







进程间通信
前言
1. 概念
进程间通信(IPC):不同进程之间进行数据交换和信息传递的过程。
- 因为进程独立性的原因,所以进程之间通信是有成本的。
成本:需要通过特定的机制来实现,这个过程会增加额外的开销和复杂性。还有数据传输、同步、互斥等方面的开销。
2. 目的
其实概念就是IPC存在的目的。
进一步解释:
- 数据传输:一个进程需要把数据传输到另一个进程。
- 资源共享:多个进程共享同一个资源
- 通知:一个进程通知另一个(不限于一个)发生了某些事件。(eg:子进程退出,要通知父进程)
- 进程控制:控制进程希望拦截被控制进程的异常,并及时知道它的状态改变
- 协同:… (eg:信号量)
3. 怎么做
- 让不同的进程看到同一份“资源” —— 特定形式的内存空间
- “资源”一般是由OS提供。因为如果是通信双方的进程提供,那这一份资源本质就是这个进程独有的,会破坏进程间的独立性
- 进程通信本质就是访问OS,进程代表的就是用户。 “资源”的 创建 -> 使用 -> 释放 ——>都离不开system call (因为群众有坏人,OS不放心把底层暴露出来)。
4. 分类
- system call -> 从底层设计,接口设计,都要由OS设计。一般OS会有独立的通信模块(IPC通信模块)——> 隶属文件系统
- 既然出现通信,就要制定标准,进程间通信的标准:
- System V(本机通信)
- POSIX (网络方便)
本文先介绍的是System V和基于文件级别的通信方式——管道
System V IPC:
- System V 共享内存(主讲)
- System V 消息队列(介绍原理)
- System V 信号量(介绍原理)
一、管道
因为设计是数据从一端进去从另一端出去,是一种单向的通信方式,所以命名为管道
1. 管道原理
管道:基于文件级别的通信方式
原理图:介绍如何基于文件
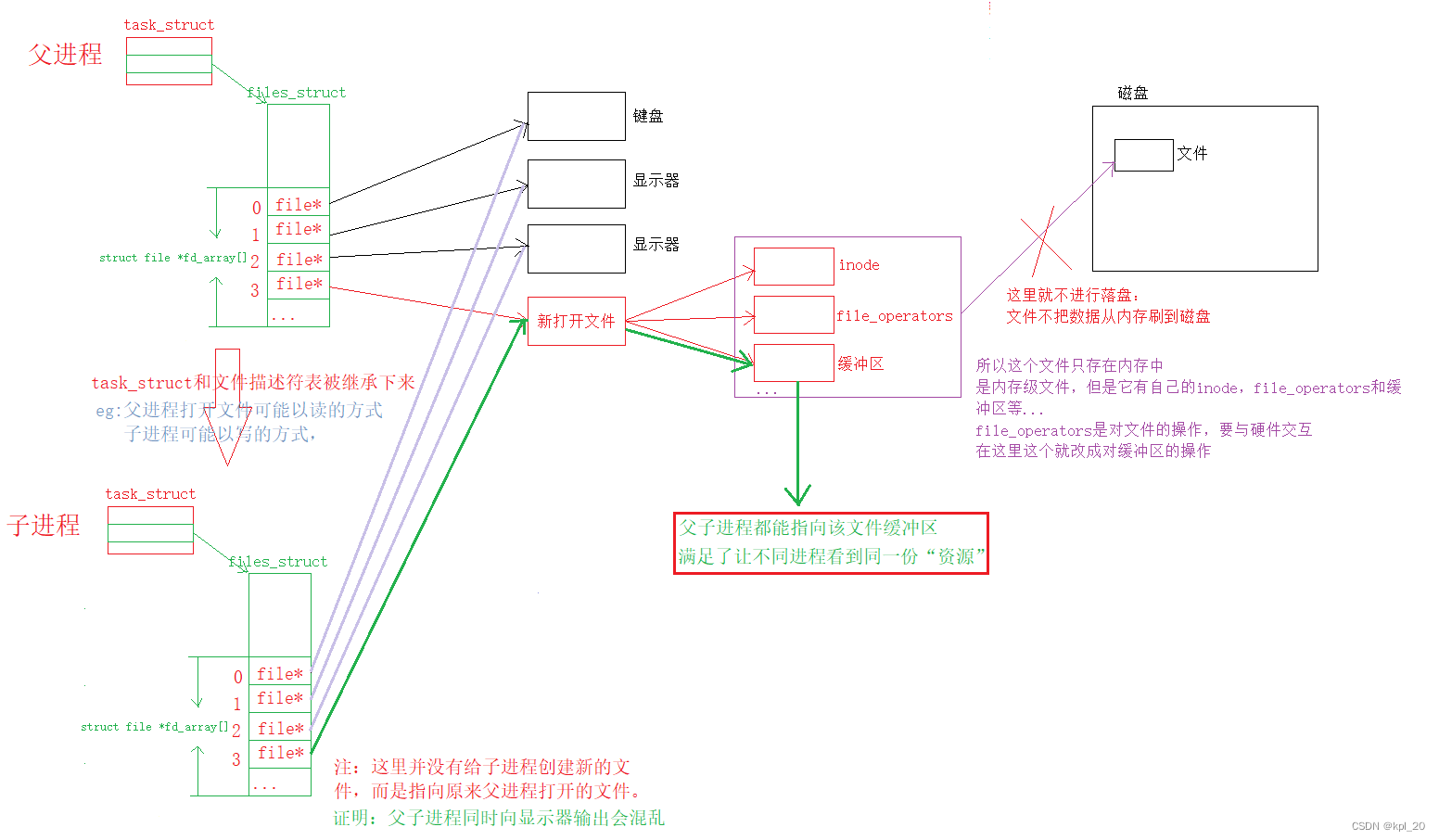
再叙述一下:
- 文件本身是不会继承下去的,被子进程继承的是文件描述符,所以通过文件描述符父子(具有血缘关系的)进程就可以对同一份资源进行访问。这就是管道的前提条件
- 因为进程间通信的数据基本不需要落盘,所以内存级文件通信提高了效率,减少拷贝和与外设的交互
注:因为和文件有关,这里涉及文件的知识就不再介绍,想要了解可以看另一篇文章IO Linux
2. 匿名管道
①理解匿名管道
匿名管道:用于父子进程、兄弟进程,具有亲缘关系的进程之间通信。管道是一种单向通信方式,数据只能在一个方向上流动。
简化图:
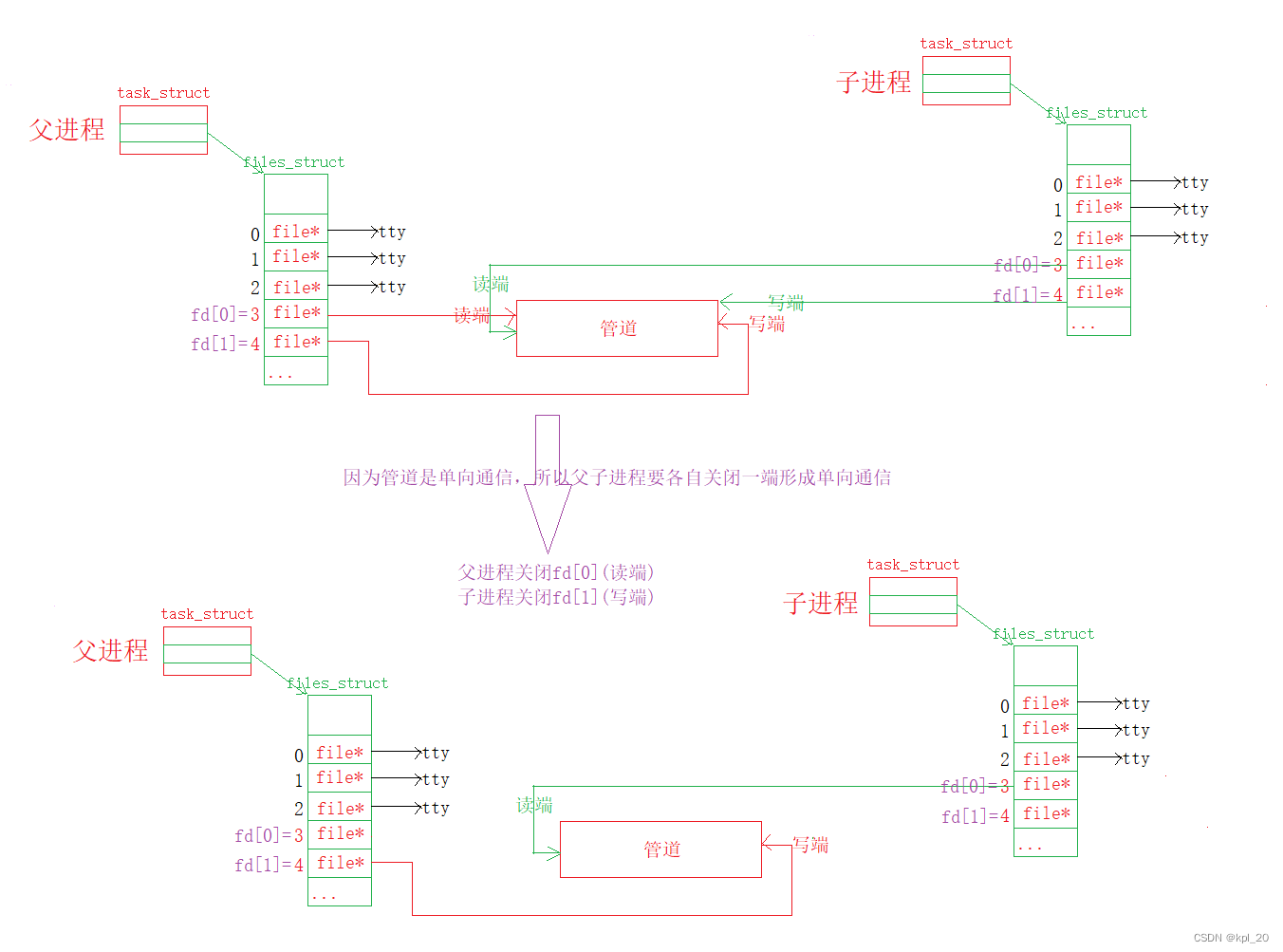
匿名管道的特殊性导致:
- 只能用于共同祖先的进程(具有亲缘关系)之间进行通信。通常一个管道由一个进程创建,然后fork,此后父子进程就都可以使用该管道。
- 不能双向通信,所以想要双向通信,再建立一条匿名管道
- 到这里只是让通信进程看到了同一份“资源”,还没有进行通信。所以因为进程独立性,进程间通信是需要成本的。
注:
数据为脏:无论读写都要先把数据加载到内存中。如果进行修改,在内存中修改好,此时内存中的数据和磁盘上的数据不一致,此时内存中的就是脏数据
②创建匿名管道——pipe
系统调用介绍:pipe
头文件:
#include <unistd.h>
函数声明:
int pipe(int pipefd[2]);
函数参数:
pipefd[2]:两个整型元素的数组。输出型参数:这两个元素带出来的是管道的文件描述符。
pipefd[0]:读端的文件描述符
pipefd[1]:写端的文件描述符
返回值:
1. 成功返回0
2. 失败返回-1,错误码被设置
输出型参数pipefd[2]:根据上面匿名管道的简化图,可以看到想要建立任取一方读或写的单向通信。就需要在父进程时,以读和写两种方式打开管道文件然后fork,子进程继承这两种方式,然后根据需要再关闭通信进程对应一端。
使用系统调用——pipe:
介绍下面这串代码的逻辑:
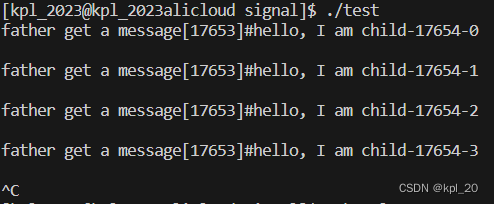
创建管道 -> 子进程继承,然后关闭子进程的读端和父进程的写端。子进程每秒写一条信息,父进程读。对子进程的写和父进程的读都进行封装,读写方法我会单独拿出来验证管道的四种状态。
#include <iostream>
#include <string>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <cstdio>
#include <cstring>
#include <cstdlib>
#include <cerrno>
using namespace std;
#define SIZE 1024
// child -> w
void Writer(int wfd)
{
string s = "hello, I am child";
pid_t child_pid = getpid();
int number = 0; //展现数据是变化的
char buffer[SIZE];
while (true)
{
buffer[0] = 0; // 字符串情况,告诉阅读代码的人,这个数组被当成字符串使用
// 通过上面三个数据构建字符串
snprintf(buffer, sizeof(buffer), "%s-%d-%d\n", s.c_str(), child_pid, number++);
// 发送/写入给父进程信息 system call
write(wfd, buffer, strlen(buffer));
sleep(1); //一秒写一条信息
}
}
// father -> r
void Reader(int rfd)
{
char buffer[SIZE];
while (true)
{
buffer[0] = 0; // 告诉阅读代码的人,这个数组被当成字符串使用
ssize_t n = read(rfd, buffer, sizeof(buffer));
if (n < 0)
break;
else if (n == 0)
{
printf("read file done!\n");
break;
}
