







文本特征
expansion编码
consolidation编码
文本长度特征
标点符号特征
词汇属性特征
特殊词汇特征
词频特征
TF-IDF特征
LDA特征
下面的文章主要是梯度提升树模型展开的,抽取的特征主要为帮助梯度提升树模型挖掘其挖掘不到的信息,本文介绍的所有特征都可以当做特征直接加入模型,和基于神经网络策略有些许差别。
- 因篇幅过多,本篇文章介绍文本特征的20种不同的特征,后续的文本特征会在后面的文章中更新!
文本特征

文本特征和类别特征会有一些简单的交集,一些简单的文本特征可以直接当做类别特征来处理。例如:
- 花的颜色:red,blue,yellow等等;
- 名字:Mr jack,Mr smith,Mrs will,Mr phil等等。
对于这些特征可以直接使用 L a b e l Label Label编码,然后采用类别特征的技巧对其进行特征工程。除了把文本特征当做类别特征处理外,我们再做文本相关的特征工程时,需要注意非常多的细节。相较于 L a b e l Label Label编码。就是如何防止文本内的信息丢失问题。文本特征处理涉及非常多的NLP技术。此外,我们需要经常介绍一些经常需要注意的地方及一些技巧。关于最新的方法,大家可以跟进最新的NLP相关技术。
针对梯度提升树模型对文本特征进行特征工程。我们需要充分挖掘 L a b e l Label Label丢失信息。例如,上面的名字特征,内部存在非常强的规律。Mr等信息。这些信息反映了性别相关的信息。如果直接进行 L a b e l Label Label编码就会丢失此类信息。所以我们可以通过文本技巧对其进行挖掘。
expansion编码
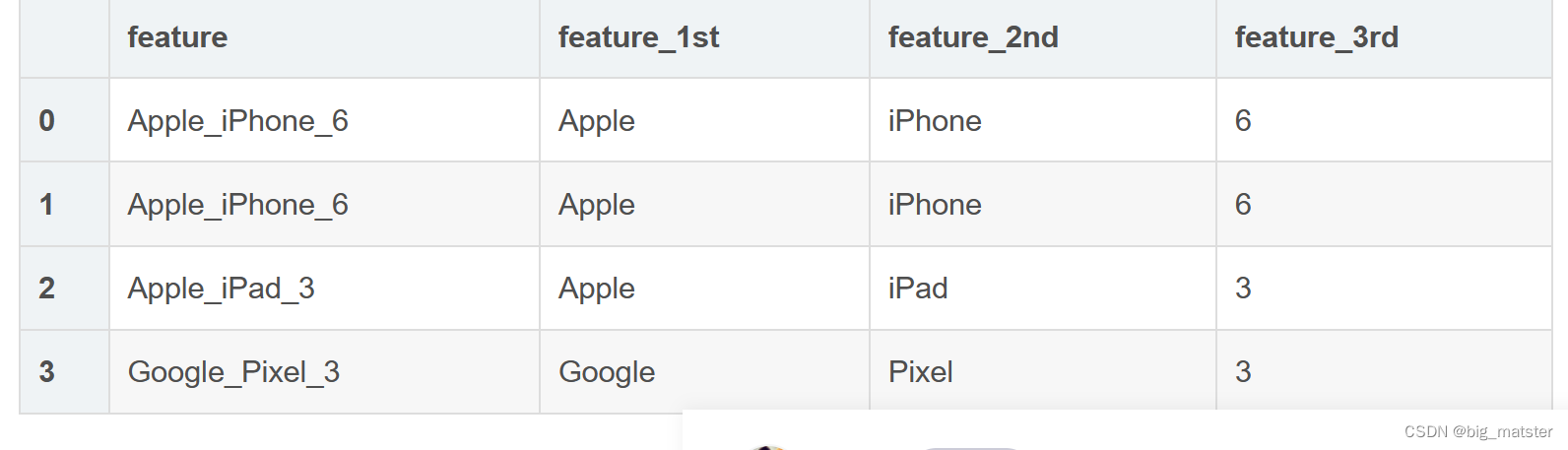
expansion编码常常出现在一些复杂字符串中,例如一些带有版本信息的字符串。很多版本号的信息中涵盖了时间以及编号等信息。我们需要将其拆分开,形成多个新的特征列。例如下面的例子如下:
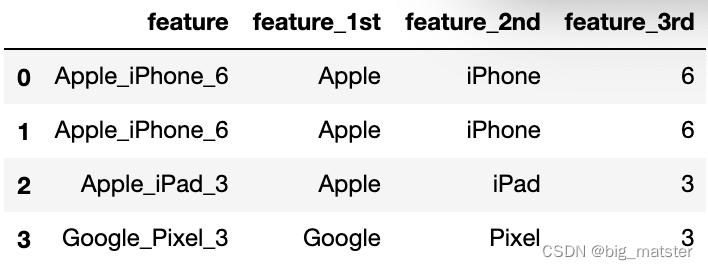
expansion编码类似于带有业务信息的聚类信息 。可以加速树模型的搜索速度,也是非常非常不错的特征。
import pandas as pd
df = pd.DataFrame()
df['feature'] = ['Apple_iPhone_6', 'Apple_iPhone_6', 'Apple_iPad_3', 'Google_Pixel_3']
df['feature_1st'] = df['feature'].apply(lambda x: x.split('_')[0])
df['feature_2nd'] = df['feature'].apply(lambda x: x.split('_')[1])
df['feature_3rd'] = df['feature'].apply(lambda x: x.split('_')[2])
df
consollidation编码
consollidation编码常常出现在一些特殊字符串中。例如:
