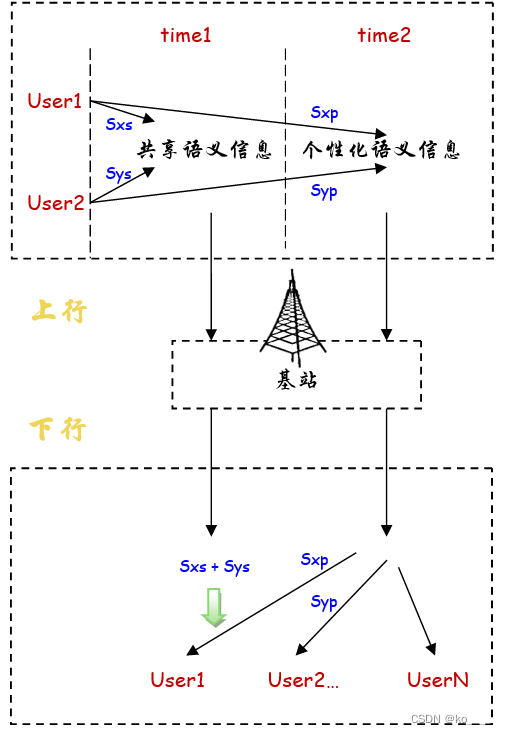
用户1和用户2在时间1(频率1)向基站发送共享语义信息Sxs+Sys。此后,用户1和用户2在时间2(频率2)向基站发送个性化语义信息Sxp和Syp。任意信道编码模块可以被配置为传输上述语义信息。在接收到来自用户1和用户2的共享和个性化信息后,基站可以恢复每个用户的原始语义信号,并使用语义解码器恢复信息源。
基于MDMA的下行信道设计:
下行链路设计,允许基站将来自多个源数据的语义信号同时分发给多个用户。首先,基站根据用户的需求,使用基于人工智能的语义模型搜索匹配用户并提取语义信息。通过比较两个语义特征之间的相似性,可以提取共享信息Sxs和Sys以及个性化信息Sxp和Syp。携带共享信息Sxs和Sys的信号被组合并一起发送,而携带个性化信息Sxp和Syp的信号被单独发送给用户。因此,用户1和用户2接收共享信息和他们自己的个性化信息,并且可以使用语义解码器来恢复原始图像X和Y。
论文简介
作者
Ping Zhang (张平) Xiaodong Xu (许晓东) Chen Dong (董辰) Kai Niu (牛凯)
发表期刊or会议
《Frontiers of Information Technology & Electronic Engineering》
发表时间
2023.6

















 1352
1352

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