else
{
buffer[n] = 0; // 因为是字符串,所以读出来要注意
cout << "father get a message[" << getpid() << "]#" << buffer << endl;
}
}
}
int main()
{
//创建管道
int pipefd[2] = {0};
int n = pipe(pipefd);
if (n < 0)
exit(errno); //创建失败直接退出
// child -> w, father -> r
pid_t id = fork();
if (id < 0)
exit(errno);
else if (id == 0)
{
// child 关闭读端
close(pipefd[0]);
// 写方法
Writer(pipefd[1]);
close(pipefd[1]);
exit(0);
}
// father
close(pipefd[1]);
// 读方法
Reader(pipefd[0]);
// wait child process
pid_t rid = waitpid(id, nullptr, 0);
if (rid < 0)
exit(errno);
close(pipefd[0]);
return 0;
}
运行结果:
管道的四种情况:
- 读写端正常 ,写方法改成从键盘输入,其余代码不变
改变写方法代码:
void Writer(int wfd)
{
pid_t child_pid = getpid();
char buffer[SIZE];
while (true)
{
buffer[0] = 0;
cout << "Please Enter@";
fgets(buffer, sizeof(buffer), stdin);
buffer[strlen(buffer) - 1] = '\0'; //把换行符去掉
// 发送/写入给父进程信息 system call
write(wfd, buffer, strlen(buffer));
sleep(1);
}
}
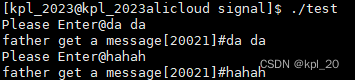
实验结果:
现象:
- 在子进程输入数据然后向父进程发送消息,父进程进行读取,再一次写的时候,上一次信息清空(调整位置),父进程读取新内容
- 子进程写完之后父进程读取,因此子进程未写之前,父进程读端处于阻塞状态
- 读写端正常,写端写满
改变读写方法代码:
void Writer(int wfd)
{
int cnt = 0;
while(true)
{
cout << cnt++ << endl;
write(wfd, "c", 1);
}
}
void Reader(int rfd)
{
while(true)
{
sleep(5);
break;
}
}
实验结果:
现象:
- 写端写满,写端陷入阻塞,管道写入了65536字节,即64KB
- 不同内核,可能有一定差别
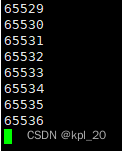
- 读端正常,写端关闭
改变写方法代码:
void Writer(int wfd)
{
string s = "hello, I am child";
pid_t child_pid = getpid();
int cnt = 3;
char buffer[SIZE];
while (cnt)
{
buffer[0] = 0;
snprintf(buffer, sizeof(buffer), "%s-%d-%d\n", s.c_str(), child_pid, cnt--);
write(wfd, buffer, strlen(buffer));
//读三次之后关闭文件描述符
if(cnt == 0)
{
close(wfd);
cout << "wfd close!!" << endl;
}
sleep(1);
}
}
实验结果:
现象:
- 正常读写三次之后,写端关闭,读端会返回0,表面读到文件尾,不会被阻塞
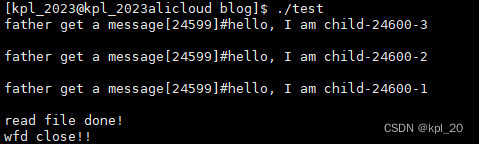
- 写端正常,读端关闭
改变读方法代码,并且在父进程等待处获取子进程退出状态
void Reader(int rfd)
{
char buffer[SIZE];
int cnt = 3;
while (cnt)
{
buffer[0] = 0; // 告诉阅读代码的人,这个数组被当成字符串使用
ssize_t n = read(rfd, buffer, sizeof(buffer));
if (n < 0)
break;
else if (n == 0)
{
printf("read file done!\n");
break;
}
else
{
buffer[n] = 0; // 因为是字符串,所以读出来要注意
cout << "father get a message[" << getpid() << "]#" << buffer << endl;
}
cnt--;
if(cnt == 0)
{
close(rfd);
}
}
}
//在main函数最后多加了几行的内容 ——> 获取子进程退出状态
int status = 0;
pid_t rid = waitpid(id, &status, 0);
if (rid < 0)
exit(errno);
cout << "wait success pid:" << id;
cout << " exit code:" << ((status >> 8)&0xFF) << " exit signal:" << (status&0x7F) << endl;
实验结果:
现象:
- 首先我们没有对写代码做任何更改,只是读端被我们读了三次关闭了。结果OS杀掉正在写入的进程,子进程异常退出。
- 父进程等待子进程,获取的子进程退出信息,退出码没有问题,退出信号是13号信号
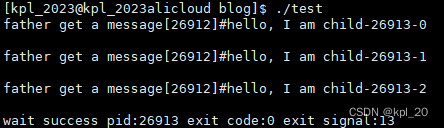

③模拟实现进程池——管道
注:我们可以使用管道模拟实现进程池
