









【日常学习】U-net的改进
ResNet
ResNet建立的模块如下:
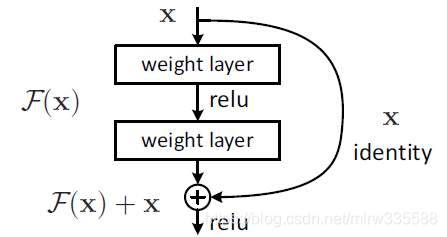
残差网络提出了一个捷径(shortcut)的概念,即跳过一个或多个层,将输入结果直接添加到底层,残差网络可以通过下面的公式1来表示
H
(
x
)
=
x
+
F
(
x
)
(
1
)
H (x) = x + F(x)~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~(1)
H(x)=x+F(x) (1)
其中
H
(
x
)
H(x)
H(x)为底层的映射,
x
x
x为输入结果,
F
(
x
)
F(x)
F(x)为网络中的隐藏层输出结果。
残差网络通过将多个卷积层级联的输出与输入相加的方式对图片进行特征提取,减少了训练参数。
在卷积神经网络中,网络层次越深,训练时产生的错误越多,训练时间越长。残差网络的出现在一定程度上解决了这个问题。
与其他网络相比,残差网络结构相对简单,训练参数较少,训练时间较短,解决了在极深度条件下深度卷积神经网络性能退化的问题。
U-net与ResNet结合
改进后的U-NET分为收缩网络以及扩张网络两部分。
收缩网络与U-NET中的收缩网络类似,有所不同的是,对于每一层输出的结果先进行规范化处理,随后通过激活函数进行激活。每一个下采样包含两个3x3的卷积层,一个1x1的“捷径”以及一个2x2的池化层。
扩张网络与 U-NET 中的扩张网络类似,每一次上采样包含两个 3x3的卷积层,一个 1x1 的“捷径”,在每一次上采样之前,需要合并收缩网络与之相对应的结果。与收缩网络相似,扩张网络中每一层输出结果都需要先进性规范化处理,随后通过激活函数进行激活。最后,加入 1x1 的卷积网络确定 该特征图所对应的结果。
改进后的 U-NET 网络结构如下图所示。

改进后的U-NET网络结构示意图,与U-NET网络相比,改进后的U-NET加入了残差网络,并且对于每一层输出结果进行规范化处理。红色的箭头表示“捷径”层,绿色的方块表示通过“捷径” 层后获取的结果,灰色方块代表上采样过程中对于边界信息的补充。
加入残差网络后的U-NET网络,层次更加深入,训练参数更多,在一定程度上弥补了 U-NET网络不够深的问题,同时由于残差网络的特性,解决了在极深度条件下深度卷积神经网络性能退化的问题。
捷径层(Shortcut)
我们将该网络结构用下面的公式表示
y
=
W
n
+
1
K
(
w
n
x
)
+
b
x
(
2
)
y = W_{n+1}K(w_nx) + bx ~~~~~~~~~~~~~~~~~~~~(2)
y=Wn+1K(wnx)+bx (2)
这里 y y y和 x x x表示该网络的输出以及输入, W n + 1 W_{n+1} Wn+1表示权值, K K K表示激活函数; b b b为一个可调节的参数,默认为 1。
一个“捷径”层中可以包含多个卷积层,我们可以将
W
n
+
1
K
(
w
n
x
)
W_{n+1}K(w_nx)
Wn+1K(wnx)通过
F
(
x
,
w
i
)
F(x,w_i)
F(x,wi)表示多个卷积层的情况,改进后的公式如(3)所示
y
=
F
(
x
,
w
i
)
+
b
x
(
3
)
y = F(x,w_i) + bx ~~~~~~~~~~~~~~~~(3)
y=F(x,wi)+bx (3)
引入“捷径”层使得U-NET的网络结构更加深入,同时也避免了训练时间过长,训练参数过多以及过拟合现象的发生。
损失函数(Loss)
损失函数(loss function)是用来评估预测值与参考值(ground truth)之间的不一致程度,损失函数越小,模型的鲁棒性越好。
我们将
L
(
X
,
Y
)
L(X, Y)
L(X,Y)作为该模型的损失函数,
L
(
X
,
Y
)
L(X, Y)
L(X,Y)如公式(4)所示

其中
X
X
X表示预测值,
Y
Y
Y表示参考值,
S
(
X
,
Y
)
S(X,Y)
S(X,Y)表示两个模型之间的相似程度,
S
(
X
,
Y
)
S(X, Y)
S(X,Y)表达式如(5)所示。

∣
X
∩
Y
∣
|X∩Y|
∣X∩Y∣表示两个样本间相交部分或重叠部分,
∣
X
∣
+
∣
Y
∣
|X|+|Y|
∣X∣+∣Y∣表示预测值和参考值的总量
优化函数
优化函数在训练模型的同时,帮助模型调整权值,使得模型权值调整到最优,使得损失函数最小。Adam具有计算高效,占用内存较少,善于处理非平稳模型等优势。

















 1048
1048

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









