







近期出去面试Java的总结
- 一、Java基础
- 1、Java的类加载顺序
- 2、Java的创建对象的几种方式
- 3、java的基础数据类型
- 4、Java中的CAS
- 5、HashSet是如何实现的
- 6、你了解迭代器吗?说一说是如何使用的?
- 7、JVM内存是如何划分
- 8、Java的容器有哪些
- 9、常用的时间类
- 10、Java动态代理
- 11、自动装箱和拆箱
- 12、Java Lambda 表达式应用场景
- 13、JDK1.7和JDK1.8有什么差别
- 14、Java中Synchronized的用法
- 15、Java类加载过程
- 16、static关键字的作用
- 17、Java几种集合基本实现与应用场景
- 二、集合相关的问题
- 二、多线程相关的问题
- 三、Spring相关的问题
- 四、Spring boot和Spring Cloud相关
- 五、sql相关
- 五、Redis相关
- 六、消息队列相关的问题
- 七、git命令的使用
- 八、docker相关
- 九、Linux命令
- 十、前端
- 十一、关于项目
- 十二、设计模式
- 十三、Nginx相关
- 十四、应用相关
一、Java基础
1、Java的类加载顺序
面试官问:“class A和class B,其中class A中有静态方法和构造函数,class B中也有静态方法和构造函数,class A为父类,class B为子类,请问他们的加载顺序如何?”
对于有继承关系的加载顺序
关于关键字static,大家 都知道它是静态的,相当于一个全局变量,也就是这个属性或者方法是可以通过类来访问,当class文件被加载进内存,开始初始化的时候,被static修饰的变量或者方法即被分配了内存,而其他变量是在对象被创建后,才被分配了内存的。
所以在类中,加载顺序为:
- 首先加载父类的静态字段或者静态语句块
- 子类的静态字段或静态语句块
- 父类普通变量以及语句块
- 父类构造方法被加载
- 子类变量或者语句块被加载
- 子类构造方法被加载
详细可见:
Java的类加载顺序
2、Java的创建对象的几种方式
1、使用new关键字
这是我们最常见的也是最简单的创建对象的方式,通过这种方式我们还可以调用任意的构造函数(无参的和有参的)。
User user = new User();
2、使用反射机制
运用反射手段,调用Java.lang.Class或者java.lang.reflect.Constructor类的newInstance()实例方法。
1)使用Class类的newInstance方法
可以使用Class类的newInstance方法创建对象。这个newInstance方法调用无参的构造函数创建对象。
//创建方法1
User user = (User)Class.forName("根路径.User").newInstance();
//创建方法2(用这个最好)
User user = User.class.newInstance();
2)使用Constructor类的newInstance方法
和Class类的newInstance方法很像, java.lang.reflect.Constructor类里也有一个newInstance方法可以创建对象。我们可以通过这个newInstance方法调用有参数的和私有的构造函数。
Constructor<User> constructor = User.class.getConstructor();
User user = constructor.newInstance();
这两种newInstance方法就是大家所说的反射。事实上Class的newInstance方法内部调用Constructor的newInstance方法。
3、使用clone方法
无论何时我们调用一个对象的clone方法,jvm就会创建一个新的对象,将前面对象的内容全部拷贝进去。用clone方法创建对象并不会调用任何构造函数。
要使用clone方法,我们需要先实现Cloneable接口并实现其定义的clone方法。
Employee emp4 = (Employee) emp3.clone();
4、使用反序列化
序列化与反序列化实现方式:序列化的对象所对应的类必须实现Serializable接口或Externalizable接口;
Serializable接口序列化举例:Serializable接口是一个标记接口,不用实现任何方法。一旦实现了此接口,该类的对象就是可序列化的;当然还有Externalizable接口序列化方式,详细的情况另行介绍;- 反序列化:从IO流中恢复对象;
详细可见:
Java的创建对象的几种方式
3、java的基础数据类型
Java语言提供了八种基本类型。六种数字类型(四个整数型,两个浮点型),一种字符类型,还有一种布尔型。
byte:
byte 数据类型是8位、有符号的,以二进制补码表示的整数;
最小值是 -128(-2^7);
最大值是 127(2^7-1);
默认值是 0;
byte 类型用在大型数组中节约空间,主要代替整数,因为 byte 变量占用的空间只有 int 类型的四分之一;
例子:byte a = 100,byte b = -50。
short:
short 数据类型是 16 位、有符号的以二进制补码表示的整数
最小值是 -32768(-2^15);
最大值是 32767(2^15 - 1);
Short 数据类型也可以像 byte 那样节省空间。一个short变量是int型变量所占空间的二分之一;
默认值是 0;
例子:short s = 1000,short r = -20000。
int:
int 数据类型是32位、有符号的以二进制补码表示的整数;
最小值是 -2,147,483,648(-2^31);
最大值是 2,147,483,647(2^31 - 1);
一般地整型变量默认为 int 类型;
默认值是 0 ;
例子:int a = 100000, int b = -200000。
long:
long 数据类型是 64 位、有符号的以二进制补码表示的整数;
最小值是 -9,223,372,036,854,775,808(-2^63);
最大值是 9,223,372,036,854,775,807(2^63 -1);
这种类型主要使用在需要比较大整数的系统上;
默认值是 0L;
例子: long a = 100000L,Long b = -200000L。
"L"理论上不分大小写,但是若写成"l"容易与数字"1"混淆,不容易分辩。所以最好大写。
float:
float 数据类型是单精度、32位、符合IEEE 754标准的浮点数;
float 在储存大型浮点数组的时候可节省内存空间;
默认值是 0.0f;
浮点数不能用来表示精确的值,如货币;
例子:float f1 = 234.5f。
double:
double 数据类型是双精度、64 位、符合IEEE 754标准的浮点数;
浮点数的默认类型为double类型;
double类型同样不能表示精确的值,如货币;
默认值是 0.0d;
例子:double d1 = 123.4。
boolean:
boolean数据类型表示一位的信息;
只有两个取值:true 和 false;
这种类型只作为一种标志来记录 true/false 情况;
默认值是 false;
例子:boolean one = true。
char:
char类型是一个单一的 16 位 Unicode 字符;
最小值是 \u0000(即为0);
最大值是 \uffff(即为65,535);
char 数据类型可以储存任何字符;
例子:char letter = ‘A’;。
参考:
Java 基本数据类型
4、Java中的CAS
1 CAS是如何保证原子性
CAS是英文单词CompareAndSwap的缩写,中文意思是:比较并替换。CAS需要有3个操作数:内存地址V,旧的预期值A,即将要更新的目标值B。
CAS指令执行时,当且仅当内存地址V的值与预期值A相等时,将内存地址V的值修改为B,否则就什么都不做。整个比较并替换的操作是一个原子操作。
扩展
1)CAS的缺点:
CAS虽然很高效的解决了原子操作问题,但是CAS仍然存在三大问题。
- 循环时间长开销很大。
- 只能保证一个变量的原子操作。
- ABA问题。
1.1)循环时间长开销很大
CAS 通常是配合无限循环一起使用的,我们可以看到 getAndAddInt 方法执行时,如果 CAS 失败,会一直进行尝试。如果 CAS 长时间一直不成功,可能会给 CPU 带来很大的开销。
1.2)只能保证一个变量的原子操作
当对一个变量执行操作时,我们可以使用循环 CAS 的方式来保证原子操作,但是对多个变量操作时,CAS 目前无法直接保证操作的原子性。
但是我们可以通过以下两种办法来解决:
- 使用互斥锁来保证原子性;
- 将多个变量封装成对象,通过 AtomicReference 来保证原子性。
1.3)什么是ABA问题?ABA问题怎么解决?
如果内存地址V初次读取的值是A,并且在准备赋值的时候检查到它的值仍然为A,那我们就能说它的值没有被其他线程改变过了吗?如果在这段期间它的值曾经被改成了B,后来又被改回为A,那CAS操作就会误认为它从来没有被改变过。这个漏洞称为CAS操作的“ABA”问题。
Java并发包为了解决这个问题,提供了一个带有标记的原子引用类“AtomicStampedReference”,它可以通过控制变量值的版本来保证CAS的正确性。因此,在使用CAS前要考虑清楚“ABA”问题是否会影响程序并发的正确性,如果需要解决ABA问题,改用传统的互斥同步可能会比原子类更高效。
参考:
面试必问的CAS,你懂了吗?
2 AQS了解吗
AQS核心思想是,如果被请求的共享资源空闲,那么就将当前请求资源的线程设置为有效的工作线程,将共享资源设置为锁定状态;如果共享资源被占用,就需要一定的阻塞等待唤醒机制来保证锁分配。这个机制主要用的是CLH队列的变体实现的,将暂时获取不到锁的线程加入到队列中。
CLH:Craig、Landin and Hagersten队列,是单向链表,AQS中的队列是CLH变体的虚拟双向队列(FIFO),AQS是通过将每条请求共享资源的线程封装成一个节点来实现锁的分配。
主要原理图如下:

AQS使用一个Volatile的int类型的成员变量来表示同步状态,通过内置的FIFO队列来完成资源获取的排队工作,通过CAS完成对State值的修改。
参考:
从ReentrantLock的实现看AQS的原理及应用
5、HashSet是如何实现的
HashSet实际上是一个HashMap实例,都是一个存放链表的数组。它不保证存储元素的迭代顺序;此类允许使用null元素。HashSet中不允许有重复元素,这是因为HashSet是基于HashMap实现的,HashSet中的元素都存放在HashMap的key上面,而value中的值都是统一的一个固定对象private static final Object PRESENT = new Object();
HashSet中add方法调用的是底层HashMap中的put()方法,而如果是在HashMap中调用put,首先会判断key是否存在,如果key存在则修改value值,如果key不存在这插入这个key-value。而在set中,因为value值没有用,也就不存在修改value值的说法,因此往HashSet中添加元素,首先判断元素(也就是key)是否存在,如果不存在这插入,如果存在着不插入,这样HashSet中就不存在重复值。
所以判断key是否存在就要重写元素的类的equals()和hashCode()方法,当向Set中添加对象时,首先调用此对象所在类的hashCode()方法,计算次对象的哈希值,此哈希值决定了此对象在Set中存放的位置;若此位置没有被存储对象则直接存储,若已有对象则通过对象所在类的equals()比较两个对象是否相同,相同则不能被添加。
6、你了解迭代器吗?说一说是如何使用的?
迭代器(Iterator)
迭代器是一种设计模式,它是一个对象,它可以遍历并选择序列中的对象,而开发人员不需要了解该序列的底层结构。迭代器通常被称为“轻量级”对象,因为创建它的代价小。
Java中的Iterator功能比较简单,并且只能单向移动:
(1) 使用方法iterator()要求容器返回一个Iterator。第一次调用Iterator的next()方法时,它返回序列的第一个元素。注意:iterator()方法是java.lang.Iterable接口,被Collection继承。
(2) 使用next()获得序列中的下一个元素。
(3) 使用hasNext()检查序列中是否还有元素。
(4) 使用remove()将迭代器新返回的元素删除。
Iterator是Java迭代器最简单的实现,为List设计的ListIterator具有更多的功能,它可以从两个方向遍历List,也可以从List中插入和删除元素。
public class IteratorTest
{
public static void main(String[] args)
{
List<String> list = new ArrayList<>();
list.add("aa");
list.add("bb");
list.add("cc");
// for (Iterator iter = list.iterator(); iter.hasNext(); )
// {
// String str = (String) iter.next();
// System.out.println(str);
// }
//用while循环
Iterator iter = list.iterator();
while (iter.hasNext())
{
String str = (String) iter.next();
System.out.println(str);
}
}
}
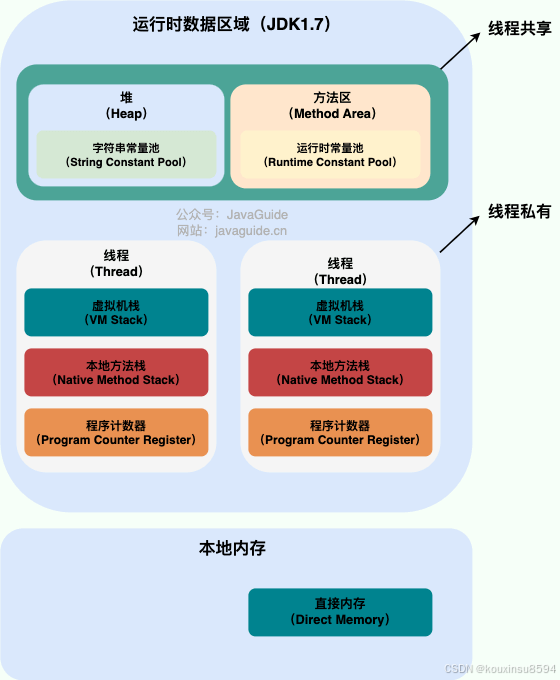
7、JVM内存是如何划分
根据《Java虚拟机规范(Java SE 7版)》的规定,Java虚拟机所管理的内存将会包括以下几个运行时数据区域:程序计数器,Java虚拟机栈,本地方法栈,Java堆,方法区。
HotSpot主要有:虚拟机栈,堆,程序计数器,Metaspace,直接内存。
下图为各个区域以及进一步细化图:
JDK1.7:
JDK1.8:
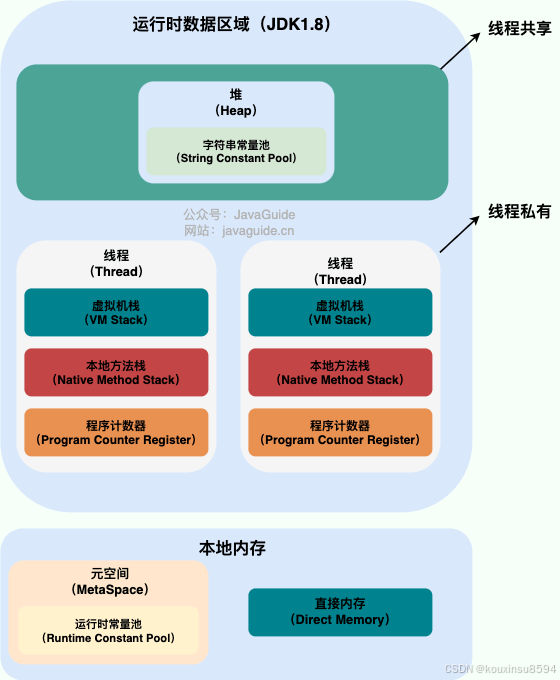
其中,元空间(Metaspace)的本质和永久代类似,都是对JVM规范中方法区的实现。不过元空间与永久代之间最大的区别在于:元空间并不在虚拟机中,而是使用本地内存。
因此,默认情况下,元空间的大小仅受本地内存限制,但可以通过以下参数来指定元空间的大小:
-XX:MetaspaceSize,初始空间大小,达到该值就会触发垃圾收集进行类型卸载,同时GC会对该值进行调整:如果释放了大量的空间,就适当降低该值;如果释放了很少的空间,那么在不超过MaxMetaspaceSize时,适当提高该值。
-XX:MaxMetaspaceSize,最大空间,默认-1,即没有限制,或者说只受本地内存大小。
-XX:MinMetaspaceFreeRatio,在GC之后,最小的Metaspace剩余空间容量的百分比,减少为分配空间所导致的垃圾收集。
-XX:MaxMetaspaceFreeRatio,在GC之后,最大的Metaspace剩余空间容量的百分比,减少为释放空间所导致的垃圾收集。
对于方法区,Java8之后的变化:
1.移除了永久代(PermGen),替换为元空间(Metaspace);
2.永久代中的 class metadata 转移到了 native memory(本地内存,而不是虚拟机);
3.永久代中的 interned Strings 和 class static variables 转移到了 Java heap;
4.永久代参数 (PermSize MaxPermSize) -> 元空间参数(MetaspaceSize MaxMetaspaceSize)
1 JVM运行时数据区
1)程序计数器(Program Counter Register)
程序计数器(Program Counter Register)是一块较小的内存空间,可以看做当前线程所执行的字节码的行号指示器。字节码解释器工作时就是通过改变这个计数器的值来选取下一条需要执行的字节码指令,分支、循环、跳转、异常处理、线程恢复等基础功能都需要依赖这个计数器来完成。如果当前方法是本地方法,PC 寄存器的值就是 undefined,该区域无OutOfMemoryError情况。
2)Java虚拟机栈(Java Virtual Machine Stacks)
Java Virtual Machine Stacks,也是线程私有的,它的生命周期与线程相同。
虚拟机栈描述的是Java方法执行的内存模型(非native方法)。
每个方法在执行的同时都会创建一个栈帧用于存储局部变量表,操作数栈,动态链接,方法出口等信息。
每一个方法从调用直至执行完成的过程,就对应着一个栈帧在虚拟机栈中入栈到出栈的过程,当方法被调用则入栈,一旦完成调用则出栈。所有的栈帧都出栈后,线程就结束了。
局部变量表存放了编译器可知的各种基本数据类型、对象引用、returnAddress类型。局部变量表所需的内存空间在编译器完成分配。当进入一个方法时,这个方法需要在帧中分配多大的局部变量空间是完全确定的,在方法运行期间不会改变局部变量表的大小。
基本类型:boolean, byte, char, short, int, float, long, double,其中long和double占用2个局部变量空间slot其余的占用1个;
对象引用:reference类型,它不等同于对象本身,可能是一个指向对象起始地址的引用指针,也可能是指向一个代表对象的句柄或其他与此对象相关的位置;
returnAddress类型:指向了一条字节码指令的地址;
在Java虚拟机规范中,对这个区域规定了两种异常:线程请求的栈深度大于虚拟机所允许的深度,抛出StackOverflowError异常;如果虚拟机栈可以动态扩展(目前大部分的Java虚拟机都可动态扩展,只不过Java虚拟机规范中也允许固定长度的虚拟机栈),如果扩展时无法申请到足够的内存,抛出OutOfMemoryError异常。
3)本地方法栈(Native Method Stack)
Native Method Stack与虚拟机栈的作用非常相似,区别是:虚拟机栈为虚拟机执行Java方法(也就是字节码)服务,而本地方法栈则为虚拟机使用到的Native方法。
本地方法被执行的时候,在本地方法栈也会创建一个栈帧,用于存放该本地方法的局部变量表、操作数栈、动态链接、出口信息。
备注:HotSpot直接把本地方法栈和虚拟机栈合二为一。本地方法栈区域也会抛出StackOverflowError和OutOfMemoryError异常。
4)Java堆(Java Heap)
Java Heap是Java虚拟机所管理的内存中最大的一块。Java堆是被所有线程共享的一块内存区域,在虚拟机启动时创建。此区域的唯一目的就是存放对象实例(Java虚拟机规范中的描述时:所有的对象实例以及数组都要在堆上分配)。
Java堆是GC的主要区域,因此很多时候也被称为GC堆。
从内存分配的角度来看,线程共享的Java堆中可能划分出多个线程私有的分配缓冲区(Thread Local Allocation Buffer, TLAB)
从内存回收的角度来看,由于现在收集器基本都采用分代收集算法,所以Java堆中还可以细分为:新生代和老年代,在细致一点的有Eden空间,From Survivor空间,To Survivor空间等。
备注:有OOM异常:
1.对dump出来的堆快照分析出内存泄漏还是内存溢出
2.内存泄漏: 查看泄漏对象的GCRoots的引用链,通过怎样的路径与GCRoots相关联导致垃圾收集器无法自动回收
3 不存在泄漏,则对象必须存活,则检查-Xmx与-Xms 及代码检查对象生命周期
5)方法区(Method Area)
Method Area是各个线程共享内存区域,用于存储已被虚拟机加载的类信息,常量,静态变量,即时编译器编译后的代码等数据。这个区域的内存回收目标主要是针对常量池的回收和对类型的卸载。
运行时常量池(Runtime Constant Pool)是方法区的一部分。Class文件中除了有类的版本,字段,方法,接口等描述信息,还有一项信息是常量池,用于存放编译期生成的各种字面量和符号引用,这部分内容将在类加载后进入方法区的运行时常量池中存放。
运行时常量池相对于Class文件常量池的另外一个重要特征是具备动态性。
6)补充
1)直接内存(Direct Memory)
Direct Memory,并不是虚拟机运行时数据区的一部分,也不是Java虚拟机规范中定义的内存区域,但线程共享。
在jdk1.4加入的NIO类,引入了一种基于通道(Chanel)与缓冲区(Buffer)的IO方式,它可以使用Native函数库直接分配堆外内存,然后通过一个存储在Java堆中的DirectByteBuffer对象作为这块内存的引用进行操作。这样能在一些场景中显著提高性能,因为避免了在Java堆和Native堆中来回复制数据。
备注:本机直接内存的分配不会受到Java堆大小的限制,受到本机总内存和处理器寻址空间的限制,有OOM异常。
7.1)其中线程共享的区域是:
- Java堆区
- 方法区
- 直接内存(不属于运行时数据区,但线程共享)
7.2)其中线程私有的区域是:
- Java虚拟机栈
- 本地方法栈
- 程序计数器
7.3)其中会出现oom的区域是:
- Java虚拟机栈
- Java堆区
- 直接内存
- 本地方法栈
参考:
JVM内存划分
2 OOM发生的位置以及如何处理
1)Java堆溢出
这种场景最为常见,报错信息:
java.lang.OutOfMemoryError: Java heap space
原因
- 代码中可能存在大对象分配
- 可能存在内存泄露,导致在多次GC之后,还是无法找到一块足够大的内存容纳当前对象。
解决方法
- 检查是否存在大对象的分配,最有可能的是大数组分配
- 通过
jmap命令,把堆内存dump下来,使用mat工具分析一下,检查是否存在内存泄露的问题 - 如果没有找到明显的内存泄露,使用
-Xmx加大堆内存 - 还有一点容易被忽略,检查是否有大量的自定义的
Finalizable对象,也有可能是框架内部提供的,考虑其存在的必要性
2)永久代/元空间溢出
报错信息:
java.lang.OutOfMemoryError: PermGen space
java.lang.OutOfMemoryError: Metaspace
原因
永久代是 HotSot 虚拟机对方法区的具体实现,存放了被虚拟机加载的类信息、常量、静态变量、JIT编译后的代码等。
JDK8后,元空间替换了永久代,元空间使用的是本地内存,还有其它细节变化:
- 字符串常量由永久代转移到堆中
- 和永久代相关的JVM参数已移除
可能原因有如下几种:
- 在Java7之前,频繁的错误使用
String.intern()方法 - 运行期间生成了大量的代理类,导致方法区被撑爆,无法卸载
- 应用长时间运行,没有重启
解决方法
因为该OOM原因比较简单,解决方法有如下几种:
- 检查是否永久代空间或者元空间设置的过小
- 检查代码中是否存在大量的反射操作
- dump之后通过mat检查是否存在大量由于反射生成的代理类
- 放大招,重启JVM
3 GC overhead limit exceeded
这个异常比较的罕见,报错信息:
java.lang.OutOfMemoryError:GC overhead limit exceeded
原因
这个是JDK6新加的错误类型,一般都是堆太小导致的。Sun 官方对此的定义:超过98%的时间用来做GC并且回收了不到2%的堆内存时会抛出此异常。
解决方法
- 检查项目中是否有大量的死循环或有使用大内存的代码,优化代码。
- 添加参数
-XX:-UseGCOverheadLimit禁用这个检查,其实这个参数解决不了内存问题,只是把错误的信息延后,最终出现java.lang.OutOfMemoryError: Java heap space。 - dump内存,检查是否存在内存泄露,如果没有,加大内存。
4 方法栈溢出
报错信息:
java.lang.OutOfMemoryError : unable to create new native Thread
原因
出现这种异常,基本上都是创建的了大量的线程导致的,以前碰到过一次,通过jstack出来一共8000多个线程。
解决方法
- 通过
-Xss降低的每个线程栈大小的容量 - 线程总数也受到系统空闲内存和操作系统的限制,检查是否该系统下有此限制:
- /proc/sys/kernel/pid_max/
- proc/sys/kernel/thread-max
- maxuserprocess(ulimit -u)
- /proc/sys/vm/maxmapcount
非常规溢出下面这些OOM异常,可能大部分的同学都没有碰到过,但还是需要了解一下
5 分配超大数组
报错信息 :
java.lang.OutOfMemoryError: Requested array size exceeds VM limit
原因
这种情况一般是由于不合理的数组分配请求导致的,在为数组分配内存之前,JVM 会执行一项检查。要分配的数组在该平台是否可以寻址(addressable),如果不能寻址(addressable)就会抛出这个错误。
解决方法
就是检查你的代码中是否有创建超大数组的地方。
6 swap溢出
报错信息 :
java.lang.OutOfMemoryError: Out of swap space
原因
这种情况一般是操作系统导致的,可能的原因有:
- swap 分区大小分配不足;
- 其他进程消耗了所有的内存。
解决方案
- 其它服务进程可以选择性的拆分出去
- 加大swap分区大小,或者加大机器内存大小
7 本地方法溢出
报错信息 :
java.lang.OutOfMemoryError: stack_trace_with_native_method
本地方法在运行时出现了内存分配失败,和之前的方法栈溢出不同,方法栈溢出发生在 JVM 代码层面,而本地方法溢出发生在JNI代码或本地方法处。这个异常出现的概率极低,只能通过操作系统本地工具进行诊断,难度有点大,还是放弃为妙。
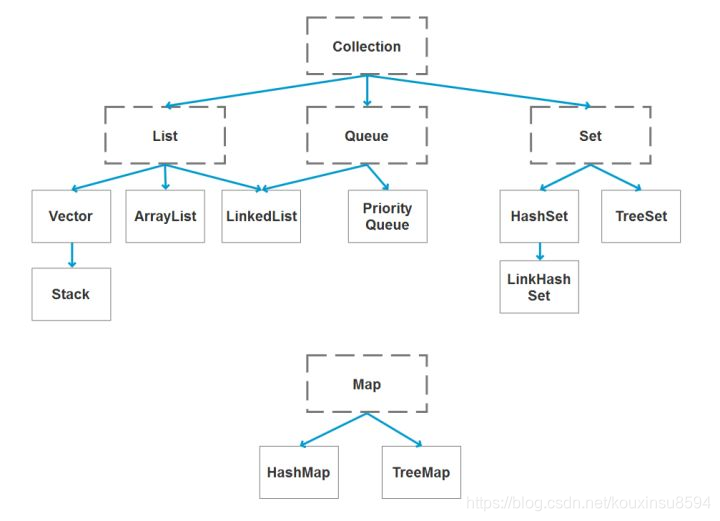
8、Java的容器有哪些
1 常用容器的图录
2、如何在列表中找出相同的对象或值
1)如何在列表中找出相同的对象
面试官问:“假如有一个List,存放的是Bean类型的数据,如List<Student>,Student实体类中包含id,name ,如何筛选出id相同的List。”
使用Collectors.groupingBy()方法
Map<String, List<Student>> listMap = list.stream()
.collect(Collectors.groupingBy(Student::getId));
完整代码:
@Data
@NoArgsConstructor
public class Student
{
private String id;
private String name;
}
@Slf4j
public class StudentTest
{
@Test
public void getStudentList()
{
List<Student> list = new ArrayList<>();
Student student1 = new Student();
student1.setId("123456");
student1.setName("张三");
Student student2 = new Student();
student2.setId("567890");
student2.setName("李四");
Student student3 = new Student();
student3.setId("567890");
student3.setName("李四");
list.add(student1);
list.add(student2);
list.add(student3);
Map<String, List<Student>> listMap = list.stream()
.collect(Collectors.groupingBy(Student::getId));
for (Map.Entry<String, List<Student>> entry : listMap.entrySet())
{
String id = entry.getKey();
String s = JSONObject.toJSONString(entry.getValue());
log.info("id ={},value = {}",id,s);
}
}
}
2)List集合取交集(包含并集、差集、去重并集)
public class ListTest
{
@Test
public void getList()
{
List<String> list1 = new ArrayList<String>();
list1.add("1");
list1.add("2");
list1.add("3");
list1.add("5");
list1.add("6");
List<String> list2 = new ArrayList<String>();
list2.add("2");
list2.add("3");
list2.add("7");
list2.add("8");
// 交集
List<String> intersection = list1.stream()
.filter(item -> list2.contains(item)).collect(toList());
System.out.println("---交集 intersection---");
intersection.parallelStream().forEach(System.out ::println);
// 差集 (list1 - list2)
List<String> reduce1 = list1.stream().filter(item -> !list2.contains(item))
.collect(toList());
System.out.println("---差集 reduce1 (list1 - list2)---");
reduce1.parallelStream().forEach(System.out ::println);
// 差集 (list2 - list1)
List<String> reduce2 = list2.stream().filter(item -> !list1.contains(item))
.collect(toList());
System.out.println("---差集 reduce2 (list2 - list1)---");
reduce2.parallelStream().forEach(System.out ::println);
// 并集
List<String> listAll = list1.parallelStream().collect(toList());
List<String> listAll2 = list2.parallelStream().collect(toList());
listAll.addAll(listAll2);
System.out.println("---并集 listAll---");
listAll.parallelStream().forEachOrdered(System.out ::println);
// 去重并集
List<String> listAllDistinct = listAll.stream().distinct()
.collect(toList());
System.out.println("---得到去重并集 listAllDistinct---");
listAllDistinct.parallelStream().forEachOrdered(System.out ::println);
System.out.println("---原来的List1---");
list1.parallelStream().forEachOrdered(System.out ::println);
System.out.println("---原来的List2---");
list2.parallelStream().forEachOrdered(System.out ::println);
}
}
参考:
java8两个List集合取交集、并集、差集、去重并集
9、常用的时间类
在Java 8之前,所有关于时间和日期的API都存在各种使用方面的缺陷,主要有:
- Java的
java.util.Date和java.util.Calendar类易用性差,不支持时区,而且他们都不是线程安全的; - 用于格式化日期的类
DateFormat被放在java.text包中,它是一个抽象类,所以我们需要实例化一个SimpleDateFormat对象来处理日期格式化,并且DateFormat也是非线程安全,这意味着如果你在多线程程序中调用同一个DateFormat对象,会得到意想不到的结果。 - 对日期的计算方式繁琐,而且容易出错,因为月份是从0开始的,从
Calendar中获取的月份需要加一才能表示当前月份。
在Java1.8中使用新的时间和日期API
Java 8的日期和时间类包含 LocalDate、LocalTime、Instant、Duration 以及 Period,这些类都包含在 java.time 包中,Java 8 新的时间API的使用方式,包括创建、格式化、解析、计算、修改。
1) LocalDate(只会获取年月日)
2) LocalTime (只会获取时分秒)
3)LocalDateTime 获取年月日时分秒,相当于 LocalDate + LocalTime
4)Instant 用于表示一个时间戳,它与我们常使用的System.currentTimeMillis()有些类似,不过Instant可以精确到纳秒(Nano-Second),System.currentTimeMillis()方法只精确到毫秒(Milli-Second)。ofEpochSecond()方法的第一个参数为秒,第二个参数为纳秒,下面的代码表示从1970-01-01 00:00:00开始后两分钟的10万纳秒的时刻,
Instant instant = Instant.ofEpochSecond(120, 100000);
控制台上的输出为:
1970-01-01T00:02:00.000100Z
5)Duration 表示一个时间段
LocalDateTime from = LocalDateTime.of(2017, Month.JANUARY, 5, 10, 7, 0); // 2017-01-05 10:07:00
LocalDateTime to = LocalDateTime.of(2017, Month.FEBRUARY, 5, 10, 7, 0); // 2017-02-05 10:07:00
Duration duration = Duration.between(from, to); // 表示从 2017-01-05 10:07:00 到 2017-02-05 10:07:00 这段时间
long days = duration.toDays(); // 这段时间的总天数
long hours = duration.toHours(); // 这段时间的小时数
long minutes = duration.toMinutes(); // 这段时间的分钟数
long seconds = duration.getSeconds(); // 这段时间的秒数
long milliSeconds = duration.toMillis(); // 这段时间的毫秒数
long nanoSeconds = duration.toNanos(); // 这段时间的纳秒数
6)Period 是以年月日来衡量一个时间段,比如2年3个月6天:
Period period = Period.of(2, 3, 6);
7) 时间格式化
DateTimeFormatter 类用于处理日期格式化操作,它被包含在java.time.format包中,Java 8的日期类有一个format()方法用于将日期格式化为字符串
LocalDateTime dateTime = LocalDateTime.now();
String strDate1 = dateTime.format(DateTimeFormatter.BASIC_ISO_DATE); // 20170105
8)时区
java.time.ZoneId 时区类,ZoneId对象可以通过ZoneId.of()方法创建,也可以通过 ZoneId.systemDefault()获取系统默认时区:
ZoneId shanghaiZoneId = ZoneId.of("Asia/Shanghai");
ZoneId systemZoneId = ZoneId.systemDefault();
参考:
Java 8新特性(四):新的时间和日期API
为什么不建议使用Date,而是使用Java8新的时间和日期API?
