







CVPR2020论文笔记:Two-Stage Peer-Regularized Feature Recombination for Arbitrary Image Style Transfer
概述
本文介绍一种神经风格迁移模型,所提出方案即使在零样本设置下也可以产生高质量的图像,且在更改内容几何形状时具有更大的自由度。通过引入Two Stage Peer-Regularization(TSPR) Layer,图卷积层将潜空间中的风格和内容重新组合在一起。与绝大多数现有方法不同,模型不依赖于任何预训练网络来计算感知损失,且直接在潜在空间进行循环损失优化。

主要贡献
- 提出了使用自定义的图卷积层,直接在隐空间(latent space)进行样式和内容的组合
- 提出了一个新的组合损失,从而能够进行端到端的训练,并且无需任何预训练好的模型(如VGG)来进行损失计算
- 通过度量学习(metric learning)构建出全局和局部结合以及内容和风格分离的隐空间
方法
-
通过度量学习将风格和内容信息在隐空间中分离,使得Decoder中保留的风格信息量大大减少。此外,为了充分考虑绑定某种风格之后对于内容的几何结构变化,加入了一个两阶段的风格转换模块,第一阶段只进行风格转换,第二阶段再进行相应内容几何结构的修改
-
整体架构图

-
xi,xt,xf分别表示内容图,风格图,fake图像。zi表示由xi经过Encoder编码得到的latent code,同时**(zi)c和(zi)s**分别表示latent code中的内容部分和风格部分
-
两个latent code之间的距离函数f定义如下

-
Encoder:由几个下采样的卷积层和多重ResNet block组成,生成的latent code为z,由(z)c(包含物体、位置、大小等内容信息)和(z)s(包含层次细节、形状等风格信息)两部分组成,并且再对(z)s均等分为
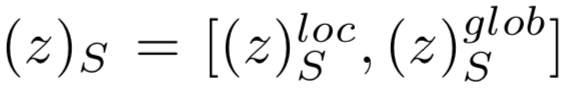
glob可以理解为是对zs的一个进一步下采样的生成结果(通过一个小的子网络下采样),采样结果为对于每一个channel对应的feature map而言,下采样到一个值,也即zs^glob
为N维向量(假设有N个channel) -
辅助Decoder:它的唯一作用是用来训练Encoder模块,包含以下几个loss
1. 内容特征cycle loss(用来将latent code表示相同内容的zc聚合在一起)
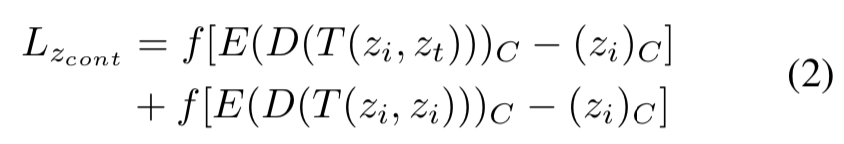
第一项表示要让内容图code和风格图code经过TPFR模块融合后得到的迁移图的code和原始内容的code越接近越好
第二项表示内容图code和内容图code经过TPFR融合后的结果图code与原始内容图code越接近越好(这一项loss的目标是让Encoder得到的z能够将内容 latent code聚合为zc,在z的上半部分)
2. 度量(metric learning)学习loss(度量学习的目的是通过训练和学习,减小或限制同类样本之间的距离,同时增大不同类别样本之间的距离。
)

第一项减小内容图样本之间的风格图的风格code之间的距离,同时增加内容图以及风格图之间的风格code的距离
3.辅助Decoder的重构损失
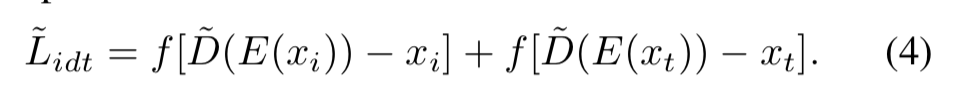
4.latent cycle loss:保证输入的latent code和重构图像的latent code一致

5.辅助Decoder总loss

下面实验提到选择了25作为λ的值进行训练 -
Main Decoder:其初始结构直接复制上面的辅助Decoder,其输入是TPFR的输出code,且训练这个Main Decoder时要固定Encoder不改变。有以下三个loss:
1.Decoder adversarial loss(对抗损失)

目的就是要提高生成的图(fake)的判别分数C(xf),其中C是判别器当生成的fake图和真实风格图的风格越像,那么分数就越高。
2.transfer latent cycle loss:为了让风格化之后的图能够既保留内容图的latent code(zc部分)又能够保留风格图的latent code(zs部分)
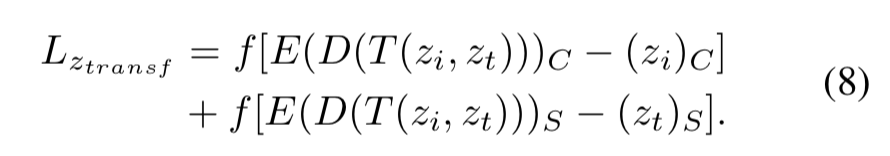
3.和训练辅助Decoder一样的重构损失
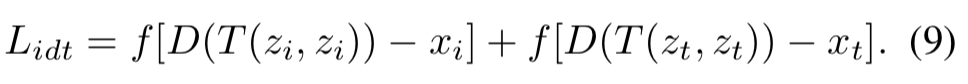
4.总的Main Decoder损失