由父进程创建一批进程,父子进程之间建立管道,当父进程有任务时,给子进程发送信号,让指定的子进程去完成该任务。进程池代码实现链接:本质上这个进程池的实现,体现了OS底层的模式:先描述再组织的思想。首先创建一个结构体进行描述,然后使用C++的容器进行管理。
简易图解:
每次有任务时,父进程只需要把任务码通过管道发送给空闲的子进程。(判断是否是空闲的子进程,可以在结构体中添加一些属性,然后派送任务的时候进行遍历,判断该进程是否空闲)
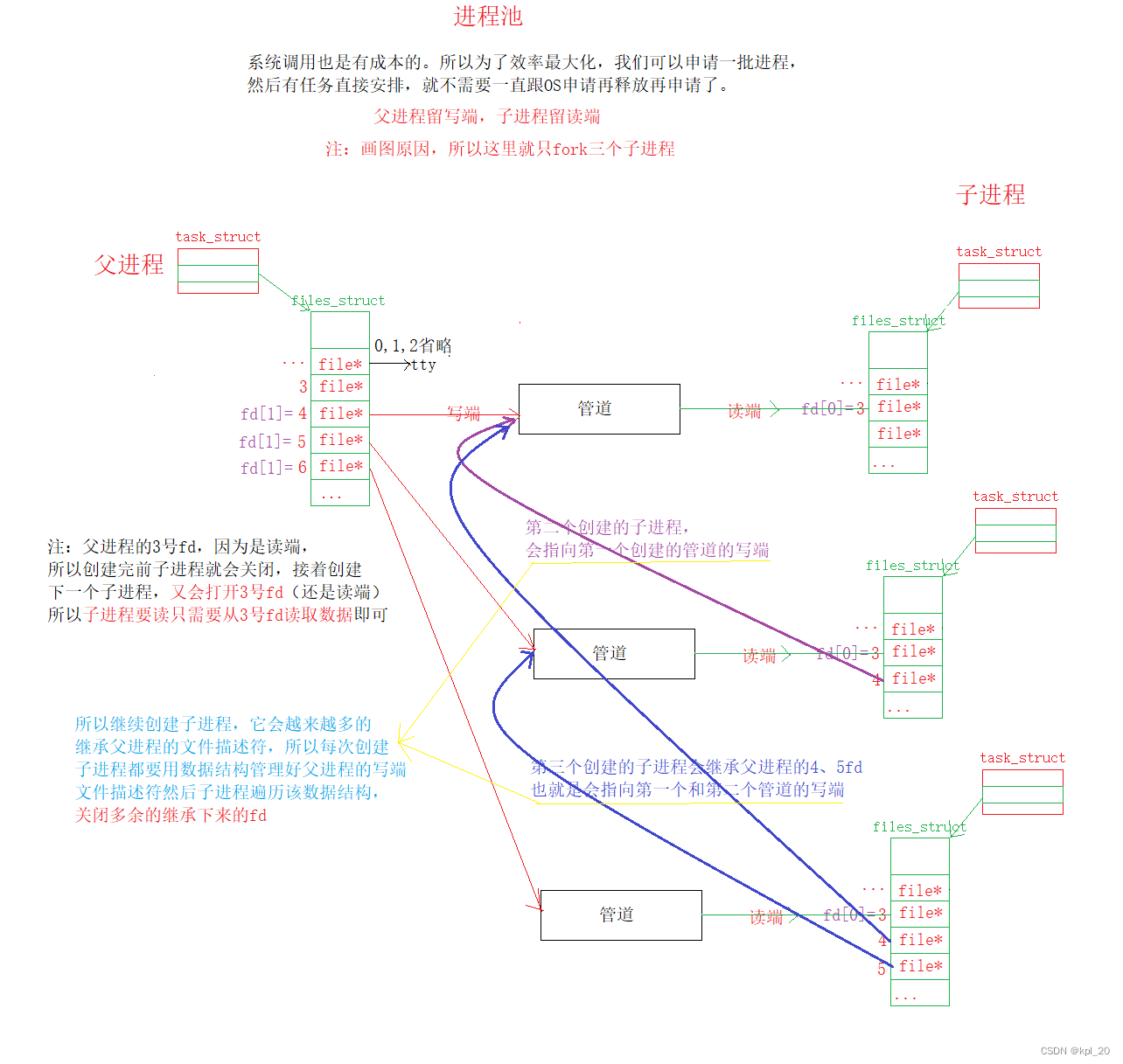
3. 命名管道
①理解命名管道
命名管道:命名管道是一种特殊的管道,可以在无关的进程之间进行通信。命名管道是一种有名字的通信方式,可以通过文件系统中的路径来访问。
②使用命名管道——mkfifo
- 命名管道可以直接使用命令创建
mkfifo [filename]- 也可以使用系统调用接口
mkfifo注:
- Linux下,创建一个命名管道(也称为FIFO)时,无论用户设置的权限是什么,最终创建出来的命名管道的权限都会被内核自动修改为0666(即所有用户都有读写权限)。
- 管道创建出来,属于内存级文件,内容不会进行落盘,所以管道不占用磁盘空间
拓展 —— 日志
日志简单介绍:
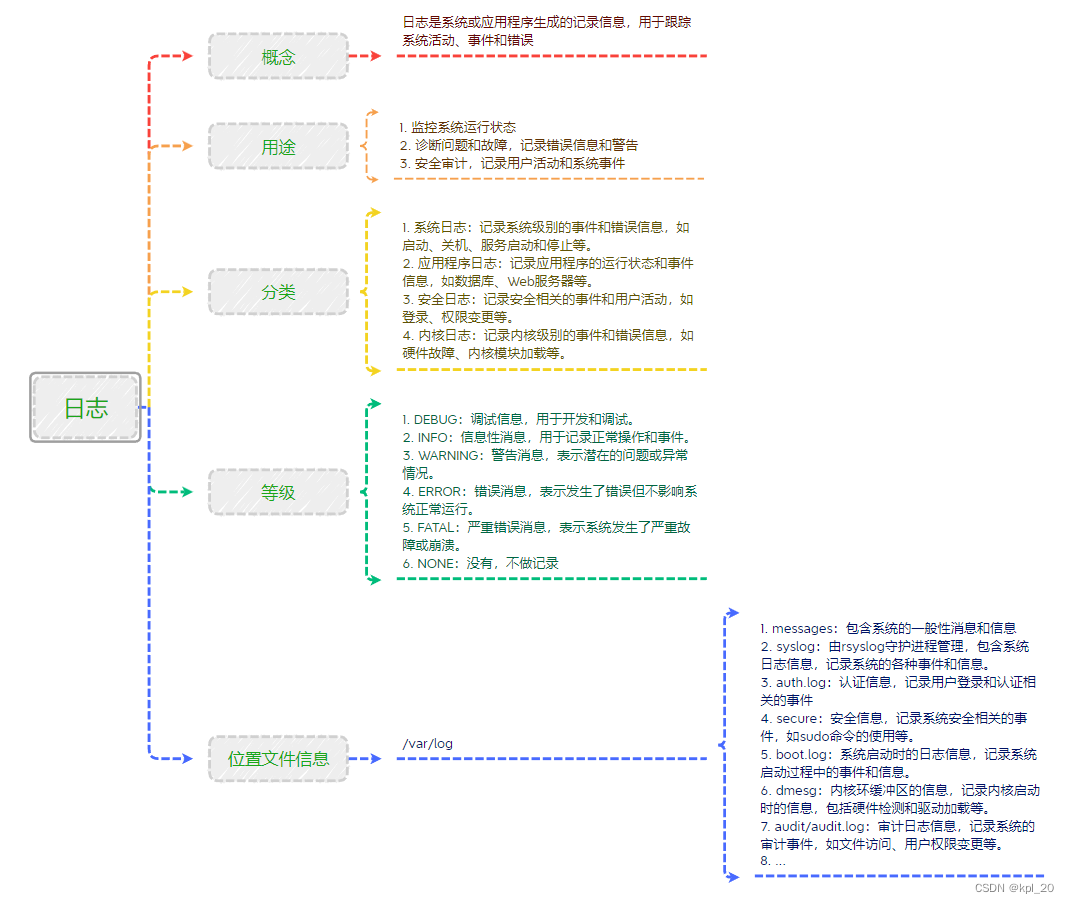
日志类实现的一些函数、宏和结构体介绍:
time、localtime、struct tm、snprintf、可变参数(va_list、va_start、va_end)、vsnprintf
注:可变参数,至少要有一个具体参数
//time —— 返回时间戳
头文件:
#include <time.h>
函数声明:
time_t time(time_t *t);
参数:
t:输出型参数,放的是当前的时间戳
函数返回值:
1. 成功返回时间戳
2. 失败返回-1,错误码被设置
注:使用时,参数设为nullptr即可
time使用:
#include <iostream>
#include <time.h>
int main()
{
time_t t1 = 0;
time_t t2 = time(&t1);
std::cout << "t1:" << t1 << " t2:" << t2 << std::endl;
return 0;
}
//output:
//t1:1710156476 t2:1710156476
//
//localtime 和 struct tm
头文件:
#include <time.h>
函数声明:
struct tm *localtime(const time_t *timep);
参数:
timep:指向要转换成本地时间的时间戳
返回值:
1. 成功返回结构体指针(struct tm),包含了转换后的本地之间信息。
2. 失败返回nullptr
struct tm定义:
struct tm
{
int tm_sec; // 秒,范围为 0-59
int tm_min; // 分,范围为 0-59
int tm_hour; // 时,范围为 0-23
int tm_mday; // 一个月中的日期,范围为 1-31
int tm_mon; // 月份,范围为 0-11
int tm_year; // 年份,从 1900 年开始
int tm_wday; // 一周中的天数,范围为 0-6 (0 表示周日)
int tm_yday; // 一年中的天数,范围为 0-365
int tm_isdst; // 夏令时标识符,负数表示不可确定,0 表示不使用夏令时,正数表示使用夏令时
};
localtime使用:
#include <iostream>
#include <time.h>
#include <cstdio>
int main()
{
time_t t = time(nullptr);
struct tm *ctime = localtime(&t);
printf("%d-%d-%d %d:%d:%d\n", ctime->tm_year + 1900, ctime->tm_mon + 1, ctime->tm_mday,
ctime->tm_hour, ctime->tm_min, ctime->tm_sec);
return 0;
}
//output:
// 2024-3-11 19:47:31
/
//snprintf
头文件:
#include <stdio.h>
函数声明:
int snprintf(char *str, size_t size, const char *format, ...);
参数:
1. 区别sprintf,snprintf限制输出的字符数
2. 将可变参数(...)按照format格式化成字符串,然后复制到str中
3. size:要写入的大小,超过size会被截断,最终写size-1大小,末尾添加'\0'
返回值:
1. 成功返回想要写入str的长度,而不是实际写入的长度
2. 失败返回负值
使用:
#include <cstdio>
int main()
{
char buffer[50];
const char* s = "runoobcom";
int j = snprintf(buffer, 6, "%s\n", s);
printf("string:%s\ncharacter count = %d\n", buffer, j);
return 0;
}
// string:
// runoo
// character count = 10
/
//可变参数va_list、va_start(ap, last_arg)、va_end(ap)、va_arg(ap,type)
头文件:
#include <stdarg.h>
四个宏:
1. va_list:实际就是char*类型
2. va_start:初始化可变参数列表,ap是va_list类型的变量,last_arg是最后一个固定参数的名称(可变参数裂变前一个参数)。目的是为了将ap指向可变参数列表中第一个参数
3. va_end:结束可变参数裂变访问,ap置为nullptr
4. va_arg:获取可变参数列表中下一个参数,ap是一个va_list类型的变量,type是下一个参数的类型。返回值是type类型的值,并将ap指向下一个参数
