







摘要
我们为少样本分类问题提出了原型网络,其中分类器必须泛化到训练集中没有看到的新类,每个新类只给出少量示例。原型网络学习一个度量空间,其中可以通过计算到每个类的原型表示的距离来执行分类。与最近的小样本学习方法相比,它们反映了一种更简单的归纳偏差,这在这种有限数据的情况下是有益的,并取得了出色的结果。我们提供的分析表明,与最近涉及复杂架构选择和元学习的方法相比,一些简单的设计决策可以产生实质性的改进。我们进一步将原型网络扩展到零样本学习,并在 CU-Birds 数据集上实现了最先进的结果。
介绍
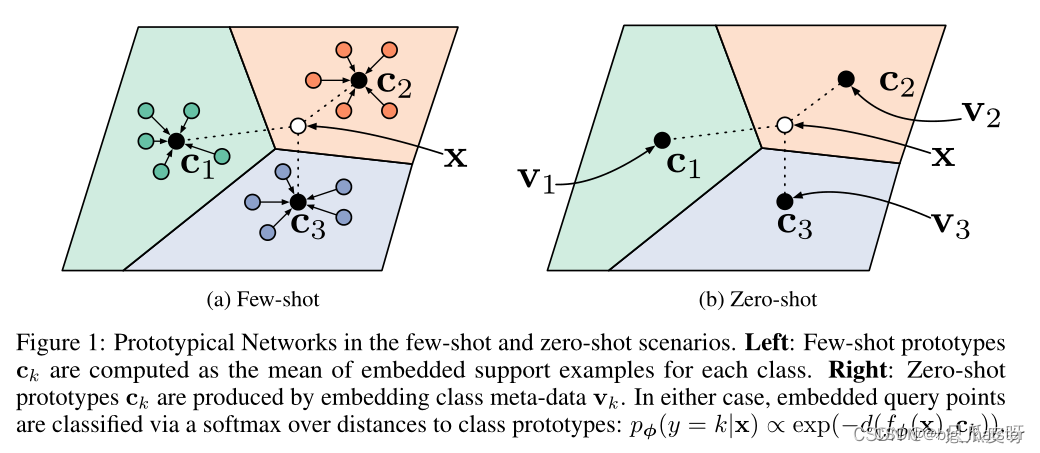
我们通过解决过度拟合的关键问题来解决小样本学习的问题。由于数据非常有限,我们假设分类器应该有一个非常简单的归纳偏差(模型的指导准则)。我们的方法,原型网络,基于这样的想法,即存在一个嵌入,其中点围绕每个类的单个原型表示聚集。为了做到这一点,我们使用神经网络学习输入到嵌入空间的非线性映射,并将类的原型作为其在嵌入空间中的支持集的平均值。然后通过简单地找到最近的类原型对嵌入的查询点执行分类。
(神经网络学习输入到非线性空间的非线性映射)
类原型作为其在嵌入空间中的主持集的平均值。
简单找到最近的类原型对嵌入的查询点执行分类。
我们采用相同的方法来解决零样本学习;这里每个类都带有提供类的高级描述的元数据,而不是少量的标记示例。因此,我们学习将元数据嵌入到共享空间中,作为每个类的原型。分类是通过为嵌入的查询点找到最近的类原型来执行的,就像在小样本场景中一样。
- 每个类都带有提供类的高级描述的元数据。
- 将元数据嵌入到共享空间中。(每个类的原型)
- 为嵌入的查询点找到最近的类原型。来执行。
Method
原型网络通过嵌入函数
f
ϕ
:
R
D
→
R
M
f_{\phi}:RD\rightarrow RM
fϕ:RD→RM
和可学习参数
ϕ
\phi
ϕ,计算每个类的
M
M
M维表示,
c
k
∈
R
M
ck \in RM
ck∈RM或原型,
每个原型都属于其类的嵌入支持点的平均向量。
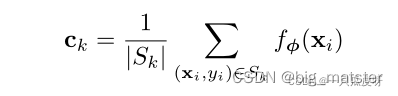
给定距离函数
d
:
R
M
×
R
M
→
[
0
,
∞
)
d:RM \times RM \rightarrow [0,\infty)
d:RM×RM→[0,∞)
原型网络基于到嵌入空间中原型的距离上的softmax上的生成查询点
x
x
x的类分布。
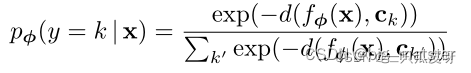
通过SGD最小化真实类的
k
k
k,的负对数概率进行学习。

算法流程

大致了解了。然后再从原始论文中迭代,将其看完整都行啦的样子与打算。全部都将其搞定都行啦的样子与。
慢慢的将其研究透彻都行啦的的样子与打算。
总结
利用距离函数和softmax函数来设计概率分布,进行学习与研究。全部都将其搞定都行啦的样子与打算。
















 2003
2003











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











