






随着工业自动化和信息化的快速发展,表计识别技术在能源管理、制造监控、智能家居等领域扮演着越来越重要的角色。表计,如电表、水表、燃气表等,是记录和计量能源消耗的关键设备。传统的表计数据读取方式通常依赖于人工抄表,这种方法不仅效率低下,而且容易出错,特别是在大规模部署的情况下。
为了提高数据读取的准确性和效率,自动化的表计识别技术应运而生。计算机视觉领域的深度学习技术,特别是卷积神经网络(CNN),已经在图像识别和分割任务中取得了显著的成果。U2Net,作为一种先进的深度学习模型,以其出色的性能在图像分割领域引起了广泛关注。
U2Net模型的核心优势在于其能够精确地分割出图像中的小目标,这在表计识别中尤为重要,因为表计的数字和指针往往尺寸较小,且可能受到环境光线、遮挡等因素的影响。通过U2Net,可以实现对表计图像的自动分割和识别,从而提高数据采集的自动化水平和准确性。
一、数据集准备
本篇准备了414张表计图片,以7:3的比例划分训练集和验证集,数据集的下载地址附在文章最后。

二、代码准备
本篇代码是从网上下载下来后经过改进完善而来的,主要添加了训练结果的绘图功能以及添加了深度可分离卷积以及注意力机制提高准确率。
主要添加的画图代码如下:
def save_metrics(self):
with open('training_metrics.txt', 'w') as f:
for epoch, (train_loss, train_tar_loss) in enumerate(self.epoch_train_losses):
train_accuracy = self.epoch_train_accuracies[epoch]
val_loss, val_tar_loss = self.epoch_val_losses[epoch]
val_accuracy = self.epoch_val_accuracies[epoch]
f.write(f'Epoch {epoch + 1}: Train Loss = {train_loss:.6f}, Train Tar Loss = {train_tar_loss:.6f}, Train Accuracy = {train_accuracy:.6f}\n')
f.write(f' Val Loss = {val_loss:.6f}, Val Tar Loss = {val_tar_loss:.6f}, Val Accuracy = {val_accuracy:.6f}\n')
def plot_metrics(self):
epochs = range(1, len(self.epoch_train_losses) + 1)
avg_train_losses = [loss for loss, _ in self.epoch_train_losses]
avg_train_tar_losses = [tar_loss for _, tar_loss in self.epoch_train_losses]
train_accuracies = self.epoch_train_accuracies
avg_val_losses = [loss for loss, _ in self.epoch_val_losses]
avg_val_tar_losses = [tar_loss for _, tar_loss in self.epoch_val_losses]
val_accuracies = self.epoch_val_accuracies
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.plot(epochs, avg_train_losses, label='Average Train Loss')
plt.plot(epochs, avg_train_tar_losses, label='Average Train Target Loss')
plt.plot(epochs, avg_val_losses, label='Average Val Loss')
plt.plot(epochs, avg_val_tar_losses, label='Average Val Target Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.title('Loss per Epoch')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(epochs, train_accuracies, label='Train Accuracy', color='green')
plt.plot(epochs, val_accuracies, label='Val Accuracy', color='red')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.title('Accuracy per Epoch')
plt.legend()
plt.tight_layout()
plt.savefig('training_metrics.png')
plt.show()
可深度分离卷积代码:
# 定义深度可分离卷积模块
class DepthwiseSeparableConv(nn.Module):
def __init__(self, in_channels, out_channels, dw_kernel_size, dw_padding, pw_kernel_size, pw_padding, dw_dilation=1, pw_dilation=1):
super(DepthwiseSeparableConv, self).__init__()
self.depthwise_conv = nn.Conv2d(
in_channels,
in_channels,
kernel_size=dw_kernel_size,
padding=dw_padding,
dilation=dw_dilation,
groups=in_channels
)
self.pointwise_conv = nn.Conv2d(