10、Java动态代理
动态代理:代理类在程序运行时创建的代理方式。也就是说,这种情况下,代理类并不是在Java代码中定义的,而是在运行时根据我们在Java代码中的“指示”动态生成的。相比于静态代理, 动态代理的优势在于可以很方便的对代理类的函数进行统一的处理,而不用修改每个代理类的函数。
在运行期动态创建一个interface实例的方法如下:
- 定义一个
InvocationHandler实例,它负责实现接口的方法调用; - 通过
Proxy.newProxyInstance()创建interface实例,它需要3个参数:
1) 使用的ClassLoader,通常就是接口类的ClassLoader
2) 需要实现的接口数组,至少需要传入一个接口进去;
3) 用来处理接口方法调用的InvocationHandler实例。 - 将返回的
Object强制转型为接口。
总结来说:首先通过newProxyInstance方法获取代理类实例,而后我们便可以通过这个代理类实例调用代理类的方法,对代理类的方法的调用实际上都会调用中介类(调用处理器)的invoke方法,在invoke方法中我们调用委托类的相应方法,并且可以添加自己的处理逻辑。
扩展
1 静态代理
静态代理代理方式需要代理对象和目标对象实现一样的接口。
优点
可以在不修改目标对象的前提下扩展目标对象的功能。
缺点
- 冗余。由于代理对象要实现与目标对象一致的接口,会产生过多的代理类。
- 不易维护。一旦接口增加方法,目标对象与代理对象都要进行修改。
2 cglib代理
cglib (Code Generation Library )是一个第三方代码生成类库,运行时在内存中动态生成一个子类对象从而实现对目标对象功能的扩展。
cglib特点
- JDK的动态代理有一个限制,就是使用动态代理的对象必须实现一个或多个接口。
如果想代理没有实现接口的类,就可以使用CGLIB实现。 - CGLIB是一个强大的高性能的代码生成包,它可以在运行期扩展Java类与实现Java接口。
它广泛的被许多AOP的框架使用,例如Spring AOP和dynaop,为他们提供方法的interception(拦截)。 - CGLIB包的底层是通过使用一个小而快的字节码处理框架ASM,来转换字节码并生成新的类。
不鼓励直接使用ASM,因为它需要你对JVM内部结构包括class文件的格式和指令集都很熟悉。
cglib与动态代理最大的区别就是
- 使用动态代理的对象必须实现一个或多个接口
- 使用cglib代理的对象则无需实现接口,达到代理类无侵入。
参考:
Java三种代理模式:静态代理、动态代理和cglib代理
11、自动装箱和拆箱
1 什么是自动装箱和拆箱
1)自动装箱
自动装箱就是Java自动将原始类型值转换成对应的对象,比如将int的变量转换成Integer对象,这个过程叫做装箱。
原理:
自动装箱时编译器调用valueOf将原始类型值转换成对象
2)自动拆箱
自动拆箱就是Java自动将对象转成原始类型,将Integer对象转换成int类型值,这个过程叫做拆箱。
原理:
编译器通过调用类似intValue(),doubleValue()这类的方法将对象转换成原始类型值。
2 装箱/拆箱有关的问题
1 Integer和int类型
public class Main {
public static void main(String[] args) {
Integer i1 = 100;
Integer i2 = 100;
Integer i3 = 200;
Integer i4 = 200;
System.out.println(i1==i2);
System.out.println(i3==i4);
}
}
返回键结果:
true
false
原因:
在通过valueOf方法创建Integer对象的时候,如果数值在[-128,127]之间,便返回指向IntegerCache.cache中已经存在的对象的引用;否则创建一个新的Integer对象。
上面的代码中i1和i2的数值为100,因此会直接从cache中取已经存在的对象,所以i1和i2指向的是同一个对象,而i3和i4则是分别指向不同的对象。
参考:
深入剖析Java中的装箱和拆箱
12、Java Lambda 表达式应用场景
1 列表迭代
对一个列表的每一个元素进行操作,不使用 Lambda 表达式时如下:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
numbers.forEach(x -> System.out.println(x));
2 Map 映射
使用 Stream 对象的 map 方法将原来的列表经由 Lambda 表达式映射为另一个列表,并通过 collect 方法转换回 List 类型:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
List<Integer> mapped = numbers.stream().map(x -> x * 2).collect(Collectors.toList());
mapped.forEach(System.out::println);
3 代替 Runnable
以创建线程为例,使用 Runnable 类的代码如下:
Runnable r = new Runnable() {
@Override
public void run() {
//to do something
}
};
Thread t = new Thread(r);
t.start();
使用 Lambda 表达式:
Runnable r = () -> {
//to do something
};
Thread t = new Thread(r);
t.start();
或者使用更加紧凑的形式:
Thread t = new Thread(() -> {
//to do something
});
t.start;
4 Predicate 接口
java.util.function 包中的 Predicate 接口可以很方便地用于过滤。如果你需要对多个对象进行过滤并执行相同的处理逻辑,那么可以将这些相同的操作封装到filter方法中,由调用者提供过滤条件,以便重复使用。
使用 Predicate 接口,将相同的处理逻辑封装到 filter 方法中,重复调用:
public static void main(String[] args) {
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
List<String> words = Arrays.asList("a", "ab", "abc");
filter(numbers, x -> (int)x % 2 == 0);
filter(words, x -> ((String)x).length() > 1);
}
public static void filter(List list, Predicate condition) {
list.forEach(x -> {
if (condition.test(x)) {
//process logic
}
})
}
filter 方法也可写成:
public static void filter(List list, Predicate condition) {
list.stream().filter(x -> condition.test(x)).forEach(x -> {
//process logic
})
}
5 事件监听
使用 Lambda 表达式,需要编写多条语句时用花括号包围起来:
button.addActionListener(e -> {
//handle the event
});
13、JDK1.7和JDK1.8有什么差别
JDK1.8增加了主要有:
-
Lambda 表达式 − Lambda 允许把函数作为一个方法的参数(函数作为参数传递到方法中)。
-
方法引用 − 方法引用提供了非常有用的语法,可以直接引用已有Java类或对象(实例)的方法或构造器。与lambda联合使用,方法引用可以使语言的构造更紧凑简洁,减少冗余代码。
-
默认方法 − 默认方法就是一个在接口里面有了一个实现的方法。
-
新工具 − 新的编译工具,如:Nashorn引擎 jjs、 类依赖分析器jdeps。
-
Stream API −新添加的Stream API(java.util.stream) 把真正的函数式编程风格引入到Java中。
-
Date Time API − 加强对日期与时间的处理。
-
Optional 类 − Optional 类已经成为 Java 8 类库的一部分,用来解决空指针异常。
-
Nashorn, JavaScript 引擎 − Java 8提供了一个新的Nashorn javascript引擎,它允许我们在JVM上运行特定的javascript应用。
14、Java中Synchronized的用法
synchronized是Java中的关键字,是一种同步锁。它修饰的对象有以下几种:
1. 修饰一个代码块,被修饰的代码块称为同步语句块,其作用的范围是大括号{}括起来的代码,作用的对象是调用这个代码块的对象;
2. 修饰一个方法,被修饰的方法称为同步方法,其作用的范围是整个方法,作用的对象是调用这个方法的对象;
3. 修改一个静态的方法,其作用的范围是整个静态方法,作用的对象是这个类的所有对象;
4. 修改一个类,其作用的范围是synchronized后面括号括起来的部分,作用主的对象是这个类的所有对象。
参考:
Java中Synchronized的用法(简单介绍)
15、Java类加载过程
系统加载 Class 类型的文件主要三步:加载->连接->初始化。连接过程又可分为三步:验证->准备->解析。
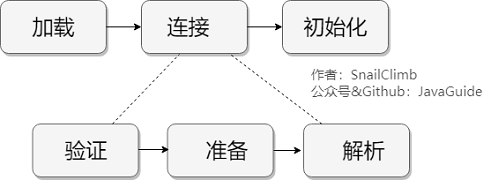
1)加载
类加载过程的第一步,主要完成下面3件事情:
- 通过全类名获取定义此类的二进制字节流
- 将字节流所代表的静态存储结构转换为方法区的运行时数据结构
- 在内存中生成一个代表该类的 Class 对象,作为方法区这些数据的访问入口
2)验证
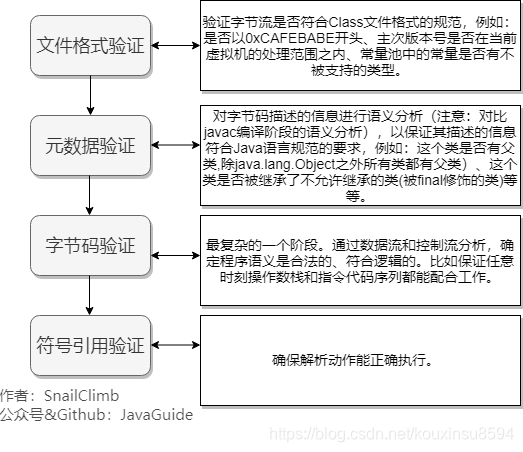
3)准备
准备阶段是正式为类变量分配内存并设置类变量初始值的阶段,这些内存都将在方法区中分配。对于该阶段有以下几点需要注意:
- 这时候进行内存分配的仅包括类变量(static),而不包括实例变量,实例变量会在对象实例化时随着对象一块分配在 Java 堆中。
- 这里所设置的初始值"通常情况"下是数据类型默认的零值(如0、0L、null、false等),比如我们定义了
public static int value=111,那么 value 变量在准备阶段的初始值就是 0 而不是111(初始化阶段才会赋值)。特殊情况:比如给 value 变量加上了 fianl 关键字public static final int value=111,那么准备阶段 value 的值就被赋值为 111。
4)解析
解析阶段是虚拟机将常量池内的符号引用替换为直接引用的过程。解析动作主要针对类或接口、字段、类方法、接口方法、方法类型、方法句柄和调用限定符7类符号引用进行。
5)初始化
初始化是类加载的最后一步,也是真正执行类中定义的 Java 程序代码(字节码),初始化阶段是执行类构造器 <clinit> ()方法的过程。
参考:
JavaGuide/docs/java/jvm/类加载过程.md
16、static关键字的作用
static的主要意义是在于创建独立于具体对象的域变量或者方法。以致于即使没有创建对象,也能使用属性和调用方法!
static关键字还有一个比较关键的作用就是 用来形成静态代码块以优化程序性能。static块可以置于类中的任何地方,类中可以有多个static块。在类初次被加载的时候,会按照static块的顺序来执行每个static块,并且只会执行一次。
static的独特之处
1、被static修饰的变量或者方法是独立于该类的任何对象,也就是说,这些变量和方法不属于任何一个实例对象,而是被类的实例对象所共享。
2、在该类被第一次加载的时候,就会去加载被static修饰的部分,而且只在类第一次使用时加载并进行初始化,注意这是第一次用就要初始化,后面根据需要是可以再次赋值的。
3、static变量值在类加载的时候分配空间,以后创建类对象的时候不会重新分配。赋值的话,是可以任意赋值的!
4、被static修饰的变量或者方法是优先于对象存在的,也就是说当一个类加载完毕之后,即便没有创建对象,也可以去访问。
参考:
深入理解static关键字
17、Java几种集合基本实现与应用场景
1、List集合
- ArrayList是一个可变大小的数组实现,适用于需要频繁访问元素的场景。
- LinkedList是一个双向链表实现,适用于需要频繁插入和删除元素的场景
- Vector与ArrayList相似,但是线程安全,适用于并发环境。
2、Set集合
- HashSet使用哈希表实现,适用于不允许重复元素的场景。
- TreeSet使用红黑树实现,适用于需要元素自动排序的场景。
3、Map集合
- HashMap是基于哈希表的键值对实现,适用于需要快速查找和存储键值对的场景。
- TreeMap基于红黑树实现,适用于需要按键自动排序的场景。
二、集合相关的问题
1、数组和列表的转换
1 List转数组
1)使用List.toArray()方法
public class ListToArraysTest
{
public static void main(String[] args)
{
//要转换的list集合
List<String> testList = new ArrayList<String>()
{{
add("aa");
add("bb");
add("cc");
}};
//使用toArray(T[] a)方法
String[] array2 = testList.toArray(new String[testList.size()]);
//打印该数组
for (int i = 0; i < array2.length; i++)
{
System.out.println(array2[i]);
}
}
}
2)使用for循环
public class ListToArraysTest
{
public static void main(String[] args)
{
//要转换的list集合
List<String> testList = new ArrayList<String>()
{{
add("aa");
add("bb");
add("cc");
}};
//初始化需要得到的数组
String[] array = new String[testList.size()];
//使用for循环得到数组
for(int i = 0; i < testList.size();i++){
array[i] = testList.get(i);
}
//打印数组
for(int i = 0; i < array.length; i++){
System.out.println(array[i]);
}
}
}
2 数组转List
1)使用Arrays.asList()
public class ArraysToListTest
{
public static void main(String[] args)
{
String[] arrays = new String[] { "aa", "bb", "cc" };
ArrayList<String> arrayList = new ArrayList<String>(
Arrays.asList(arrays));
System.out.println(arrayList);
}
}
2)使用Collections.addAll()
public class ArraysToListTest
{
public static void main(String[] args)
{
String[] arrays = new String[] { "aa", "bb", "cc" };
List<String> list = new ArrayList<String>(arrays.length);
Collections.addAll(list, arrays);
System.out.println(list);
}
}
3)使用Arrays.asList()的另一种写法
public class ArraysToListTest
{
public static void main(String[] args)
{
String[] arrays = new String[] { "aa", "bb", "cc" };
List<String> list = Arrays.asList(arrays);
System.out.println(list);
list.add("dd");
System.out.println("add后:"+list);
}
}
这里在list继续使用add()方法之后会报如下UnsupportedOperationException异常
Exception in thread "main" java.lang.UnsupportedOperationException
at java.util.AbstractList.add(AbstractList.java:148)
at java.util.AbstractList.add(AbstractList.java:108)
at com.sunsun.designmodedemo.test.ArraysToListTest.main(ArraysToListTest.java:28)
原因如下:
因为asList()返回的列表的大小是固定的。事实上,返回的列表不是java.util.ArrayList,而是定义在java.util.Arrays中一个私有静态类。我们知道ArrayList的实现本质上是一个数组,而asList()返回的列表是由原始数组支持的固定大小的列表。这种情况下,如果添加或删除列表中的元素,程序会抛出异常UnsupportedOperationException。
4)使用for循环
public class ArraysToListTest
{
public static void main(String[] args)
{
String[] arrays = new String[] { "aa", "bb", "cc" };
//初始化list
List<String> list3 = new ArrayList<String>();
//使用for循环转换为list
for(String str : arrays){
list3.add(str);
}
//打印得到的list
System.out.println(list3);
}
}
2、concurrentashmap和HashTable的区别
ConcurrentHashMap 和 Hashtable 的区别主要体现在实现线程安全的方式上不同。
底层数据结构:
ConcurrentHashMap:
JDK1.7的 ConcurrentHashMap 底层采用 分段的数组+链表 实现,JDK1.8 采用的数据结构跟HashMap1.8的结构一样,数组+链表/红黑二叉树。
Hashtable :
Hashtable 和 JDK1.8 之前的 HashMap 的底层数据结构类似都是采用 数组+链表 的形式,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的;
实现线程安全的方式(重要):
① 在JDK1.7的时候,ConcurrentHashMap(分段锁) 对整个桶数组进行了分割分段(Segment),每一把锁只锁容器其中一部分数据,多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高并发访问率。(默认分配16个Segment,比Hashtable效率提高16倍。) 到了 JDK1.8 的时候已经摒弃了Segment的概念,而是直接用 Node 数组+链表+红黑树的数据结构来实现,并发控制使用 synchronized 和 CAS来操作。(JDK1.6以后 对 synchronized锁做了很多优化) 整个看起来就像是优化过且线程安全的 HashMap,虽然在JDK1.8中还能看到 Segment 的数据结构,但是已经简化了属性,只是为了兼容旧版本;
② Hashtable(同一把锁) :使用 synchronized 来保证线程安全,效率非常低下。当一个线程访问同步方法时,其他线程也访问同步方法,可能会进入阻塞或轮询状态,如使用 put 添加元素,另一个线程不能使用 put 添加元素,也不能使用 get,竞争会越来越激烈效率越低。
3、什么是HashMap
JDK1.8 之前 HashMap 由数组+链表组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的(“拉链法”解决冲突)。JDK1.8 以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)时,将链表转化为红黑树,以减少搜索时间
扩展:LinkedHashMap
LinkedHashMap 继承自 HashMap,所以它的底层仍然是基于拉链式散列结构即由数组和链表或红黑树组成。另外,LinkedHashMap 在上面结构的基础上,增加了一条双向链表,使得上面的结构可以保持键值对的插入顺序。同时通过对链表进行相应的操作,实现了访问顺序相关逻辑。
4、HashMap的扩容机制
1 什么时候扩容
HashMap的容量是有限的。当经过多次元素插入的时候,使得HashMap达到一定的饱和度,Key映射位置的几率不断变大。这个时候,HashMap就需要扩容了,也就是resize()。
HashMap扩容的条件:
1、HashMap中的数据达到阈值。
2、出现hash碰撞的情况。
2 怎么扩容
1)创建一个新的Entry空数组,使用的是2次幂的扩展(长度是原来的2倍)。
2)ReHash:遍历原Entry数组,把所有的Entry重新Hash到新数组。
为什么要重新Hash呢?因为长度扩大以后,Hash的规则也随之改变。
Hash的公式—> index = HashCode(Key) & (Length - 1)
扩容前:
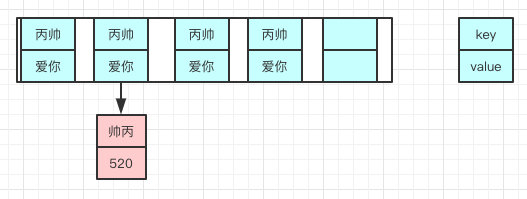
扩容后:

参考:
一个HashMap跟面试官扯了半个小时
阿里面试官没想到一个HashMap,我能跟他扯半小时
HashMap扩容
5、List在遍历的时候如果remove一个元素会发生什么问题?
1 普通for循环遍历
public static void main(String[] args) {
List<String> list = new ArrayList<>(3);
list.add("a");
list.add("b");
list.add("c");
for(int i=0;i<list.size();i++){
if("a".equals(list.get(i))) {
list.remove(i);
}
}
System.out.println(list);
}
有两个相同且相邻的元素3则只能删除一个,原因是删除一个元素后后造成数组索引左移。这里有一个小细节使用的是==i<list.size()==否则还会造成数组越界问题。
- 可以让**remove(i–)**让索引同步调整。
- 倒序遍历List删除元素
2 使用增强for遍历
public static void main(String[] args) {
List<String> list = new ArrayList<>(3);
list.add("a");
list.add("b");
list.add("c");
for (String i : list) {
if ("a".equals(list.get(1))) {
list.remove(i);
}
}
System.out.println(list);
}
结果
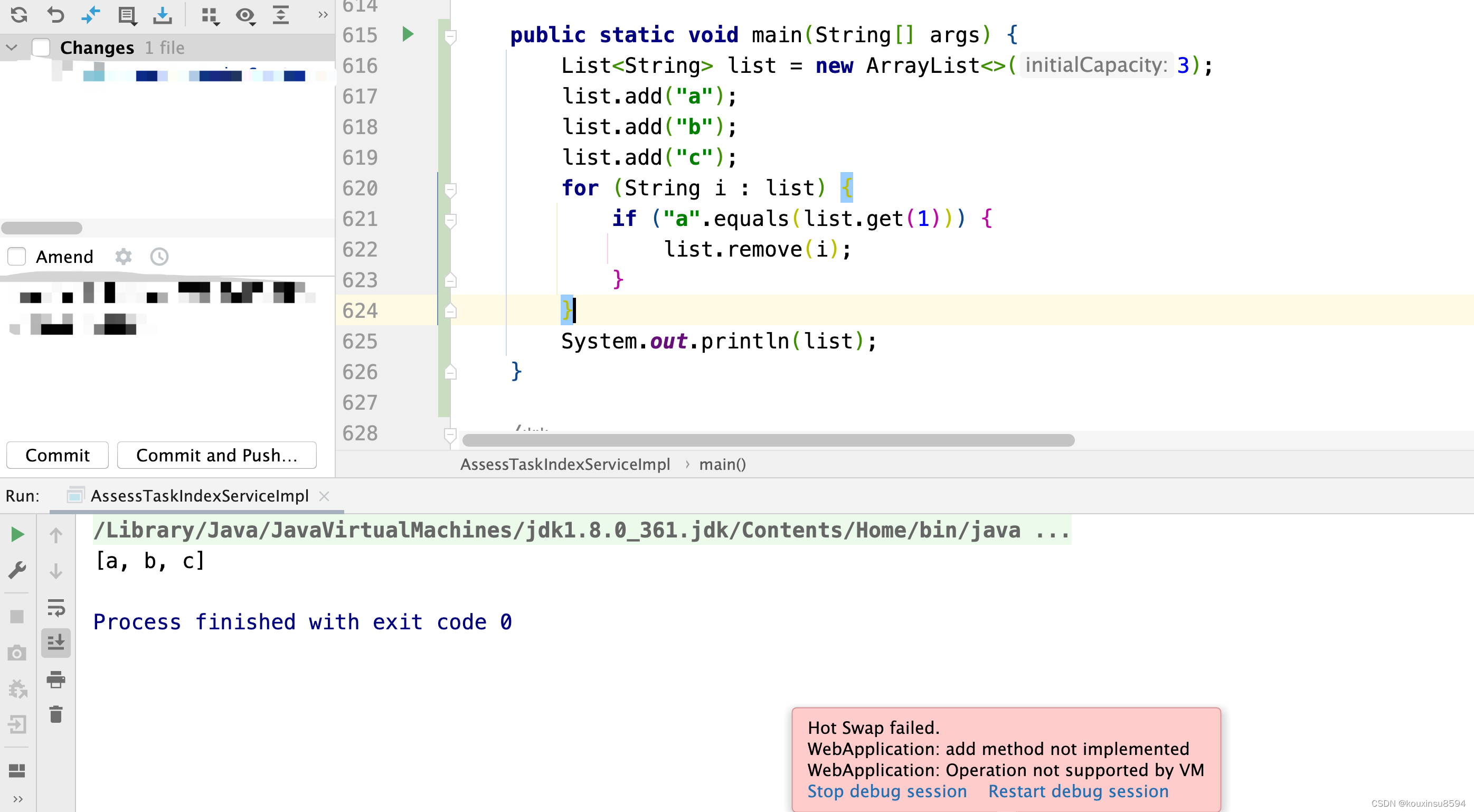
每次正常执行 remove 方法后,会进行元素个数的比较,都会对执行expectedModCount = modCount赋值,保证两个值相等,那么问题基本上已经清晰了,在 foreach 循环中执行 list.remove(item);,对 list 对象的 modCount 值进行了修改,而 list 对象的迭代器的 expectedModCount 值未进行修改,因此抛出了ConcurrentModificationException异常。
3 Iterator迭代器遍历
public static void main(String[] args) {
List<String> list = new ArrayList<>(3);
list.add("a");
list.add("b");
list.add("c");
Iterator<String> it= list.iterator();
while(it.hasNext()){
String value=it.next();
if(value.equals("c")){
list.remove(value);
}
}
System.out.println(list);
}
运行结果:
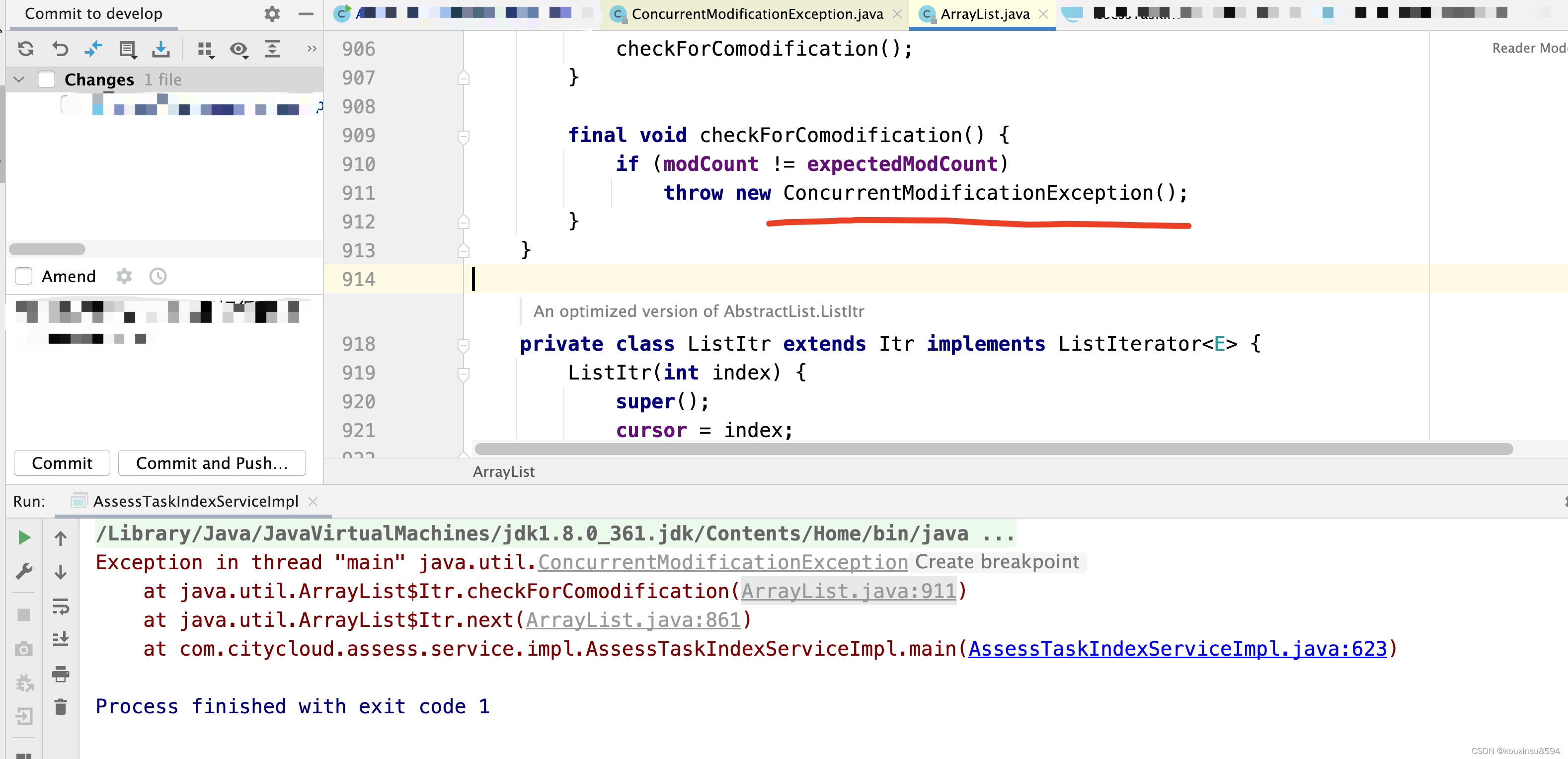
原理同2
4 List删除元素时,注意Integer类型和int类型的区别
list删除元素时传入的int类型的,默认按索引删除。如果删除的是Integer对象,则调用的是remove(object)方法,删除的是列表对应的元素。
二、多线程相关的问题
1、进程和线程?
