






大家好,本期内容由好哥们抄手提供,本期我们做了一个文献总结工具,对于写基金和写文献综述都有很大帮助。
目录
开发原因
-
外文文献阅读效率低
虽然不借助工具也能完成外文文献的阅读,但是借助工具却能极大地提升阅读效率,过去的一些翻译软件的翻译能力已经无法和AI大模型的翻译能力相比较,因此考虑借助Deepseek的翻译能力提升外文文献阅读效率。
-
官方能力限制
尽管Deepseek支持上传最多50个文件,但是实际测试发现,当文件较大时,虽然只有几个文件,Deepseek却无法完整阅读,因此考虑开发工具实现完整地对批量文件的阅读和总结。
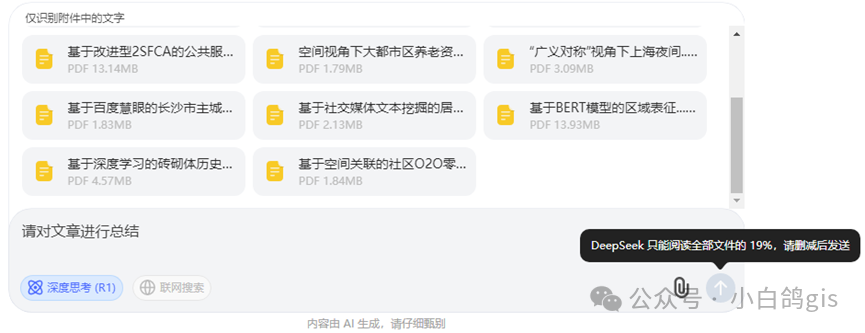
工具效果
工具整合了PDF解析能力以及Deepseek的文献阅读和翻译能力,可以实现批量上传文献,对文献按照标准化结构总结并保存输出结果和思考过程,不论输入中文文献还是英文文献,都可以通过总结得到较为理想的结果。
工具用途
-
提升阅读效率:
通过Deepseek大模型实现文献秒级解析,提升阅读效率。
-
学术写作增强:
在写基金、写论文引言或者写文献综述时,通常需要阅读大量文献,通过该工具可以批量总结文献内容,有利于用户把握主要信息,缩短写作时间。
主要思路
-
PDF解析:利用pdfplumber库,从pdf中提取文字并保存为文件。主要提取参考文献之前的文字内容。
-
Deepseek R1大模型:通过API调用Deepseek R1模型,将保存的文件作为输入,并且指示Deepseek按照研究背景、研究方法、研究结果、讨论的结构进行输出,并且附上标题和作者信息。
注:通过API调用的Deepseek R1是满血版R1。
代码展示
PDF解析代码
import os
import pdfplumber
#=============================================================寻找pdf文件路径的函数===========================================================
def file_name(file_dir):
pdf_file_paths = [] # 用于保存后缀为pdf的完整文件路径
for root, dirs, files in os.walk(file_dir):
for file in files:
# 判断文件名后缀是否为.pdf(忽略大小写)
if file.lower().endswith('.pdf'):
full_path = os.path.join(root, file)
pdf_file_paths.append(full_path)
print('找到pdf文件:', full_path)
return pdf_file_paths
file_dir = 'G:\\文献汇总\\files\\' #pdf文献路径
save_path = 'G:\\文献汇总\\pytxt\\' #输出保存的txt路径
# 调用函数并获取所有文件的完整路径
all_file_paths = file_name(file_dir)
for pdf_path in all_file_paths:
# 用于保存提取的文本
output_text = ""
# 打开 PDF 文件
with pdfplumber.open(pdf_path) as pdf:
# 遍历每一页
for page in pdf.pages:
page_text = page.extract_text()
if not page_text:
continue
# 检查当前页是否包含“参考文献”
if "reference" in page_text:
# 如果找到,提取“参考文献”之前的文本内容
ref_index = page_text.find("reference")
output_text += page_text[:ref_index]
# 假设从此处起后面的都是参考文献,直接退出循环
break
elif:
if "参考文献" in page_text:
# 如果找到,提取“参考文献”之前的文本内容
ref_index = page_text.find("参考文献")
output_text += page_text[:ref_index]
# 假设从此处起后面的都是参考文献,直接退出循环
break
else:
output_text += page_text
# 将提取的内容写入文本文件
output_text = output_text.replace('\n', '').replace('\r', '')
with open(save_path + pdf_path.split("\\")[-1].split(".")[0] + "output.txt", "w", encoding="utf-8") as f:
f.write(output_text)
print("文本提取完成,结果保存在 output.txt 中。")文献总结代码
import pdfplumber
import re
from openai import OpenAI
import pandas as pd
import os
#=============================================================寻找txt文件路径的函数===========================================================
def file_name(file_dir):
pdf_file_paths = [] # 用于保存后缀为txt的完整文件路径
for root, dirs, files in os.walk(file_dir):
for file in files:
# 判断文件名后缀是否为.txt(忽略大小写)
if file.lower().endswith('.txt'):
full_path = os.path.join(root, file)
pdf_file_paths.append(full_path)
print('找到txt文件:', full_path)
return pdf_file_paths
#=============================================================AI模型调用===========================================================
# 初始化 OpenAI 客户端
client = OpenAI(
api_key="sk*********di", # 替换自己的 API 密钥
base_url="https://api.siliconflow.cn/v1",
)
#messages = [{"role": "system", "content": "You are a helpful assistant."}]
stream_mode = True # True:启用流式输出,False:非流式输出
def get_response(client, messages, stream=False):
"""获取助手回复"""
try:
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-R1",
messages=messages,
# max_tokens=1024, #默认4096
# response_format={n
# 'type': 'text'
# },
# temperature=0.7,
stream=stream, # 根据传入的参数控制流式输出,默认false
)
return response
except Exception as e:
print(f"API 请求失败: {str(e)}")
return None
# 流式拼接(保存对话历史)
def get_stream_response(response):
