






补充说明一下 beam search,生成模型的目标如下式,
y
{
T
}
y^{\{T\}}
y{T}代表在目标语言端所有词可以排列组合生成的句子。
y
^
=
arg max
y
∈
{
v
{
T
}
}
p
θ
(
y
∣
x
)
\displaystyle{\widehat{y}=\underset {y\in\{v^{\{T\}}\}}{\operatorname {arg\,max} }}\, p_\theta(y|x)
y
=y∈{v{T}}argmaxpθ(y∣x)
这个式子也可以用如下公式等价表达(条件概率的链式法则):
p
θ
(
y
∣
x
)
=
∏
t
=
0
T
p
θ
(
y
t
∣
x
;
{
y
0
.
.
.
y
t
−
1
}
)
p_\theta(y|x)=\prod_{t=0}^{T}{p_\theta(y_t|x;\{y_0...y_{t-1}\})}
pθ(y∣x)=t=0∏Tpθ(yt∣x;{y0...yt−1})
以transformer模型为例,decoder部分最后接上的softmax层,输出的是
p
θ
(
y
t
∣
x
;
{
y
0
.
.
.
y
t
−
1
}
)
\displaystyle p_\theta(y_t|x;\{y_0...y_{t-1}\})
pθ(yt∣x;{y0...yt−1}),而前面的束中的hypothesis保存了
∏
t
=
0
T
−
1
p
θ
(
y
t
∣
x
;
{
y
0
.
.
.
y
t
−
1
}
)
\prod_{t=0}^{T-1}{p_\theta(y_t|x;\{y_0...y_{t-1}\})}
∏t=0T−1pθ(yt∣x;{y0...yt−1}),所以只需要把他们乘起来即可。因为前面的束大小是k,而每个时间步可能的
y
t
y_t
yt都有目标语言词表大小那么多,所以每次相乘都会得到一个
k
×
∣
V
t
∣
k\times|V_t|
k×∣Vt∣大小的概率矩阵,通过在这个二维矩阵中找到k个最大的值并进行排序,得到一个新的大小为k的beam。
Lexically Constrained Decoding for Sequence Generation Using Grid Beam Search
Chris Hokamp (2017) Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics
code:https://github.com/chrishokamp/constrained_decoding
提出了Grid Beam Search(GBS)方法,适用于通过最大化 ∏ t p { y t ∣ x ; { y 0 . . . y t − 1 } } \displaystyle\prod_t{p\{y_t|x;\{y_0...y_t-1\}\}} t∏p{yt∣x;{y0...yt−1}}生成序列的模型。词法约束可以是短语或单词。
伪代码如下:
def ConstrainedSearch(model, input, constraints, maxLen, numC, k):
'''
:param model:
:param input:
:param constraints: 二维约束集合(约束短语数,每个短语的词数)
:param maxLen:
:param numC: constraints中包含的token数量
:param k:
:return:
'''
startHyp = model.getStartHyp(input, constraints) # 生成开始的假设
Grid = initGrid(maxLen, numC, k) # 生成一个(maxLen,numC)的搜索空间,其中每个beam包含k个hyp
# t是timestep的索引,c表示当前beam中包含了多少个约束token
for t in range(1, maxLen):
# 当c<numC + t - maxLen 的时候,有一段空间可以用来generate
# 但达到numC + t - maxLen这个阈值的时候就必须开始生成约束,否则做不完约束要求
# 当前总共生成了t个词语,不可能已生成的约束比t多,也不可能生成超出约束表词数的约束数量
for c in range(max(0, numC + t - maxLen), min(t, numC)):
n, s, g = null
#每个hyp有两个状态 open和close,下面介绍
for hyp in Grid[t - 1][c]:
if (hyp.isOpen()):
g = g + model.generate(hyp, input, constraints)
if c > 0:
for hyp in Grid[t - 1][c - 1]:
if (hyp.isOpen()):
n = n + model.start(hyp, input, constraints)
else:
s = s + model.Continue(hyp, input, constraints)
h = n + s + g
Grid[t][c] = k - argmax(model.score(h))
# 从Grid最顶层截取,因为这些hyp有所有的约束词
topLevelHyps = Grid[:][numC]
# 检查这些满足约束的hyp有没有正确结束
finishedHyps = hasEOS(topLevelHyps)
# 选出最好的hyp返回
bestHyp = argmax(model.score(finishedHyps))
return bestHyp
hypothesis有两个状态,分别是
- open 在这个状态下既可以根据模型的输出结果选择下一步进入Generate,也可以根据还未生成的约束进入Start状态
- 只能进入Continue状态,生成未完成的约束项
每个hypothesis中维护一个覆盖数组,保证不会在start和continue的过程中生成重复的约束。
当想设定不连续的约束的时候,可以通过过滤器规则解决。譬如ask out,此时我们可以设定ask为 c o n s t r a i n t 0 constraint_0 constraint0,out为 c o n s t r a i n t 1 constraint_1 constraint1,定如下两条规则,要求 c o n s t r a i n t 1 constraint_1 constraint1不能在 c o n s t r a i n t 0 constraint_0 constraint0之前使用,另一个要求这两个约束之间必须至少有一个生成的token。
图示:

这个二维地图就是伪代码中提到的Grid,每个长方形是一个beam,其中有k个hypothesis。虚线的箭头指向右上,代表生成约束(因为越往上走就说明已生成的约束越多);实线箭头水平向右,代表正常的generate过程。最顶层的绿色方框包括的长方形,则是生成了所有约束的beam。

每个时间步的输出标记显示在图的顶部,包括封闭的约束盒子。每个hypothesis用不同颜色区分,生成以蓝色显示,绿色表示新约束,红色表示继续约束。用于在每个时间步创建hypothesis的函数写在底部。网格中的每个框表示一个beam;beam中的彩色条表示beam的k-best个hypothesis。有圆圈的假设是close的,所有其他假设都是open的。
时间复杂度是 O ( k t c ) O(ktc) O(ktc) ,k是束大小,t是时间步,c是约束的token数量。常规的束搜索自然是 O ( k t ) O(kt) O(kt)。
实验部分
1.机器翻译后期编辑互动周期。
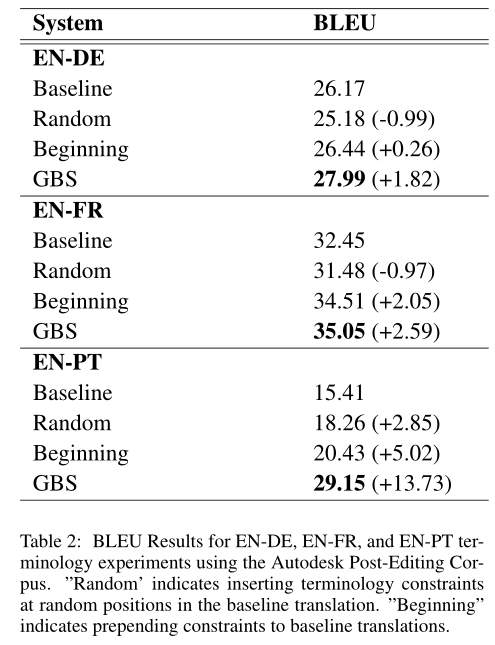
对于原始翻译假设(也就是无约束的时候),用户首先选择假设中不正确的部分,然后为输出的该部分提供正确的翻译。将用户提供的校正用作下一个解码周期的约束。拾取修改过程可以根据需要重复多次,假设用户只提供假设中缺失的最多三个单词的序列,每一轮迭代只增加一个最多三个词的短语约束,并且分别设置为硬约束(这个约束必须在上一轮假设中从没出现过),软约束(只要求缺少第一个单词)。下表显示了具有四个周期的模拟编辑会话的结果。当找不到三个标记短语时,我们退避到两个标记短语,然后退避到单个标记作为约束。如果假设已与引用匹配,则不添加任何约束。通过在每个循环中指定最多三个单词的新约束,所有语言对中的BLEU点数增加了20多个。