- 进程是程序的一次执行过程,是系统运行程序的基本单位,因此进程是动态的。系统运行一个程序即是一个进程从创建,运行到消亡的过程。
- 线程是一个比进程更小的执行单位。一个进程在其执行的过程中可以产生多个线程。与进程不同的是同类的多个线程共享进程的堆和方法区资源,但每个线程有自己的程序计数器、虚拟机栈和本地方法栈,所以系统在产生一个线程,或是在各个线程之间作切换工作时,负担要比进程小得多,也正因为如此,线程也被称为轻量级进程。
2、线程池你了解吗?线程池的参数是如何的?
1 线程池
线程池通过 ThreadPoolExecutor 的方式创建,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险
1)线程池生命周期
ThreadPoolExecutor生命周期转换:
RUNNING:能接受新提交的任务,并且也能处理阻塞队列中的任务;SHUTDOWN:关闭状态,不再接受新提交的任务,但却可以继续处理阻塞队列中已保存的任务。在线程池处于RUNNING状态时,调用SHUTDOWN()方法会使线程池进入到该状态。(finalize() 方法在执行过程中也会调用SHUTDOWN()方法进入该状态);STOP:不能接受新任务,也不处理队列中的任务,会中断正在处理任务的线程。在线程池处于RUNNING或SHUTDOWN状态时,调用SHUTDOWNNow() 方法会使线程池进入到该状态;TIDYING:如果所有的任务都已终止了,workerCount (有效线程数) 为0,线程池进入该状态后会调用terminated()方法进入TERMINATED状态。TERMINATED:在terminated()方法执行完后进入该状态,默认terminated()方法中什么也没有做。
进入TERMINATED的条件如下:- 线程池不是
RUNNING状态; - 线程池状态不是
TIDYING状态或TERMINATED状态; - 如果线程池状态是
SHUTDOWN并且workerQueue为空; workerCount为0;- 设置
TIDYING状态成功。
- 线程池不是
2)常用的线程池
1. new SingleThreadExecutor()
创建一个单线程的线程池。这个线程池只有一个线程在工作,也就是相当于单线程串行执行所有任务。如果这个唯一的线程因为异常结束,那么会有一个新的线程来替代它。此线程池保证所有任务的执行顺序按照任务的提交顺序执行。
2. new FixedThreadPool()
创建固定大小的线程池。每次提交一个任务就创建一个线程,直到线程达到线程池的最大大小。线程池的大小一旦达到最大值就会保持不变,如果某个线程因为执行异常而结束,那么线程池会补充一个新线程。
3. new CachedThreadPool()
创建一个可缓存的线程池。如果线程池的大小超过了处理任务所需要的线程,
那么就会回收部分空闲(60秒不执行任务)的线程,当任务数增加时,此线程池又可以智能的添加新线程来处理任务。此线程池不会对线程池大小做限制,线程池大小完全依赖于操作系统(或者说JVM)能够创建的最大线程大小。
4. new ScheduledThreadPool()
创建一个大小无限的线程池。此线程池支持定时以及周期性执行任务的需求。
2 线程池参数
ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
1)corePoolSize:核心线程数(设置多少合适)
核心线程会一直存活,及时没有任务需要执行
当线程数小于核心线程数时,即使有线程空闲,线程池也会优先创建新线程处理
设置allowCoreThreadTimeout=true(默认false)时,核心线程会超时关闭
1.5)核心线程数设置多少合适
一个计算为主的程序(CPU密集型程序),多线程跑的时候,可以充分利用起所有的 CPU 核心数,比如说 8 个核心的CPU ,开8 个线程的时候,可以同时跑 8 个线程的运算任务,此时是最大效率。但是如果线程远远超出 CPU 核心数量,反而会使得任务效率下降,因为频繁的切换线程也是要消耗时间的。因此对于 CPU 密集型的任务来说,线程数等于 CPU 数是最好的了。
如果是一个磁盘或网络为主的程序(IO密集型程序),一个线程处在 IO 等待的时候,另一个线程还可以在 CPU 里面跑,有时候 CPU 闲着没事干,所有的线程都在等着 IO,这时候他们就是同时的了,而单线程的话此时还是在一个一个等待的。我们都知道 IO 的速度比起 CPU 来是很慢的。此时线程数等于CPU核心数的两倍是最佳的。
混合型任务:如果应用程序同时执行CPU密集型和IO密集型任务,核心线程数的设置需要综合考虑。通常可以根据具体情况来调整核心线程数。
2)maximumPoolSize:最大允许线程数量(一般是核心线程数2-3倍,不固定)
线程池内部线程数量已经达到核心线程数量,即corePoolSize,并且任务队列已满,此时如果继续有任务被提交,将判断线程池内部线程总数是否达到maximumPoolSize,如果小于maximumPoolSize,将继续使用线程工厂创建新线程。如果线程池内线程数量等于maximumPoolSize,就不会继续创建线程,将触发拒绝策略RejectedExecutionHandler。新创建的同样是一个Work对象,并最终放入workers集合中。
3)keepAliveTime、unit:超出线程的存活时间
当线程池内部的线程数量大于corePoolSize,则多出来的线程会在keepAliveTime时间之后销毁。
如果allowCoreThreadTimeout=true,则会直到线程数量=0
4)workQueue:任务队列
被提交但未执行的任务队列,它是一个BlockingQueue接口的对象,仅用于存放Runnable对象。ThreadPoolExecutor的构造函数中,可使用以下几种BlockingQueue,通常有固定数量的ArrayBlockingQueue,无限制的LinkedBlockingQueue。
1、直接提交队列。
即SynchronousQueue ,这是一个比较特殊的BlockKingQueue, SynchronousQueue没有容量,每一个插入操作都要等待对应的删除操作,反之 一个删除操作都要等待对应的插入操作。 也就是如果使用SynchronousQueue,提交的任务不会被真实保存,而是将新任务交给空闲线程执行,如果没有空闲线程,则创建线程,如果线程数都已经大于最大线程数,则执行拒绝策略。使用这种队列,需要将maximumPoolSize设置的非常大,不然容易执行拒绝策略。比如说
没有最大线程数限制的newCachedThreadPool()
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
但是这个在大量任务的时候,会启用等量的线程去处理,有风险造成系统资源不足。
2、有界任务队列。
有界任务队列可以使用ArrayBlockingQueue实现。需要给一个容量参数表示该队列的最大值。当有新任务进来时,如果当前线程数小于corePoolSize,则会创建新线程执行任务。如果大于,则会将任务放到任务队列中,如果任务队列满了,在当前线程小于将maximumPoolSize的情况下,将会创建新线程,如果大于maximumPoolSize,则执行拒绝策略。
也就是,一阶段,当线程数小于coresize的时候,创建线程;二阶段,当线程任务数大于coresize的时候,放入到队列中;三阶段,队列满,但是还没大于maxsize的时候,创建新线程。 四阶段,队列满,线程数也大于了maxsize, 则执行拒绝策略。
可以发现,有界任务队列,会大概率将任务保持在coresize上,只有队列满了,也就是任务非常繁忙的时候,会到达maxsize。
3、无界任务队列。
使LinkedBlockingQueue实现,队列最大长度限制为Integer.MAX。无界任务队列,不存在任务入队失败的情况, 当任务过来时候,如果线程数小于coresize ,则创建线程,如果大于,则放入到任务队列里面。也就是,线程数几乎会一直维持在coresize大小。FixedThreadPool和SingleThreadPool即是如此。 风险在于,如果任务队列里面任务堆积过多,可能导致内存不足。
4、优先级任务队列。
使用PrioriBlockingQueue ,特殊的无界队列,和普通的先进先出队列不同,它是优先级高的先出。
5)threadFactory:线程工厂
线程池内初初始没有线程,任务来了之后,会使用线程工厂创建线程。
6)rejectedExecutionHandler:任务拒绝处理器
两种情况会拒绝处理任务:
- 当线程数已经达到
maxPoolSize,切队列已满,会拒绝新任务 - 当线程池被调用
shutdown()后,会等待线程池里的任务执行完毕,再shutdown。如果在调用shutdown()和线程池真正shutdown之间提交任务,会拒绝新任务
线程池会调用rejectedExecutionHandler来处理这个任务。如果没有设置默认是AbortPolicy,会抛出异常
ThreadPoolExecutor类有几个内部实现类来处理这类情况:
AbortPolicy丢弃任务,抛运行时异常
-CallerRunsPolicy执行任务
-DiscardPolicy忽视,什么都不会发生
-DiscardOldestPolicy从队列中踢出最先进入队列(最后一个执行)的任务
实现RejectedExecutionHandler接口,可自定义处理器
参考:
JAVA线程池参数详解
Java线程池,知道这些就够了
线程池各个参数详解以及如何自定义线程池
深入理解 Java 线程池:ThreadPoolExecutor
3 线程池的应用
- 异步发送邮件通知,发送一个任务,然后注入到线程池中异步发送。
- 异步送券
- 心跳请求任务,创建一个任务,然后定时发送请求到线程池中
三、Spring相关的问题
1、Spring Aop怎么使用
AOP:是一种面向切面的编程范式,是一种编程思想,旨在通过分离横切关注点,提高模块化,可以跨越对象关注点。Aop的典型应用即spring的事务机制,日志记录。 利用AOP可以对业务逻辑的各个部分进行隔离,从而使得业务逻辑各部分之间的耦合度降低,提高程序的可重用性,同时提高了开发的效率。主要功能是:日志记录,性能统计,安全控制,事务处理,异常处理等等;主要的意图是:将日志记录,性能统计,安全控制,事务处理,异常处理等代码从业务逻辑代码中划分出来,通过对这些行为的分离,我们希望可以将它们独立到非指导业务逻辑的方法中,进而改变这些行为的时候不影响业务逻辑的代码。
AOP技术利用一种称为“横切”的技术,剖解开封装的对象内部,并将那些影响了多个类的公共行为封装到一个可重用模块,并将其名为“Aspect”,即方面。所谓“方面”,简单地说,就是将那些与业务无关,却为业务模块所共同调用的逻辑或责任封装起来,便于减少系统的重复代码,降低模块间的耦合度,并有利于未来的可操作性和可维护性。AOP代表的是一个横向的关系,如果说“对象”是一个空心的圆柱体,其中封装的是对象的属性和行为;那么面向方面编程的方法,就仿佛一把利刃,将这些空心圆柱体剖开,以获得其内部的消息。而剖开的切面,也就是所谓的“方面”了。然后它又以巧夺天功的妙手将这些剖开的切面复原,不留痕迹。
AspectJ和Spring AOP 是AOP的两种实现方案,Aspectj是aop的java实现方案,是一种编译期的用注解形式实现的AOP;Spring aop是aop实现方案的一种,它支持在运行期基于动态代理的方式将aspect织入目标代码中来实现aop,其中动态代理有两种方式(jdk动态代理和cglib动态代理)
参考:
spring项目中aop的使用
2、说一说你对Spring Ioc的理解
控制反转(IoC), IOC是Inversion of Control的缩写,多数书籍翻译成“控制反转”,简单来说就是把复杂系统分解成相互作用合作的对象,这些对象类通过封装以后,内部实现对外部是透明的,从而降低了解决问题的复杂度,而且可以灵活地被重用和扩展.IOC理论提出的观点大体是这样的:借助于“第三方”实现具有依赖关系的对象之间的,如图:
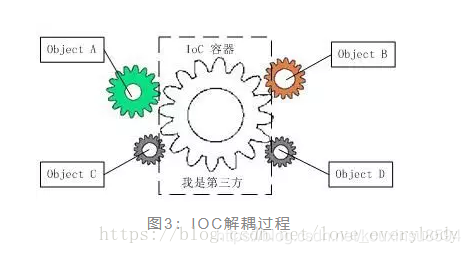
IOC的别名:依赖注入(DI)
实现IOC的方法:注入。所谓依赖注入,就是由IOC容器在运行期间,动态地将某种依赖关系注入到对象之中。
所以,依赖注入(DI)和控制反转(IOC)是从不同的角度的描述的同一件事情,指就是通过引入IOC容器,利用依赖关系注入的方式,实现对象之间的解耦。
3、Spring事务
Spring 支持两种方式的事务管理
1 编程式事务管理
通过 TransactionTemplate或者TransactionManager手动管理事务,实际应用中很少使用,但是对于你理解 Spring 事务管理原理有帮助。
使用TransactionTemplate 进行编程式事务管理的示例代码如下:
@Autowired
private TransactionTemplate transactionTemplate;
public void testTransaction() {
transactionTemplate.execute(new TransactionCallbackWithoutResult() {
@Override
protected void doInTransactionWithoutResult(TransactionStatus transactionStatus) {
try {
// .... 业务代码
} catch (Exception e){
//回滚
transactionStatus.setRollbackOnly();
}
}
});
}
2 声明式事务管理
推荐使用(代码侵入性最小),实际是通过 AOP 实现(基于@Transactional 的全注解方式使用最多)。
使用 @Transactional注解进行事务管理的示例代码如下:
@Transactional(propagation=propagation.PROPAGATION_REQUIRED)
public void aMethod {
//do something
B b = new B();
C c = new C();
b.bMethod();
c.cMethod();
}
事务的其他详解:Spring事务详解
3、spring是如何加载事务的
以注解方式为例子
- 配置文件开启注解驱动,在相关的类和方法上通过注解
@Transactional标识。 spring在启动的时候会去解析生成相关的bean,这时候会查看拥有相关注解的类和方法,并且为这些类和方法生成代理,并根据@Transaction的相关参数进行相关配置注入,这样就在代理中为我们把相关的事务处理掉了(开启正常提交事务,异常回滚事务)。- 真正的数据库层的事务提交和回滚是通过
binlog或者redo log实现的。
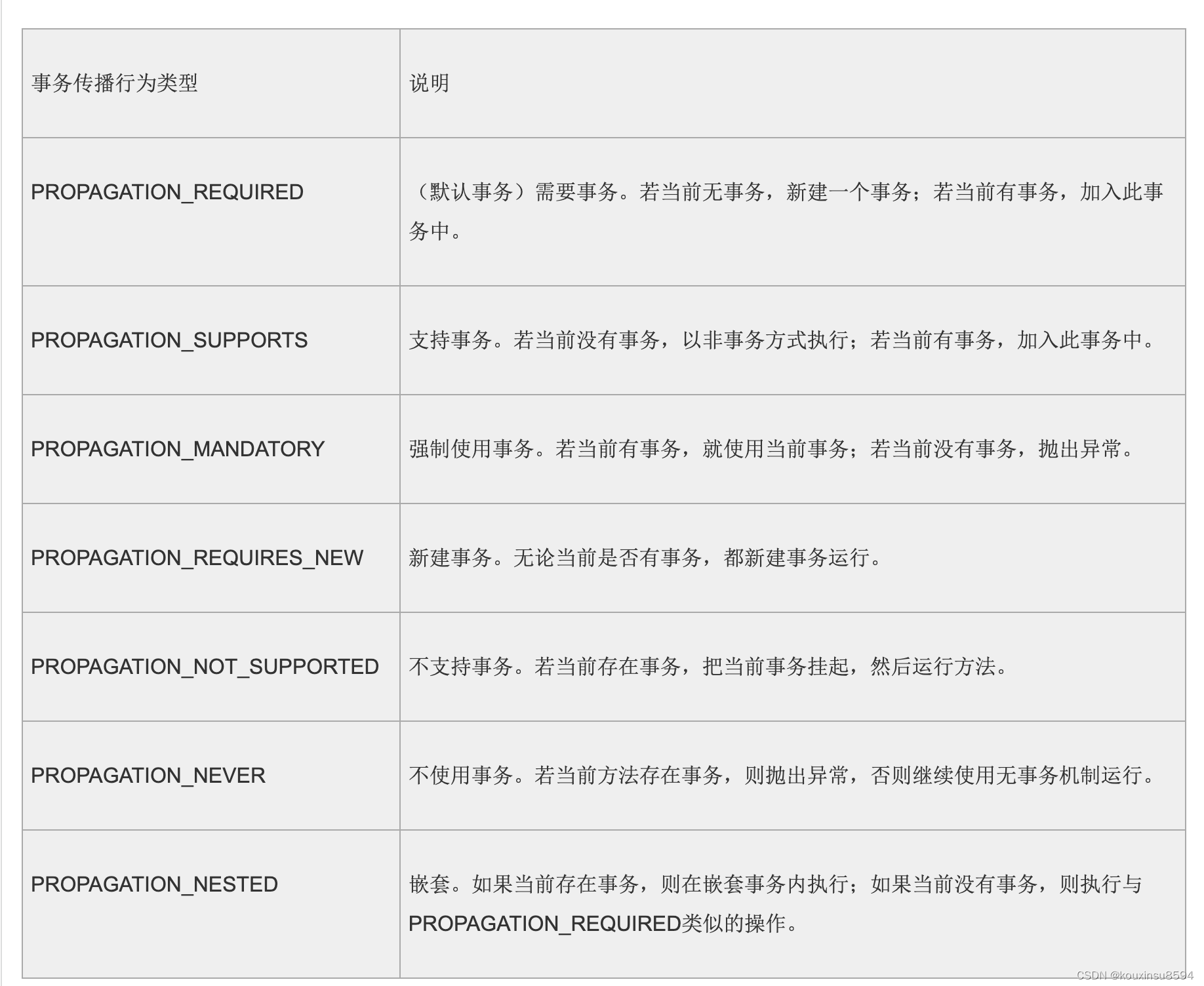
4、Spring事务传播属性
四、Spring boot和Spring Cloud相关
1、Spring boot的主要优点
- 开发基于 Spring 的应用程序很容易。
- Spring Boot 项目所需的开发或工程时间明显减少,通常会提高整体生产力。
- Spring Boot不需要编写大量样板代码、XML配置和注释。
- Spring引导应用程序可以很容易地与Spring生态系统集成,如Spring JDBC、Spring ORM、Spring Data、Spring Security等。
- Spring Boot遵循“固执己见的默认配置”,以减少开发工作(默认配置可以修改)。
- Spring Boot 应用程序提供嵌入式HTTP服务器,如Tomcat和Jetty,可以轻松地开发和测试web应用程序。(这点很赞!普通运行Java程序的方式就能运行基于Spring Boot web 项目,省事很多)
- Spring Boot提供命令行接口(CLI)工具,用于开发和测试Spring Boot应用程序,如Java或Groovy。
- Spring Boot提供了多种插件,可以使用内置工具(如Maven和Gradle)开发和测试Spring Boot应用程序。
2、说一说Spring boot是如何自动加载配置
这个是因为 @SpringBootApplication 注解的原因,在上一个问题中已经提到了这个注解。我们知道 @SpringBootApplication 看作是 @Configuration、@EnableAutoConfiguration、@ComponentScan 注解的集合。
@EnableAutoConfiguration:启用 SpringBoot 的自动配置机制@ComponentScan:扫描被@Component(@Service,@Controller)注解的bean,注解默认会扫描该类所在的包下所有的类。@Configuration:允许在上下文中注册额外的bean或导入其他配置类
@EnableAutoConfiguration是启动自动配置的关键
import java.lang.annotation.Documented;
import java.lang.annotation.ElementType;
import java.lang.annotation.Inherited;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
import org.springframework.context.annotation.Import;
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@AutoConfigurationPackage
@Import({AutoConfigurationImportSelector.class})
public @interface EnableAutoConfiguration {
String ENABLED_OVERRIDE_PROPERTY = "spring.boot.enableautoconfiguration";
Class<?>[] exclude() default {};
String[] excludeName() default {};
}
@EnableAutoConfiguration 注解通过Spring 提供的 @Import 注解导入了AutoConfigurationImportSelector类(@Import 注解可以导入配置类或者Bean到当前类中)。
AutoConfigurationImportSelector类中getCandidateConfigurations方法会将所有自动配置类的信息以 List 的形式返回。这些配置信息会被 Spring 容器作 bean 来管理。
protected List<String> getCandidateConfigurations(AnnotationMetadata metadata, AnnotationAttributes attributes) {
List<String> configurations = SpringFactoriesLoader.loadFactoryNames(getSpringFactoriesLoaderFactoryClass(),
getBeanClassLoader());
Assert.notEmpty(configurations, "No auto configuration classes found in META-INF/spring.factories. If you "
+ "are using a custom packaging, make sure that file is correct.");
return configurations;
}
自动配置信息有了,那么自动配置还差什么呢?
@Conditional 注解。@ConditionalOnClass(指定的类必须存在于类路径下),@ConditionalOnBean(容器中是否有指定的Bean)等等都是对@Conditional注解的扩展。拿 Spring Security 的自动配置举个例子:
SecurityAutoConfiguration中导入了WebSecurityEnablerConfiguration类,WebSecurityEnablerConfiguration源代码如下:
@Configuration
@ConditionalOnBean(WebSecurityConfigurerAdapter.class)
@ConditionalOnMissingBean(name = BeanIds.SPRING_SECURITY_FILTER_CHAIN)
@ConditionalOnWebApplication(type = ConditionalOnWebApplication.Type.SERVLET)
@EnableWebSecurity
public class WebSecurityEnablerConfiguration {
}
WebSecurityEnablerConfiguration类中使用 @ConditionalOnBean 指定了容器中必须还有WebSecurityConfigurerAdapter 类或其实现类。所以,一般情况下 Spring Security 配置类都会去实现 WebSecurityConfigurerAdapter,这样自动将配置就完成了。
参考:
(重要)Spring Boot 的自动配置是如何实现的?