可变参数使用:
int sum(int n, ...)
{
va_list s; // va_list <==> char*
va_start(s, n);
int sum = 0;
while (n--)
{
sum += va_arg(s, int);
}
va_end(s); // s=NULL
return sum;
}
int main()
{
int c = sum(4, 1, 2, 3, 4);
int d = sum(5, 1, 2, 3, 4, 5);
cout << "c = " << c << ", d = " << d <<endl;
return 0;
}
//output: c = 10, d = 15
/
//vsnprintf
头文件:
#include <stdio.h>
函数声明:
int vsnprintf(char *str, size_t size, const char *format, va_list ap);
参数:
1. str:用于存储格式化后的字符串
2. size:字符数组大小
3. format:类似printf函数中的格式化字符串
4. ap:va_list类型的参数列表,包含要格式化的数据
返回值:
1. 成功返回想要写入str的长度,而不是实际写入的长度
2. 失败返回负值
vsnprintf使用:
#include <cstdio>
#include <stdarg.h>
void my_vsnprintf(const char *format, ...) {
va_list args;
va_start(args, format);
char buffer[100];
int n = vsnprintf(buffer, sizeof(buffer), format, args);
va_end(args);
printf("string:%s return val:%d\n", buffer, n);
}
int main()
{
my_vsnprintf("Hello, %s Size: %d", "world", 42);
return 0;
}
//output:
// string:Hello, world Size: 42 return val:21
实现一个简单的日志类:
文件名:log.hpp
#pragma once
#include <iostream>
#include <string>
#include <cstdio>
#include <cstring>
#include <cerrno>
#include <cstdarg>
#include <time.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
// 定义日志等级
#define Info 0
#define Debug 1
#define Waring 2
#define Error 3
#define Fatal 4
// 输出方式
#define Screen 1
#define OneFile 2
#define SortFile 3
#define LOG_MODE 0666
#define SIZE 1024
// 输出到一个文件的文件名 输出到多个文件时,可以加日志等级作为后缀,进行区分
#define LogFile "log.txt"
class Log
{
public:
Log(int printMethod = Screen, std::string path = "./log/")
: _printMethod(printMethod), _path(path)
{}
// 改变输出方式,使用者设置
void Enable(int method)
{
_printMethod = method;
}
// 根据等级转字符串
std::string LevelToString(int level)
{
switch (level)
{
case Info:
return "Info";
case Debug:
return "Debug";
case Waring:
return "Waring";
case Error:
return "Error";
case Fatal:
return "Fatal";
default:
return "None";
}
}
void PrintLog(int level, const std::string &logtxt)
{
switch (_printMethod)
{
case Screen:
std::cout << logtxt << std::endl;
break;
case OneFile:
PrintOneFile(LogFile, logtxt);
break;
case SortFile:
PrintSortFile(level, logtxt);
break;
default:
break;
}
}
// 写在一个文件中
void PrintOneFile(const std::string &logname, const std::string &logtxt)
{
std::string _logname = _path + logname;
int fd = open(_logname.c_str(), O_WRONLY | O_CREAT | O_APPEND, LOG_MODE);
if (fd < 0)
return;
write(fd, logtxt.c_str(), logtxt.size());
close(fd);
}
//根据日志等级不同,写在多个文件中
void PrintSortFile(int level, const std::string &logtxt)
{
std::string filename = LogFile;
filename += '.';
filename += LevelToString(level);
PrintOneFile(filename, logtxt);
}
// 可变参数
void operator()(int level, const char *format, ...)