Results for four simulated editing cycles using WMT test data. EN-DE usesnewstest2013, EN-FR usesnewstest2014,
and EN-PT uses the Autodesk corpus discussed in Section4.2. Improvement in BLEU score over the previous cycle is shown
in parentheses. * indicates use of our test corpus created from Autodesk post-editing data.
2.通过术语进行域适配
KaTeX parse error: No such environment: align at position 8: \begin{̲a̲l̲i̲g̲n̲}̲ pmi(x,y)=&\log…
我们提取长度为2-5的所有n-gram作为候选术语。通过对源语言和目标语言做npmi,选取分数在0.9以上且出现次数大于5次的加入约束。
当在测试数据中观察到与术语匹配的源短语时,相应的目标短语将添加到该段的约束中。
3.实验了一下加入约数词,发现不仅仅是错误的词变正确了,全句翻译质量都提升了(就是和替换词语不相关的地方)
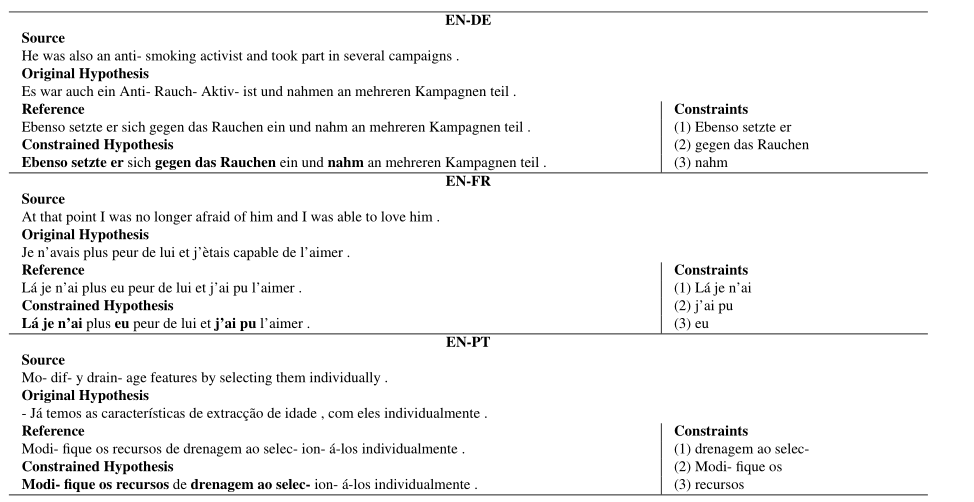
可以看到,加入约束后,生成的句子从第2行变成了第4行,和标黑地方无关的也翻译对了。
Fast Lexically Constrained Decoding with Dynamic Beam Allocation for Neural Machine Translation
Matt Post(2018) Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics
code:https://github.com/awslabs/sockeye
tutorial:https://awslabs.github.io/sockeye/inference.html#lexical-constraints

作者说GBS有如下两个问题
- 复杂度太高
- 本质上GBS的工作,其实是相当于给beam多加了一个维度,在面对不同句子的decoding的时候,beam大小会改变(因为约束不同了)。而大多数解码器在模型加载时指定波束大小,以优化计算图,特别是在GPU上运行时。GBS还使提高吞吐量的波束搜索优化(如批处理)复杂化。
DBA解决了这两个问题,和GBS不同的地方在于,GBS是乘上了约束的数量,但是DBA是给定一个固定的beam size,然后用除法分配beam到各个约束组里去。
给了俩定义,其实和GBS差不多,一个是 word constrain,一个来源于目标语言词表的token;一个是 phrasal constrain,是两个或更多的连续单词(也包含被子词切分的)。比如 high-ranking member或者 thou@ @ ghtful 。
DBA只是修改了Algorithm 1的 KBEST 函数

有俩问题需要考虑
- 生成一组候选集合(考虑了约束的),而不是像beam search一样直接找KBEST
- 通过约束组分配beam。对于固定大小的beam和任意数量的约束,我们需要找到一种分配策略,以便将beam划分到约束组中。
第一个问题的解决思路:

最左侧的是时间t的beam,其中的每行各种图案表示了约束,填充是满足约束,轮廓是未满足约束。蓝色的方块表示长度为2的phrasal constraint,必须按顺序完成(先生成左半边,再生成右半边)。中间是解码器中的一个步骤(algorithm 1 中的 DECODE-STEP)生成 k × ∣ V t ∣ k\times|V_t| k×∣Vt∣大小的score矩阵,每一个约束对应着目标语言词表的一个单词,被标注在了score矩阵的底部。灰色的方块表示生成的候选集合,规则有:K-BEST( ⋆ \star ⋆),生成一个未完成的约束( → \rightarrow →),和每一句话中也就是每一行中最高分数的一项( ◊ \Diamond ◊)。有些项目中包含了( ↺ \circlearrowleft ↺)符号,这个符号只出现在已经部分开始生成phrasal constraint的假设行中,比如(2,3)中,他的意思是把已经生成的蓝色方块约束的左半部分视为非约束(也就是把他的约束情况变得像右侧的(1,3)一样),这是为了防止约束中的前缀和想生成的话的前缀冲突,比如说“我喜欢你”(这是个约束)和“我讨厌你”,开头的我重复了,但是模型可以决定生成 喜或者讨字,在生成讨字的这个item中,就得擦除 “我”在已满足约束里的标记。最右侧的结果讲完第二个问题再说。
第二个问题的解决思路:
给个定义,我们用 bank 来表示为满足相同数量约束的项目保留的beam部分(包括满足零约束的假设的一组)。那么任务就是要把K个beam分散给C+1个约束 bank,C可能比K大。用一个最简单的策略,就是均分这些beam,每个bank可以分到[k/C]个beam,如果还有剩下的,就全部分给约束数量最多的组。如下图所示
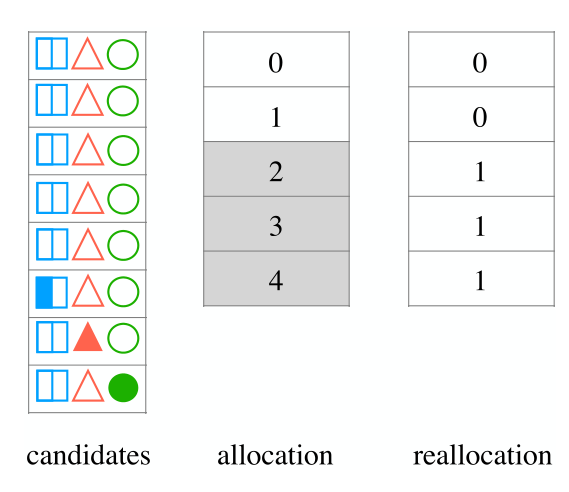
这个图中,左侧的candidates里只满足了0个约束(比如第1至第5个候选项)或1个约束(比如第6,7,8个候选项)。中间的是5个beam,他们一开始是均分给全部约束组的,灰色的部分没有出现在候选组里,所以重新进行分配后,他们被平均分配给0约束组和1约束组。还剩下一个多的beam,因为1约束组比0约束组约束数量更多,所以给他多分一个beam,就形成了2个分给0,3个分给1的beam分配结果。
更详细一点说,还存在如下两种可能,那就是beam分配过多(比如0约束组可能只有一个候选项,但是分配了两个beam给它),比如2组分配过多,他会看看3组有没有缺少beam,如果有就把多的给3组,否则逐次向更多约束的组检查。beam分配过少,那没办法了,按优分配吧。
回头看看第一个问题图Figure 1中,候选组确认的最右侧部分,因为候选集合里的约束分布是0,1,2,3,4刚好5个beam,那就一人一个,在每个约束数量的候选集中选出分数最多的,就是结果。
最后,不允许没生成完全部约束的句子生成结束标记EOS,从完成约束正常结束的句子里选择分数最高的返回,算法如下图:

输入是score矩阵,第一句先从hyp的假设中获取一个二维数组constraints(beamSize x 每个beam里包含的词),第二句是先把topK分数的加入候选集中,候选集是一个三元组,里面存放着score矩阵里的行标,列标和constraints[]。然后再把未满足约束加入candidate,再把每句话最好的结果加入,然后分配beam,最后把选择的候选集加入新的beam中。
这里有个小问题,constraints数组我一开始以为是约束词组,但是其实是全部的词语,因为topk和best single word加入的词不一定在约束里。
Training Neural Machine Translation To Apply Terminology Constraints
Dinu et al. ACL 2019 短文
code :none
dataset:https://github.com/mtresearcher/terminology_dataset
除了一些在解码时期修改beam search的工作,这个工作提出了怎么在训练时期解决融入术语约束的问题。
我的建议是不要读这篇,你将浪费生命中宝贵的?个小时。
但是比较有意思的事情是,他让我想起了蔡登的那篇单语翻译记忆的工作,如果可以把 每个术语约束看成一个翻译记忆,然后把他们的relevance score都设成统一值,然后把 λ t \lambda_t λt设置的很大,是不是也是一个可行的方案。















 1190
1190











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