3、说一说Spring Cloud中的Eureka的原理
Eureka 就是 Netflix 的 服务发现框架
Eureka高可用集群:
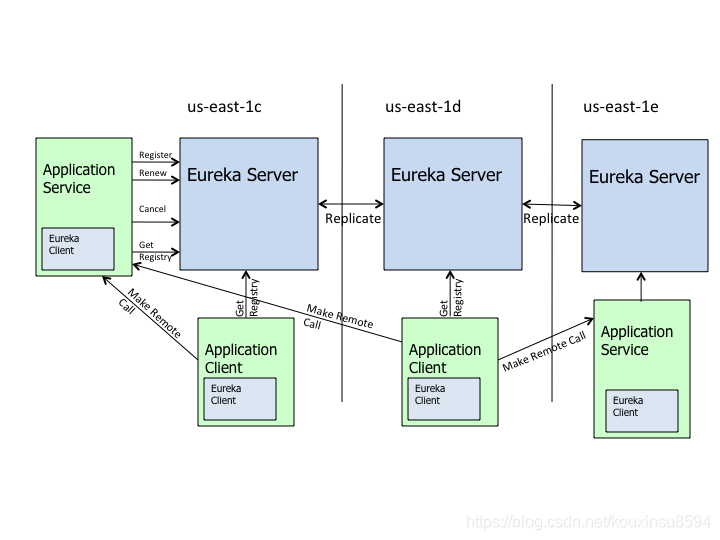
这是基于集群配置的eureka;
- 处于不同节点的eureka通过Replicate进行数据同步
- Application Service为服务提供者
- Application Client为服务消费者
- Make Remote Call完成一次服务调用
服务启动后向Eureka注册,Eureka Server会将注册信息向其他Eureka Server进行同步,当服务消费者要调用服务提供者,则向服务注册中心获取服务提供者地址,然后会将服务提供者地址缓存在本地,下次再调用时,则直接从本地缓存中取,完成一次调用。
当服务注册中心Eureka Server检测到服务提供者因为宕机、网络原因不可用时,则在服务注册中心将服务置为DOWN状态,并把当前服务提供者状态向订阅者发布,订阅过的服务消费者更新本地缓存。
服务提供者在启动后,周期性(默认30秒)向Eureka Server发送心跳,以证明当前服务是可用状态。Eureka Server在一定的时间(默认90秒)未收到客户端的心跳,则认为服务宕机,注销该实例。
参考:
深入浅出 Spring Cloud 之 Eureka
4、说一说Fegin的工作流程
Feign是一个声明式的REST客户端,它的目的就是让REST调用更加简单。
Feign的工作流:
@EnableFeignClients 表示开启Feign功能,然后扫描 注解@FeignClient,程序启动后,会将这些类扫描进IOC容器;Feign会 对 RestTemplate 进行 封装,生成代理时,Feign会为每个接口方法创建一个RequestTemplate对象,简化HTTP远程过程调用;RestTemplate使用Request 模板生成新的Requst 发送请求,其底层通常是基于URLConnection,最后Client被封装到LoadBalanceClient类,这个类结合Ribbon负载均衡发器实现服务之间的调用。
从源码上看Feign的调用过程:
-
将
EnableFeignClients注解对应的配置属性注入; -
将
FeignClient注解对应的属性注入。 -
生成
FeignClient对应的bean,注入到Spring的IOC容器。 -
在
registerFeignClient方法中构造了一个BeanDefinitionBuilder对象,BeanDefinitionBuilder的主要作用就是构建一个AbstractBeanDefinition,AbstractBeanDefinition类最终被构建成一个BeanDefinitionHolder然后注册到Spring中。
注意:beanDefinition类为FeignClientFactoryBean,故在Spring获取类的时候实际返回的是FeignClientFactoryBean类。 -
通过
FeignClientFactoryBean的getObject()方法得到不同动态代理的类并为每个方法创建一个SynchronousMethodHandler对象; -
为每一个方法创建一个动态代理对象, 动态代理的实现是
ReflectiveFeign.FeignInvocationHanlder,代理被调用的时候,会根据当前调用的方法,转到对应的SynchronousMethodHandler
参考:
springcloud-Feign配置
Spring Cloud Feign 调用过程分析
5、spring cloud Hystrix
1 熔断器机制
当Hystrix Command请求后端服务失败数量超过一定比例(默认50%), 断路器会切换到开路状态(Open). 这时所有请求会直接失败而不会发送到后端服务. 断路器保持在开路状态一段时间后(默认5秒), 自动切换到半开路状态(HALF-OPEN). 这时会判断下一次请求的返回情况, 如果请求成功, 断路器切回闭路状态(CLOSED), 否则重新切换到开路状态(OPEN)。Hystrix的断路器就像我们家庭电路中的保险丝, 一旦后端服务不可用, 断路器会直接切断请求链, 避免发送大量无效请求影响系统吞吐量, 并且断路器有自我检测并恢复的能力.
2 降级
Fallback相当于是降级操作。 对于查询操作, 我们可以实现一个fallback方法, 当请求后端服务出现异常的时候, 可以使用fallback方法返回的值。 fallback方法的返回值一般是设置的默认值或者来自缓存。
3 资源隔离
在Hystrix中,主要通过线程池来实现资源隔离。 通常在使用的时候我们会根据调用的远程服务划分出多个线程池。 例如调用产品服务的Command放入A线程池,调用账户服务的Command放入B线程池。 这样做的主要优点是运行环境被隔离开了。 这样就算调用服务的代码存在bug或者由于其他原因导致自己所在线程池被耗尽时,不会对系统的其他服务造成影响。 但是带来的代价就是维护多个线程池会对系统带来额外的性能开销。 如果是对性能有严格要求而且确信自己调用服务的客户端代码不会出问题的话,可以使用Hystrix的信号模式(Semaphores)来隔离资源。
Hystrix的集成参考白话SpringCloud | 第五章:服务容错保护(Hystrix)
6、Spring Cloud Ribbon
1 什么是负载调用
负载均衡(Load Balance)是分布式系统架构设计中必须考虑的因素之一,它通常是指,将请求/数据【均匀】分摊到多个操作单元上执行,负载均衡的关键在于【均匀】。
1 服务器端负载均衡和客户端负载均衡的区别
服务器端负载均衡:例如Nginx,通过Nginx进行负载均衡,先发送请求,然后通过负载均衡算法,在多个服务器之间选择一个进行访问;
客户端负载均衡:例如spring cloud中的ribbon,客户端会有一个服务器地址列表,在发送请求前通过负载均衡算法选择一个服务器,然后进行访问,这是客户端负载均衡;
2 负载调用的实现方式
1)【协议层】http重定向协议实现负载均衡
2)【协议层】dns域名解析负载均衡
3)【协议层】反向代理负载均衡
4)【网络层】IP负载均衡
5)【链路层】数据链路层负载均衡
参考:
几种负载均衡技术的实现
3 Ribbon的几种负载均衡算法
负载均衡,不管 Nginx 还是 Ribbon 都需要其算法的支持,如果我没记错的话 Nginx 使用的是 轮询和加权轮询算法。而在 Ribbon 中有更多的负载均衡调度算法,其默认是使用的 RoundRobinRule 轮询策略。
RoundRobinRule:轮询策略。Ribbon 默认采用的策略。若经过一轮轮询没有找到可用的provider,其最多轮询 10 轮。若最终还没有找到,则返回 null。RandomRule: 随机策略,从所有可用的provider中随机选择一个。RetryRule: 重试策略。先按照RoundRobinRule策略获取provider,若获取失败,则在指定的时限内重试。默认的时限为 500 毫秒。
更换默认的负载均衡算法,只需要在配置文件中做出修改就行。
providerName:
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule
当然,在 Ribbon 中你还可以自定义负载均衡算法,你只需要实现 IRule 接口,然后修改配置文件或者自定义 Java Config 类。
7、Spring Cloud Zuul
Zuul的功能:
- Zuul 注册于 Eureka 并集成了 Ribbon 所以自然也是可以从注册中心获取到服务列表进行客户端负载。
- 功能丰富的路由功能,解放运维。
- 具有过滤器,所以鉴权、验签都可以集成。
通过服务发现自动映射路由
Eureka配合Zuul使用的优美之处在于,不仅可以通过单个端点来访问应用的所有服务,而且,在添加或移除服务实例的时候不用修改Zuul的路由配置。另外,也可以添加一个新的服务到Eureka,而Zuul会对访问新添加的服务自动路由,因为Zuul是通过与Eureka通信然后从Eureka获取微服务实例真正物理地址,只要服务托管在Eureka中。
在项目中使用到Zuul这块主要是用在了负载均衡反向代理。这里记录一下Zuul的路由的使用。
参考:
sbc(六) Zuul GateWay 网关应用
服务网关——Spring Cloud Zuul
8、Spring boot中配置相关
1 配置文件中Map和List类型是如何配置的?
-
在
yml或者properties文件中写需要的配置(下面是yml文件中的写法):
Map:person.maps: {key1: value1,key2: value2}List、Set:person: list: [1,2,3] -
在pom文件加入
spring-boot-configuration-processor依赖<!--导入配置文件处理器,配置文件进行绑定就会有提示--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-configuration-processor</artifactId> <optional>true</optional> </dependency> -
创建一个与配置文件相关的配置文件,如之前的配置文件前缀是
person@Component // 或者@Configuration @ConfigurationProperties(prefix = "person") public class Person { private Map<String,Object> maps; private List<String> list; private String name; private int age; public Map<String, Object> getMaps() { return maps; } public void setMaps(Map<String, Object> maps) { this.maps = maps; } public List<String> getList() { return list; } public void setList(List<String> list) { this.list = list; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } }@ConfigurationProperties注解向Spring Boot声明该类中的所有属性和配置文件中相关的配置进行绑定。prefix = "person":声明配置前戳,将该前戳下的所有属性进行映射。
@Component或者@Configuration:将该组件加入Spring Boot容器,只有这个组件是容器中的组件,配置才生效。
参考:
最全面的SpringBoot配置文件详解
Spring Boot配置文件详解
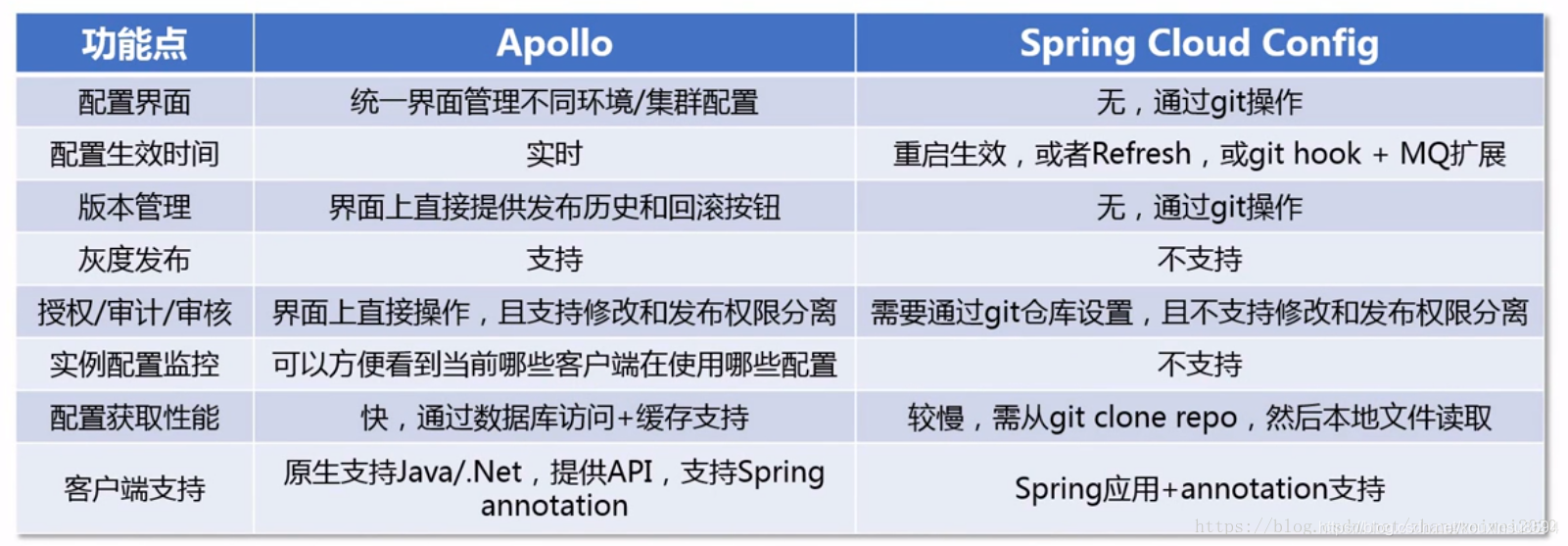
9、spring cloud config和apollo有什么区别
五、sql相关
1、索引相关
1 sql索引命中
SQL优化建议:
-
应尽量避免在
where子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描。 -
对查询进行优化,应尽量避免全表扫描,首先应考虑在
where及order by涉及的列上建立索引。 -
应尽量避免在
where子句中对字段进行null值判断,否则将导致引擎放弃使用索引而进行全表扫描。如:
select id from t where num is null
可以在num上设置默认值为0,确保表中num列没有null值,然后这样查询:
select id from t where num =0 -
尽量避免在
where子句中使用or来连接条件,前后都得有索引否则可能导致引擎放弃使用索引而进行全表扫描(上面已有例子). -
下面的查询也将导致全表扫描:(不能前置百分号),例:
select id from t where name like ‘%product_no%’
若要提高效率可以考虑全文索引最好改为:
select id from t where name like 'product_no%' -
对于
in,not in要慎用。 例 :EXPLAIN SELECT * FROM tc_test WHERE pripid NOT IN (1,2,3) -
应尽量避免在
where子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描。如:EXPLAIN SELECT * FROM tc_test WHERE pripid/2=100
应改为:select * from t where pripid=200 -
应尽量避免在
where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描。如:
-- enttype以41开头的pripid
EXPLAIN SELECT pripid FROM tc_test WHERE SUBSTRING(enttype,1,2)='41'
应改为: expalin select pripid from tc_test where pripid like '41%'
-
不要在
where子句中的=左边进行函数、算术运算或其他表达式运算,否则系统将可能无法正确使用索引 -
在使用索引字段作为条件时,如果该索引是复合索引,那么必须使用到该索引中的第一个字段作为条件时才能保证系统使用该索引,否则该索引将不会被使用,并且应尽可能的让字段顺序与索引顺序相一致。
-
很多时候用 exists 代替 in 是一个好的选择:
select num from a where num in(select num from b)
用下面的语句替换:
select num from a where exists(select 1 from b where num=a.num) -
并不是所有索引对查询都有效,SQL是根据表中数据来进行查询优化的,当索引列有大量数据重复时,SQL查询可能不会去利用索引,如一表中有字段 sex,male、female几乎各一半,那么即使在sex上建了索引也对查询效率起不了作用
-
索引并不是越多越好,索引固然可以提高相应的
select的效率,但同时也降低了insert及update的效率,因为insert或update时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。一个表的索引数较好不要超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有必要. -
如果在 where 子句中使用参数,也会导致全表扫描。因为SQL只有在运行时才会解析局部变量,但优化程序不能将访问计划的选择推迟到运行时;它必须在编译时进行选择。然 而,如果在编译时建立访问计划,变量的值还是未知的,因而无法作为索引选择的输入项。
如下面语句将进行全表扫描:select id from t where num = @num
可以改为强制查询使用索引:select id from t with(index(索引名)) where num = @num -
应尽可能的避免更新
clustered索引数据列,因为clustered索引数据列的顺序就是表记录的物理存储顺序,一旦该列值改变将导致整个表记录的顺序的调整,会耗费相当大的资源。若应用系统需要频繁更新clustered索引数据列,那么需要考虑是否应将该索引建为clustered索引 -
尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。这是因为引擎在处理查询和连接时会 逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了!
-
尽可能的使用
varchar/nvarchar代替char/nchar,因为首先变长字段存储空间小,可以节省存储空间,其次对于查询来说,在一个相对较小的字段内搜索效率显然要高些。 -
任何地方都不要使用
select * from t,用具体的字段列表代替*,不要返回用不到的任何字段。 -
尽量避免向客户端返回大数据量,若数据量过大,应该考虑相应需求是否合理。
-
尽量避免大事务操作,提高系统并发能力.
-
MySql的子查询实现的非常糟糕。最糟糕的一类查询是
WHERE条件中包含IN()的子查询语句。应该尽可能用关联替换子查询,可以提高查询效率。
参考:
SQL优化一键命中索引
2 索引类型
从索引的实现上,我们可以将其分为聚集索引与非聚集索引,或称辅助索引或二级索引,这两大类;从索引的实际应用中,又可以细分为普通索引、唯一索引、主键索引、联合索引、外键索引、全文索引这几种。
参考:
MySQL 索引的原理与应用:索引类型,存储结构与锁
3 索引的数据结构
目前大部分数据库系统及文件系统都采用B-Tree或其变种B+Tree作为索引结构。MySQL就普遍使用B+Tree实现其索引结构。
B+的特性:
- 所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好是有序的;
- 不可能在非叶子结点命中;
- 非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储(关键字)数据的数据层;
- 更适合文件索引系统;
B+tree的优点:
- B±tree的磁盘读写代价更低
B+ tree的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对B 树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了。
举个例子,假设磁盘中的一个盘块容纳16bytes,而一个关键字2bytes,一个关键字具体信息指针2bytes。一棵9阶B-tree(一个结点最多8个关键字)的内部结点需要2个盘快。而**B+树内部结点只需要1个盘快。当需要把内部结点读入内存中的时候,B 树就比B+ **树多一次盘块查找时间(在磁盘中就是盘片旋转的时间)。 - B±tree的查询效率更加稳定
由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
参考:
干货:mysql索引的数据结构
4 索引匹配原则
1 最左匹配原则
在mysql建立联合索引时会遵循前缀匹配原则,即最左优先,在检索数据时从联合索引的最左边开始匹配,示例:
KEY test_col1_col2_col3 on test(col1,col2,col3);
联合索引test_col1_col2_col3实际建立了(col1),(col1,col2),(col1,col2,col3)三个索引。
select * from test where col1="1" and col2="2" and col4="4"
上面这个查询语句执行时会按照最左匹配的原则,检索时会使用索引
(col1,col2)。
2 为什么要使用联合索引
-
减少开销。建一个联合索引
(col1,col2,col3),实际相当于建了(col1),(col1,col2),(col1,col2,col3)三个索引。每多一个索引,都会增加写操作的开销和磁盘空间的开销。对于大量数据的表,使用联合索引会大大的减少开销! -
覆盖索引。对联合索引
(col1,col2,col3),如果有如下的sql:select col1,col2,col3 from test where col1=1 and col2=2.那么MySQL可以直接通过遍历索引取得数据,而无需回表,这减少了很多的
随机io操作。减少io操作,特别的随机io其实是dba主要的优化策略。所以,在真正的实际应用中,盖索引是主要的提升性能的优化手段之一。 -
效率高。索引列越多,通过索引筛选出的数据越少。有1000W条数据的表,有如下sql:
select from table where col1=1 and col2=2 and col3=3
,假设假设每个条件可以筛选出10%的数据,如果只有单值索引,那么通过该索引能筛选出1000W10%=100w条数据,然后再回表从100w条数据中找到
符合col2=2 and col3=3的数据,然后再排序,再分页;如果是联合索引,通过索引筛选出1000w10%10%*10%=1w,效率提升可想而知!
参考:
Mysql联合索引最左匹配原则
5 哪些字段可以用来做为索引?
1、表的主键、外键必须有索引;
2、数据量超过300的表应该有索引;
3、经常与其他表进行连接的表,在连接字段上应该建立索引;
4、经常出现在Where子句中的字段,特别是大表的字段,应该建立索引;
5、索引应该建在选择性高的字段上;
6、索引应该建在小字段上,对于大的文本字段甚至超长字段,不要建索引;
7、复合索引的建立需要进行仔细分析;尽量考虑用单字段索引代替:
A、正确选择复合索引中的主列字段,一般是选择性较好的字段;
B、复合索引的几个字段是否经常同时以AND方式出现在Where子句中?单字段查询是否极少甚至没有?如果是,则可以建立复合索引;否则考虑单字段索引;
C、如果复合索引中包含的字段经常单独出现在Where子句中,则分解为多个单字段索引;
D、如果复合索引所包含的字段超过3个,那么仔细考虑其必要性,考虑减少复合的字段;
E、如果既有单字段索引,又有这几个字段上的复合索引,一般可以删除复合索引;
8、频繁进行数据操作的表,不要建立太多的索引;
9、删除无用的索引,避免对执行计划造成负面影响;
6 了解前缀索引吗?
前缀索引:对文本的前几个字符建立索引(具体是几个字符在建立索引时去指定),比如以产品名称的前 10 位来建索引,这样建立起来的索引更小,查询效率更快!
但是mysql中无法使用前缀索引进行 ORDER BY 和 GROUP BY,也无法用来进行覆盖扫描。
这样设置解决什么问题:
- 能有效的减小索引文件的大小,让每个索引页可以保存更多的索引值,从而提高了索引查询的速度;
- 节省索引存储空间。
2、左连接和内连接的区别
内连接:取的两个表的(有能连接的字段)的交集,即字段相同的。
外连接:左右连接。
left join(左连接)返回包括左表中的所有记录和右表中连接字段相等的记录,将左表没有的对应项显示,右表的列为NULL
right join(右连接)返回包括右表中的所有记录和左表中连接字段相等的记录,将右表没有的对应项显示,左表的列为NULL
inner join (等值连接)只返回两个表中联结字段相等的
3、如何区分是行锁还是表锁
mysql的行锁是通过索引加载的,即是行锁是加在索引响应的行上的
要是对应的SQL语句没有走索引,则会全表扫描,行锁则无法实现,取而代之的是表锁。
- 表锁:不会出现死锁,发生锁冲突几率高,并发低。
- 行锁:会出现死锁,发生锁冲突几率低,并发高。
锁冲突:例如说事务A将某几行上锁后,事务B又对其上锁,锁不能共存否则会出现锁冲突。(但是共享锁可以共存,共享锁和排它锁不能共存,排它锁和排他锁也不可以)
死锁:例如说两个事务,事务A锁住了1-5行,同时事务B锁住了6-10行,此时事务A请求锁住6-10行,就会阻塞直到事务B施放6-10行的锁,而随后事务B又请求锁住1-5行,事务B也阻塞直到事务A释放1~5行的锁。死锁发生时,会产生Deadlock错误。
锁是对表操作的,所以自然锁住全表的表锁就不会出现死锁。
4、mybatis框架
1 使用mybatis框架连接数据库与直连数据库有什么区别?说一说mybatis框架的优点
JDBC的工作量大:需要先注册驱动和数据库信息、操作Connection、通过statement对象执行SQL,将结果返回给resultSet,然后从resultSet中读取数据并转换为pojo对象,最后需要关闭数据库相关资源。
而且还需要自己对JDBC过程的异常进行捕捉和处理。
而MyBatis使用SqlSessionFactoryBuilder来连接完成JDBC需要代码完成的数据库获取和连接,减少了代码的重复。JDBC将SQL语句写到代码里,属于硬编码,非常不易维护,MyBatis可以将SQL代码写入xml中,易于修改和维护。JDBC的resultSet需要用户自己去读取并生成对应的POJO,MyBatis的mapper会自动将执行后的结果映射到对应的Java对象中。
mybatis框架优点:
- 与JDBC相比,减少了50%以上的代码量
- 最简单的持久化框架、小巧简单易学
- SQL代码从程序代码中彻底分离出来,可重用
- 提供XML标签,支持编写动态SQL
- 提供映射标签,支持对象与数据库的ORM字段关系映射
mybatis框架缺点:
- SQL语句编写工作量大,熟练度要高
- 数据库移植性差,比如mysql移植到Orecle,SQL语句会有差异从而引起err
mybatis框架适用场合:
MyBatis专注于SQL本身,是一个足够灵活的DAO层解决方案。
对性能的要求很高,或者需求变化较多的项目,如互联网项目,MyBatis将是不错的选择。
参考:
MyBatis与JDBC的比较
MyBatis框架的优缺点及其适用场合
MyBatis框架的优缺点
2 mybatis框架中#和$有什么区别
#{}:占位符号(在对数据解析时会对数据自动添加' ')
${}:sql拼接符号(替换结果不会增加单引号‘ ’,like和order by后使用,存在sql注入问题,需手动代码中过滤)
mybatis什么情况下必须要使用${}格式?
在涉及到动态表名和列名时,必须使用${xxxxx}进行注入。
order by:
因为#是按string类型拼接,就成为:order by ‘cloumn’ ‘desc’。
使用$则为:order by cloumn desc。
limit:
例: limit #{index}, #{rows}
like
例: and prod_name like ‘%${prodName}%’
解决这个类${xxxx}的防SQL的方案:java判断一下输入的参数的长度是否正常。
3 mybatis中的一级缓存和二级缓存有了解吗?
一级缓存
一级缓存是SqlSession级别的缓存。在操作数据库时需要构造sqlSession对象,在对象中有一个数据结构用于存储缓存数据。不同的sqlSession之间的缓存数据区域是互相不影响的。也就是他只能作用在同一个sqlSession中,不同的sqlSession中的缓存是互相不能读取的。
一级缓存的工作原理:
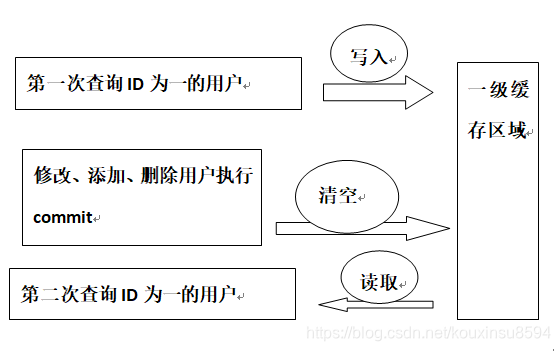
用户发起查询请求,查找某条数据,sqlSession先去缓存中查找,是否有该数据,如果有,读取;如果没有,从数据库中查询,并将查询到的数据放入一级缓存区域,供下次查找使用。但sqlSession执行commit,即增删改操作时会清空缓存。这么做的目的是避免脏读。
如果commit不清空缓存,会有以下场景:A查询了某商品库存为10件,并将10件库存的数据存入缓存中,之后被客户买走了10件,数据被delete了,但是下次查询这件商品时,并不从数据库中查询,而是从缓存中查询,就会出现错误。
二级缓存
二级缓存是mapper级别的缓存,多个SqlSession去操作同一个Mapper的sql语句,多个SqlSession可以共用二级缓存,二级缓存是跨SqlSession的。二级缓存的作用范围更大。还有一个原因,实际开发中,MyBatis通常和Spring进行整合开发。Spring将事务放到Service中管理,对于每一个service中的sqlsession是不同的,这是通过mybatis-spring中的org.mybatis.spring.mapper.MapperScannerConfigurer创建sqlsession自动注入到service中的。 每次查询之后都要进行关闭sqlSession,关闭之后数据被清空。所以Spring整合之后,如果没有事务,一级缓存是没有意义的。二级缓存默认是关闭的状态,开启需要再setting全局参数中配置二级缓存。
二级缓存原理:
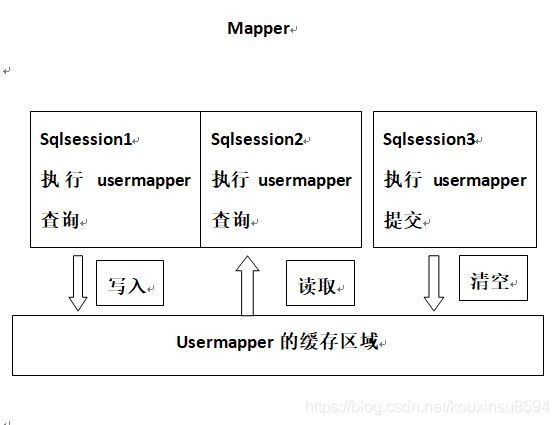
UserMapper有一个二级缓存区域(按namespace分),其它mapper也有自己的二级缓存区域(按namespace分)。每一个namespace的mapper都有一个二级缓存区域,两个mapper的namespace如果相同,这两个mapper执行sql查询到数据将存在相同的二级缓存区域中。
参考:
深入理解MyBatis中的一级缓存与二级缓存
Mybatis的缓存机制(一级缓存二级缓存和刷新缓存)和Mybatis整合ehcache
4、MyBatis SqlSession的作用
SqlSession 的作用类似于一个 JDBC 中的 Connection 对象,代表着一个连接资源的启用。具体而言,它的作用有 3 个:
- 获取 Mapper 接口。
- 发送 SQL 给数据库。
- 控制数据库事务。
SqlSession的最佳的作用域是请求或方法作用域。
5、MyBatis中resultType和resultMap的区别
- 类的名字和数据库相同时,可以直接设置 resultType 参数为 Pojo 类
- 若不同,需要设置 resultMap 将结果名字和 Pojo 名字进行转换
6、Mybatis的xml文件中常用的标签
7、Mybatis中 mapper.java和mapper.xml是如何映射起来的
mybatis里所有mapper接口的实现类都可以看做是mapperProxy,mapper代理类,然后调用MapperProxy.invoke()方法,invoke()方法会执行相应sql语句,并将结果返回。
参考:
【Mybatis】- mapper.java和mapper.xml是如何映射起来的-源码分析
5、如何高效的在大量数据(百万级甚至更多)的oracle数据库表中筛选错误数据
第一步:分表
如果历史表中存储了很多年的数据,会造成严重的数据冗余。那如果将历史表分表存储,比如每年创建一个表,数据存储到对应的年表中,必定会减少很多数据量。(如果分成年表数据量还是过大,可以细分到月表,天表…)。
第二步:分区
年表创建过后,查询就是查询年表中的数据,可是虽然分表了,但是年表中的数据量仍然很大,查询速度虽然有提升,但并不能满足用户的要求。便考虑到分表再分区,即将历史数据以不同的年表来存储,在年表中按月分区。
数据库分区:就是减少SQL操作的数据量,从而提升查询效率。表分区后,逻辑上仍然是一张表,只不过将表中的数据在物理上存放到多个表空间上。这样在查询数据时,会查询相应分区的数据,避免了全表扫描。
分区又分为水平分区、垂直分区。
水平分区:就是对行进行分区,举个例子来说,就是一个表中有1000万条数据,每100万条数据划一个分区,这样就将表中数据分到10个分区中去。水平分区要通过某个特定的属性列进行分区,比如我用的列就是Date时间。
垂直分区:通过对标垂直划分来减少表的宽度,从而提升查询效率。比如一个学生表中,有他相关的信息列,还有论文列以CLOB存储。这些以CLOB存储的论文并不会经常被访问到,这时候就要把这些不经常使用的CLOB划分到另一个分区,需要访问时再调用它。
要在大量数据中高效地筛选错误数据,可以采取以下几种方式:
1、使用索引:在经常用于筛选的列上创建索引,可以大大提高查询速度。尤其是对于错误数据的筛选,通常不需要全表扫描。
CREATE INDEX error_index ON large_table (error_column);
2、分区表:将大表划分为多个较小的部分。这样,针对某一个分区的查询会更快。分区通常基于时间或其他关键字段进行。
CREATE TABLE large_table (
column1 data_type,
column2 data_type,
...