- 一些带有地址的字符串,字符串会给出详细的信息,XX市XX县XX村XX号等,这时我们可以将市抽取来作为一个全新的特征;
- 很多产品,例如手机、pad等等。我们可以单独抽象为苹果、三星等公司等信息。


- concolidation编码和上面的expansion编码类似,也是一种带有业务信息的聚类信息,可以加速树模型的搜搜速度,也是一类非常不错的特征。
文本长度特征
文本的长度特征可以按照文本的段落,句子,单词和字母四大粒度进行枚举式构建。这些特征可以反映文本的段落结构,在很多问题中都是非常重要的信息,例如判断文本的类型。判断文本是小说还是其它,此时文本的长度特征都是非常强的特征。

段落的个数
顾名思义都是文本中段落的个数。
句子的个数
文本中句子的个数,可以通过计算句号感叹号等次数来统计。
单词的个数
文本中单词的个数,可以直接通过将标点符号转换为空格,然后计算空格个数的方式来计算。
字母的个数
删除所有标点之后,直接统计所有字母的个数。
平均每个段落的句子数
平均每个段落句子数 = 句子的个数/段落的个数。
平均每个段落单词个数
平均每个段落的单词个数 = 单词的个数 / 段落的个数
平均每个段落字母个数。
平均每个段落字母个数 = 文本字母个数/段落个数。
平均每个句子单词个数
平均每个句子的单词个数 = 单词的个数 / 句子的个数
平均每个句子字母个数。
平均每个句子的字母个数 = 文本字母个数 / 句子的个数
平均每个单词的长度
平均每个单词的长度 = 文本字母个数/文本单词个数。
标点符号特征
标点符号也涵盖这非常重要的信息, 例如在情感分类问题中,感叹号等信息往往意味着非常强烈的情感表达。对于最终模型的预测可以带来非常强大的帮助。

标点符号的个数。
直接计算标点符号出现的次数。
特征标点符号的个数。
统计文本中一些重要的标点符号出现的次数,例如:
情感分类问题中,感叹号出现的次数,问号出现的次数等。
在病毒预测问题中,异常符号出现的次数。
其它
此外,需要额外注意一点,就是一些奇异的标点符号。例如连续多个感叹号,"!!!"或者连续多个问号“???”,这种符号的情感表示更为强烈,所以很多时候也需要特别注意。
词汇属性特征
每个词都有其所属的属性,例如是名词、动词还是形容词等等。词汇属性特征很多时候能帮助模型带来效果上的微弱提升。可以作为一些补充信息。

特殊词汇特征
标点符号能够从侧面反映文本的情感强烈程度等信息。在情感分类,文本分类中有重要的作用。当然,与此同时,特殊词汇的特征则更有重要。
我们可以选择直接分类别(每一类情感表示一类)统计每个类别中词汇的出现次数。
词频特征
上面是一些简单的文本特征**,还有一些文本信息会相对复杂一些**,例如是句子等文本。这个时候我们就需要一些常用的文本工具了,而最为常见的就是词频统计特征,该特征较为简单,就是统计文本中每个词出现的次数,因为每个文本一般都是由单词所组成的,而每个单词出现的次数在一定程度上又可以从侧面反映该文章的内容,例如在谋篇文章中,"love"这个词出现的比较多,也就是说"love"对应的词频比较大,则我们可以猜测该文章很大可能属于情感类的文章。所以在处理文本类的信息时,词频特征是非常重要的信息之一。
