







 本文详细介绍了文本分类的历史、流程、方法和挑战,从传统机器学习到深度学习,包括SVM、贝叶斯、词袋模型、TF-IDF、词向量以及深度学习中的RNN、CNN、注意力机制和Transformer模型。重点讨论了特征工程、预处理(如分词、去停用词)和表示学习(如词向量、BERT)。此外,还提到了文本分类面临的挑战,如数据稀缺、模型解释性和鲁棒性。
本文详细介绍了文本分类的历史、流程、方法和挑战,从传统机器学习到深度学习,包括SVM、贝叶斯、词袋模型、TF-IDF、词向量以及深度学习中的RNN、CNN、注意力机制和Transformer模型。重点讨论了特征工程、预处理(如分词、去停用词)和表示学习(如词向量、BERT)。此外,还提到了文本分类面临的挑战,如数据稀缺、模型解释性和鲁棒性。
最近在学习文本分类,读了很多博主的文章,要么已经严重过时(还在一个劲介绍SVM、贝叶斯),要么就是机器翻译的别人的英文论文,几乎看遍全文,竟然没有一篇能看的综述,花了一个月时间,参考了很多文献,特此写下此文。
文本分类简介
文本分类(Text Classification)又称为自动文本分类(Automatic Text Categorization)。是指计算机将载有信息的一篇文本映射到预先给定的某一类别或某几类别主题的过程。实现这一过程的算法模型叫做分类器,文本分类问题是自然语言领域的一个非常经典的问题。
根据预定义的类别不同,文本分类两种:二分类和多分类。多分类可以通过二分类来实现,从文本标注的类别上讲,**文本分类又可以分为单标签和多标签。**因为,很多文本同时可以关联到多个类别。
文本分类词云一览

文本分类历史
文本分类最初是通过专家规则来进行分类,利用知识工程建立专家系统,这样做的好处是比较直观地解决了问题,但费时费力,覆盖的范围和准确率都有限。
后来伴随着统计学习方法地发展,特别是90年代后期,互联网在线文本数量增长和机器学习学科的兴起,逐渐形成了一套解决大规模文本分类问题的经典做法,也即特征工程+浅层分类模型,又分为传统机器学习方法和深度学习文本分类方法。
文本分类的应用场景
文本分类主流应用场景有
- 情感分析
- 话题标记
- 新闻分类
- 问答系统
- 对话行为分类
- 自然语言推理
- 关系分类
- 事件预测
文本分类流程
这里讨论的文本分类流程指的是基于机器学习\深度学习的文本分类,专家系统已经基本上淘汰了,文本分类流程图如下所示:
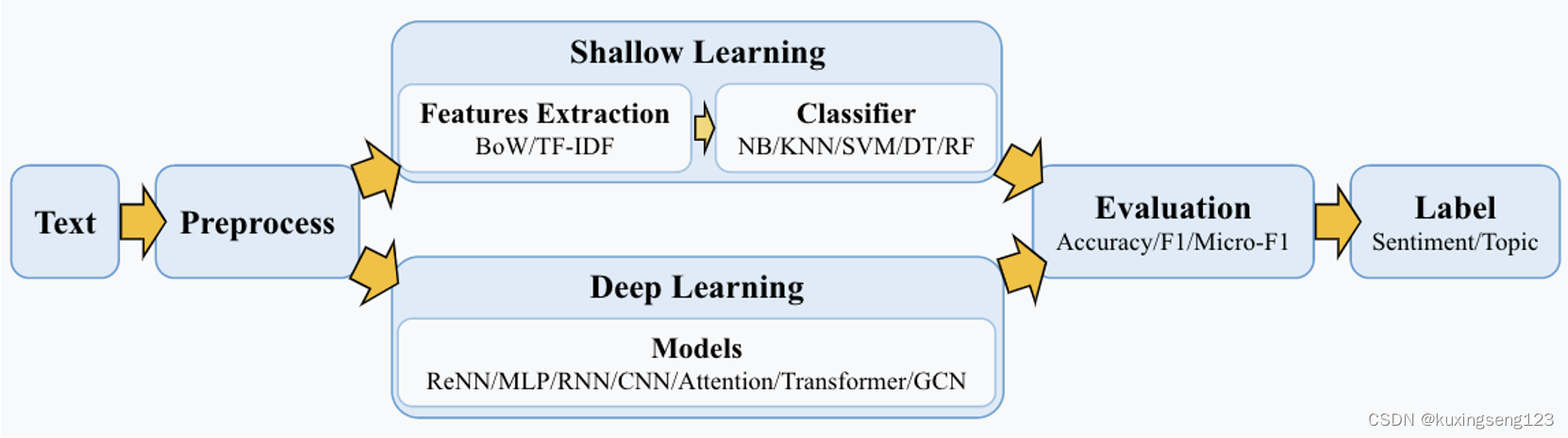
其中,先具体看浅层学习的具体过程,如下所示:
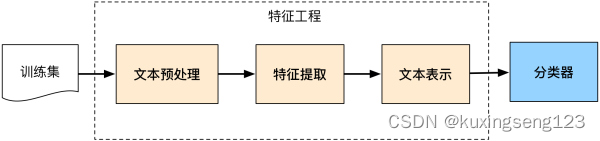
如果不考虑训练集,整个文本分类问题就拆分成了特征工程和分类器两部分。其实最后还应该有一个性能检验的步骤来评估模型。
获取训练数据集
数据采集是文本挖掘的基础,主要包括爬虫技术和页面处理两种方法。先通过网络爬虫获取到原始 web 网页数据,然后通过页面处理去除掉多余的页面噪声,将 Web 页面转化成为纯净统一的文本格式和元数据格式。
文本特征工程(针对浅层学习)
文本预处理
文本要转化成计算机可以处理的数据结构,就需要将文本切分成构成文本的语义单元。这些语义单元可以是句子、短语、词语或单个的字。
通常无论对于中文还是英文文本,统一将最小语义单元称为“词组”。
英文文本预处理
英文文本的处理相对简单,因为单词之间有空格或标点符号隔开。如果不考虑短语,仅以单词作为唯一的语义单元的话,只需要分割单词,去除标点符号、空格等。(单词作为唯一的语义单元)
英文还需要考虑的一个问题是大小写转换,一般认为大小写意义是相同的,这就要求将所有单词都转换成小写/大写。
英文文本预处理更为重要的问题是词根的还原,或称词干提取。词根还原的任务就是将属于同一个词干(Stem)的派生词进行归类转化为统一形式。
例如,把“computed”, “computer”, “computing”可以转化为其词干 “compute”。通过词干还原实现使用一个词来代替一类中其他派生词,可以进一步增加类别与文档中的词之间匹配度。词根还原可以针对所有词进行,也可以针对少部分词进行。
因为大家都是中国人,所以主要讨论的还是中文文本预处理方法。
中文文本预处理
和英文文本处理分类相比,中文文本预处理是更为重要和关键,相对于英文来说,中文的文本处理相对复杂。中文的字与字之间没有间隔,并且单个汉字具有的意义弱于词组。一般认为中文词语为最小的语义单元,词语可以由一个或多个汉字组成。所以中文文本处理的第一步就是分词。
中文文本处理中主要包括文本分词和去停用词两个阶段。
分词
研究表明中文文本特征粒度为词粒度远远好于字粒度,因为大部分分类算法不考虑词序信息,如果基于字粒度就会损失了过多的 n-gram 信息。
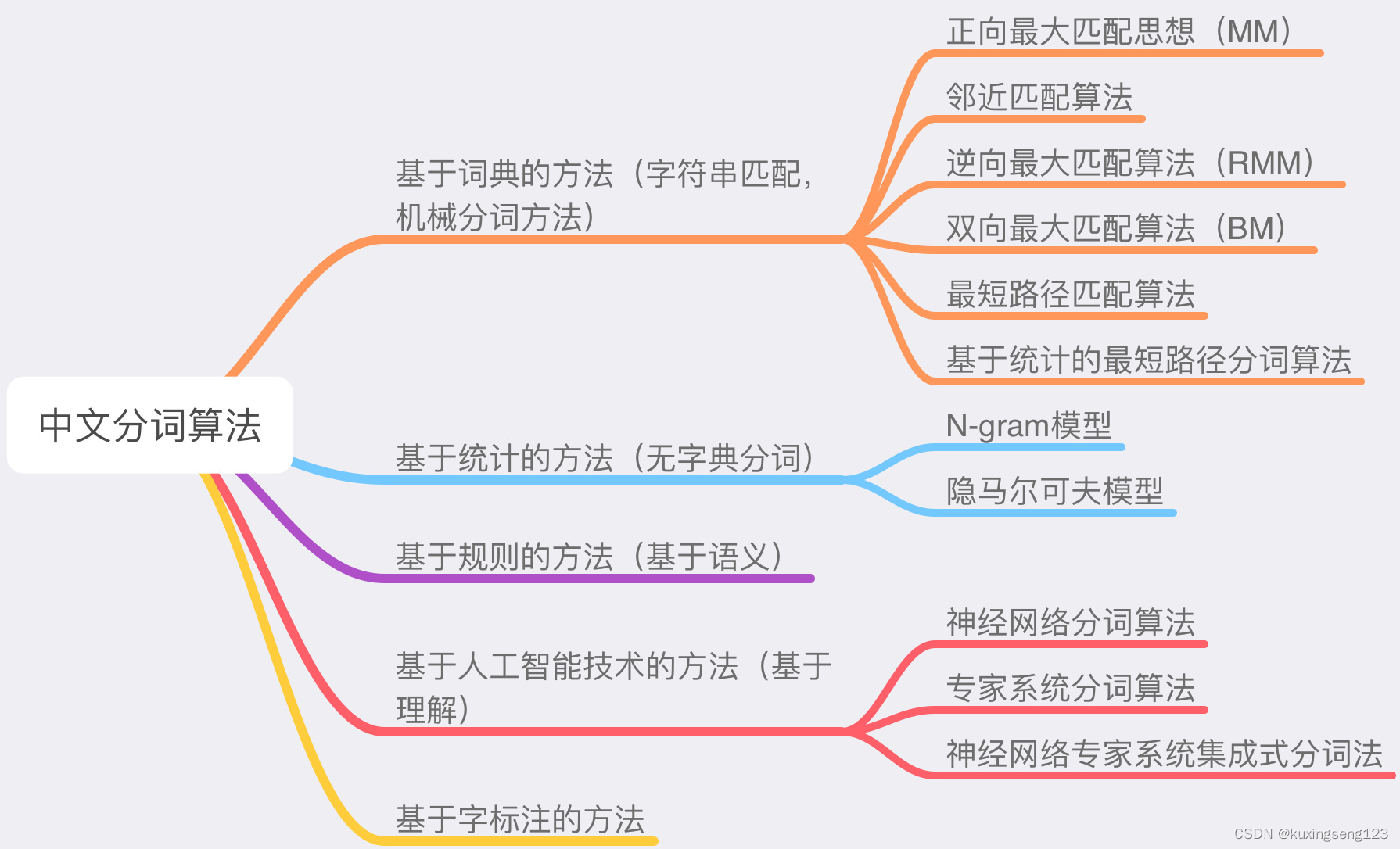
目前常用的中文分词算法可分为三大类:基于词典的分词方法、基于理解的分词方法和基于统计的分词方法。
- 基于词典的中文分词(字符串匹配)
核心是首先建立统一的词典表,当需要对一个句子进行分词时,首先将句子拆分成多个部分,将每一个部分与字典一一对应,如果该词语在词典中,分词成功,否则继续拆分匹配直到成功。字典,切分规则和匹配顺序是核心。 - 基于统计的中文分词方法