) PARTITION BY RANGE (column_name)
( PARTITION partition_name VALUES LESS THAN (value) );
3、增量刷新策略:定期刷新(如每天)从上次刷新决策时发生的新记录中提取错误数据。可使用如 TRUNCATE 和 INSERT INTO 的策略进行。避免每次都运行全量查询,节省时间成本。
TRUNCATE TABLE error_data;
INSERT INTO error_data
SELECT * FROM large_table
WHERE error_criteria = 1
AND creation_date >= TRUNC(SYSDATE-1);
4、并行查询:使用 PARALLEL 关键字以并行方式扫描表中的错误数据。
SELECT /*+ PARALLEL(large_table, 8) */ *
FROM large_table
WHERE error_criteria = 1;
5、材化视图:根据常见的错误筛选创建一个材化视图,并定期刷新。这样可以有效加速频繁的筛选操作。
CREATE MATERIALIZED VIEW error_mv
REFRESH FAST START WITH SYSDATE NEXT SYSDATE + 1/24 -- 每小时刷新一次
AS
SELECT * FROM large_table
WHERE error_criteria = 1;
6、事务相关
1 简述一下ACID
1)原子性(Atomicity)
事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
这指的是在并发环境中,当不同的事务同时操纵相同的数据时,每个事务都有各自的完整数据空间。由并发事务所做的修改必须与任何其他并发事务所做的修改隔离。事务查看数据更新时,数据所处的状态要么是另一事务修改它之前的状态,要么是另一事务修改它之后的状态,事务不会查看到中间状态的数据。
2)一致性(Consistency)
一致性是指在事务开始之前和事务结束以后,数据库的完整性约束没有被破坏。这是说数据库事务不能破坏关系数据的完整性以及业务逻辑上的一致性。
3)隔离性(Isolation)
多个事务并发访问时,事务之间是隔离的,一个事务不应该影响其它事务运行效果。
隔离级别
-
未提交读: 在读数据时不会检查或使用任何锁。因此,在这种隔离级别中可能读取到没有提交的数据。 不可避免 脏读、不可重复读、虚读。
-
已提交读:只读取提交的数据并等待其他事务释放排他锁。读数据的共享锁在读操作完成后立即释放。已提交读是SQL Server的默认隔离级别。 避免了脏读,但是可能会造成不可重复读。oracle采用读已提交。
-
可重复读: 像已提交读级别那样读数据,但会保持共享锁直到事务结束。 可以避免不可重复读。但还有可能出现幻读 。mysql采用可重复读。
-
可串行读:工作方式类似于可重复读。但它不仅会锁定受影响的数据,还会锁定这个范围。这就阻止了新数据插入查询所涉及的范围。可避免 脏读、不可重复读、幻读情况的发生
4)持久性(Durability)
持久性,意味着在事务完成以后,该事务所对数据库所作的更改便持久的保存在数据库之中,并不会被回滚。即使出现了任何事故比如断电等,事务一旦提交,则持久化保存在数据库中。
参考:
谈谈数据库的ACID
6、索引结构
B+树(Mysql InnoDB和MyIsam使用,B-Tree变种)
- 非叶子节点不存储data,只存储索引(冗余),可以放更多的索引
- 叶子节点包含所有索引字段
- 叶子节点用指针连接,提高区间访问的性能
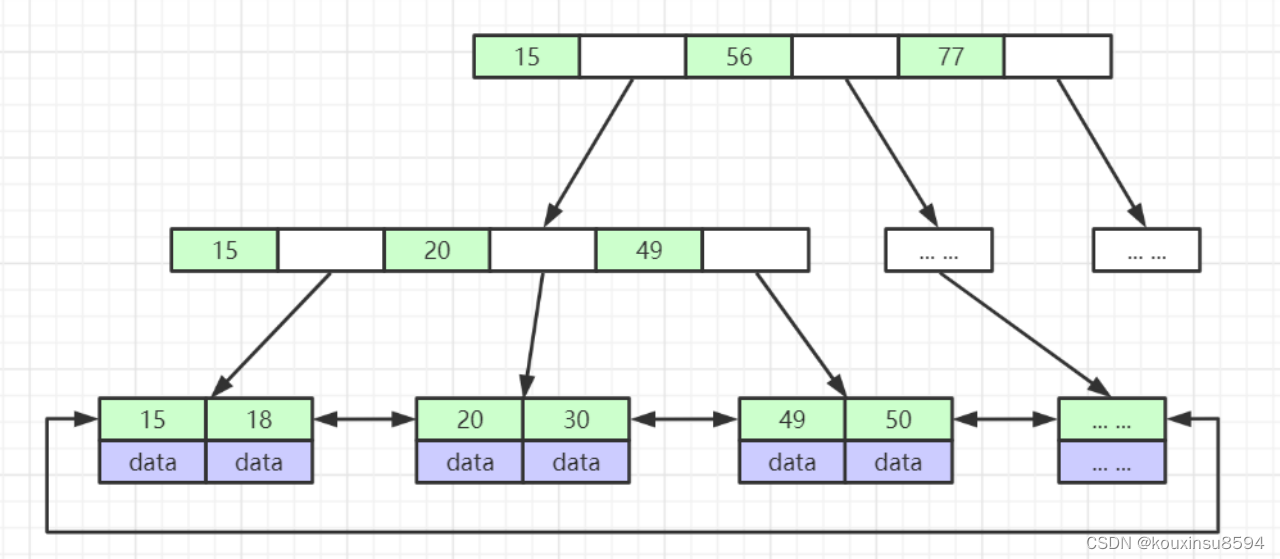
B-Tree
- 叶节点具有相同的深度,叶节点的指针为空
- 所有索引元素不重复
- 节点中的数据索引从左到右递增排列

与B+树的区别
- 所有的data都在子节点
- 叶节点没有区间指针
mysql使用b+树的原因
- 提高索引查询时的磁盘IO效率。还可以提高范围查询的效率
- 所有查询都要查找叶子节点,查询性能稳定
- B+树里的元素也都是有序的
Hash
- 对索引的key进行一次hash计算就可以定位出数据存储的位置
- 很多时候Hash索引要比B+ 树索引更高效
- 仅能满足 “=”,“IN”,不支持范围查询
- hash冲突问题
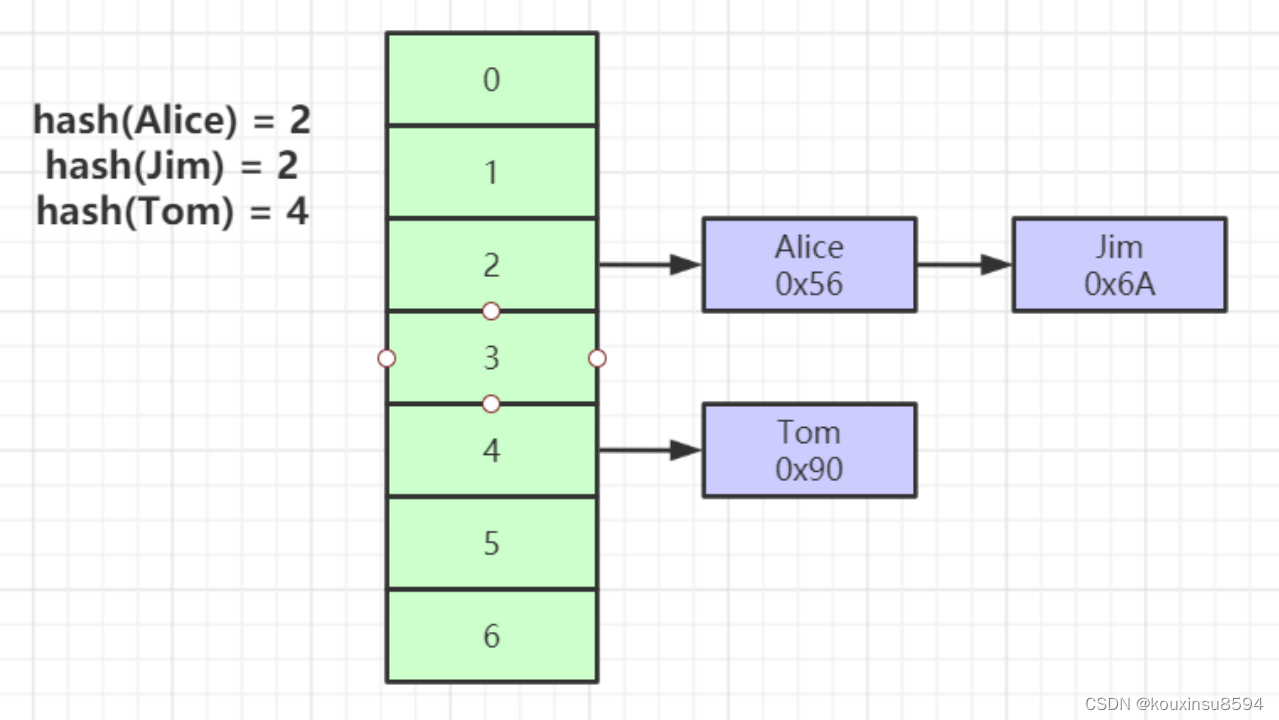
其他关联文档:
MySQL索引详解
7、慢SQL调优怎么处理
1、找到慢查询 SQL
首先需要找到慢查询 SQL,可以通过使用 MySQL 自带的慢查询日志(slow query log)来实现。在 MySQL 配置文件中启用慢查询日志,然后将执行时间超过阈值的 SQL 查询语句记录到慢查询日志中。通过分析慢查询日志,可以找到执行时间较长的 SQL 查询语句。
- 打开MySQL配置文件 my.cnf。该文件通常位于
/etc/mysql目录下。 - 找到
[mysqld]段落. - 添加或修改以下行:
slow_query_log = 1 # 启用慢查询日志
slow_query_log_file = /var/log/mysql/mysql-slow.log # 指定慢查询日志文件路径
long_query_time = 10 # 指定查询执行时间超过多少秒时被认为是慢查询
注意:上述示例中,慢查询日志文件路径为 /var/log/mysql/mysql-slow.log,您可以根据需要更改为其他路径。
-
保存并关闭文件。
-
重新启动MySQL服务以使更改生效。
-
确认慢查询日志是否在指定的路径中生成。
要查看慢查询日志,您可以使用以下命令:
sudo tail -f /var/log/mysql/mysql-slow.log
2、分析慢查询 SQL
找到慢查询 SQL 后,需要对 SQL 进行分析,了解 SQL 查询语句的执行计划、索引使用情况等信息。可以通过 MySQL 自带的 Explain 命令来查看 SQL 的执行计划,以及哪些索引被使用了。根据执行计划和索引使用情况,可以确定 SQL 查询语句的瓶颈所在。
1 获取SQL执行计划
MySQL 为我们提供了 EXPLAIN 命令,来获取执行计划的相关信息。需要注意的是,EXPLAIN 语句并不会真的去执行相关的语句,而是通过查询优化器对语句进行分析,找出最优的查询方案,并显示对应的信息。EXPLAIN 执行计划支持 SELECT、DELETE、INSERT、REPLACE 以及 UPDATE 语句。我们一般多用于分析 SELECT 查询语句,使用起来非常简单,语法如下:
EXPLAIN + SELECT 查询语句;
例子:
mysql> explain SELECT * FROM dept_emp WHERE emp_no IN (SELECT emp_no FROM dept_emp GROUP BY emp_no HAVING COUNT(emp_no)>1);
+----+-------------+----------+------------+-------+-----------------+---------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+-------+-----------------+---------+---------+------+--------+----------+-------------+
| 1 | PRIMARY | dept_emp | NULL | ALL | NULL | NULL | NULL | NULL | 331143 | 100.00 | Using where |
| 2 | SUBQUERY | dept_emp | NULL | index | PRIMARY,dept_no | PRIMARY | 16 | NULL | 331143 | 100.00 | Using index |
+----+-------------+----------+------------+-------+-----------------+---------+---------+------+--------+----------+-------------+
可以看到,执行计划结果中共有 12 列,各列代表的含义总结如下表:
| 列名 | 含义 |
|---|---|
| id | SELECT 查询的序列标识符 |
| select_type | SELECT 关键字对应的查询类型 |
| table | 用到的表名 |
| partitions | 匹配的分区,对于未分区的表,值为 NULL |
| type | 表的访问方法 |
| possible_keys | 可能用到的索引 |
| key | 实际用到的索引 |
| key_len | 所选索引的长度 |
| ref | 当使用索引等值查询时,与索引作比较的列或常量 |
| rows | 预计要读取的行数 |
| filtered | 按表条件过滤后,留存的记录数的百分比 |
| Extra | 附加信息 |
2 如何分析 EXPLAIN 结果
id
SELECT 标识符,是查询中 SELECT 的序号,用来标识整个查询中 SELELCT 语句的顺序。id 如果相同,从上往下依次执行。id 不同,id 值越大,执行优先级越高,如果行引用其他行的并集结果,则该值可以为 NULL。
select_type
查询的类型,主要用于区分普通查询、联合查询、子查询等复杂的查询,常见的值有:
- SIMPLE:简单查询,不包含 UNION 或者子查询。
- PRIMARY:查询中如果包含子查询或其他部分,外层的 SELECT 将被标记为 PRIMARY。
- SUBQUERY:子查询中的第一个 SELECT。
- UNION:在 UNION 语句中,UNION 之后出现的 SELECT。
- DERIVED:在 FROM 中出现的子查询将被标记为 DERIVED。UNION RESULT:UNION 查询的结果。
table
查询用到的表名,每行都有对应的表名,表名除了正常的表之外,也可能是以下列出的值:<unionM,N> : 本行引用了 id 为 M 和 N 的行的 UNION 结果;<derivedN> : 本行引用了 id 为 N 的表所产生的的派生表结果。派生表有可能产生自 FROM 语句中的子查询。 <subqueryN> :本行引用了 id 为 N 的表所产生的的物化子查询结果。
type(重要)
查询执行的类型,描述了查询是如何执行的。所有值的顺序从最优到最差排序为:system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
常见的几种类型具体含义如下:
- system:如果表使用的引擎对于表行数统计是精确的(如:MyISAM),且表中只有一行记录的情况下,访问方法是 system ,是 const 的一种特例。
- const:表中最多只有一行匹配的记录,一次查询就可以找到,常用于使用主键或唯一索引的所有字段作为查询条件。
- eq_ref:当连表查询时,前一张表的行在当前这张表中只有一行与之对应。是除了 system 与 const 之外最好的 join 方式,常用于使用主键或唯一索引的所有字段作为连表条件。
- ref:使用普通索引作为查询条件,查询结果可能找到多个符合条件的行。
- index_merge:当查询条件使用了多个索引时,表示开启了 Index Merge 优化,此时执行计划中的 key 列列出了使用到的索引。
- range:对索引列进行范围查询,执行计划中的 key 列表示哪个索引被使用了。
- index:查询遍历了整棵索引树,与 ALL 类似,只不过扫描的是索引,而索引一般在内存中,速度更快。
- ALL:全表扫描。
possible_keys
possible_keys 列表示 MySQL 执行查询时可能用到的索引。如果这一列为 NULL ,则表示没有可能用到的索引;这种情况下,需要检查 WHERE 语句中所使用的的列,看是否可以通过给这些列中某个或多个添加索引的方法来提高查询性能。
key(重要)
key 列表示 MySQL 实际使用到的索引。如果为 NULL,则表示未用到索引。
key_len
key_len 列表示 MySQL 实际使用的索引的最大长度;当使用到联合索引时,有可能是多个列的长度和。在满足需求的前提下越短越好。如果 key 列显示 NULL ,则 key_len 列也显示 NULL 。
rows
rows 列表示根据表统计信息及选用情况,大致估算出找到所需的记录或所需读取的行数,数值越小越好。
Extra(重要)
这列包含了 MySQL 解析查询的额外信息,通过这些信息,可以更准确的理解 MySQL 到底是如何执行查询的。常见的值如下:
- Using filesort:在排序时使用了外部的索引排序,没有用到表内索引进行排序。
- Using temporary:MySQL 需要创建临时表来存储查询的结果,常见于 ORDER BY 和 GROUP BY。
- Using index:表明查询使用了覆盖索引,不用回表,查询效率非常高。
- Using index condition:表示查询优化器选择使用了索引条件下推这个特性。
- Using where:表明查询使用了 WHERE 子句进行条件过滤。一般在没有使用到索引的时候会出现。
- Using join buffer (Block Nested Loop):连表查询的方式,表示当被驱动表的没有使用索引的时候,MySQL 会先将驱动表读出来放到 join buffer 中,再遍历被驱动表与驱动表进行查询。这里提醒下,当 Extra 列包含 Using filesort 或 Using temporary 时,MySQL 的性能可能会存在问题,需要尽可能避免。
参考:
MySQL执行计划分析
3、优化 SQL 查询语句
根据 SQL 查询语句的瓶颈所在,可以采取不同的优化方法。下面列举几种常见的优化方法:
-
添加索引:如果 SQL 查询语句没有使用索引或者索引使用不当,可以通过添加索引来优化 SQL 查询语句的性能。需要注意的是,添加索引也有可能降低性能,因此需要权衡索引的使用。
-
优化查询条件:如果 SQL 查询语句的查询条件不合理,可以通过优化查询条件来提高 SQL 查询语句的性能。例如,可以使用更合适的数据类型、避免使用函数等。
-
优化 SQL 查询语句结构:如果 SQL 查询语句的结构不合理,可以通过重构 SQL 查询语句来提高性能。例如,可以使用子查询、使用 Join 语句等。
-
减少数据扫描次数:如果 SQL 查询语句需要扫描大量数据,可以通过减少数据扫描次数来提高性能。例如,可以使用分页查询、避免使用 like 模糊查询等。
参考:
针对慢查询如何进行sql优化?
8、有用过分库分表吗?是怎么实现的?
用sharding-jdbc
当Sharding-JDBC接受到一条SQL语句时,会陆续执行 SQL解析 => 查询优化 => SQL路由 => SQL改写 => SQL执行 =>结果归并 ,最终返回执行结果

参考:
sharding-jdbc分库分表-使用及原理
9、mysql是如何锁住一条数据的
场景是:经典的就是操作银行卡, 用户A有一张cardA,现在在取钱,同时用户B在往用户A的cardA里打钱,如何保证数据一致性:
答:在MySQL中,当多个事务同时访问数据库中的同一条数据时,就会出现并发控制的问题。为了解决这个问题,MySQL提供了多种锁机制,其中最常用的是行级锁。
行级锁是MySQL中最细粒度的锁,它可以在对数据进行读取或修改时,对该数据行进行锁定,避免其他事务对该数据行进行操作。使用MySQL锁定一条数据可分为以下步骤:
1. 开始一个事务
START TRANSACTION;
2. 锁定数据行
SELECT * FROM table WHERE id = 1 FOR UPDATE;
3. 对数据行进行操作
UPDATE table SET column = value WHERE id = 1;
4. 提交事务
COMMIT;
在这个过程中,使用SELECT … FOR UPDATE语句可以锁定一条数据行,当其他事务尝试访问该数据行时,将会被阻塞或等待。在修改完数据后,必须提交事务,这样才能释放锁,其他事务才能进行操作。
除了行级锁外,MySQL还提供了表级锁和页级锁等多种锁机制,程序开发人员应该根据具体应用场景选择合适的锁机制来实现数据并发控制。
参考:
mysql 锁定一条数据
10、MongoDB和mysql有什么区别?