-
判别器:判别器的输入是两个图片在channel方向的连接,当两个图片有同样的风格类别的话,那么判别风格最高为1,否则为0
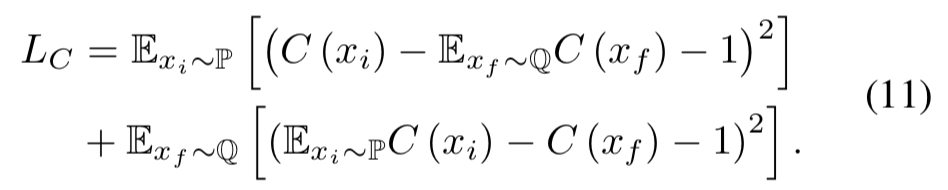
-
Two-stage Peer-regularized Feature Recombination (TPFR)模块

TPFR模块的输入是
和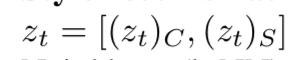
latent code zi或者zt均为HWxN维的,也就是N个channel,每一个channel都是列向量,每一个列向量长度均为HW=d维
1:Style重组
用欧式距离计算内容code部分的k近邻
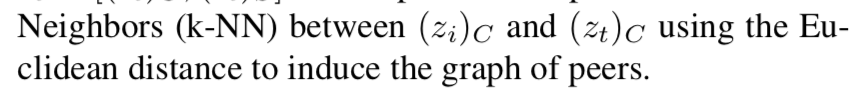
输出的结果为
可以看出这一阶段zout的content部分的code是直接采用的输入的内容图的内容code,只对于zout的style 部分的code进行的合成转化。合成的公式为
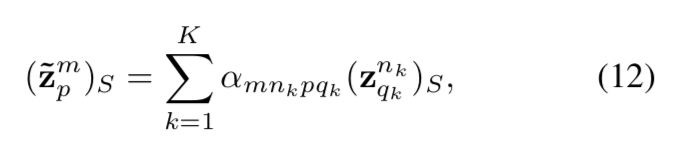
其中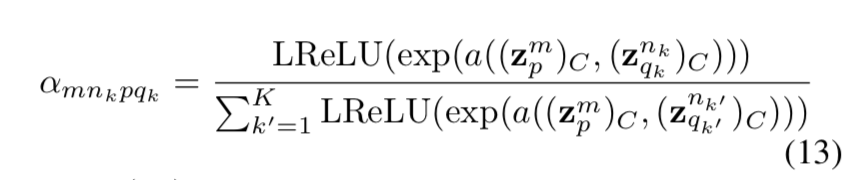
即引入了一个图注意力机制,基于内容图和风格图的latent code 的内容code部分进行k近邻计算(我的理解是计算对于内容图的latent code (zi)c中的每一个channel,都计算出了风格图的latent code (zt)c中K近邻的K个channel,即在风格图的latent code zt中那几个channel中的内容code同内容图当前遍历到的channel的内容code类似(表明某一种内容特征类似),那么就优先依次考虑将风格图latent code的这一个channel对应的style code加入更大注意力,即对于最终(zout)s有更大的影响,只考虑K近邻的K个channel的style code的影响)

2:Content重组
和上面Style重组过程完全一样,只是将Style 和Content部分交换计算而已
实验
-
训练过程
通过总的如下损失
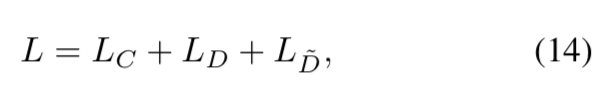
交替的对编码器,辅助解码器,主解码器以及判别器进行端到端的迭代优化训练 -
实验证明不仅对于已经训练集中见过的风格样式有很好的迁移效果,对于训练过程中从没见过的风格样式也有很好的迁移效果(Zero-shot)

-
消融分析:分析了每一步操作对于结果的影响,即每次去除掉一种操作,看效果是否有所损伤

结论
本文提出了一种新型的风格迁移网络,不仅能够高效实现多种风格的迁移,还能够实现Zero-shot迁移(即在没有见过的风格中进行迁移),引入的辅助Decoder有效的防止了训练的退化失败。可以进行端到端的训练,而不需要依赖于现有的预训练好的模型(如VGG)来计算损失,因此解除了对于这些模型提取到的特征的可靠性的依赖。















 523
523











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









