







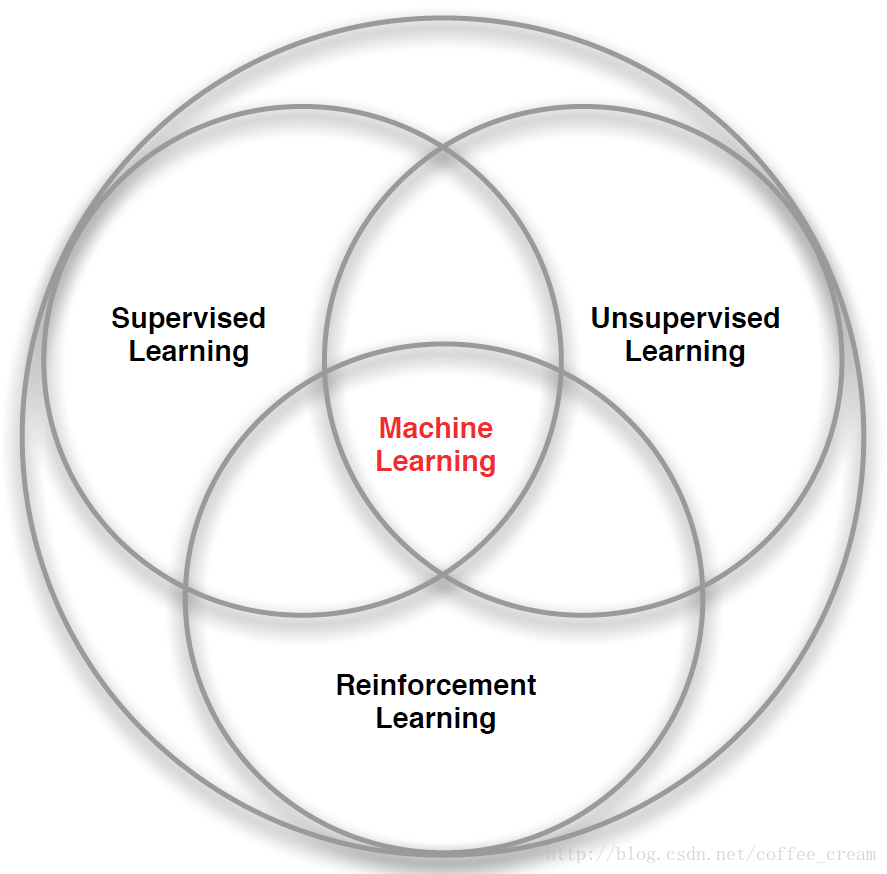
当前的机器学习算法可以分为3种:有监督的学习(Supervised Learning)、无监督的学习(Unsupervised Learning)和强化学习(Reinforcement Learning),结构图如下所示:
其他许多机器学习算法中学习器都是学得怎样做,而RL是在尝试的过程中学习到在特定的情境下选择哪种行动可以得到最大的回报。在很多场景中,当前的行动不仅会影响当前的rewards,还会影响之后的状态和一系列的rewards。RL最重要的3个特定在于:(1)基本是以一种闭环的形式;(2)不会直接指示选择哪种行动(actions);(3)一系列的actions和奖励信号(reward signals)都会影响之后较长的时间。
RL与有监督学习、无监督学习的比较:
(1)有监督的学习是从一个已经标记的训练集中进行学习,训练集中每一个样本的特征可以视为是对该situation的描述,而其label可以视为是应该执行的正确的action,但是有监督的学习不能学习交互的情景,因为在交互的问题中获得期望行为的样例是非常不实际的,agent只能从自己的经历(experience)中进行学习,而experience中采取的行为并一定是最优的。这时利用RL就非常合适,因为RL不是利用正确的行为来指导,而是利用已有的训练信息来对行为进行评价。
(2)因为RL利用的并不是采取正确行动的experience,从这一点来看和无监督的学习确实有点像,但是还是不一样的,无监督的学习的目的可以说是从一堆未标记样本中发现隐藏的结构,而RL的目的是最大化reward signal。
(3)总的来说,RL与其他机器学习算法不同的地方在于:其中没有监督者,只有一个reward信号;反馈是延迟的,不是立即生成的;时间在RL中具有重要的意义;agent的行为会影响之后一系列的data。
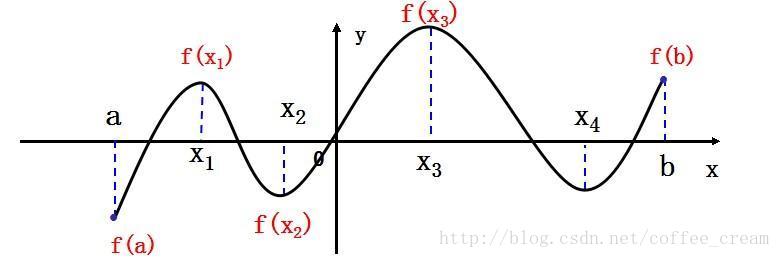
RL采用的是边获得样例边学习的方式,在获得样例之后更新自己的模型,利用当前的模型来指导下一步的行动,下一步的行动获得reward之后再更新模型,不断迭代重复直到模型收敛。在这个过程中,非常重要的一点在于“在已有当前模型的情况下,如果选择下一步的行动才对完善当前的模型最有利”,这就涉及到了RL中的两个非常重要的概念:探索(exploration)和开发(exploitation),exploration是指选择之前未执行过的actions,从而探索更多的可能性;exploitation是指选择已执行过的actions,从而对已知的actions的模型进行完善。RL非常像是“trial-and-error learning”,在尝试和试验中发现好的policy。就比如下图中的曲线代表函数
f(x)
,它是一个未知的
[a,b]
的连续函数,现在让你选择一个
x
使得
f(x)
取的最大值,规则是你可以通过自己给定
x
来查看其所对应的
f(x)
,假如通过在
[a,0]