{
// 获取时间
time_t t = time(nullptr);
struct tm *ctime = localtime(&t);
char leftbuffer[SIZE];
snprintf(leftbuffer, sizeof(leftbuffer), "[%s][%d-%d-%d %d:%d:%d]", LevelToString(level).c_str(),
ctime->tm_year + 1900, ctime->tm_mon + 1, ctime->tm_mday,
ctime->tm_hour, ctime->tm_min, ctime->tm_sec);
va_list s;
va_start(s, format);
char rightbuffer[SIZE];
vsnprintf(rightbuffer, sizeof(rightbuffer), format, s);
va_end(s);
char logtxt[SIZE * 2];
snprintf(logtxt, sizeof(logtxt), "%s %s\n", leftbuffer, rightbuffer);
// std::cout << logtxt << std::endl;
PrintLog(level, logtxt);
}
~Log()
{}
private:
int _printMethod;
std::string _path;
};
俩无关进程通信
mkfifo接口介绍:
头文件:
#include <sys/types.h>
#include <sys/stat.h>
函数声明:
int mkfifo(const char *pathname, mode_t mode);
函数参数:
1. pathname:要创建的所在路径+管道名
2. mode:所创建管道的权限
返回值:
1. 成功返回0
2. 失败返回-1,错误码被设置
使用: 实现两个无关的进程间的通信,使用命名管道,同时引用我们上面刚刚实现的日志类。
首先要先看到同一份资源:
comm.hpp
#pragma once
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <cstdio>
#include <cstdlib>
#include <string>
#include <iostream>
//创建的管道文件名 + 权限
#define FIFO_FILE "./myfifo"
#define MODE 0666
#define MAX_SIZE 1024
//程序退出码都封装在枚举中
enum exit
{
FIFO_CREAT_ERR = 1,
FIFO_DESTROY_ERR,
FIFO_OPEN_ERR,
FIFO_READ_ERR,
FIFO_WRITE_ERR
};
//把创建管道和销毁管道,封装成一个类
class InitPipe
{
public:
//创建管道
InitPipe()
{
int n = mkfifo(FIFO_FILE, MODE);
if (n == -1)
{
perror("mkfifo");
exit(FIFO_CREAT_ERR);
}
}
// 销毁管道
~InitPipe()
{
int m = unlink(FIFO_FILE);
if (m == -1)
{
perror("unlink");
exit(FIFO_DESTROY_ERR);
}
}
};
服务端:server.cc
#include "comm.hpp"
#include "log.hpp"
int main()
{
// 借用命名管道类,实现创建和销毁管道
InitPipe Init;
//使用日志类定义对象,并选择输出方式
Log log;
log.Enable(OneFile);
log(Info, "already creat pipe success!");
// 打开管道 以读的方式
int fd = open(FIFO_FILE, O_RDONLY);
if (fd == -1)
{
perror("open");
log(Fatal, "error string:%s, errno code:%d", strerror(errno), errno);
exit(FIFO_OPEN_ERR);
}
//这里主要是为了测试日志类,下面这四条语句
log(Info, "server already open fifo_file, error string:%s, errno code:%d", strerror(errno), errno);
log(Waring, "server already open fifo_file, error string:%s, errno code:%d", strerror(errno), errno);
log(Fatal, "server already open fifo_file, error string:%s, errno code:%d", strerror(errno), errno);
log(Debug, "server already open fifo_file, error string:%s, errno code:%d", strerror(errno), errno);
// 开始通信
while (true)
{
char buffer[MAX_SIZE] = {0};
int x = read(fd, buffer, sizeof(buffer));
if (x > 0)
{
buffer[x] = 0;
std::cout << "client say:" << buffer << std::endl;
}
else if (x == 0)
{
log(Debug, "client quit, server too!error string:%s, errno code:%d", strerror(errno), errno);
break;
}
else
{
perror("read");
exit(FIFO_READ_ERR);
}
}
close(fd);
return 0;
}
客户端:client.cc
#include "comm.hpp"
#include "log.hpp"
int main()
{
// 服务端创建好管道,客户端打开即可
// 打开管道
int fd = open(FIFO_FILE, O_WRONLY);