# 导入工具包
from sklearn.feature_extraction.text import CountVectorizer
# 初始化,并引入停止词汇
vectorizer = CountVectorizer(stop_words=set(['the', 'six', 'less', 'being', 'indeed', 'over', 'move', 'anyway', 'four', 'not', 'own', 'through', 'yourselves']))
df = pd.DataFrame()
df['text'] = ["The sky is blue.", "The sun is bright.","The sun in the sky is bright.", "We can see the shining sun, the bright sun."]
# 获取词汇
vectorizer.fit_transform(df['text']).todense()
matrix([[1, 0, 0, 0, 1, 0, 0, 1, 0, 0],
[0, 1, 0, 0, 1, 0, 0, 0, 1, 0],
[0, 1, 0, 1, 1, 0, 0, 1, 1, 0],
[0, 1, 1, 0, 0, 1, 1, 0, 2, 1]])
如果希望知道上面每一列的意思,可以直接观测文本的字典即可。
vectorizer.vocabulary_
{'sky': 7,
'is': 4,
'blue': 0,
'sun': 8,
'bright': 1,
'in': 3,
'we': 9,
'can': 2,
'see': 5,
'shining': 6}
词频特征简单易于理解,能够从宏观的角度捕获文本的信息。相较于直接Label编码可以能提取更多有用的信息特征,从而带来效果上的提升,但是词频特征往往会受到停止词汇的影响(stop words),例如"the,a"出现次数往往较多,这在聚类的时候如果选用了错误的聚类距离,例如l2距离等,则往往难以获得较好的聚类效果,所以需要细心的进行停止词汇的删选;受文本大小的影响,如果文章比较长,则词汇较多,文本较短,词汇则会较少等问题。
TF-IDF特征
T F − I D F TF-IDF TF−IDF特征是词频特征的一个扩展延伸,词频特征可以从宏观的方面表示文本的信息,但在词频方法因为将频繁的词汇的作用放大了,例如常见的"I",'the"等;将稀有的词汇,例如"garden","tiger"的作用缩减了,而这些单词却有着极为重要的信息量,所以词频特征往往很难捕获一些出现次数较少但是又非常有效的信息。而TF-IDF特征可以很好地缓解此类问题的方法。TF-IDF从全局(所有文件)和局部(单个文件)的角度来解决上述问题,TF-IDF可以更好地给出某个单词对于某个文件的重要性。
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf_model = TfidfVectorizer()