之间的几次尝试你发现在接近
x1
的时候的值较大,于是你想通过在
x1
附近不断的尝试和逼近来寻找这个可能的“最大值”,这个就称为是exploitation,但是
[0,b]
之间就是个未探索过的未知的领域,这时选择若选择这一部分的点就称为是exploration,如果不进行exploration也许找到的只是个局部的极值。“exploration”与“exploitation”在RL中同样重要,如何在“exploration”与“exploitation”之间权衡是RL中的一个重要的问题和挑战。
在RL中,agents是具有明确的目标的,所有的agents都能感知自己的环境,并根据目标来指导自己的行为,因此RL的另一个特点是它将agents和与其交互的不确定的环境视为是一个完整的问题。在RL问题中,有四个非常重要的概念:
(1)规则(policy)
Policy定义了agents在特定的时间特定的环境下的行为方式,可以视为是从环境状态到行为的映射,常用
π
来表示。policy可以分为两类:
确定性的policy(Deterministic policy):
a=π(s)
随机性的policy(Stochastic policy):
π(a|s)=P[At=a|St=t]
其中,
t
是时间点,
t=0,1,2,3,……
St∈S
,
S
是环境状态的集合,
St
代表时刻
t
的状态,
s
代表其中某个特定的状态;
At∈A(St)
,
A(St)
是在状态
St
下的actions的集合,
At
代表时刻
t
的行为,
a
代表其中某个特定的行为。
(2)奖励信号(a reward signal)
Reward就是一个标量值,是每个time step中环境根据agent的行为返回给agent的信号,reward定义了在该情景下执行该行为的好坏,agent可以根据reward来调整自己的policy。常用
R
来表示。
(3)值函数(value function)
Reward定义的是立即的收益,而value function定义的是长期的收益,它可以看作是累计的reward,常用
v
来表示。
(4)环境模型(a model of the environment)
整个Agent和Environment交互的过程可以用下图来表示:
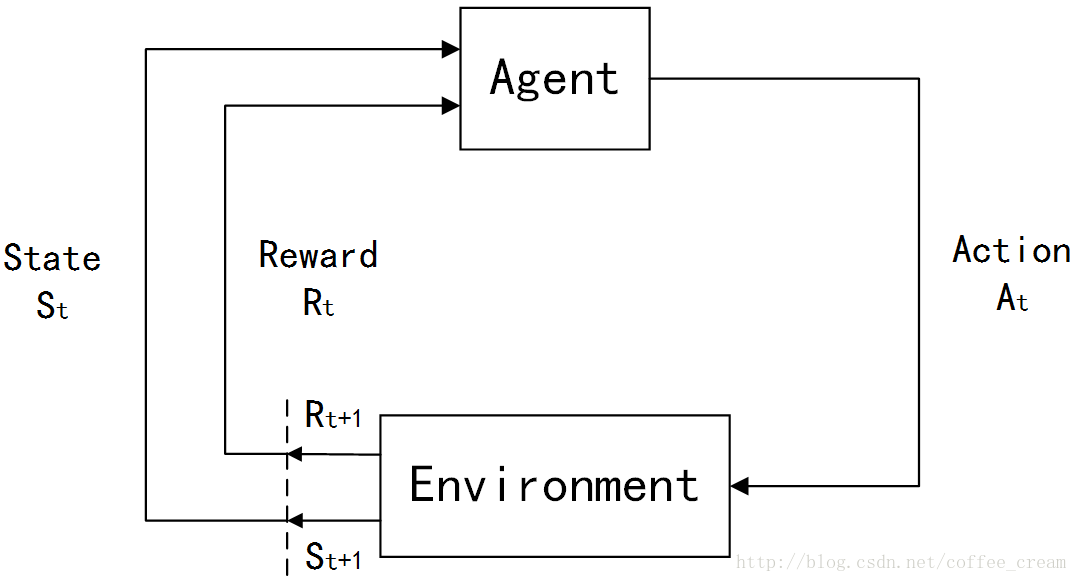
其中,
t
是时间点,
t=0,1,2,3,……
St∈S
,
S
是环境状态的集合;
At∈A(St)
,
A(St)
是在状态
St
下的actions的集合;
Rt∈R∈R
是数值型的reward。
参考文献
[1] Reinforcement Learning: An Introduction, Richard S. Sutton and Andrew G. Barto
[2] UCL Course on RL















 4579
4579

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