1、数据模型,MongoDB是一种面向文档的数据库,使用BSON(Binary JSON)格式存储文档,文档可以包含任意数量和类型的字段。而MySQL是一种关系型数据库,使用表格来存储数据,每个表格由多个行和列组成。
2、数据查询,MongoDB使用一种称为MongoDB Query Language(MQL)的语言来查询数据,它可以轻松地查询嵌套文档和数组。而MySQL使用结构化查询语言(SQL)来查询数据,它可以对多个表格进行复杂的联合查询;
3、扩展性,MongoDB可以很容易地扩展到多个服务器,它支持分片和复制来实现高可用性和可伸缩性。而MySQL也可以扩展到多个服务器,但通常需要更多的配置和管理。
4、数据处理,MongoDB内置了一些数据处理功能,如地理空间索引和聚合管道,这些功能可用于大型和复杂的数据集。而MySQL需要使用第三方库或自定义函数来实现类似的功能。
11、幻读和不可重复读有什区别?幻读是怎么产生的
脏读是指一个事务读取到了其他事务没有提交的数据,如果其他事务失败回滚了,就那就是读的脏数据了。
不可重复读是指在同一个事务内,同一条SQL语句的多次查询的同一条记录的值不一致。
可重复读即相反。
幻读是它发生在一个事务读取了几行数据,接着另一个并发事务插入了一些数据时。在随后的查询中,第一个事务就会发现多了一些原本不存在的记录,就好像发生了幻觉一样。
幻读和不可重复读区别:
- 不可重复读的重点是内容修改或者记录减少比如多次读取一条记录发现其中某些记录的值被修改;
- 幻读的重点在于记录新增比如多次执行同一条查询语句(DQL)时,发现查到的记录增加了。
幻读产生的原因:
行锁只能锁住行、但是新插入记录这个动作、要更新的是记录之间的间隙。
如何解决幻读:
引入了间隙锁(Gap Lock)
事务隔离级别脏读、幻读、不可重复读的关系
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| READ UNCOMMITED(读未提交) | 允许 | 允许 | 允许 |
| READ COMMITED(读已提交) | 不允许 | 允许 | 允许 |
| REPEATABLE READ(可重复读) | 不允许 | 不允许 | 允许 |
| SERIALIZABLE(串行化) | 不允许 | 不允许 | 不允许 |
五、Redis相关
1、Redis可以存储的数据类型
1 数据类型
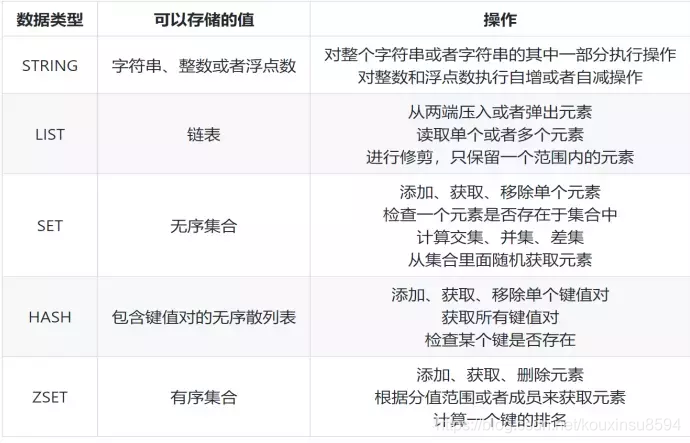
2 Redis在互联网公司一般有以下应用
String:缓存、限流、计数器、分布式锁、分布式Session;累加类型的数据
Hash:存储用户信息、用户主页访问量、组合查询
List:微博关注人时间轴列表、简单队列
Set:赞、踩、标签、好友关系
Zset:排行榜
Zset实现排行榜的实现思路
利用有序集合(sorted set)来存储排行榜数据,每个成员都有一个分数(score)来表示其在排行榜中的位置。可以使用Redis提供的命令(例如ZADD、ZREVRANGE等)来对有序集合进行操作,从而实现排行榜的增删改查等功能。这样就能得到一个实时的用户得分排行榜。
排行榜数据量过大怎么处理
如果排行榜数据访问量非常大,可能会成为Redis的热点数据,造成Redis的压力过大。这时我们可以将排行榜数据缓存到本地,定时从Redis更新排行榜数据。
排行榜的过期策略
如果排行榜有时间限制,例如每日排行榜,每周排行榜等,我们可以设置ZSet的过期时间,或者在新的一期开始时,删除上一期的排行榜。
3 Redis在用户数据统计中value的设计
- 对于累加类型的数据,可以使用
String,比如:每日消耗的金币,每日注册人数等 - 对于需要计算唯一性的数据,比如登录用户,充值人数等,不能继续使用 String,可以选用的有Set,Hash,bitmap等。
考虑到平均下来每个服务器分担的用户可能只在万级左右,并且在线人数统计要频繁地统计长度,最后选择了使Set来对这些数据统计 - 在计算每小时平均在线的时候,使用
String来存储,后续只要对字符串进行格式化,即可方便地计算出每小时平均在线,每小时最高在线,整天的数据。 - 新增的数据计算
这一类要记录的数据可能比较多,因为涉及到集合的交集,并集计算,一开始想到的就是Set,又考虑到内存的问题,便将目光转移到bitmap上。
2、什么是缓存雪崩和缓存击穿以及缓存穿透
1 缓存雪崩
缓存雪崩是指:缓存在同一时间大面积的失效,后面的请求都直接落到了数据库上,造成数据库短时间内承受大量请求,导致数据库的压力过大而宕机。
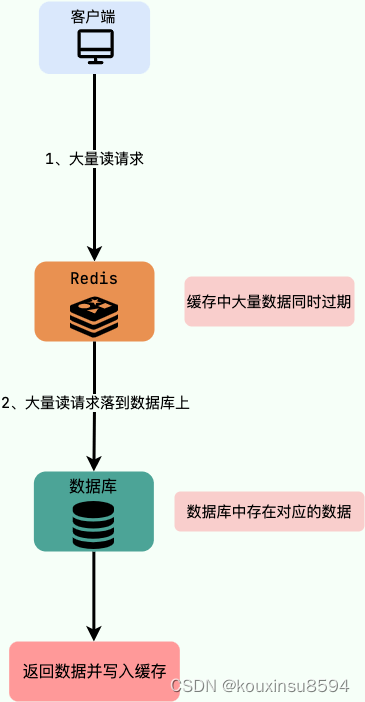
解决办法
1)Redis服务不可用:
- 采用Redis集群,避免单机出现问题整个缓存服务都没办法使用。
- 限流,避免同时处理大量的请求。
2)热点缓存失效:
- 设置不同的失效时间比如随机设置缓存的失效时间。
- 缓存永不失效。
2 缓存击穿
key 对应的数据库数据存在,但在 redis 中过期,此时若有大量并发请求过来,这些请求发现缓存过期一般都会从后端 DB 加载数据并回设到缓存,这个时候大量并发的请求可能会瞬间把后端 DB 压垮(redis某个热门数据过期,大量的合理数据请求到达数据库)
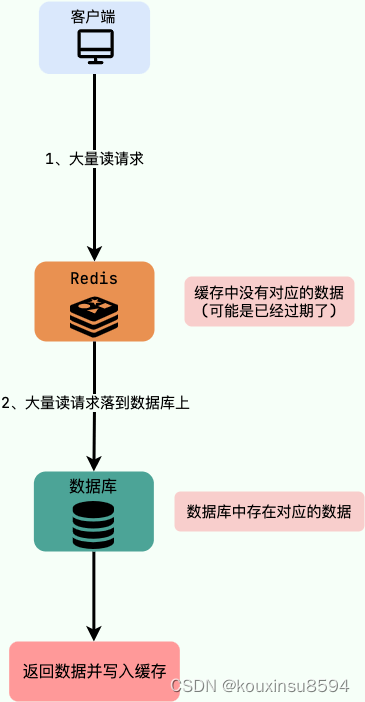
产生原因: redis中的某个热门的key过期了,而此时客户端对这个key的访问量激增,redis无法命中,这些访问就会转发到数据库,造成数据库瞬间压力过大
解决办法
- 设置热点数据永不过期或者过期时间比较长。
- 针对热点数据提前预热,将其存入缓存中并设置合理的过期时间比如秒杀场景下的数据在秒杀结束之前不过期
- 请求数据库写数据到缓存之前,先获取互斥锁,保证只有一个请求会落到数据库上,减少数据库的压力
3 缓存穿透
key 对应的数据在redis中并不存在,每次针对此 key的请求从缓存获取不到,请求转发到数据库,访问量大了可能压垮数据库。比如用一个不存在的用户 id 获取用户信息,redis缓存和数据库中都没有,若黑客利用此漏洞进行攻击可能压垮数据库(黑客访问肯定不存在的数据,造成服务器压力大)
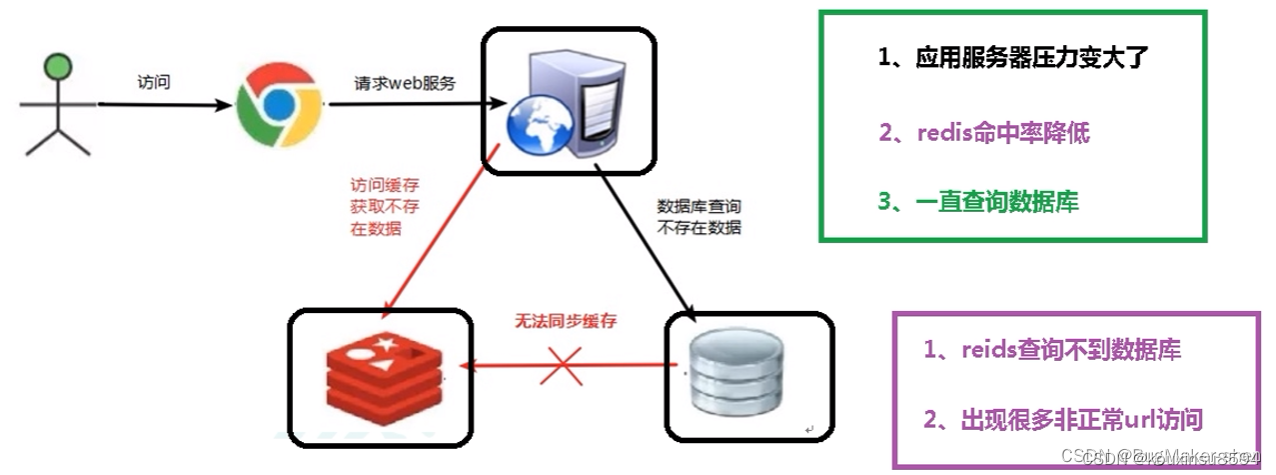
缓存击穿现象:
- 应用服务器压力变大
- redis命中率变低,从而会不断查询数据库
解决方案
一个一定不存在的数据,由于缓存是不命中时被动写的,并且出于容错考虑,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义
1)对空值缓存
如果一个查询返回的数据为空(不管是数据是否不存在),我们仍然把这个空结果(null)进行缓存,这样可以缓解数据库的访问压力,然后设置空结果的过期时间会很短,最长不超过五分钟。(只能作为简单的应急方案)
如果缓存和数据库都查不到某个 key 的数据就写一个到 Redis 中去并设置过期时间,具体命令如下: SET key value EX 10086 。这种方式可以解决请求的 key 变化不频繁的情况。如果黑客恶意攻击,每次构建不同的请求 key,会导致 Redis 中缓存大量无效的 key 。很明显,这种方案并不能从根本上解决此问题。如果非要用这种方式来解决穿透问题的话,尽量将无效的 key 的过期时间设置短一点比如 1 分钟。
一般情况下我们是这样设计 key 的: 表名:列名:主键名:主键值。
public Object getObjectInclNullById(Integer id) {
// 从缓存中获取数据
Object cacheValue = cache.get(id);
// 缓存为空
if (cacheValue == null) {
// 从数据库中获取
Object storageValue = storage.get(key);
// 缓存空对象
cache.set(key, storageValue);
// 如果存储数据为空,需要设置一个过期时间(300秒)
if (storageValue == null) {
// 必须设置过期时间,否则有被攻击的风险
cache.expire(key, 60 * 5);
}
return storageValue;
}
return cacheValue;
}
2)设置可访问的名单(白名单)
使用 bitmaps 类型定义一个可以访问的名单,名单 id 作为 bitmaps 的偏移量,每次访问和 bitmap 里面的 id 进行比较,如果访问 id 不在 bitmaps 里面,进行拦截,不允许访问。
3)布隆过滤器
将所有可能存在的数据哈希到一个足够大的 bitmaps 中,一个一定不存在的数据会被这个bitmaps 拦截掉,从而避免了对底层存储系统的查询压力
把所有可能存在的请求的值都存放在布隆过滤器中,当用户请求过来,先判断用户发来的请求的值是否存在于布隆过滤器中。不存在的话,直接返回请求参数错误信息给客户端,存在的话才会走下面的流程。
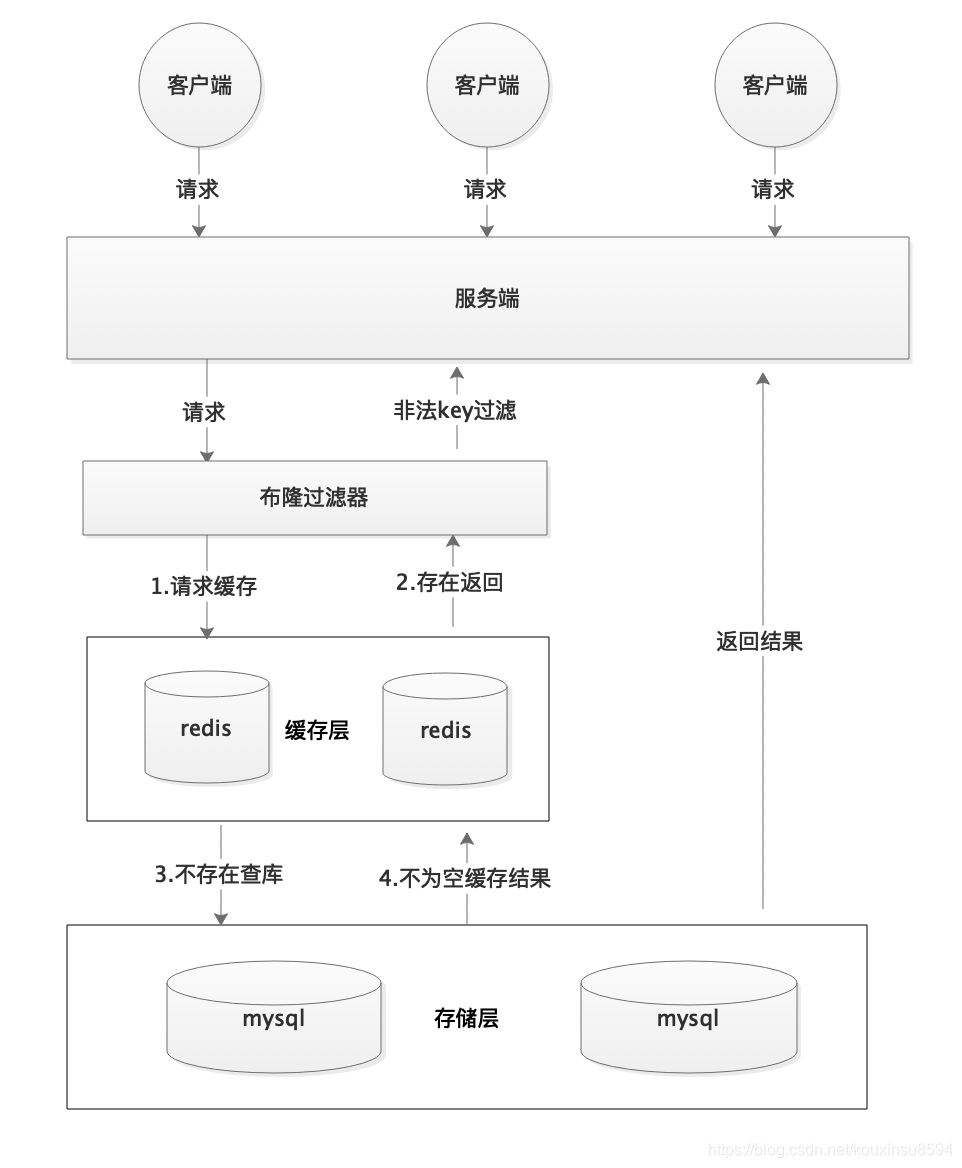
布隆过滤器可能会存在误判的情况。总结来说就是: 布隆过滤器说某个元素存在,小概率会误判。布隆过滤器说某个元素不在,那么这个元素一定不在。
解决:可以适当增加位数组大小或者调整我们的哈希函数来降低概率。
i 布隆过滤器的原理
布隆过滤器的原理是,当一个元素被加入集合时,通过K个散列函数将这个元素映射成一个位数组中的K个点,把它们置为1。检索时,我们只要看看这些点是不是都是1就(大约)知道集合中有没有它了:如果这些点有任何一个0,则被检元素一定不在;如果都是1,则被检元素很可能在。这就是布隆过滤器的基本思想。
优点:
相比于其它的数据结构,布隆过滤器在空间和时间方面都有巨大的优势。布隆过滤器存储空间和插入/查询时间都是常数( O(k))。另外,散列函数相互之间没有关系,方便由硬件并行实现。布隆过滤器不需要存储元素本身,在某些对保密要求非常严格的场合有优势。
布隆过滤器可以表示全集,其它任何数据结构都不能;
k和m相同,使用同一组散列函数的两个布隆过滤器的交并[来源请求]运算可以使用位操作进行。
缺点:
但是布隆过滤器的缺点和优点一样明显。误算率是其中之一。随着存入的元素数量增加,误算率随之增加。但是如果元素数量太少,则使用散列表足矣。
另外,一般情况下不能从布隆过滤器中删除元素。我们很容易想到把位数组变成整数数组,每插入一个元素相应的计数器加1, 这样删除元素时将计数器减掉就可以了。然而要保证安全地删除元素并非如此简单。首先我们必须保证删除的元素的确在布隆过滤器里面。这一点单凭这个过滤器是无法保证的。另外计数器回绕也会造成问题。
在降低误算率方面,有不少工作,使得出现了很多布隆过滤器的变种。
4)进行实时监控
当发现 Redis 的命中率开始急速降低,需要排查访问对象和访问的数据,和运维人员配合,可以设置黑名单限制服务
参考:
缓存雪崩和缓存穿透问题解决方案
Redis 缓存穿透、缓存击穿、缓存雪崩
3、Redis的应用场景
1、会话缓存(最常用)
2、消息队列,比如支付
3、活动排行榜或计数
4、发布、订阅消息(消息通知)
5、商品列表、评论列表等
4、Redis持久化
1 AOF(Append-only file)
Append-only file,将“操作 + 数据”以格式化指令的方式追加到操作日志文件的尾部,在append操作返回后(已经写入到文件或者即将写入),才进行实际的数据变更,“日志文件”保存了历史所有的操作过程;当server需要数据恢复时,可以直接replay此日志文件,即可还原所有的操作过程。AOF相对可靠,它和mysql中bin.log、apache.log、zookeeper中txn-log简直异曲同工。AOF文件内容是字符串,非常容易阅读和解析。
优点:可以保持更高的数据完整性,如果设置追加file的时间是1s,如果redis发生故障,最多会丢失1s的数据;且如果日志写入不完整支持redis-check-aof来进行日志修复;AOF文件没被rewrite之前(文件过大时会对命令进行合并重写),可以删除其中的某些命令(比如误操作的flushall)。
缺点:AOF文件比RDB文件大,且恢复速度慢。
AOF默认关闭
2 RDB(Redis DataBase)
RDB是在某个时间点将数据写入一个临时文件,持久化结束后,用这个临时文件替换上次持久化的文件,达到数据恢复。
优点:使用单独子进程来进行持久化,主进程不会进行任何IO操作,保证了redis的高性能
缺点:RDB是间隔一段时间进行持久化,如果持久化之间redis发生故障,会发生数据丢失。所以这种方式更适合数据要求不严谨的时候
这里说的这个执行数据写入到临时文件的时间点是可以通过配置来自己确定的,通过配置redis在n秒内如果超过m个key被修改这执行一次RDB操作。这个操作就类似于在这个时间点来保存一次Redis的所有数据,一次快照数据。所以这个持久化方法也通常叫做snapshots。RDB默认开启。
3 AOF和RDB如何选择?
- 在架构良好的环境中,master通常使用AOF,slave使用snapshot,主要原因是master需要首先确保数据完整性,它作为数据备份的第一选择;slave提供只读服务(目前slave只能提供读取服务),它的主要目的就是快速响应客户端read请求;
- 但是如果你的redis运行在网络稳定性差/物理环境糟糕情况下,建议你master和slave均采取AOF,这个在master和slave角色切换时,可以减少“人工数据备份”/“人工引导数据恢复”的时间成本;
- 如果你的环境一切非常良好,且服务需要接收密集性的write操作,那么建议master采取snapshot,而slave采用AOF。
5、Redis如何实现分布式锁
什么情况下需要分布式锁
在多线程环境中,如果多个线程同时访问共享资源(例如商品库存、外卖订单),会发生数据竞争,可能会导致出现脏数据或者系统问题,威胁到程序的正常运行。
举个例子,假设现在有 100 个用户参与某个限时秒杀活动,每位用户限购 1 件商品,且商品的数量只有 3 个。如果不对共享资源进行互斥访问,就可能出现以下情况:
- 线程 1、2、3 等多个线程同时进入抢购方法,每一个线程对应一个用户。
- 线程 1查询用户已经抢购的数量,发现当前用户尚未抢购且商品库存还有 1 个,因此认为可以继续执行抢购流程。
- 线程 2也执行查询用户已经抢购的数量,发现当前用户尚未抢购且商品库存还有 1 个,因此认为可以继续执行抢购流程。
- 线程 1继续执行,将库存数量减少 1 个,然后返回成功。
- 线程 2 继续执行,将库存数量减少 1个,然后返回成功。
- 此时就发生了超卖问题,导致商品被多卖了一份。
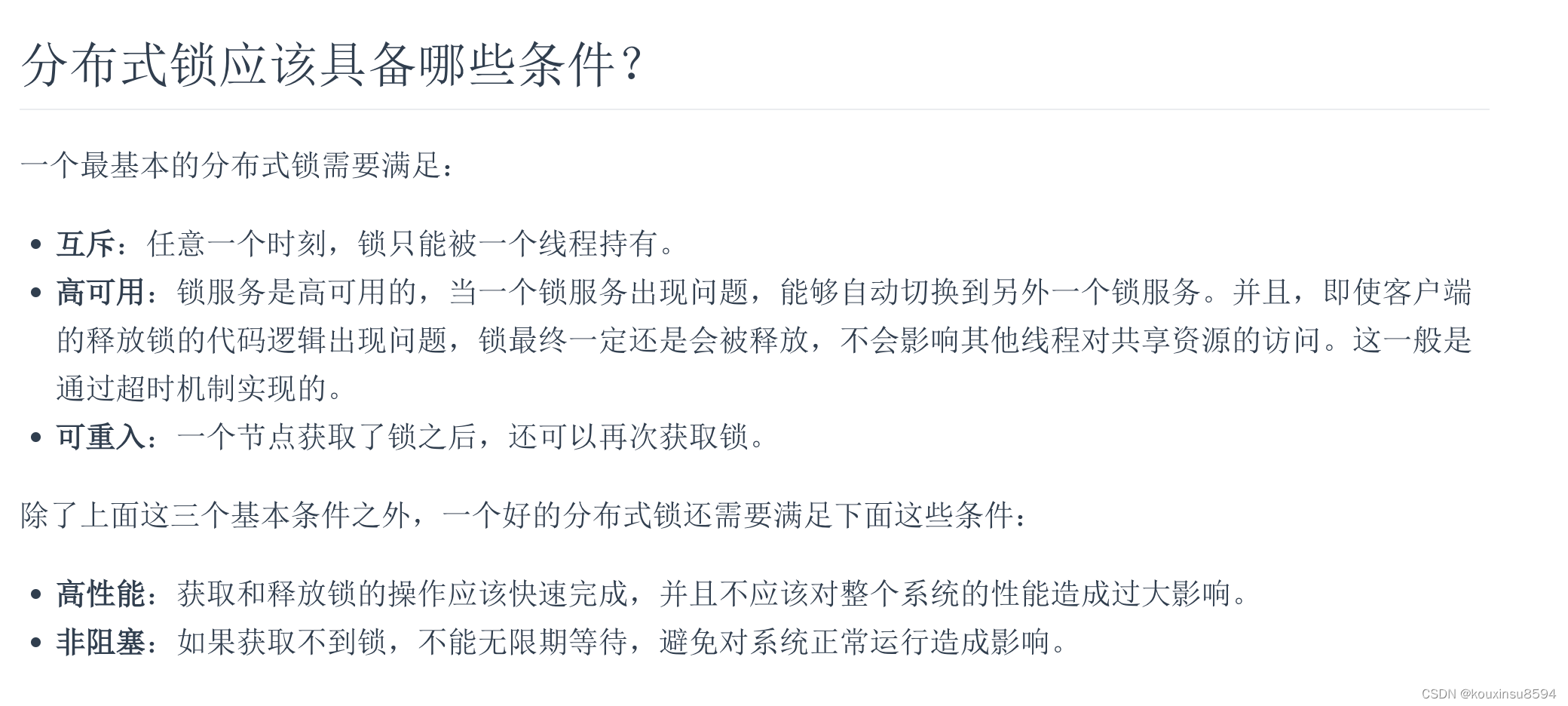
分布式锁应该具备的条件
如何基于 Redis 实现一个最简易的分布式锁
在 Redis 中, SETNX 命令是可以帮助我们实现互斥。SETNX 即 SET if Not eXists (对应 Java 中的 setIfAbsent 方法),如果 key 不存在的话,才会设置 key 的值。如果key已经存在, SETNX 啥也不做。
> SETNX lockKey uniqueValue
(integer) 1
> SETNX lockKey uniqueValue
(integer) 0
释放锁的话,直接通过 DEL 命令删除对应的 key 即可。
> DEL lockKey
(integer) 1
为了防止误删到其他的锁,这里我们建议使用 Lua 脚本通过 key 对应的 value(唯一值)来判断。选用 Lua 脚本是为了保证解锁操作的原子性。因为 Redis 在执行 Lua 脚本时,可以以原子性的方式执行,从而保证了锁释放操作的原子性。
// 释放锁时,先比较锁对应的 value 值是否相等,避免锁的误释放
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
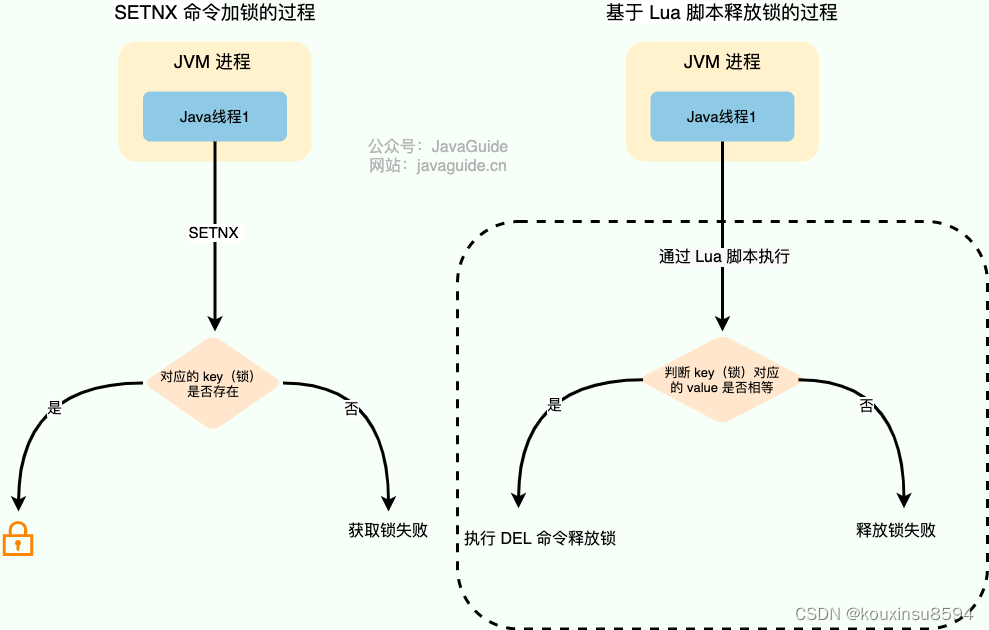
这种方式实现分布式锁存在一些问题。就比如应用程序遇到一些问题比如释放锁的逻辑突然挂掉,可能会导致锁无法被释放,进而造成共享资源无法再被其他线程/进程访问。
为了避免锁无法被释放,我们可以想到的一个解决办法就是:给这个 key(也就是锁) 设置一个过期时间 。
127.0.0.1:6379> SET lockKey uniqueValue EX 3 NX
OK
- lockKey:加锁的锁名
- uniqueValue:能够唯一标示锁的随机字符串;
- NX:只有当 lockKey 对应的 key 值不存在的时候才能 SET 成功;
- EX:过期时间设置(秒为单位)EX 3 标示这个锁有一个 3 秒的自动过期时间。与 EX 对应的是 PX(毫秒为单位),这两个都是过期时间设置。
一定要保证设置指定 key 的值和过期时间是一个原子操作!!! 不然的话,依然可能会出现锁无法被释放的问题。
这样确实可以解决问题,不过,这种解决办法同样存在漏洞:如果操作共享资源的时间大于过期时间,就会出现锁提前过期的问题,进而导致分布式锁直接失效。如果锁的超时时间设置过长,又会影响到性能。
这时可以用Redisson,Redisson 中的分布式锁自带自动续期机制,其提供了一个专门用来监控和续期锁的 Watch Dog( 看门狗),如果操作共享资源的线程还未执行完成的话,Watch Dog 会不断地延长锁的过期时间,进而保证锁不会因为超时而被释放。
参考:
分布式锁常见实现方案总结
六、消息队列相关的问题
1、RocketMQ
1、RocketMQ在项目中的使用
这里不展开,只是记录一下
2、使用RocketMQ如何解决分布式事务
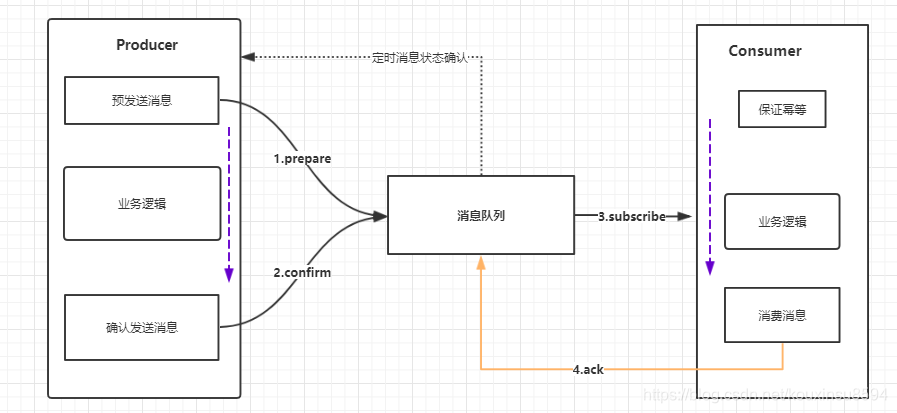
针对这里的 可靠消息最终一致性方案 来说,我们说的 可靠 是指保证消息一定能发送到消息中间件里面去,保证这里可靠。
对于下游的系统来说,消费不成功,一般来说就是采取失败重试,重试多次不成功,那么就记录日志,后续人工介入来进行处理。所以这里得强调一下,后面的系统,一定要处理 幂等,重试,日志 这几个东西。
如果是对于资金类的业务,后续系统回滚了以后,得想办法去通知前面的系统也进行回滚,或者是发送报警由人工来手工回滚和补偿。
3、扩展:其他几种分布式事务解决方案
1 TCC
TCC 的全程分为三个阶段,分别是 Try、Confirm、Cancel:
Try阶段:这个阶段说的是对各个服务的资源做检测以及对资源进行锁定或者预留Confirm阶段:这个阶段说的是在各个服务中执行实际的操作Cancel阶段:如果任何一个服务的业务方法执行出错,那么这里就需要进行补偿,就是执行已经执行成功的业务逻辑的回滚操作
还是以转账的例子为例,在跨银行进行转账的时候,需要涉及到两个银行的分布式事务,从A 银行向 B 银行转 1 块,如果用TCC 方案来实现:
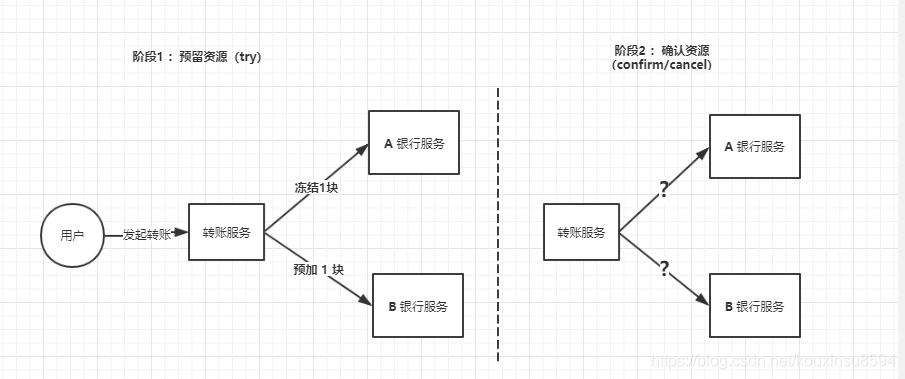 大概思路就是这样的:
大概思路就是这样的:
- Try 阶段:先把A 银行账户先冻结 1 块,B银行账户中的资金给预加 1 块。
- Confirm 阶段:执行实际的转账操作,A银行账户的资金扣减 1块,B 银行账户的资金增加 1 块。
- Cancel 阶段:如果任何一个银行的操作执行失败,那么就需要回滚进行补偿,就是比如A银行账户如果已经扣减了,但是B银行账户资金增加失败了,那么就得把A银行账户资金给加回去。
这种方案就比较复杂了,一步操作要做多个接口来配合完成。
以 ByteTCC 框架的实现例子来大概描述一下上面的流程,示例地址 https://gitee.com/bytesoft/ByteTCC-sample/tree/master/dubbo-sample
该方案使用场景:
一般来说和钱相关的支付、交易等相关的场景,我们会用TCC,严格严格保证分布式事务要么全部成功,要么全部自动回滚,严格保证资金的正确性!
2 2PC

在XA协议中分为两阶段:
第一阶段:事务管理器要求每个涉及到事务的数据库预提交(precommit)此操作,并反映是否可以提交.