if (fd == -1)
{
perror("open");
exit(FIFO_OPEN_ERR);
}
log(Info, "client already open fifo_file!");
std::string line;
// 通信
while (true)
{
std::cout << "Please Enter@ ";
getline(std::cin, line);
int w = write(fd, line.c_str(), line.size());
if(w < 0)
{
perror("write");
exit(FIFO_WRITE_ERR);
}
}
close(fd);
return 0;
}
3. 小结
①管道总结
- 管道的四种状态:
- 读写端正常,管道为空,读端阻塞
- 读写端正常,管道被写满,写端阻塞
- 读端正常,写端关闭,读端就会读到0,表示读到文件结尾,不会被阻塞
- 写端正常,读端关闭,OS就会杀掉正在写入的进程,使用13号信号杀掉
- 管道的特征:
- 进程间会进行协同:内核会对管道操作进行同步和互斥——保护管道文件的数据安全
- 管道是面向字节流的
- 匿名管道和命名管道的区别:
- 匿名管道由pipe接口创建,并打开,后续要关闭相应的文件描述符。命名管道由mkfifo接口创建,打开要使用open,要决定用读还是写的方式打开
- 匿名管道只有具有亲缘关系的进程才能进行通信。命名管道,无关的进程间也可以通信
- 管道只能单向通信
- 管道是基于文件的,文件的声明周期是随进程的,所以管道的生命周期随进程。(匿名管道的声明周期随进程,命名管道的声明周期要显示的删除)
- 原子性:
- 当要写入的数据量小于PIPE_BUF时,Linux保证写入的原子性
- 当要写入的数据量大于PIPE_BUF时,Linux不再保证写入的原子性
注:
PIPE_BUF——大概意思就是向管道写入的内容小于PIPE_BUF就是原子的,PIPE_BUF的大小是4KB。
原子性: 是一个操作要么完全执行成功,要么完全不执行 
②拓展命令和接口
-
ulimit -aOS对一些重要资源的限制
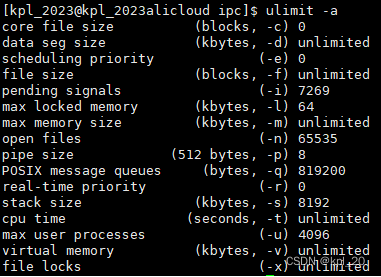
-
写代码时最好有一套规范,参数传参规范:
- 输入型参数: const &
- 输出型参数: *
- 输入输出型参数:& -
unlink删除文件,不论是管道文件还是普通文件,软链接和硬链接等都可以删除。
-
gettimeofday也可以获取时间
二、System V
1. 共享内存
共享内存是最快的IPC形式,允许多个进程共享同一块内存区域。进程可以直接读写共享内存中的数据,不再涉及到内核(不需要执行内核的系统调用来传递彼此的数据),也无需进行数据拷贝。
①原理
共享内存看到同一份资源的原理
图解:
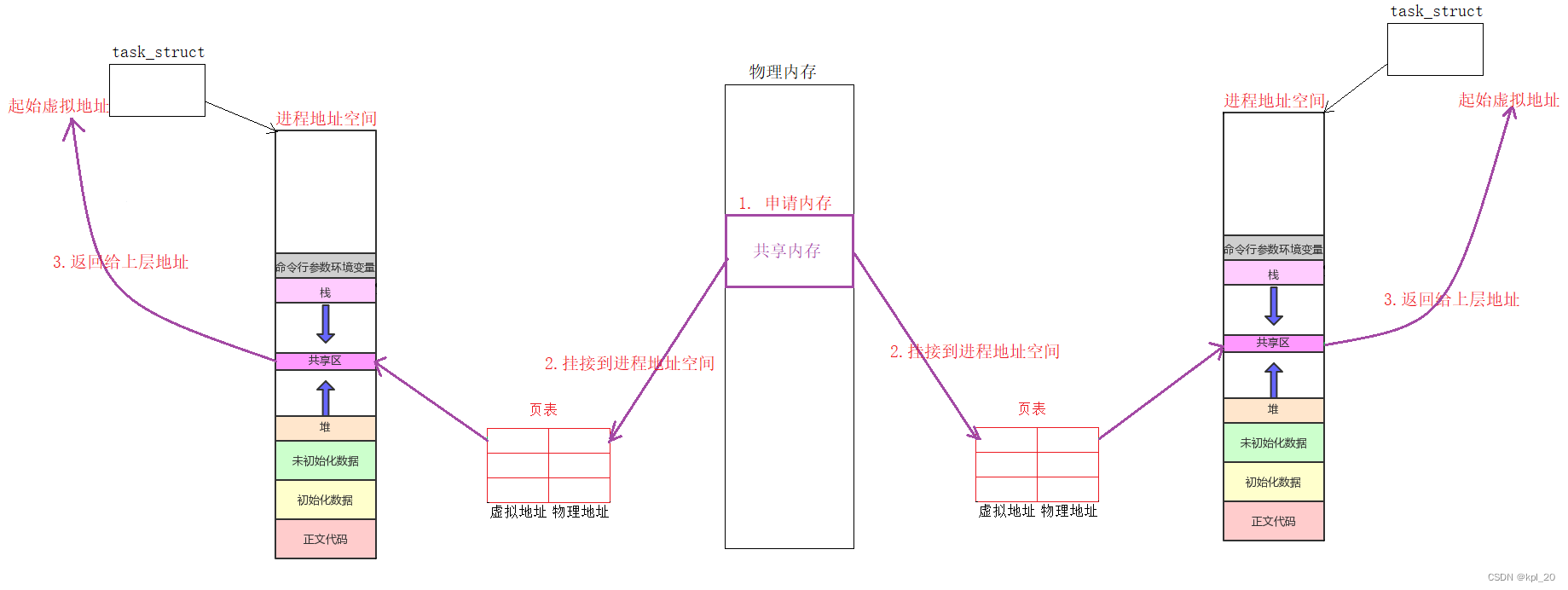
- 上图的内容可以理解为创建共享内存,让进程拿到这块内存。用完还是要和进程地址空间去关联,然后释放共享内存。这些操作只能由OS来做 —— 系统调用
- OS中肯定不止一份共享内存,所以OS就要对共享内存进行管理——先描述,再组织(后面对System V总结时,介绍其内核结构体)
- 共享内存映射到进程地址空间的共享区,并且会把映射的起始虚拟位置返回给上层用户
- 因为这块内存空间是映射到不同进程的进程地址空间内,可以直接使用(都以为是自己的),通信时不需要更多的拷贝。
- 共享内存的生命周期是随内核的,需要手动关闭,如果忘记也是内存泄漏
②使用共享内存
接口介绍
1. shmget和ftok: 共享内存的创建
/ftok///
头文件:
#include <sys/types.h>
#include <sys/ipc.h>
函数声明:
key_t ftok(const char *pathname, int proj_id);
参数:
1. pathname:指向路径(现有,可访问的路径)的字符串
2. proj_id:自定义整数
返回值:
1. 成功,返回key_t类型的唯一键值
2. 失败,返回-1,错误码被设置
/shmget///
头文件:
#include <sys/ipc.h>
#include <sys/shm.h>
函数声明:
int shmget(key_t key, size_t size, int shmflg);
参数:
1. key:共享内存的内核标识符,通常使用ftok生成。(保证了让不同进程获得同一个共享内存)
2. size:开辟共享内存的大小(单位字节)
3. shmflg:创建方式
IPC_CREAT(单独使用):没有就创建,有就返回
IPC_CREAT | IPC_EXIT:有就出错返回,没有就创建。(保证是新创建的共享内存)
IPC_EXIT:不单独使用
在最后可以直接给共享内存|一个权限
返回值:
1. 成功,返回共享内存的标识符
2. 失败,返回-1,错误码被设置
上述两个接口的介绍:
- ftok:
- ftok函数本质就是一套算法,将pathname转换成一个唯一的整数值,然后和proj_id再组合,生成唯一键值,用于创建、获取IPC对象的标识符。
- key能让不同进程进行唯一性标识,第一个进程通过key(这个唯一键值)创建共享内存,第二个之后的进程,只要拿着同一个key就可以和第一个进程看到同一个共享内存
- key类似路径(具有唯一性)
注:生成的值可能存在冲突的风险。- shmget:
- 通过ftok接口获取的key,创建一个新的共享内存或者获取一个已存在的共享内存的shmid
- shmid就是shmget的返回值,其是为了用户接下来控制共享内存。
上述两个函数的返回值对比:shmid和key

测试shmget和ftok接口:
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#include <iostream>
#include <string>
#include <cerrno>
#include <cstdio>
// 为了获取key值设置的两个参数 -> ftok
const std::string pathname = "/home/kpl_2023";
const int proj_id = 0x32231;
// 开辟共享内存的大小
// 共享内存的大小建议4096的整数倍
#define SIZE 4096
// 创建共享内存的权限.实际权限可能在OS内核中被限制和管理