"""提取并拼接流式返回的内容"""
return ''.join(
chunk['choices'][0]['delta']['content']
for chunk in response
if chunk.get('choices') and chunk['choices'][0].get('delta') and chunk['choices'][0]['delta'].get('content')
)
def chat(prompt, user_input):
print("\n正在上传资料,请稍等。")
# 添加用户消息到对话历史
messages = messages = [
{"role": "system", "content": "你是一个母语为中文的科学家"},
{"role": "user", "content": prompt + user_input},
]
# 获取助手回复
response = get_response(client, messages, stream=stream_mode)
if response:
if stream_mode:
print("助手: ", end='', flush=True) # 不换行,实时输出
# 逐步接收并输出助手的回复
chunk_reasoning_content_list = []
chunk_content_list = []
for chunk in response:
if chunk.choices[0].delta.content == None:
chunk_reasoning_content_message = chunk.choices[0].delta.reasoning_content
chunk_reasoning_content_list.append(chunk_reasoning_content_message)
print(chunk_reasoning_content_message, end='', flush=True) # 逐步输出
else:
chunk_content_message = chunk.choices[0].delta.content
chunk_content_list.append(chunk_content_message)
print(chunk_content_message, end='', flush=True) # 逐步输出
chunk_reasoning_content_text = ''.join(chunk_reasoning_content_list)
chunk_content_text = ''.join(chunk_content_list)
return chunk_reasoning_content_text, chunk_content_text
print() # 输出完毕后换行
else:
assistant_response = response.choices[0].message.content
content = response.choices[0].message.content
reasoning_content = response.choices[0].message.reasoning_content
return content, reasoning_content
print(f"助手: {assistant_response}")
assistant_response_content = get_stream_response(response) if stream_mode else response.choices[
0].message.content
assistant_response_reasoning_content = get_stream_response(response) if stream_mode else response.choices[
0].message.content
else:
print("未能获取回复,请查找原因。")
#=============================================================AI模型询问===========================================================
if __name__ == "__main__":
file_dir = r'G:\\文献汇总\\pytxt' # txt论文存放路径
save_path = r'G:\\文献汇总\\md_file' # txt结果输出路径
# 调用函数并获取所有文件的完整路径
all_file_paths = file_name(file_dir)
# 创建收集回答的list
content_list = []
reasoning_content_list = []
for text in all_file_paths:
# print(file)
# 提取论文文本
with open(text, 'r', encoding='utf-8') as f:
paper = f.read()
# 开始论文pdf提取的文字传入模型,
prompt = (
"你是一个环境eDNA领域的专家,非常擅长数据分析和生态学等方面的知识,"
"请总结下面文章中研究背景和意义,按照以下的结构:\n"
"1. 研究背景\n"
"2. 研究方法\n"
"3. 研究结果\n"
"4. 讨论\n"
"请分点列出并进行总结,着重分析理解研究方法、研究结果和讨论部分,并且细化到每个小节,所有数据均严格来自于本文"
"并在最后附上作者和原文文章标题信息,"
)
user_input = ( paper )
reasoning_content, content = chat(prompt, user_input)
content_list.append(content)
#print(reasoning_content, content )
# 同时进行每个content的保存,防止网络报错导致无法保存
reasoning_content_list.append(reasoning_content)
with open(save_path + text.split('.')[0].split('\\')[-1] + "_DS_content_output.txt", "w", encoding="utf-8") as file:
file.write(content)
with open(save_path + text.split('.')[0].split('\\')[-1] + "_DS_reasoning_content_output.txt", "w", encoding="utf-8") as file:
file.write(reasoning_content)
df = pd.DataFrame()
df['content'] = content_list
df['reasoning_content'] = reasoning_content_list
df.to_excel("output.xlsx", index=False, encoding="utf-8")使用方法
-
安装Python
-
安装所需的库,包括pdfplumber、re、openai和pandas,通过以下代码安装:
pip install pdfplumber re openai pandas -
获取Deepseek API_Key,API_Key获取方法可以关注公众号查看
官方API_Key获取教程
硅基流动平台API_Key获取教程 -
替换API_Key并运行代码
获取帮助
如果你希望获取源文件或者更多帮助,可以关注公众号“小白鸽gis”



















 1173
1173

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