第二阶段:事务协调器要求每个数据库提交数据,或者回滚数据。
优点: 尽量保证了数据的强一致,实现成本较低,在各大主流数据库都有自己实现,对于MySQL是从5.5开始支持。
缺点:
- 单点问题:事务管理器在整个流程中扮演的角色很关键,如果其宕机,比如在第一阶段已经完成,在第二阶段正准备提交的时候事务管理器宕机,资源管理器就会一直阻塞,导致数据库无法使用。
- 同步阻塞:在准备就绪之后,资源管理器中的资源一直处于阻塞,直到提交完成,释放资源。
- 数据不一致:两阶段提交协议虽然为分布式数据强一致性所设计,但仍然存在数据不一致性的可能,比如在第二阶段中,假设协调者发出了事务commit的通知,但是因为网络问题该通知仅被一部分参与者所收到并执行了commit操作,其余的参与者则因为没有收到通知一直处于阻塞状态,这时候就产生了数据的不一致性。
总的来说,XA协议比较简单,成本较低,但是其单点问题,以及不能支持高并发(由于同步阻塞)依然是其最大的弱点。
参考:
面互联网公司必备的分布式事务方案
突破Java面试(44)-分布式事务解决方案
再有人问你分布式事务,把这篇扔给他
4、RocketMQ的消费模式
1 广播模式(BROADCASTING)
广播消费:当使用广播消费模式时,消息队列 RocketMQ 版会将每条消息推送给集群内所有注册过的消费者,保证消息至少被每个消费者消费一次。
适用场景
适用于消费端集群化部署,每条消息需要被集群下的每个消费者处理的场景。具体消费示例如下图所示。
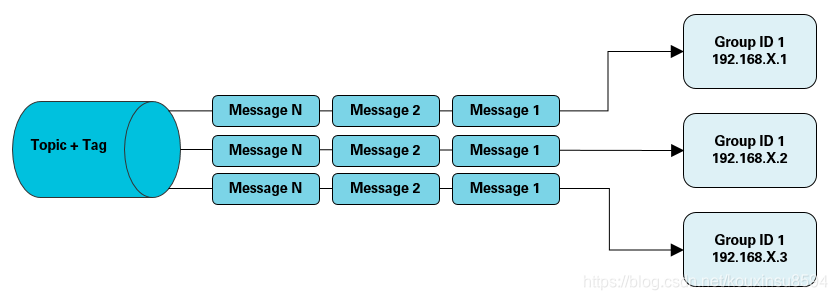
注意事项
- 广播消费模式下不支持顺序消息。
- 广播消费模式下不支持重置消费位点。
- 每条消息都需要被相同订阅逻辑的多台机器处理。
- 消费进度在客户端维护,出现重复消费的概率稍大于集群模式。
- 广播模式下,消息队列 RocketMQ 版保证每条消息至少被每台客户端消费一次,但是并不会重投消费失败的消息,因此业务方需要关注消费失败的情况。
- 广播模式下,客户端每一次重启都会从最新消息消费。客户端在被停止期间发送至服务端的消息将会被自动跳过,请谨慎选择。
- 广播模式下,每条消息都会被大量的客户端重复处理,因此推荐尽可能使用集群模式。
- 广播模式下服务端不维护消费进度,所以消息队列 RocketMQ 版控制台不支持消息堆积查询、消息堆积报警和订阅关系查询功能。
2 集群模式(CLUSTERING)
集群消费:当使用集群消费模式时,消息队列 RocketMQ 版认为任意一条消息只需要被集群内的任意一个消费者处理即可。
适用场景
适用于消费端集群化部署,每条消息只需要被处理一次的场景。此外,由于消费进度在服务端维护,可靠性更高。具体消费示例如下图所示。
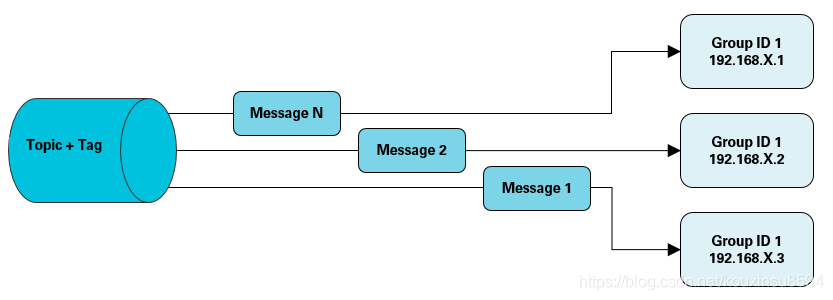
注意事项
- 集群消费模式下,每一条消息都只会被分发到一台机器上处理。如果需要被集群下的每一台机器都处理,请使用广播模式。
- 集群消费模式下,不保证每一次失败重投的消息路由到同一台机器上。
多个 Group ID 通过集群订阅方式实现广播消费模式
适用场景
适用于每条消息都需要被多台机器处理,每台机器的逻辑可以相同也可以不一样的场景。具体消费示例如下图所示。
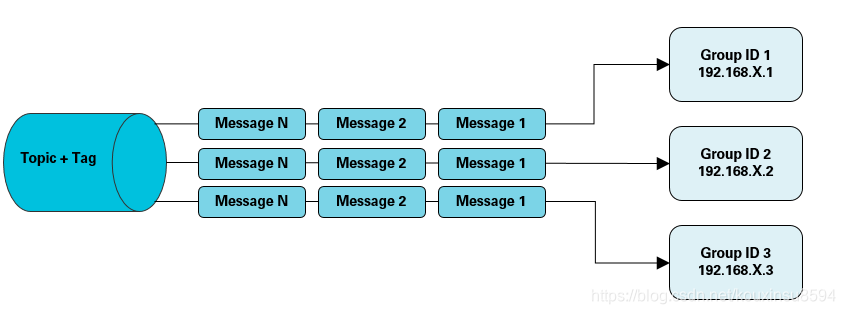
如果业务需要使用广播模式,也可以创建多个 Group ID,用于订阅同一个 Topic。
注意事项
- 消费进度在服务端维护,可靠性高于广播模式。
- 对于一个 Group ID 来说,可以部署一个消费者实例,也可以部署多个消费者实例。当部署多个消费者实例时,实例之间又组成了集群模式(共同分担消费消息)。假设 Group ID 1 部署了三个消费者实例 C1、C2、C3,那么这三个实例将共同分担服务器发送给 Group ID 1 的消息。同时,实例之间订阅关系必须保持一致。
5、RocketMQ消息消费模型
RockerMQ 中的消息模型就是按照 主题模型 所实现的,又可以称为 发布订阅模型 。不需要每个消费者维护自己的消息队列,生产者将消息发送到topic,消费者订阅此topic 读取消息。
所以,RocketMQ 中的 主题模型 的实现:
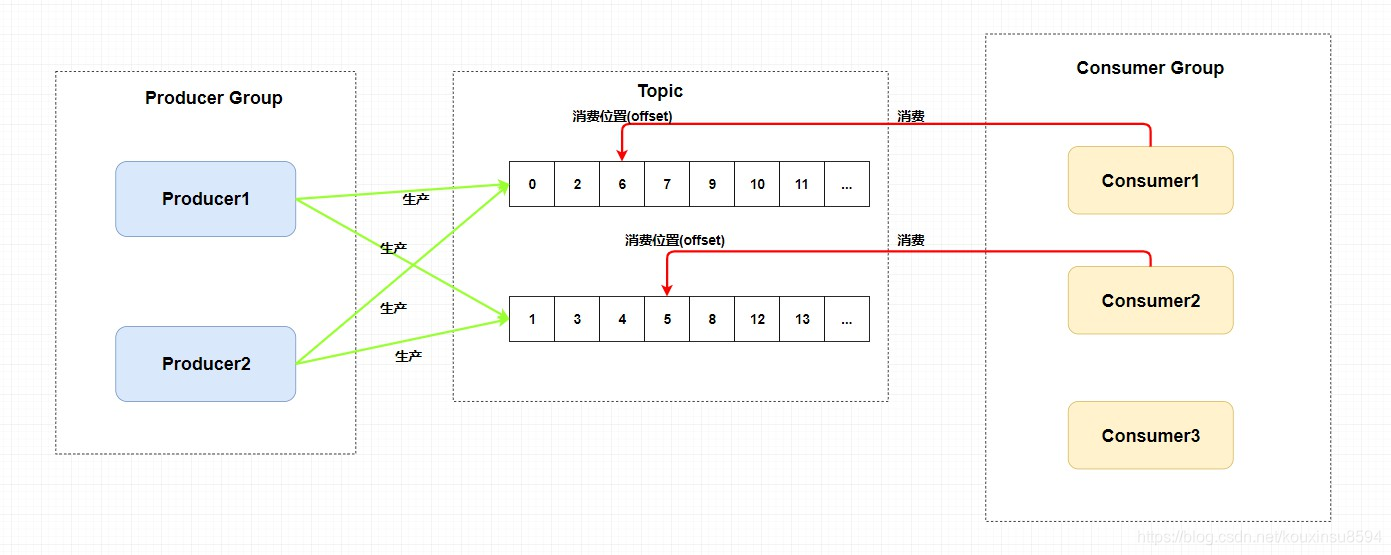
消息模型:消息模型包括 producer, consumer, broker三部分。 producer生产消息, consumer消费消息, broker存储消息, broker可以是集群部署,其中 topic位于 broker中
-
Producer: 一般是业务系统为生产者,将消息投递到broker,投递消息要经历“请求-确认”机制,确保消息不会在投递过程中丢失。过程:生产者生产消息到broker,broker接受消息写入topic。
之后给生产者发送确认相应,如果生产者没有收到服务端的确认或者收到失败的响应,则会重新发送消息;在消费端,消费者在收到消息并完成自己的消费业务逻辑(比如,将数据保存到数据库中)后,也会给服务端发送消费成功的确认,服务端只有收到消费确认后,才认为一条消息被成功消费,否则它会给消费者重新发送这条消息,直到收到对应的消费成功确认。 -
Topic:表示一类消息的集合,每个主题包含若干条消息,每条消息只能属于一个主题,是RocketMQ进行消息订阅的基本单位。 -
生产者组:同一类
Producer的集合,这类Producer发送同一类消息且发送逻辑一致。如果发送的是事物消息且原始生产者在发送之后崩溃,则broker服务器会联系同一生产者组的其他生产者实例以提交或回溯消费。 -
消费者组:同一类
consumer的集合,这类consumer通常消费同一类消息且消费逻辑一致。消费者组使得在消息消费方面,实现负载均衡和容错的目标变得非常容易。要注意的是,消费者组的消费者实例必须订阅完全相同的Topic。
RocketMQ 支持两种消息模式:集群消费(Clustering)和广播消费(Broadcasting)
参考:
RocketMQ消息模型
6、RocketMQ消息消费流程

- 启动
NameServer,NameServer启动后进行端口监听,等待Broker、Producer、Consumer连上来,相当于一个路由控制中心 Broker启动,跟所有的NameServer保持长连接,定时发送心跳包- 心跳包中,包含当前
Broker信息(IP+端口等)以及存储所有Topic信息 - 注册成功后,
NameServer集群中就有Topic跟Broker的映射关系
- 心跳包中,包含当前
- 收发消息前,先创建
Topic。创建Topic时,需要指定该Topic要存储在哪些Broker上。也可以在发送消息时自动创建Topic Producer发送消息- 启动时,先跟
NameServer集群中的其中一台建立长连接,并从NameServer中获取当前发送的Topic存在哪些Broker上 - 然后跟对应的
Broker建立长连接,直接向Broker发消息
- 启动时,先跟
Consumer消费消息- 跟其中一台
NameServer建立长连接,获取当前订阅Topic存在哪些Broker上 - 然后直接跟
Broker建立连接通道,开始消费消息RocketMQ的消息领域模型
- 跟其中一台
参考:
必须先理解的RocketMQ入门手册,才能再次深入解读
7、如何解决消息重复消费
需要给我们的消费者实现 幂等 ,也就是对同一个消息的处理结果,执行多少次都不变。
在业务上实现幂等:
- 可以使用 写入
Redis来保证,因为Redis的key和value就是天然支持幂等的。 - 当然还有使用 数据库插入法 ,基于数据库的唯一键来保证重复数据不会被插入多条。或者先根据主键查一下,如果这数据都有了,你就别插入了,update数据。
- 可以让生产者发送每条数据的时候,里面加一个全局唯一的id,类似订单id之类的东西,然后你这里消费到了之后,先根据这个id去比如redis里查一下之前是否消费过,如果没有消费过,你就处理,然后这个id写redis。如果消费过了,那你就别处理了,保证别重复处理相同的消息即可。
2、RabbitMQ
1、RabbitMQ怎么实现的延迟消息队列
Rabbitmq可以通过以下两种方式实现延时消息:
① Rabbitmq插件rabbitmq_delayed_message_exchange 安装这个插件后,可以使用x-delayed-message类型的exchange来实现延时消息。
具体步骤如下:
- 安装插件:rabbitmq-plugins enable rabbitmq_delayed_message_exchange
- 创建exchange时指定类型为x-delayed-message:arguments = {“x-delayed-type”: “direct”}
- 发送消息时,在消息头中设置延迟时间:headers = {“x-delay”: 5000} (单位为毫秒)
② 建立延时队列并设置TTL 在Rabbitmq中,可以创建一个队列,并设置队列的TTL(生存时间)。当消息被发送到该队列时,如果没有被消费者消费,在TTL过期后,该消息将会被自动删除。
具体步骤如下:
- 创建一个队列,设置队列的TTL:arguments = {“x-message-ttl”: 5000} (单位为毫秒)
- 发送消息到该队列
- 消费该队列时,需要设置auto_ack为false,并在处理完消息后手动确认ack
以上两种方式都可以实现延时消息,选择哪种方式取决于项目的实际需求和使用场景。
七、git命令的使用
1、版本回退命令
代码未提交,本地回退到上一次commit
git reset commit_id
代码已提交,回退到指定版本
git revert commit_id
具体可以看第三点
2、git add加入错误文件后如何回退
git status 先看一下add 中的文件
git reset HEAD 如果后面什么都不跟的话 就是上一次add 里面的全部撤销了
git reset HEAD XXX/XXX/XXX.java 就是对某个文件进行撤销了
3、git reset和git revert有什么区别
git reset 可以用在git commit 错误 的时候
先使用
git log 查看节点
commit xxxxxxxxxxxxxxxxxxxxxxxxxx
Merge:
Author:
Date:
然后
git reset commit_id
还没有 push 也就是 repo upload 的时候
git reset commit_id (回退到上一个 提交的节点 代码还是原来你修改的)
git reset –hard commit_id (回退到上一个commit节点, 代码也发生了改变,变成上一次的)
如果要是 提交了以后,可以使用 git revert 用来还原已经提交的修改
此次操作之前和之后的commit和history都会保留,并且把这次撤销作为一次最新的提交
git revert HEAD 撤销前一次 commit
git revert HEAD^ 撤销前前一次 commit
git revert commit-id (撤销指定的版本,撤销也会作为一次提交进行保存)
git revert是提交一个新的版本,将需要revert的版本的内容再反向修改回去,版本会递增,不影响之前提交的内容。
参考:
git add , git commit 添加错文件 撤销
4、git rebase的用法
git rebase:将多次commit合并,只保留一次提交历史。
具体的操做参考:
使用git rebase合并多次commit
5、如何把一个项目迁移到另一个git仓库
1、使用git remote set-url origin命令替换远程的git仓库
git remote set-url origin git@git.xxxxxxxxx/xxx.git
2、使用git clone --bare 和 git push --mirror 命令
-
从原地址克隆一份裸版本库,比如原本托管于 GitHub。
git clone --bare git://github.com/username/project.git -
然后到新的 Git 服务器上创建一个新项目,比如 GitCafe。
-
以镜像推送的方式上传代码到 GitCafe 服务器上。
cd project.gitgit push --mirror git@gitcafe.com/username/newproject.git -
删除本地代码
cd .. rm -rf project.git -
到新服务器 GitCafe 上找到 Clone 地址,直接 Clone 到本地就可以了。
git clone git@gitcafe.com/username/newproject.git
这种方式可以保留原版本库中的所有内容。
八、docker相关
1、使用docker自动化部署项目的流程
- 梳理中
2、docker命令
1 使用docker查所有的镜像
docker images
或:
docker image ls
2 使用docker查所有的容器
docker ps -a
3 docker进入容器内部的命令
docker exec -it xxxxxxxxx /bin/sh
4 docker 数据卷
管理卷
# docker volume create edc-nginx-vol // 创建一个自定义容器卷
# docker volume ls // 查看所有容器卷
# docker volume inspect edc-nginx-vol // 查看指定容器卷详情信息
有了自定义容器卷,我们可以创建一个使用这个数据卷的容器,这里我们以nginx为例:
创建使用指定卷的容器
# docker run -d -it --name=edc-nginx -p 8800:80 -v edc-nginx-vol:/usr/share/nginx/html nginx
其中,-v代表挂载数据卷,这里使用自定数据卷edc-nginx-vol,并且将数据卷挂载到 /usr/share/nginx/html (这个目录是yum安装nginx的默认网页目录)。
如果没有通过-v指定,那么Docker会默认帮我们创建匿名数据卷进行映射和挂载。
参考:
你必须知道的Docker数据卷(Volume)
3、DockerFile
1 DockerFile的关键标签
1)FROM(指定基础镜像)
构建指令,Docker中必须使用FROM命令,必须指定且需要在Dockerfile其他指令的前面。后续的指令都依赖于该指令指定的image。FROM指令指定的基础image可以是官方远程仓库中的,也可以位于本地仓库。
2)MAINTAINER(指定镜像创建者信息)
构建指令,用于将image的制作者相关的信息写入到image中,一般输入名字和电子邮箱即可。当我们对该image执行docker inspect命令时,输出中有相应的字段记录该信息。
3)RUN(安装软件用)
构建指令,在FROM中设置的镜像上运行脚本或命令,在RUN可以运行任何被基础image支持的命令。如基础image选择了ubuntu,那么软件管理部分只能使用ubuntu的命令。
4)CMD(设置container启动时执行的操作)
设置指令,用于容器启动时指定的操作。该操作可以是执行自定义脚本,也可以是执行系统命令。
一个Dockerfile中只能有一条CMD命令,多条则只执行最后一条CMD.
5)ENTRYPOINT(设置container启动时执行的操作)
设置指令,指定容器启动时执行的命令。
但是一个Dockerfile中只能有一条ENTRYPOINT命令,可以多次设置,但是只有最后一个有效。
6)EXPOSE(指定容器需要映射到宿主机器的端口)
设置指令,该指令会将容器中的端口映射成宿主机器中的某个端口。
7)ENV(用于设置环境变量)
构建指令,在image中设置一个环境变量。
8)ADD(向镜像添加文件)
构建指令,所有拷贝到container中的文件和文件夹权限为0755,uid和gid为0。
9)COPY(向镜像添加文件)
复制本地主机的 <src> (为Dockerfile所在目录的相对路径)到容器中的 <dest>
使用COPY添加文件时,不会解压缩,也不能使用文件URL
10)VOLUME(指定挂载点)
设置指令,使容器中的一个目录具有持久化存储数据的功能,该目录可以被容器本身使用,也可以共享给其他容器使用。,当容器关闭后,所有的更改都会丢失。当容器中的应用有持久化数据的需求时可以在Dockerfile中使用该指令。可以将本地文件夹或者其他container的文件夹挂载到container中。
11)WORKDIR(切换目录)
切换目录用,设置指令,可以多次切换(相当于cd命令),对RUN,CMD,ENTRYPOINT生效。
更多使用及参考:
DockerFile关键字介绍
2 DockerFile的COPY和ADD有什么区别
Dockerfile中的COPY指令和ADD指令都可以将主机上的资源复制或加入到容器镜像中,都是在构建镜像的过程中完成的。
COPY指令和ADD指令的唯一区别在于是否支持从远程URL获取资源。COPY指令只能从执行docker build所在的主机上读取资源并复制到镜像中。而ADD指令还支持通过URL从远程服务器读取资源并复制到镜像中。
满足同等功能的情况下,推荐使用COPY指令。ADD指令更擅长读取本地tar文件并解压缩。
参考:
Dockerfile中的COPY和ADD指令详解与比较
九、Linux命令
1、创建单层文件夹以及创建多级文件夹命令
1 创建单层文件夹
创建单层文件夹,不能创建多层,不能重复创建。 比如mkdir abc。
mkdir <folder>
2 创建多层次文件夹
创建多层次文件夹,可以重复创建同一个文件夹。如mkdir -p abc/a/b/c/
mkdir -p <path>
2、删除文件夹
rm -rf 指定目录*
3、如何赋给用户管理员权限
sudo usermod -G <管理员组> <用户>
但是这样设置话每次用到使用root权限都需要输入密码,可以修改/etc/sudoers 配置文件来设置执行root权限操作的时候不输入密码。
进入root用户,修改 /etc/sudoers 配置文件,先查看root对这个文件的权限:
[yaoqi@java-devenv ~]$ ll /etc/sudoers
-r--r----- 1 root root 4187 Nov 17 19:20 /etc/sudoers
root用户对该文件只有读的权限,需要给root用户写的权限。
[root@java-devenv ~]# chmod +w /etc/sudoers
[root@java-devenv ~]# ll /etc/sudoers
-rw-r-----. 1 root root 4188 Jul 7 2015 /etc/sudoers
执行chmod +w /etc/sudoers 就是给当前用户对/etc/sudoers文件增加写的权限。然后再用vim 修改该文件。
vim /etc/sudoers
...
## Allows people in group wheel to run all commands
%wheel ALL=(ALL) ALL
## Same thing without a password
%wheel ALL=(ALL) NOPASSWD: ALL
把 ##Same thing without a password 下一行的注释去掉,就可以设置执行root权限操作的时候不输入密码了(注释中说的很明确了)。
操作完成之后记得收回root的权限。
[root@java-devenv ~]# chmod -w /etc/sudoers
[root@java-devenv ~]# ll /etc/sudoers
-r--r----- 1 root root 4187 Nov 17 19:20 /etc/sudoers
然后登录新建的用户,虽然加入了管理员用户组,但是执行root权限操作的时候用命令前面需要加上sudo。
比如:在登录了刚刚新建用户后试试 vim /etc/sudoers 看不到任何东西,sudo vim /etc/sudoers 后才能看到该配置文件中的内容。
参考:
linux新建用户并赋管理员权限
十、前端
1、js中== 和=== 有什么区别
简单来说: == 代表相同, === 代表严格相同
这么理解: 当进行==比较时候: 先检查两个操作数数据类型,如果相同, 则进行 === 比较, 如果不同, 则愿意为你进行一次类型转换, 转换成相同类型后再进行比较, 而 === 比较时, 如果类型不同,直接就是false.
操作数1 == 操作数2, 操作数1 === 操作数2
比较过程:
双等号==:
(1)如果两个值类型相同,再进行三个等号(===)的比较
(2)如果两个值类型不同,也有可能相等,需根据以下规则进行类型转换在比较:
- 1)如果一个是null,一个是undefined,那么相等
- 2)如果一个是字符串,一个是数值,把字符串转换成数值之后再进行比较
三等号===:
(1)如果类型不同,就一定不相等
(2)如果两个都是数值,并且是同一个值,那么相等;如果其中至少一个是NaN,那么不相等。(判断一个值是否是NaN,只能使用isNaN( ) 来判断)
(3)如果两个都是字符串,每个位置的字符都一样,那么相等,否则不相等。
(4)如果两个值都是true,或是false,那么相等
(5)如果两个值都引用同一个对象或是函数,那么相等,否则不相等
(6)如果两个值都是null,或是undefined,那么相等
参考:
js中==和===区别
2、js的数据类型
8种。Number、String、Boolean、Null、undefined、object、symbol、bigInt。
十一、关于项目
1、项目整体叙述
2、项目中有遇到什么困难吗?如何解决的?
这里主要是面试官想考察你的问题处理思路和是否有固定的处理问题套路。
3、关于项目发布gitlab上有什么规范
4、项目开发中API接口安全性如何保证?
Token授权机制
用户使用用户名密码登录后服务器给客户端返回一个Token(通常是UUID),并将Token-UserId以键值对的形式存放在缓存服务器中。服务端接收到请求后进行Token验证,如果Token不存在,说明请求无效。Token是客户端访问服务端的凭证。
时间戳超时机制
用户每次请求都带上当前时间的时间戳timestamp,服务端接收到timestamp后跟当前时间进行比对,如果时间差大于一定时间(比如5分钟),则认为该请求失效。时间戳超时机制是防御DOS攻击的有效手段。
签名机制
将 Token 和 时间戳 加上其他请求参数再用MD5或SHA-1算法(可根据情况加点盐)加密,加密后的数据就是本次请求的签名sign,服务端接收到请求后以同样的算法得到签名,并跟当前的签名进行比对,如果不一样,说明参数被更改过,直接返回错误标识。签名机制保证了数据不会被篡改。
输入参数验证
在到达应用程序逻辑之前,首先验证请求参数。进行严格的验证检查,如果验证失败,则立即拒绝请求。在API响应中,发送相关的错误消息和正确输入格式的示例,以改善用户体验。
一律使用HTTPS
通过始终使用SSL,可以将身份验证凭据简化为随机生成的访问令牌,该令牌在HTTP基本身份验证的用户名字段中提供。它相对简单易用,并且免费提供许多安全功能。
如果使用HTTP 2来提高性能–甚至可以通过单个连接发送多个请求,则可以避免以后的请求完全进行TCP和SSL握手。
参考:
API接口安全性设计
REST API Security Essentials
5、项目当中用到的加密算法?