# 获取词汇
tfidf_matrix = tfidf_model.fit_transform(df['text']).todense()
tfidf_matrix
matrix([[0.65919112, 0. , 0. , 0. , 0.42075315,
0. , 0. , 0.51971385, 0. , 0.34399327,
0. ],
[0. , 0.52210862, 0. , 0. , 0.52210862,
0. , 0. , 0. , 0.52210862, 0.42685801,
0. ],
[0. , 0.3218464 , 0. , 0.50423458, 0.3218464 ,
0. , 0. , 0.39754433, 0.3218464 , 0.52626104,
0. ],
[0. , 0.23910199, 0.37459947, 0. , 0. ,
0.37459947, 0.37459947, 0. , 0.47820398, 0.39096309,
0.37459947]])
如果希望知道上面每一列的意思,可以直接观测文本的字典即可。
tfidf_model.vocabulary_
{'the': 9,
'sky': 7,
'is': 4,
'blue': 0,
'sun': 8,
'bright': 1,
'in': 3,
'we': 10,
'can': 2,
'see': 5,
'shining': 6}
tfidf_model.idf_
array([1.91629073, 1.22314355, 1.91629073, 1.91629073, 1.22314355,
1.91629073, 1.91629073, 1.51082562, 1.22314355, 1. ,
1.91629073])
TDIDF忽略了文章的内容,词汇之间的联系,虽然可以通过N-Gram的方式进行缓解,但其实依然没有从本质上解决该问题。
LDA特征
基于词频的特征和基于TFIDF的特征都是向量形式的,因而我们可以采用基于向量抽取特征的方式对其抽取新特征,而最为典型的就是主题模型。主题模型的思想是围绕从以主题表示的文档语料库中提取关键主题或概念的过程为中心。每个主题都可以表示为一个包或从文档语料库收集单词/术语。这些术语共同表示特定的主题、主题或概念,每个主题都可以通过这些术语所传达的语义意义与其他主题进行区分。这些概念可以从简单的事实和陈述到观点和观点**。主题模型在总结大量文本文档来提取和描述关键概念方面非常有用**。它们还可以从捕获数据中潜在模式的文本数据中提取特征。
-
捕获数据中潜在模式的文本数据中提取特征。
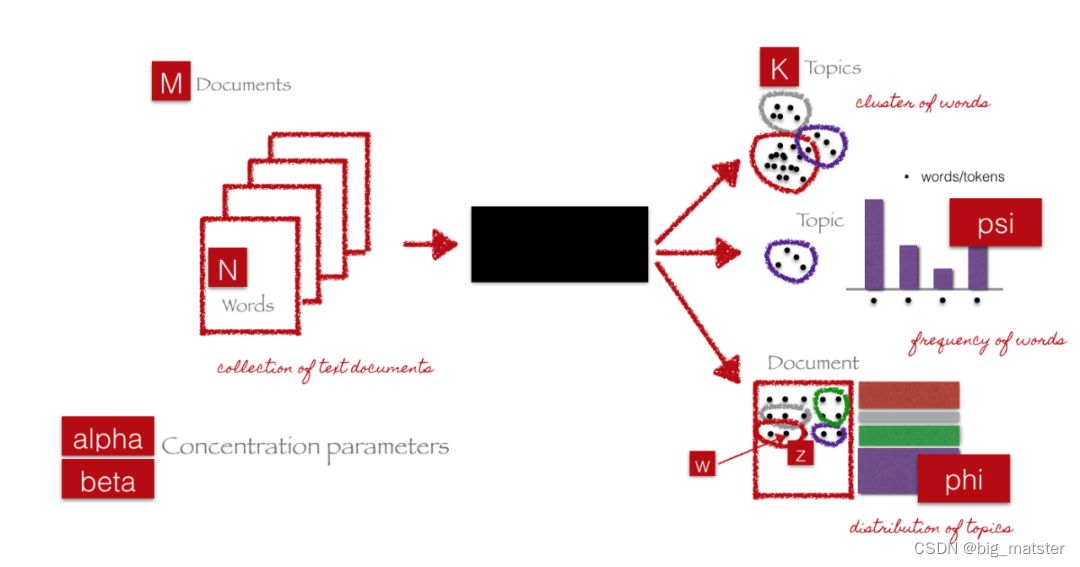
因为主题模型涉及的数学等概念较多,此处我们仅仅介绍其使用方案,有兴趣的朋友可以去阅读论文等资料。
一般我们会在 T F − I D F TF-IDF TF−IDF或者词频等矩阵上使用 L D A LDA LDA,最终我们得到的结果也可以拆解为下面两个核心部分:
*** document-topic矩阵**,这将是我们需要的特征矩阵你在找什么。 -
一个topic-term矩阵,它帮助我们查看语料库中的潜在主题。