#define SHM_MODE 0666
int main()
{
// 获取key,用来创建共享内存
key_t key = ftok(pathname.c_str(), proj_id); // key_t 实际就是 int
if (key < 0)
{
perror("ftok");
exit(errno);
}
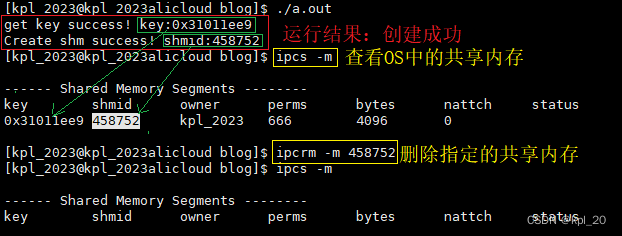
printf("get key success! key:0x%x\n", key);
// 创建共享内存
int shmid = shmget(key, SIZE, IPC_CREAT | IPC_EXCL | SHM_MODE); //权限直接在最后的位置 |上即可
if (shmid < 0)
{
perror("shmget");
exit(errno);
}
printf("Create shm success! shmid:%d\n", shmid);
return 0;
}
注:
- 查看系统中共享内存的命令
ipcs -m - 删除系统中共享内存的命令
ipcrm -m [shmid]
测试结果:
2. shmat和shmdt: 共享内存操作
/shmat///
头文件:
#include <sys/types.h>
#include <sys/shm.h>
函数声明:
void *shmat(int shmid, const void *shmaddr, int shmflg);
参数:
1. shmid:共享内存标识(shmget成功的返回值)
2. shmaddr:指定连接的地址(一般设置成nullptr,由OS自己分配。如果设置了,并且该被挂接的地址空间位置又被占用,返回-1)
3. shmflg:进程映射共享内存的方式,一般设置成0。两个可能取值:
SHM_RND:这可以提高内存访问的效率。
SHM_RDONLY:进程只能读取共享内存中的数据,而不能修改数据。
shmaddr不为nullptr且shmflg设置SHM_RND标记,则连接地址会自动向下调整SHMLBA的整数倍。
返回值:
1. 成功,返回共享内存映射到进程地址空间的地址
2. 失败,返回-1,错误码被设置
/shmdt///
头文件:
#include <sys/types.h>
#include <sys/shm.h>
函数声明:
int shmdt(const void *shmaddr);
参数:
shmaddr:共享内存映射到进程地址空间的地址
返回值:
1. 成功返回0
2. 失败返回-1,错误码被设置
上述两个接口的作用
- shmat:将共享内存段连接到进程地址空间
- shadt:将共享内存段与当前进程脱离
3. shmctl: 共享内存控制
头文件:
#include <sys/ipc.h>
#include <sys/shm.h>
函数声明:
int shmctl(int shmid, int cmd, struct shmid_ds *buf);
参数:
1. shmid:共享内存标识(shmget成功的返回值)
2. cmd:要控制的动作:IPC_STAT、IPC_SET、IPC_RMID
IPC_STAT:获取共享内存的状态信息,放在buf中
IPC_SET:在进程有足够的权限下,把共享内存当前的管理值设置为shmid_ds数据结构中给出的值
IPC_RMID:删除共享内存段
3. buf:根据选项不同可以是输入型参数也可以是输出型参数,指向一个保存着共享内存的模式状态和访问权限的数据结构
返回值:
1. 成功,返回0
2. 失败返回-1,错误码被设置
可以删除共享内存、获取共享内存的信息
使用
两个进程间的通信,使用共享内存
首先创建同一份资源:
comm.hpp
#ifndef __COMM_HPP__
#define __COMM_HPP__
#include <iostream>
#include <string>
#include <cstdio>
#include <cstdlib>
#include <cstring>
#include <cerrno>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#include <unistd.h>
// 为了获取key值
const std::string pathname = "/home/kpl_2023";
const int proj_id = 0x32231;
// 开辟共享内存的大小
// 共享内存的大小简易4096的整数倍
#define SIZE 4096
// 创建共享内存的权限
#define SHM_MODE 0666
enum exit
{
SHM_FTOK_ERR = 1,
SHM_SHMGET_ERR,
SHM_SHMAT_ERR,
SHM_SHMDT_ERR,
SHM_SHMCTL_IPC_RMID_ERR,
FIFO_CREATE_ERR = 10,
FIFO_DELETE_ERR,
FIFO_OPEN_ERR
};
// 获取key
key_t GetKey()
{
key_t key = ftok(pathname.c_str(), proj_id); // key_t 实际就是 int
if (key < 0)
{
perror("ftok");
exit(SHM_FTOK_ERR);
}
return key;
}
// 获取shmid
int GetShareMemHelper(int flag)
{
key_t key = GetKey();
int shmid = shmget(key, SIZE, flag);
if (shmid < 0)
{
perror("shmget");
exit(SHM_SHMGET_ERR);
}
return shmid;
}
// 给服务端的接口
int CreatShm()
{
return GetShareMemHelper(IPC_CREAT | IPC_EXCL | SHM_MODE);
}
// 给客户端的接口
int GetShm()
{
return GetShareMemHelper(IPC_CREAT);
}
#endif
进程1:
share_mema.cc
#include "comm.hpp"
int main()
{
//创建共享内存
int shmid = CreatShm();
// shm挂接到进程地址空间 -> 返回的时挂接在进程地址空间处的地址
