









Abstract
尽管为许多计算机视觉任务提供了出色的结果,但最先进的深度学习算法在低数据场景中举步维艰。然而,如果存在其他模式中的数据(如文本),这可以弥补数据的不足,并改善分类结果。为了克服这种数据匮乏的问题,我们设计了一个跨模态特征生成框架,该框架能够在样本较少的场景中丰富低填充嵌入空间,利用来自辅助模态的数据。具体来说,我们训练生成模型,将文本数据映射到视觉特征空间,以获得更可靠的原型。这允许在训练期间利用来自其他模式(如文本)的数据,而测试时间的最终任务仍然是用唯一的视觉数据进行分类。我们表明,在这种情况下,最近邻分类是一种可行的方法,在CUB-200和Oxford-102数据集上优于最先进的单模态和多模态少射击学习方法。
Introduction

我们的方法建立在观察的基础上,即通过dnn学习的表示足够强大,可以使用简单的非参数分类技术[1],而且多模态数据可以改善生成多样性。为此,1. 首先在可用的基类上训练图像编码器,2. 然后文本条件GAN学习文本和视觉嵌入空间之间的交叉模态映射。然后,这种映射可以用于生成存在于视觉空间中的特征表示,并以文本数据为条件。直观地说,我们的方法利用跨模态特征映射,将单模态原型pI(表示视觉数据)转换为pM,模拟新类的未见样本。这一过程可以在图1中观察到,在图1中,给定的样本xi通过原型的移动进行了不同的分类。在一个原型空间中,使用了非参数分类技术k-NN,因此只有表示学习阶段需要多模态数据,推理阶段只需要视觉数据。
Contributions
- 在小样本学习环境中使用跨模态特征生成网络。
- 此外,我们提出了一种结合真实特征和生成特征的策略,允许我们用一种简单的最近邻方法来推断看不见的样本的类别成员。
- 对于CUB-200和Oxford-102数据集,我们的方法比我们的基线和最先进的多模态和只有图像的少数镜头学习方法的性能要好得多。
Method
1、视觉嵌入空间中的最近邻居
在嵌入空间中使用简单的最近邻方法进行分类。假设给定一个强大的特征表示,如ResNet-18特征向量,最近邻是一个可行的选择作为分类模型,并已被证明优于更复杂的少机会学习方法[1]。因此,我们使用来自基类Cbase的可视数据来训练图像编码器ΦI,提供有区别的可视嵌入空间φ。对于新视觉样本xi, ΦI(xi)然后提供相应的嵌入,具有由预训练的视觉嵌入空间ϕ给出的区别性。
在[37]之后,对于每个新类k∈Cnovel,我们计算出所有编码训练样本的视觉原型pk:

然后,计算查询样本和每个类原型的距离,距离最近则为该类别:

2、跨模态特征生成


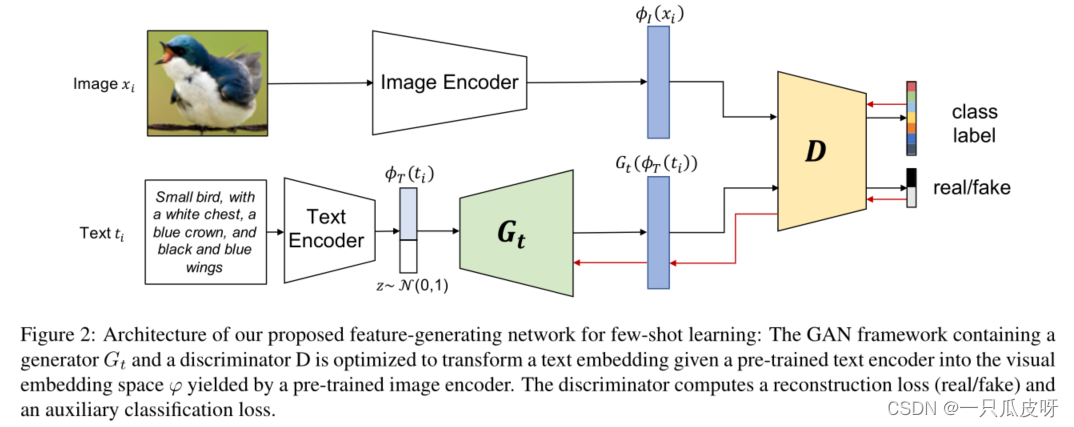
为了实现跨模态特征生成,我们使用了文本-条件生成对抗网络(tcGAN)的改进版本[33,47,45]。tcGAN的目标是在GAN框架[10]中生成给定文本描述的图像。在tcGAN中嵌入文本描述的φT(·)。因此,一个常见的策略是定义两个代理G和D解决对抗性的游戏生成图像无法区别真正的样品(G)和检测生成的图像为假(D)。因为我们的策略是执行近邻分类ϕ在pre-trained嵌入空间中,我们稍微改变了tcGAN的用途。我们没有生成图像xi∈I,而是优化G在space φ中生成其特征表示ΦI(xi)。通常情况下,嵌入空间中的表示向量的维数明显低于原始图像。因此,与图像的生成相比,特征向量的生成是一个计算成本更低的任务,可以更有效地训练和更少的错误。
为此,利用Strain的数据,我们的改进tcGAN可以通过优化以下损失函数进行训练:

这将导致传统GAN实现[10]所使用的重构损失。此外,在[24,28,48]中,我们定义了tcGAN训练过程中类预测的辅助任务。这需要用一个有区别的分类项来增加式4中给出的tcGAN损失,该分类项定义为:

用定义的辅助项增加原始GAN损耗,D和Gt的优化目标现在可以被定义为:

三、多模态原型


其中,λ是一个权重因子,k∈Cnovel表示原型的类标签。请注意,Eq. 10中的步骤可以重复多次,因为Gt允许在φ中生成可能无限数量的视觉特征向量。不可见测试样本的类成员预测现在可以通过Eq. 2使用更新的原型来执行。
实验

















 2135
2135











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