in_channels,
out_channels,
kernel_size=pw_kernel_size,
padding=pw_padding,
groups=1
)
def forward(self, x):
out = self.depthwise_conv(x)
out = self.pointwise_conv(out)
return out
# 接下来,修改RSU4类以使用深度可分离卷积
class REBNCONV(nn.Module):
def __init__(self, in_ch=3, out_ch=3, dirate=1):
super(REBNCONV, self).__init__()
self.conv_s1 = nn.Conv2d(in_ch, out_ch, 3, padding=1 * dirate, dilation=1 * dirate)
self.bn_s1 = nn.BatchNorm2d(out_ch)
self.relu_s1 = nn.ReLU(inplace=True)
def forward(self, x):
hx = x
xout = self.relu_s1(self.bn_s1(self.conv_s1(hx)))
return xout
CA注意力机制模块:
# CA注意力模块
class ChannelAttention(nn.Module):
def __init__(self, in_channels, reduction_ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(in_channels, in_channels // reduction_ratio, bias=False),
nn.ReLU(inplace=True),
nn.Linear(in_channels // reduction_ratio, in_channels, bias=False)
)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
b, c, _, _ = x.size()
avg_out = self.avg_pool(x).view(b, c)
avg_out = self.fc(avg_out)
out = self.sigmoid(avg_out).view(b, c, 1, 1)
return x * out.expand_as(x)
CBAM注意力机制:
class ChannelAttention(nn.Module):
def __init__(self, in_channels, reduction_ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc1 = nn.Sequential(
nn.Linear(in_channels, in_channels // reduction_ratio, bias=False),
nn.ReLU(inplace=True),
)
self.fc2 = nn.Linear(in_channels // reduction_ratio, in_channels, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
b, c, _, _ = x.size()
avg_out = self.fc2(self.fc1(self.avg_pool(x).view(b, c)))
max_out = self.fc2(self.fc1(self.max_pool(x).view(b, c)))
out = self.sigmoid(avg_out + max_out).view(b, c, 1, 1)
return x * out
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=kernel_size//2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x_cat = torch.cat([avg_out, max_out], dim=1)
x_att = self.conv1(x_cat)
out = self.sigmoid(x_att)
return x * out
class CBAM(nn.Module):
def __init__(self, in_channels, reduction_ratio=16, kernel_size=7):
super(CBAM, self).__init__()
self.channel_attention = ChannelAttention(in_channels, reduction_ratio)
self.spatial_attention = SpatialAttention(kernel_size)
def forward(self, x):
x = self.channel_attention(x)
x = self.spatial_attention(x)
return x三、训练
准备好数据集和代码后,运行train.py文件即可开始训练,需要注意的是,数据集和训练代码放在同一目录下。
本篇采用的是云服务器进行训练,训练过程如下图:
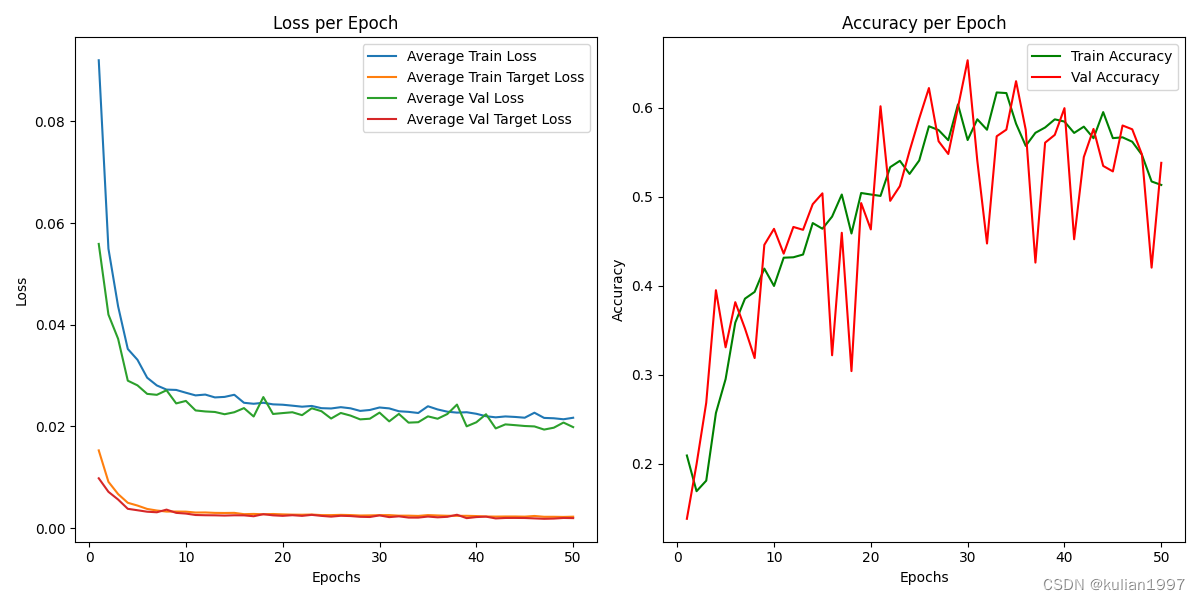
训练完成之后会生成 training_metrics.txt文件、training_metrics.png文件以及训练好的权重。training_metrics.txt中记录了每轮训练的loss和Accuracy,training_metrics.png如下图:
四、推理
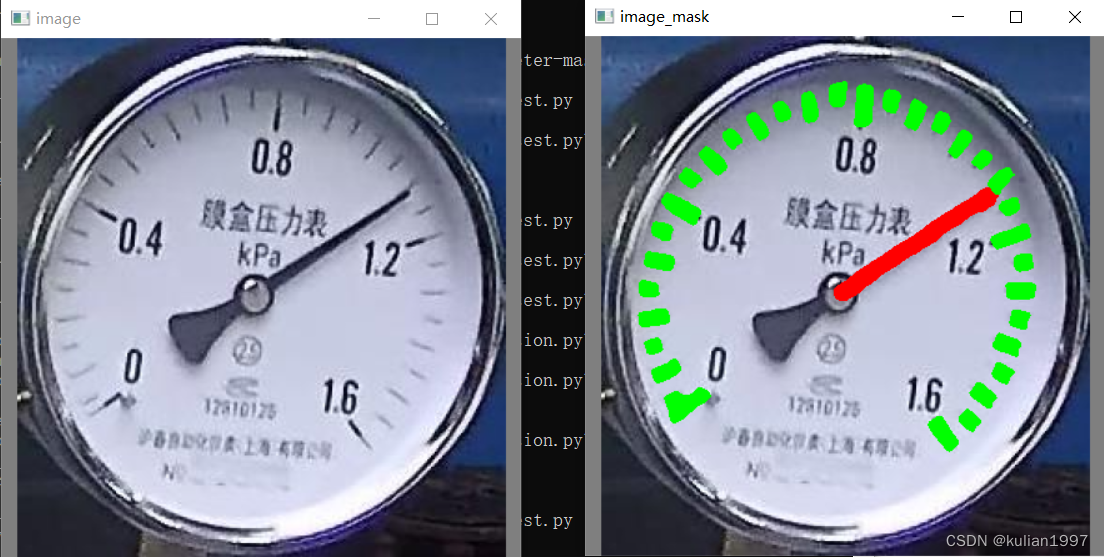
训练完成之后,运行test.py文件可进行推理,推理结果如下图:
















 169
169











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