char *shmaddr = (char *)shmat(shmid, nullptr, 0);
if (*shmaddr < 0)
{
perror("shamt");
exit(SHM_SHMAT_ERR);
}
// OS提供的结构体
struct shmid_ds shmds;
// 通信
while (true)
{
std::cout << "client say@ " << shmaddr << std::endl; // 直接访问地址即可
sleep(1);
shmctl(shmid, IPC_STAT, &shmds);
std::cout << "shm size: " << shmds.shm_segsz << std::endl;
std::cout << "shm nattch: " << shmds.shm_nattch << std::endl;
printf("shm key: 0x%x\n", shmds.shm_perm.__key);
}
// 去挂接
int shmdtid = shmdt(shmaddr);
if (shmdtid < 0)
{
perror("shmdt");
exit(SHM_SHMDT_ERR);
}
// 删除共享内存
int rmid = shmctl(shmid, IPC_RMID, nullptr);
if (rmid < 0)
{
perror("shmctl::IPC_RMID");
exit(SHM_SHMCTL_IPC_RMID_ERR);
}
return 0;
}
进程2:
share_memb.cc
#include "comm.hpp"
// 客户端不能先运行,因为我们没有让它创建共享内存,所以没有设置权限,
// 所以shmat挂接不上会出现段错误
int main()
{
//获取共享内存shmid
int shmid = GetShm();
char *shmaddr = (char *)shmat(shmid, nullptr, 0);
if (*shmaddr < 0)
{
perror("shamt");
exit(SHM_SHMAT_ERR);
}
std::cout << "shmat success !!!" << std::endl;
// 通信
while (true)
{
std::cout << "Please Enter@ ";
fgets(shmaddr, SIZE, stdin);
}
// 去挂接
int shmdtid = shmdt(shmaddr);
if (shmdtid < 0)
{
perror("shmdt");
exit(SHM_SHMDT_ERR);
}
return 0;
}
③小结
- 共享内存没有同步互斥之类的保护机制
- 共享内存是所有进程间通信中,速度最快的,拷贝少
- 共享内存内部的数据,由用户自己维护
2. 消息队列
- 消息队列是一种消息传递机制。消息队列可以实现进程之间的异步通信。
- 允许不同的进程,向内核中发送带类型的数据块,接收者进程接收的数据块可以有不同类型。
- 看到同一份资源:不同进程看到同一个队列(内核中)
- 消息的生命周期是随内核的,需要手动删除,如果忘记也是内存泄漏
原理:
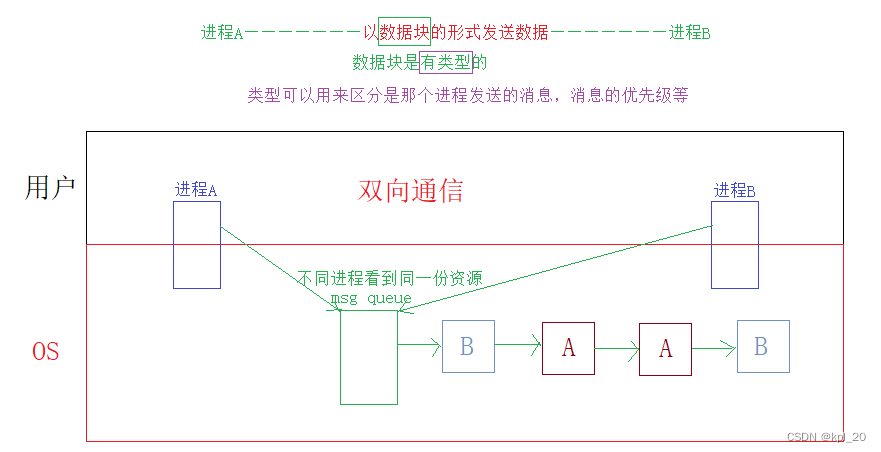
内核中,OS管理着消息队列,进程(用户)想要使用这块资源,OS一定会提供系统调用给用户。
3. 信号量
信号量是一种用于进程同步和互斥的机制,可以用来解决进程之间的竞争条件和临界区问题。
信号量的生命周期是随内核的,需要手动删除,如果忘记也是内存泄漏
信号量是进程间通信的原因:
- 通信不仅仅是数据的交互,互相协同也是
- 信号量可以被所有通信进程看到
①引入
- 数据不一致问题: A、B进程看到同一份资源(共享资源),如果不加保护,会导致数据不一致问题。eg:共享内存
- 互斥: 任何时刻只允许一个执行流访问共享资源。加锁——互斥访问
- 临界资源: 共享资源,任何时刻只允许一个执行流访问——一般是内存空间
- 临界区: 访问临界资源的代码
②原理
1. 理解信号量
信号量的本质就是一把计数器(描述临界资源中资源数量的多少)
信号量解释:
- 所以申请计数器成功,那就代表还有资源,具有访问资源的权限
- 申请计数器资源,并不表示我(执行流)访问要的资源了,而是对资源的预定机制
- 计数器可以有效保证进入这一份资源(共享资源)的执行流数量
所以每个执行流,想要访问共享资源的一部分时,不能直接访问,而是要先申请计数器资源,而这个计数器就是信号量
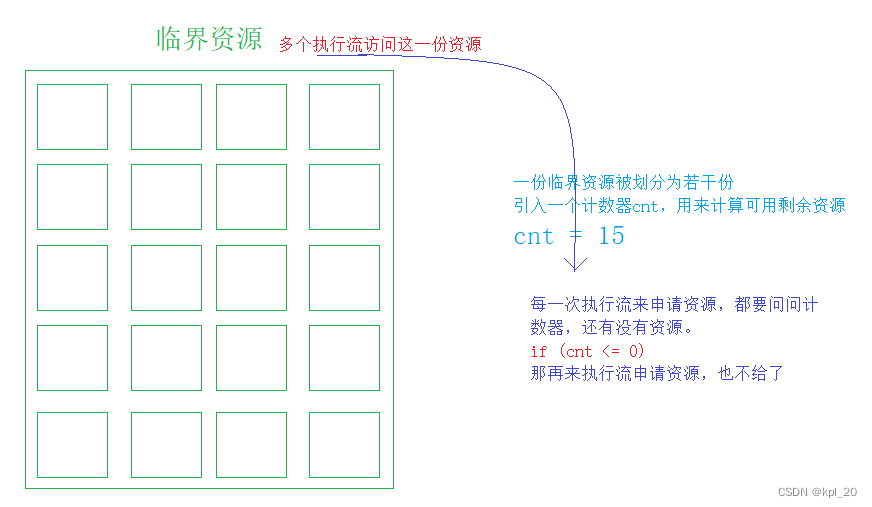
2. 二元信号量(锁)
当我们把上面那个临界资源当成一个整体,那么计数器cnt就是1。这就只能一个执行流访问,当再来执行流时计数器是0,就不能再有执行流访问了——互斥
所以,我们把值只能为1、0两态的计数器叫做二元信号量——本质就是一个锁
3. 共享资源——信号量:
- 要访问临界资源,就得先申请信号量(计数器)资源,它保护着临界资源。但是计数器也被很多执行流共享,所以也是共享资源,那也得被保护。
- 申请计数器本质就是对计数器减一,但是虽然在C语言上计数器减一是一条语句,但是转成汇编就是三条(也可能多条)汇编。进程在运行时随时被切换,所以这减一操作是不安全的
- 所以为了保护这个信号量资源,在底层做了工作
- P操作:申请信号量,本质是对计数器减一
- V操作:释放资源,释放信号量,本质是对计数器加一
结论: 信号量的PV操作都是原子的——要么不做,要么做完
4. 总结
1. 共享内存、消息队列和信号量的接口:
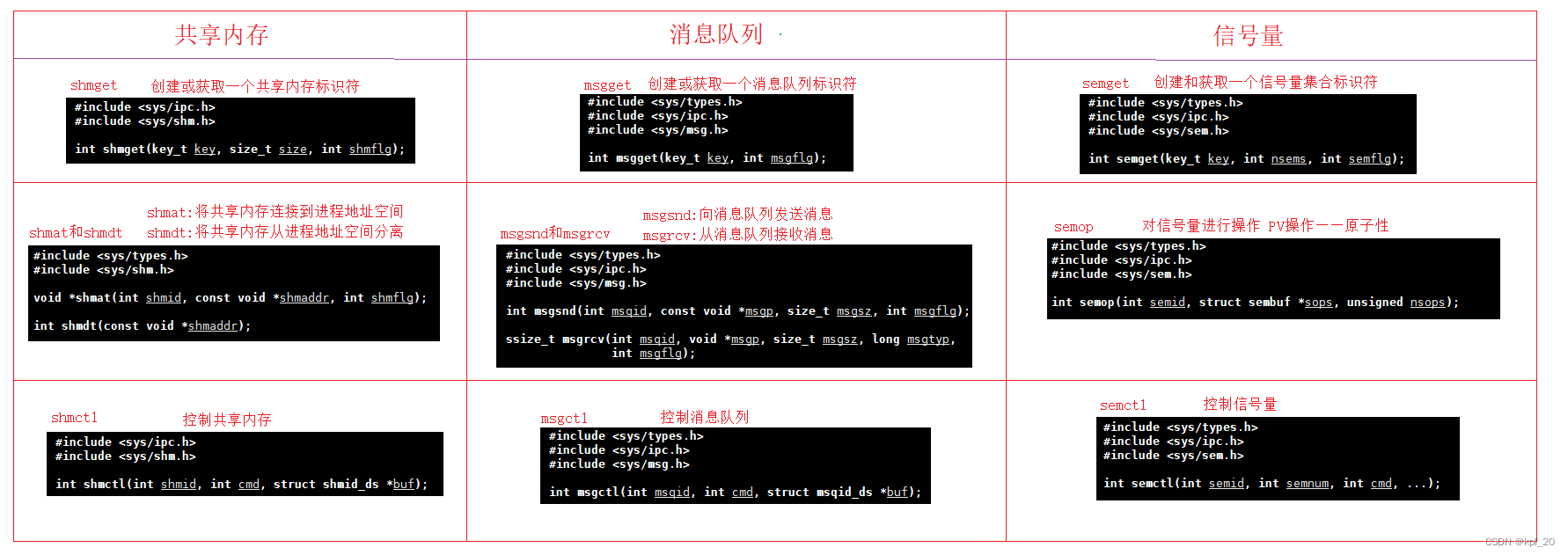
观察发现三者的接口相似,原因:System V标准规定
所以:
- 消息队列
- 查看系统中的消息队列的命令
ipcs -q- 删除系统中消息队列的命令
ipcrm -q [msgid]- 信号量
- 查看系统中信号量的命令
ipcs -s- 删除系统中信号量的命令
ipcs -s [semid]
- IPC在内核中的数据结构设计:
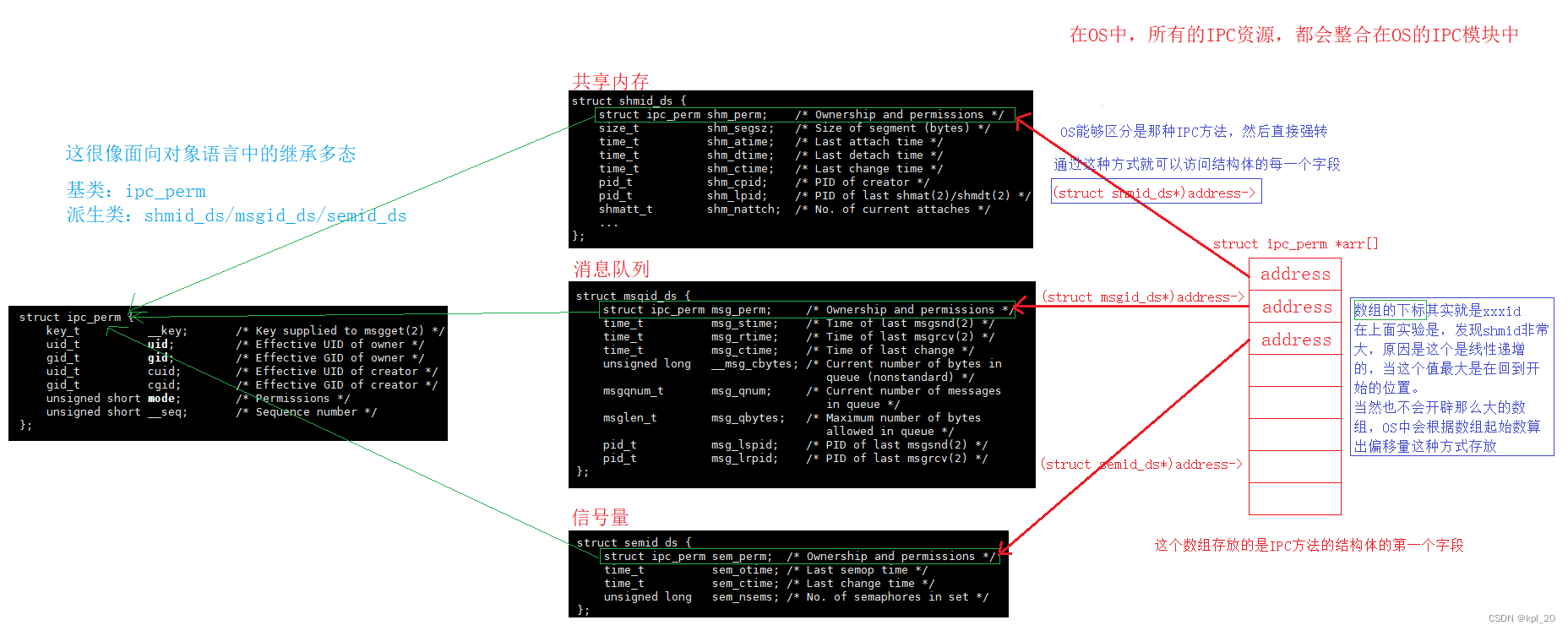















 1942
1942











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