from sklearn.decomposition import LatentDirichletAllocation
lda = LatentDirichletAllocation(n_components=2, max_iter=10000, random_state=0)
dt_matrix = lda.fit_transform(tfidf_matrix)
features = pd.DataFrame(dt_matrix, columns=['T1', 'T2'])
features
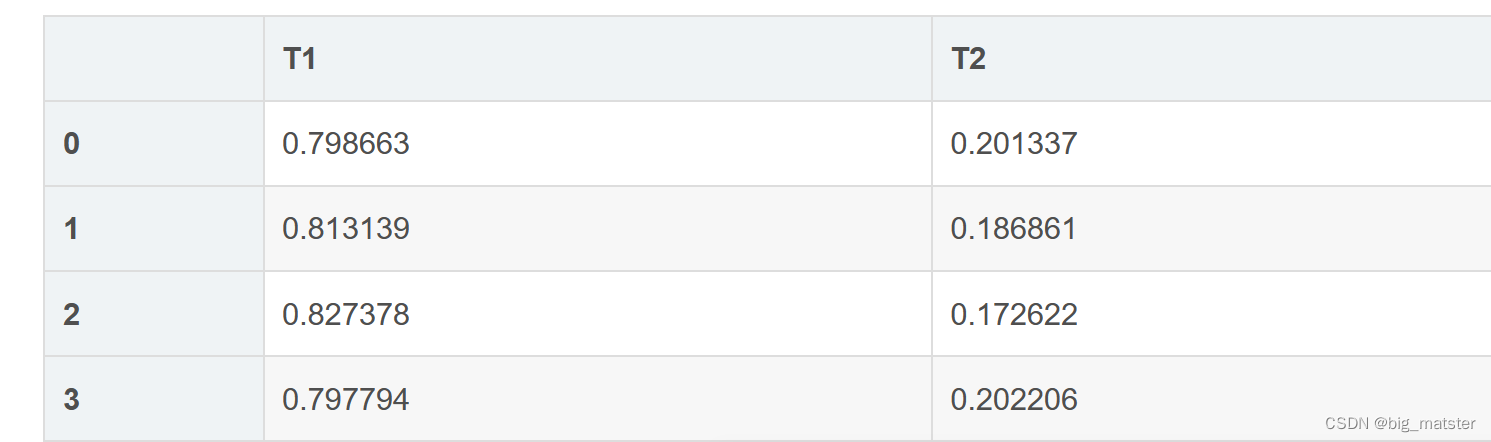
8查看主题以及对应每个词的贡献
tt_matrix = lda.components_
vocab = tfidf_model.get_feature_names()
for topic_weights in tt_matrix:
topic = [(token, weight) for token, weight in zip(vocab, topic_weights)]
topic = sorted(topic, key=lambda x: -x[1])
topic = [item for item in topic if item[1] > 0.2]
print(topic)
print()
[('the', 2.1446092537000254), ('sun', 1.7781565358915534), ('is', 1.7250615399950295), ('bright', 1.5425619519080085), ('sky', 1.3771748032988098), ('blue', 1.116020185537514), ('in', 0.9734645258594571), ('can', 0.828463031801155), ('see', 0.828463031801155), ('shining', 0.828463031801155), ('we', 0.828463031801155)]
[('can', 0.5461364394229279), ('see', 0.5461364394229279), ('shining', 0.5461364394229279), ('we', 0.5461364394229279), ('sun', 0.5440024650128295), ('the', 0.5434661558382532), ('blue', 0.5431709323301609), ('bright', 0.5404950589213404), ('sky', 0.5400833776748659), ('is', 0.539646632403921), ('in', 0.5307700509960934)]
















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