业务中用到的是MD5,RSA
1 MD5加密算法
MD5 用的是 哈希函数,它的典型应用是对一段信息产生 信息摘要,以 防止被篡改。严格来说,MD5 不是一种 加密算法 而是 摘要算法。无论是多长的输入,MD5 都会输出长度为 128bits 的一个串 (通常用 16 进制 表示为 32 个字符)。
public static final byte[] computeMD5(byte[] content) {
try {
MessageDigest md5 = MessageDigest.getInstance("MD5");
return md5.digest(content);
} catch (NoSuchAlgorithmException e) {
throw new RuntimeException(e);
}
}
2 RSA加密算法
RSA 加密算法是目前最有影响力的 公钥加密算法,并且被普遍认为是目前 最优秀的公钥方案 之一。RSA 是第一个能同时用于 加密 和 数字签名 的算法,它能够 抵抗 到目前为止已知的 所有密码攻击,已被 ISO 推荐为公钥数据加密标准。
RSA加密算法 基于一个十分简单的数论事实:将两个大 素数 相乘十分容易,但想要对其乘积进行 因式分解 却极其困难,因此可以将 乘积 公开作为 加密密钥。
import net.pocrd.annotation.NotThreadSafe;
import org.bouncycastle.jce.provider.BouncyCastleProvider;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import javax.crypto.Cipher;
import java.io.ByteArrayOutputStream;
import java.security.KeyFactory;
import java.security.Security;
import java.security.Signature;
import java.security.interfaces.RSAPrivateCrtKey;
import java.security.interfaces.RSAPublicKey;
import java.security.spec.PKCS8EncodedKeySpec;
import java.security.spec.X509EncodedKeySpec;
@NotThreadSafe
public class RsaHelper {
private static final Logger logger = LoggerFactory.getLogger(RsaHelper.class);
private RSAPublicKey publicKey;
private RSAPrivateCrtKey privateKey;
static {
Security.addProvider(new BouncyCastleProvider()); //使用bouncycastle作为加密算法实现
}
public RsaHelper(String publicKey, String privateKey) {
this(Base64Util.decode(publicKey), Base64Util.decode(privateKey));
}
public RsaHelper(byte[] publicKey, byte[] privateKey) {
try {
KeyFactory keyFactory = KeyFactory.getInstance("RSA");
if (publicKey != null && publicKey.length > 0) {
this.publicKey = (RSAPublicKey)keyFactory.generatePublic(new X509EncodedKeySpec(publicKey));
}
if (privateKey != null && privateKey.length > 0) {
this.privateKey = (RSAPrivateCrtKey)keyFactory.generatePrivate(new PKCS8EncodedKeySpec(privateKey));
}
} catch (Exception e) {
throw new RuntimeException(e);
}
}
public RsaHelper(String publicKey) {
this(Base64Util.decode(publicKey));
}
public RsaHelper(byte[] publicKey) {
try {
KeyFactory keyFactory = KeyFactory.getInstance("RSA");
if (publicKey != null && publicKey.length > 0) {
this.publicKey = (RSAPublicKey)keyFactory.generatePublic(new X509EncodedKeySpec(publicKey));
}
} catch (Exception e) {
throw new RuntimeException(e);
}
}
public byte[] encrypt(byte[] content) {
if (publicKey == null) {
throw new RuntimeException("public key is null.");
}
if (content == null) {
return null;
}
try {
Cipher cipher = Cipher.getInstance("RSA/ECB/PKCS1Padding");
cipher.init(Cipher.ENCRYPT_MODE, publicKey);
int size = publicKey.getModulus().bitLength() / 8 - 11;
ByteArrayOutputStream baos = new ByteArrayOutputStream((content.length + size - 1) / size * (size + 11));
int left = 0;
for (int i = 0; i < content.length; ) {
left = content.length - i;
if (left > size) {
cipher.update(content, i, size);
i += size;
} else {
cipher.update(content, i, left);
i += left;
}
baos.write(cipher.doFinal());
}
return baos.toByteArray();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
public byte[] decrypt(byte[] secret) {
if (privateKey == null) {
throw new RuntimeException("private key is null.");
}
if (secret == null) {
return null;
}
try {
Cipher cipher = Cipher.getInstance("RSA/ECB/PKCS1Padding");
cipher.init(Cipher.DECRYPT_MODE, privateKey);
int size = privateKey.getModulus().bitLength() / 8;
ByteArrayOutputStream baos = new ByteArrayOutputStream((secret.length + size - 12) / (size - 11) * size);
int left = 0;
for (int i = 0; i < secret.length; ) {
left = secret.length - i;
if (left > size) {
cipher.update(secret, i, size);
i += size;
} else {
cipher.update(secret, i, left);
i += left;
}
baos.write(cipher.doFinal());
}
return baos.toByteArray();
} catch (Exception e) {
logger.error("rsa decrypt failed.", e);
}
return null;
}
public byte[] sign(byte[] content) {
if (privateKey == null) {
throw new RuntimeException("private key is null.");
}
if (content == null) {
return null;
}
try {
Signature signature = Signature.getInstance("SHA1WithRSA");
signature.initSign(privateKey);
signature.update(content);
return signature.sign();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
public boolean verify(byte[] sign, byte[] content) {
if (publicKey == null) {
throw new RuntimeException("public key is null.");
}
if (sign == null || content == null) {
return false;
}
try {
Signature signature = Signature.getInstance("SHA1WithRSA");
signature.initVerify(publicKey);
signature.update(content);
return signature.verify(sign);
} catch (Exception e) {
logger.error("rsa verify failed.", e);
}
return false;
}
}
在项目中还用到了jasypt类包,主要用来对Redis、数据库的密码加密。
详情可以参考Spring Boot中使用 jasypt 处理加密问题
或者官方文档 jasypt-spring-boot
参考:
浅谈常见的七种加密算法及实现
6、说一说你们项目中会用到的依赖
1 google guava
Guava是一个Google开发的基于java的扩展项目,提供了很多有用的工具类,可以让java代码更加优雅,更加简洁。
Guava包括诸多工具类,比如Collections,cache,concurrent,hash,reflect,annotations,eventbus等。
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>28.2-jre</version>
</dependency>
参考:
google guava类库介绍
2 Apache Commons Lang3
Apache Commons Lang库提供了标准Java库函数里所没有提供的Java核心类的操作方法。Apache Commons Lang为java.lang API提供了大量的辅助工具,尤其是在String操作方法,基础数值方法,对象引用,并发行,创建及序列化,系统属性方面。
Lang3.0及其后续版本使用的包名为org.apache.commons.lang3,而之前的版本为org.apache.commons.lang,允许其在被使用的同时作为一个较早的版本。
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.9</version>
</dependency>
参考:
Commons.lang 工具
3 commons-codec
commons-codec是Apache开源组织提供的用于摘要运算、编码解码的包。常见的编码解码工具Base64、MD5、Hex、SHA1、DES等。
<dependency>
<groupId>commons-codec</groupId>
<artifactId>commons-codec</artifactId>
<version>1.9</version>
</dependency>
4 lombok
Lombok 是一种 Java™ 实用工具,可用来帮助开发人员消除 Java 的冗长,尤其是对于简单的 Java 对象(POJO)。它通过注解实现这一目的。它通过注释实现这一目的。通过在开发环境中实现Lombok,开发人员可以节省构建诸如hashCode()和equals()这样的方法以及以往用来分类各种accessor和mutator的大量时间。
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
参考:
十分钟搞懂Lombok使用与原理
5 commons-io
Apache Commons IO是Apache基金会创建并维护的Java函数库。它提供了许多类使得开发者的常见任务变得简单,同时减少重复代码,这些代码可能遍布于每个独立的项目中,你却不得不重复的编写。这些类由经验丰富的开发者维护,对各种问题的边界条件考虑周到,并持续修复相关bug。
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.6</version>
</dependency>
参考:
Java IO流学习总结七:Commons IO 2.5-FileUtils
6 Hutool
一个Java基础工具类,对文件、流、加密解密、转码、正则、线程、XML等JDK方法进行封装,组成各种Util工具类,同时提供以下组件:
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.3.8</version>
</dependency>
参考:
hutool的github库
参考:
常用的JAVA依赖库
7、国际化的项目开发要注意什么
1 需要解决页面国际化问题
详细可参考:
四种方式解决页面国际化问题——步骤详解
2 需要处理日期时间的问题
1)日期时间的国际化格式问题处理
对应的关键词:Locale
日期时间的国际化格式指的是在不同的国家和地区对日期时间的显示方式不同,主要通过不同国家地区不同的语言习惯,对同一个实现的呈现方式不同。在java中需要结合Locale类进行处理:
public class DateTest
{
public static void main(String[] args)
{
Date date = new Date();
Locale locale = Locale.CHINA;
DateFormat shortDf = DateFormat
.getDateTimeInstance(DateFormat.MEDIUM, DateFormat.MEDIUM,
locale);
System.out.println("中国格式:" + shortDf.format(date));
locale = Locale.ENGLISH;
shortDf = DateFormat
.getDateTimeInstance(DateFormat.MEDIUM, DateFormat.MEDIUM,
locale);
System.out.println("英国格式:" + shortDf.format(date));
}
}
结果:
中国格式:2020-7-1 17:55:32
英国格式:Jul 1, 2020 5:55:32 PM
2)日期时间的时区问题处理
对应的关键词:TimeZone
日期时间的时区问题,指的是在同一时刻,地球上的各个地区的日期时间不同。全球划分为24个时区,每个相邻时区时间相差一个小时(中国为了方便统一,虽然跨越5个时区,但都使用同一个时区时间),也就是说在同一时刻,全球同一时刻对应的当地时间的小时数有可能是0-23点之间的一个值。这里拿中国上海和英国伦敦举例:
public class TimeZoneTest
{
public static void main(String[] args)
{
Date date = new Date();
Locale locale = Locale.CHINA;
DateFormat shortDf = DateFormat
.getDateTimeInstance(DateFormat.MEDIUM, DateFormat.MEDIUM,
locale);
shortDf.setTimeZone(
TimeZone.getTimeZone("Asia/Shanghai"));//Asia/Chongqing
System.out.println(TimeZone.getDefault().getID());
System.out.println("中国当前日期时间:" + shortDf.format(date));
locale = Locale.ENGLISH;
shortDf = DateFormat
.getDateTimeInstance(DateFormat.MEDIUM, DateFormat.MEDIUM,
locale);
shortDf.setTimeZone(TimeZone.getTimeZone("Europe/London"));
System.out.println("英国当前日期时间:" + shortDf.format(date));
}
}
结果:
Asia/Shanghai
中国当前日期时间:2020-7-1 17:57:31
英国当前日期时间:Jul 1, 2020 10:57:31 AM
说明同一时刻,中国上海和英国伦敦相差7个小时,也就是相差7个时区。
参考:
java国际化之时区问题处理
8、项目中高并发和高可用的方案?
1 高并发方案
高并发相关常用的一些指标有响应时间(Response Time),吞吐量(Throughput),每秒查询率QPS(Query Per Second),并发用户数等。
我们在应对高并发大流量时也会采用类似“抵御洪水”的方案,归纳起来共有三种方法。
1)Scale-out(横向扩展)
分而治之是一种常见的高并发系统设计方法,采用分布式部署的方式把流量分流开,让每个服务器都承担一部分并发和流量。实际应用方案如:数据库一主多从,分裤分表,存储分片。
互联网分层架构中,各层次水平扩展的实践又有所不同:
(1)反向代理层可以通过“DNS轮询”的方式来进行水平扩展
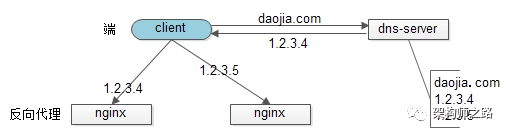
dns-server对于一个域名配置了多个解析ip,每次DNS解析请求来访问dns-server,会轮询返回这些ip。
当nginx成为瓶颈的时候,只要增加服务器数量,新增nginx服务的部署,增加一个外网ip,就能扩展反向代理层的性能,做到理论上的无限高并发
(2)站点层可以通过nginx来进行水平扩展
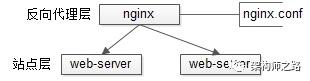
通过修改nginx.conf,可以设置多个web后端。
当web后端成为瓶颈的时候,只要增加服务器数量,新增web服务的部署,在nginx配置中配置上新的web后端,就能扩展站点层的性能,做到理论上的无限高并发。
(3)服务层可以通过服务连接池来进行水平扩展
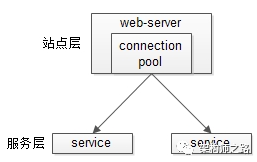
站点层通过RPC-client调用下游的服务层RPC-server时,RPC-client中的连接池会建立与下游服务多个连接,当服务成为瓶颈的时候,只要增加服务器数量,新增服务部署,在RPC-client处建立新的下游服务连接,就能扩展服务层性能,做到理论上的无限高并发。如果需要优雅的进行服务层自动扩容,这里可能需要配置中心里服务自动发现功能的支持。
(4)数据库可以按照数据范围,或者数据哈希的方式来进行水平扩展
1.按照范围水平拆分
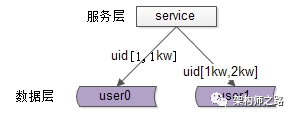
每一个数据服务,存储一定范围的数据,上图为例:
user0库,存储uid范围1-1kw
user1库,存储uid范围1kw-2kw
这个方案的好处是:
(1)规则简单,service只需判断一下uid范围就能路由到对应的存储服务;
(2)数据均衡性较好;
(3)比较容易扩展,可以随时加一个uid[2kw,3kw]的数据服务;
不足是:
(1)请求的负载不一定均衡,一般来说,新注册的用户会比老用户更活跃,大range的服务请求压力会更大;
2.按照哈希水平拆分
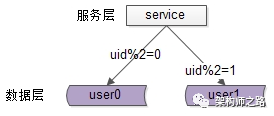
每一个数据库,存储某个key值hash后的部分数据,上图为例:
user0库,存储偶数uid数据
user1库,存储奇数uid数据
这个方案的好处是:
(1)规则简单,service只需对uid进行hash能路由到对应的存储服务;
(2)数据均衡性较好;
(3)请求均匀性较好;
不足是:
(1)不容易扩展,扩展一个数据服务,hash方法改变时候,可能需要进行数据迁移;
这里需要注意的是,通过水平拆分来扩充系统性能,与主从同步读写分离来扩充数据库性能的方式有本质的不同。
通过水平拆分扩展数据库性能:
(1)每个服务器上存储的数据量是总量的1/n,所以单机的性能也会有提升;
(2)n个服务器上的数据没有交集,那个服务器上数据的并集是数据的全集;
(3)数据水平拆分到了n个服务器上,理论上读性能扩充了n倍,写性能也扩充了n倍(其实远不止n倍,因为单机的数据量变为了原来的1/n);
通过主从同步读写分离扩展数据库性能:
(1)每个服务器上存储的数据量是和总量相同; (2)n个服务器上的数据都一样,都是全集;
(3)理论上读性能扩充了n倍,写仍然是单点,写性能不变;
2)缓存
使用缓存来提高系统的性能,就好比用“拓宽河道”的方式抵抗高并发大流量的冲击。
3)异步
在某些场景下,未处理完成之前我们可以让请求先返回,在数据准备好之后再通知请求方,这样可以在单位时间内处理更多的请求。
参考:
究竟啥才是互联网架构“高并发”
2 高可用的方案
保证系统高可用,架构设计的核心准则是:冗余。
大部分互联网公司的系统架构:
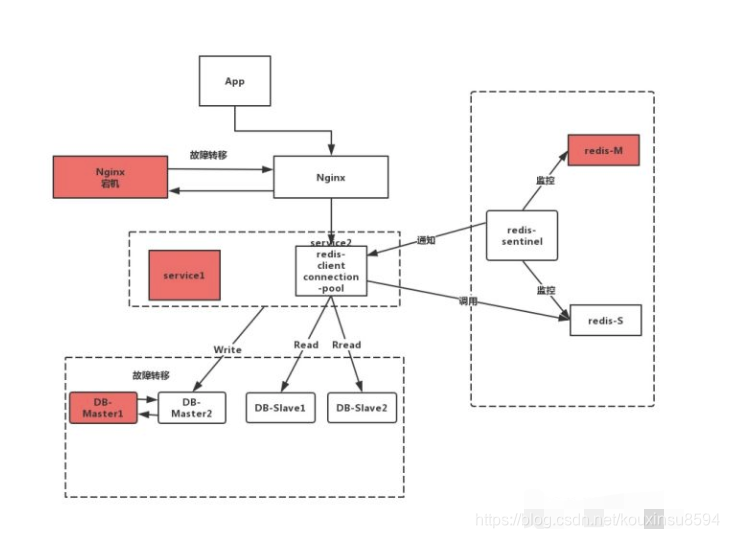
1、从客户端到反向代理Nginx这块,这个1台nginx是会可能发生故障的,所以这里可以再冗余一台Nginx,可以利用linux的 keeplived进行探测可用性,当一台Nginx挂了之后,责会自动转移到另一台Nginx机器上来,从而保证高可用。
2、从反向代理到后端服务service这块,反向代理这块,目前最受欢迎的是nginx,性能方面表现也很好,nginx能够自动探测后端服务的可用性,只需在nginx,config配置多台后端服务就行了。
3、从后端服务到缓存这块,缓存这块推荐使用redis主从同步方案来达到高可用,redis主从同步加上sentine哨兵机制来自动探活redis实例。
4、从后端服务到写数据库这块,这里可以采用双主机制,一台给线上使用,另一台冗余,当线上那台挂了才会阶梯过来使用写功能,同样是通过linux的keepalived进行自动探活。
5、从后端服务到读数据库这块,这里同样是将读库部署多台,例如部署2台,通过代码段增加连接池组件进行路由读库和探活。
注:大部分互联网技术,数据库层都用了主从同步,读写分离架构,所以数据库层的高可用,又分为“读库高可用”与“写库高可用”两类
保证系统高可用的几个方面
1)超时机制
当并发稍大一点的情况下会出现返回很慢,一直占用当前资源,使得我们大量的请求阻塞等时需要对此进行设置合理的超时时间,来快速结束这些慢请求,来保证我们系统的可用性。
2)降级
在面对流量剧增的时候,例如,秒杀,大促等这些剧增的大流量,可以将不影响本次业务的流程也砍掉,不去调用了,直接走核心业务。其实各大电商都是采取这种方案来保证系统的可用性的。
3)限流
限流是,本来我系统只能抗住10万并发,然后现在我们运营搞了什么牛逼的大促,搞的来了10倍的流量,那么系统就把瞬间不能处理的流量给截断,直接返回给用户,用户可以待会儿再试。所以限流就是为了保证系统的高可用而限制住大流量的情况发生。
参考:
你的系统怎么保证高可用
9、为什么需要用分布式服务
1、业务拆分
大型网站为了应对日益复杂的业务场景,通过使用分而治之的手段将整个网站业务分成不同的产品线,
2、分布式服务
3、网站扩展性
扩展性是指对现有系统影响最小的情况下,系统功能可持续扩展或提升的能力。设计网站可扩展架构的核心思想是模块化,并在此基础上,降低模块间的耦合性,提供模块的复用性。模块通过分布式部署,独立的模块部署在独立的服务器上(集群)从物理上分离模块之间的耦合关系。模块分布式部署以后具体聚合方式主要有分布式消息队列和分布式服务。
-
利用分布式消息队列降低系统耦合性
模块之间不存在直接调用,那么新增模块或者修改模块对其他模块影响最小,这样系统的可扩展性无疑更好一些。
通过在低耦合的模块之间传输事件消息,以保持模块的松散耦合,并借助事件消息的通信完成模块间合作,典型的架构就是生产者消费者模式。最常用的就是分布式消息队列 -
利用分布式服务打造可复用的业务平台
分布式服务则通过接口分解系统耦合性,不同子系统通过相同的接口描述进行服务调用。
大型网站分布式服务的需求与特点:
负载均衡
失效转移
高效的远程通信
整合异构系统
对应用最小入侵
版本管理
实时监控
简单来说
分布式:不同模块部署在不同服务器上
作用:分布式解决网站高并发带来问题
参考:
大型网站为什么要使用分布式服务
分布式、集群、微服务、SOA 之间的区别
十二、设计模式
1、常用的设计模式
1 单例模式
1)为什么要用到单例模式?
(1)资源共享的情况下,避免由于资源操作时导致的性能或损耗等。如上述中的日志文件,应用配置。
(2)控制资源的情况下,方便资源之间的互相通信。如线程池等。
2)Spring单例Bean与单例模式的区别
Spring单例Bean与单例模式的区别在于它们关联的环境不一样,单例模式是指在一个JVM进程中仅有一个实例,而Spring单例是指一个Spring Bean容器(ApplicationContext)中仅有一个实例。
2 工厂模式
1)简单工厂模式
2)抽象工厂模式
3 策略模式
4 建造者模式
5 适配器模式
6 代理模式
7 责任链模式
-
定义:
允许你将请求沿着处理者链进行发送。收到请求后,每个处理者均可对请求进行处理,或将其传递给链上的下个处理者。核心是解决一组服务中的先后执行处理关系 -
为什么要用:
可以让各个服务模块更加清晰,而每一个模块可以通过next的方式进行获取。而每一个next是由继承的统一抽象类实现的,最终所有类的职责可以动态的进行编排使用,编排的过程可以做成可配置化。很好的处理单一职责和开闭原则,简单耦合也使对象关系更加清晰,而且外部的调用方并不需要关系责任链是如何处理的。 -
缺点:
1)每个关卡中都有下一关的成员变量并且是不一样的,形成链很不方便
2)代码的扩展性非常不好
2、设计模式的六大原则
1 单一职责原则(Single Responsibility Principle,简称SRP )
核心思想:应该有且仅有一个原因引起类的变更
问题描述:假如有类Class1完成职责T1,T2,当职责T1或T2有变更需要修改时,有可能影响到该类的另外一个职责正常工作。
好处:类的复杂度降低、可读性提高、可维护性提高、扩展性提高、降低了变更引起的风险。
需注意:单一职责原则提出了一个编写程序的标准,用“职责”或“变化原因”来衡量接口或类设计得是否优良,但是“职责”和“变化原因”都是不可以度量的,因项目和环境而异。
2 里氏替换原则(Liskov Substitution Principle,简称LSP)
核心思想:在使用基类的的地方可以任意使用其子类,能保证子类完美替换基类。
通俗来讲:只要父类能出现的地方子类就能出现。反之,父类则未必能胜任。
好处:增强程序的健壮性,即使增加了子类,原有的子类还可以继续运行。
需注意:如果子类不能完整地实现父类的方法,或者父类的某些方法在子类中已经发生“畸变”,则建议断开父子继承关系 采用依赖、聚合、组合等关系代替继承。
3 依赖倒置原则(Dependence Inversion Principle,简称DIP)
核心思想:高层模块不应该依赖底层模块,二者都该依赖其抽象;抽象不应该依赖细节;细节应该依赖抽象;
说明:高层模块就是调用端,低层模块就是具体实现类。抽象就是指接口或抽象类。细节就是实现类。
通俗来讲:依赖倒置原则的本质就是通过抽象(接口或抽象类)使个各类或模块的实现彼此独立,互不影响,实现模块间的松耦合。
问题描述:类A直接依赖类B,假如要将类A改为依赖类C,则必须通过修改类A的代码来达成。这种场景下,类A一般是高层模块,负责复杂的业务逻辑;类B和类C是低层模块,负责基本的原子操作;假如修改类A,会给程序带来不必要的风险。
解决方案:将类A修改为依赖接口interface,类B和类C各自实现接口interface,类A通过接口interface间接与类B或者类C发生联系,则会大大降低修改类A的几率。
好处:依赖倒置的好处在小型项目中很难体现出来。但在大中型项目中可以减少需求变化引起的工作量。使并行开发更友好。
4 接口隔离原则(Interface Segregation Principle,简称ISP)
核心思想:类间的依赖关系应该建立在最小的接口上
通俗来讲:建立单一接口,不要建立庞大臃肿的接口,尽量细化接口,接口中的方法尽量少。也就是说,我们要为各个类建立专用的接口,而不要试图去建立一个很庞大的接口供所有依赖它的类去调用。
问题描述:类A通过接口interface依赖类B,类C通过接口interface依赖类D,如果接口interface对于类A和类B来说不是最小接口,则类B和类D必须去实现他们不需要的方法。
需注意:接口尽量小,但是要有限度。对接口进行细化可以提高程序设计灵活性,但是如果过小,则会造成接口数量过多,使设计复杂化。所以一定要适度
提高内聚,减少对外交互。使接口用最少的方法去完成最多的事情
为依赖接口的类定制服务。只暴露给调用的类它需要的方法,它不需要的方法则隐藏起来。只有专注地为一个模块提供定制服务,才能建立最小的依赖关系。
5 迪米特法则(Law of Demeter,简称LoD)
核心思想:类间解耦。
通俗来讲: 一个类对自己依赖的类知道的越少越好。自从我们接触编程开始,就知道了软件编程的总的原则:低耦合,高内聚。无论是面向过程编程还是面向对象编程,只有使各个模块之间的耦合尽量的低,才能提高代码的复用率。低耦合的优点不言而喻,但是怎么样编程才能做到低耦合呢?那正是迪米特法则要去完成的。
6 开放封闭原则(Open Close Principle,简称OCP)
核心思想:尽量通过扩展软件实体来解决需求变化,而不是通过修改已有的代码来完成变化
通俗来讲: 一个软件产品在生命周期内,都会发生变化,既然变化是一个既定的事实,我们就应该在设计的时候尽量适应这些变化,以提高项目的稳定性和灵活性。
总结
单一职责原则告诉我们实现类要职责单一;里氏替换原则告诉我们不要破坏继承体系;依赖倒置原则告诉我们要面向接口编程;接口隔离原则告诉我们在设计接口的时候要精简单一;迪米特法则告诉我们要降低耦合。而开闭原则是总纲,他告诉我们要对扩展开放,对修改关闭。
十三、Nginx相关
1、Nginx的应用
1 动静分离
动静分离的好处:
1)api接口服务化:动静分离之后,后端应用更为服务化,只需要通过提供api接口即可,可以为多个功能模块甚至是多个平台的功能使用,可以有效的节省后端人力,更便于功能维护。
2)前后端开发并行:前后端只需要关心接口协议即可,各自的开发相互不干扰,并行开发,并行自测,可以有效的提高开发时间,也可以有些的减少联调时间
3)减轻后端服务器压力,提高静态资源访问速度:后端不用再将模板渲染为html返回给用户端,且静态服务器可以采用更为专业的技术提高静态资源的访问速度。
2 反向代理
所谓反向代理,很简单,其实就是在location这一段配置中的root替换成proxy_pass即可。root说明是静态资源,可以由Nginx进行返回;而proxy_pass说明是动态请求,需要进行转发,比如代理到Tomcat上。
反向代理的作用
- 保障应用服务器的安全(增加一层代理,可以屏蔽危险攻击,更方便的控制权限)
- 实现负载均衡(稍等~下面会讲)
- 实现跨域(号称是最简单的跨域方式)
3 负载均衡
在服务器集群中,Nginx 可以将接收到的客户端请求“均匀地”(严格讲并不一定均匀,可以通过设置权重)分配到这个集群中所有的服务器上。这个就叫做负载均衡。
4 正向代理
正向代理,意思是一个位于客户端和原始服务器(origin server)之间的服务器,为了从原始服务器取得内容,客户端向代理发送一个请求并指定目标(原始服务器),然后代理向原始服务器转交请求并将获得的内容返回给客户端。客户端才能使用正向代理。当你需要把你的服务器作为代理服务器的时候,可以用Nginx来实现正向代理。
参考:
连前端都看得懂的《Nginx 入门指南》
8分钟带你深入浅出搞懂Nginx
十四、应用相关
1、给你一个文件夹,如何去找到文件夹包括子文件夹下的文件名,说一下实现思路
我说的是
1、使用File封装初始目录,
2、打印这个目录
3、获取这个目录下所有的子文件和子目录的数组。
4、遍历这个数组,取出每个File对象
4-1、 如果File是否是一个文件,打印
4-2、否则就是一个目录,递归调用
由递归引出的深度优先和广度优先的概念,啊,我直接说我不知道,后来去查了一下,在jdk8中可以使用Files.walk()方法递归的去查找目录下所有文件。
// 路径
String path = "xxx";
try (Stream<Path> paths = Files.walk(Paths.get(path))){
List<Path> fileNames = paths
.filter(Files::isRegularFile)
.collect(Collectors.toList());
fileNames.forEach(System.out::println);
} catch (IOException e) {
e.printStackTrace();
}
看了Files.walk()方法的解释:
通过遍历根在给定起始文件处的文件树,返回一个用Path惰性填充的流。文件树是深度优先遍历的,流中的元素是Path对象,就像通过解析相对于start的路径一样获得。 这个方法的工作原理就好像调用它就等同于计算表达式: walk(start, Integer.MAX_VALUE, options)
这个方法的工作原理就好像调用它等同于求值表达式,换句话说,它访问文件树的所有级别。
返回的流封装了一个或多个directorystream。如果需要及时处理文件系统资源,应该使用try-with-resources构造确保流的close方法在流操作完成后被调用。操作关闭的流会导致IllegalStateException异常。
maxDepth参数,设置要递归的深度;Files.walk(Paths.get(path),2)
默认不会自动跟随符号链接, 设置options参数FOLLOW_LINKS选项,则遵循符号链接。 Files.walk(Paths.get(path),FileVisitOption.FOLLOW_LINKS)
String path = "D:\\xxx";
//过滤出目录
try (Stream<Path> paths = Files.walk(Paths.get(dirName))) {
paths.filter(Files::isDirectory)
.forEach(System.out::println);
}
//按后缀名过滤
try (Stream<Path> paths = Files.walk(Paths.get(dirName), 2)) {
paths.map(path -> path.toString()).filter(f -> f.endsWith(".png"))
.forEach(System.out::println);
}
参考:
java获取文件夹下所有的文件

















 640
640

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