统计学认为分词是一个概率最大化问题,即拆分句子,基于语料库,统计相邻的字组成的词语出现的概率,相邻的词出现的次数多,就出现的概率大,按照概率值进行分词,所以一个完整的语料库很重要。 - 基于理解的分词方法
基于理解的分词方法是通过让计算机模拟人对句子的理解,达到识别词的效果。其基本思想就是在分词的同时进行句法、语义分析,利用句法信息和语义信息来处理歧义现象。
它通常包括三个部分:分词子系统、句法语义子系统、总控部分。在总控部分的协调下,分词子系统可以获得有关词、句子等的句法和语义信息来对分词歧义进行判断,即它模拟了人对句子的理解过程。
这种分词方法需要使用大量的语言知识和信息。由于汉语语言知识的笼统、复杂性,难以将各种语言信息组织成机器可直接读取的形式,因此目前基于理解的分词系统还处在试验阶段。
去停用词
“在自然语言中,很多字词是没有实际意义的,比如:【的】【了】【得】等,因此要将其剔除。”
停用词(Stop Word)是一类既普遍存在又不具有明显的意义的词,在英文中例如:“the”、“of”、“for”、“with”、“to”等,在中文中例如:“啊”、“了”、“并且”、“因此”等。
由于这些词的用处太普遍,去除这些词,对于文本分类来说没有什么不利影响,相反可能改善机器学习效果。停用词去除组件的任务比较简单,只需从停用词表中剔除定义为停用词的常用词就可以了。
文本特征提取(特征选择)
nlp 任务非常重要的一步就是特征提取(对应机器学习中的特征工程步骤,也叫做降维),在向量空间模型中,文本的特征包括字、词组、短语等多种元素表示 。在文本数据集上一般含有数万甚至数十万个不同的词组,如此庞大的词组构成的向量规模惊人,计算机运算非常困难。
进行特征选择,对文本分类具有重要的意义。特征选择就是要想办法选出那些最能表征文本含义的词组元素 。特征选择不仅可以降低问题的规模,还有助于分类性能的改善,选取不同的特征对文本分类系统的性能有非常重要的影响。
向量空间模型文本表示方法的特征提取分为特征项选择和特征权重计算两部分。但实际中区分的并没有那么严格。
特征选择的基本思路是根据某个评价指标独立地对原始特征项(词项)进行评分排序,从中选择得分最高的一些特征项****,过滤掉其余的特征项。常用的评价有**文档频率、互信息、信息增益、 X 2 X^2 X2**统计量等。
词袋模型
词袋模型是最原始的一类特征集,忽略掉了文本的语法和语序,用一组无序的单词序列来表达一段文字或者一个文档 。可以这样理解,把整个文档集的所有出现的词都丢进袋子里面,然后 无序去重 地排出来(去掉重复的)。对每一个文档,按照词语出现的次数来表示文档 。例如:
句子1:我/有/一个/苹果
句子2:我/明天/去/一个/地方
句子3:你/到/一个/地方
句子4:我/有/我/最爱的/你
把所有词丢进一个袋子:我,有,一个,苹果,明天,去,地方,你,到,最爱的。这 4 句话中总共出现了这 10 个词。
现在我们建立一个无序列表:我,有,一个,苹果,明天,去,地方,你,到,最爱的。并根据每个句子中词语出现的次数来表示每个句子。

总结以下特征:
- 句子 1 特征: ( 1 , 1 , 1 , 1 , 0 , 0 , 0 , 0 , 0 , 0 )
- 句子 2 特征: ( 1 , 0 , 1 , 0 , 1 , 1 , 1 , 0 , 0 , 0 )
- 句子 3 特征: ( 0 , 0 , 1 , 0 , 0 , 0 , 1 , 1 , 1 , 0 )
- 句子 4 特征: ( 2 , 1 , 0 , 0 , 0 , 0 , 0 , 1 , 0 , 1 )
词袋模型生成的特征叫做词袋特征,该特征的缺点是词的维度太大,导致计算困难,且每个文档包含的词语远远数少于词典的总词语数,导致文档稀疏。仅仅考虑词语出现的次数,没有考虑句子词语之间的顺序信息,即语义信息未考虑。
TF-IDF模型
这种模型主要是用词汇的统计特征来作为特征集,TF-IDF 由两部分组成:TF(Term frequency,词频),**IDF(Inverse document frequency,逆文档频率)**两部分组成,利用 TF 和 IDF 两个参数来表示词语在文本中的重要程度。TF 和 IDF 都很好理解,我们直接来说一下他们的计算公式:
(词语在文本中的重要程度)
TF
TF 是词频,指的是一个词语在一个文档中出现的频率,一般情况下,每一个文档中出现的词语的次数越多词语的重要性更大(当然要先去除停用词),例如 BOW 模型直接用出现次数来表示特征值。
问题在于在 长文档中的词语次数普遍比短文档中的次数多,导致特征值偏向差异情况,所以不能仅仅使用词频作为特征。
TF体现的是词语在文档内部的重要性。
t f i j = n i j ∑ k n k j tf_{ij} = \frac{n_{ij}}{\sum_{k}n_{kj}} tfij
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2917
2917

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











