







 本文详细介绍了强化学习的定义、基本术语,包括马尔可夫决策过程和贝尔曼方程,并探讨了Q-Learning、Sarsa、DQN等经典强化学习算法。强化学习是机器学习的一种,通过与环境的交互,智能体学习最优策略以获得最大回报。与其他学习方法相比,强化学习的特点在于不需要大量数据,而是通过试错和延迟反馈来优化决策。文章还涵盖了强化学习的基本流程和关键术语,如策略、值函数、奖励等。
本文详细介绍了强化学习的定义、基本术语,包括马尔可夫决策过程和贝尔曼方程,并探讨了Q-Learning、Sarsa、DQN等经典强化学习算法。强化学习是机器学习的一种,通过与环境的交互,智能体学习最优策略以获得最大回报。与其他学习方法相比,强化学习的特点在于不需要大量数据,而是通过试错和延迟反馈来优化决策。文章还涵盖了强化学习的基本流程和关键术语,如策略、值函数、奖励等。
一、强化学习的定义
1.1 什么是强化学习?
首先,强化学习并不是某一种特定的算法,而是一类算法的统称。
解决序列决策问题的一类方法,通过寻求最优策略,获取最大回报。
强化学习就是智能体从环境到动作映射的学习,以使回报信号(激励信号)函数值最大。
引用下百度百科下强化学习的定义:强化学习(Reinforcement Learning, RL),又称增强学习,是机器学习的范式和方法论之一,用于描述和解决智能体(agent)在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题 。
强化学习的常见模型是标准的。按给定条件,强化学习可分为基于模式的强化学习(model-based RL)和无模式强化学习(model-free RL) ,以及主动强化学习(active RL)和被动(passive RL)。
1.2 机器学习的几种方法
强化学习是和监督学习,非监督学习并列的第三种机器学习方法。
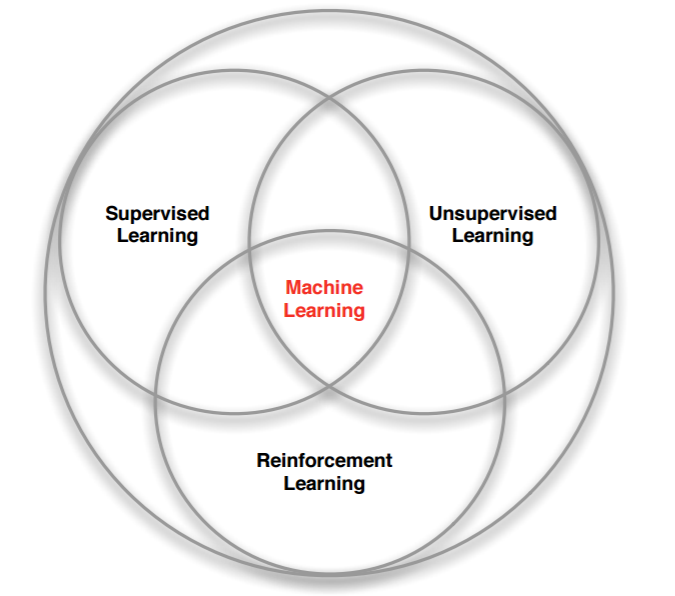
机器学习下的几种方法的对比:
- 监督学习:标签数据:需要,直接反馈,应用场景:预测输出。
- 无监督学习:标签数据:不需要,无反馈,应用场景:发掘隐藏结构。
- 强化学习:标签数据:不需要,延迟反馈,应用场景:决策过程。

强化学习和监督学习、无监督学习最大的不同就是不需要大量的“数据喂养”,而是通过自己不停的尝试来学会某些技能。也就是说,强化学习是让计算机实现从一开始完全随机的进行操作,通过不断地尝试,从错误中学习,最后找到规律,学会了达到目的的方法。智能体(Agent)以“试错”的方式进行学习,通过与环境进行交互获得的奖赏指导行为,目标是使智能体获得最大的奖赏。
1.3 强化学习基本思路
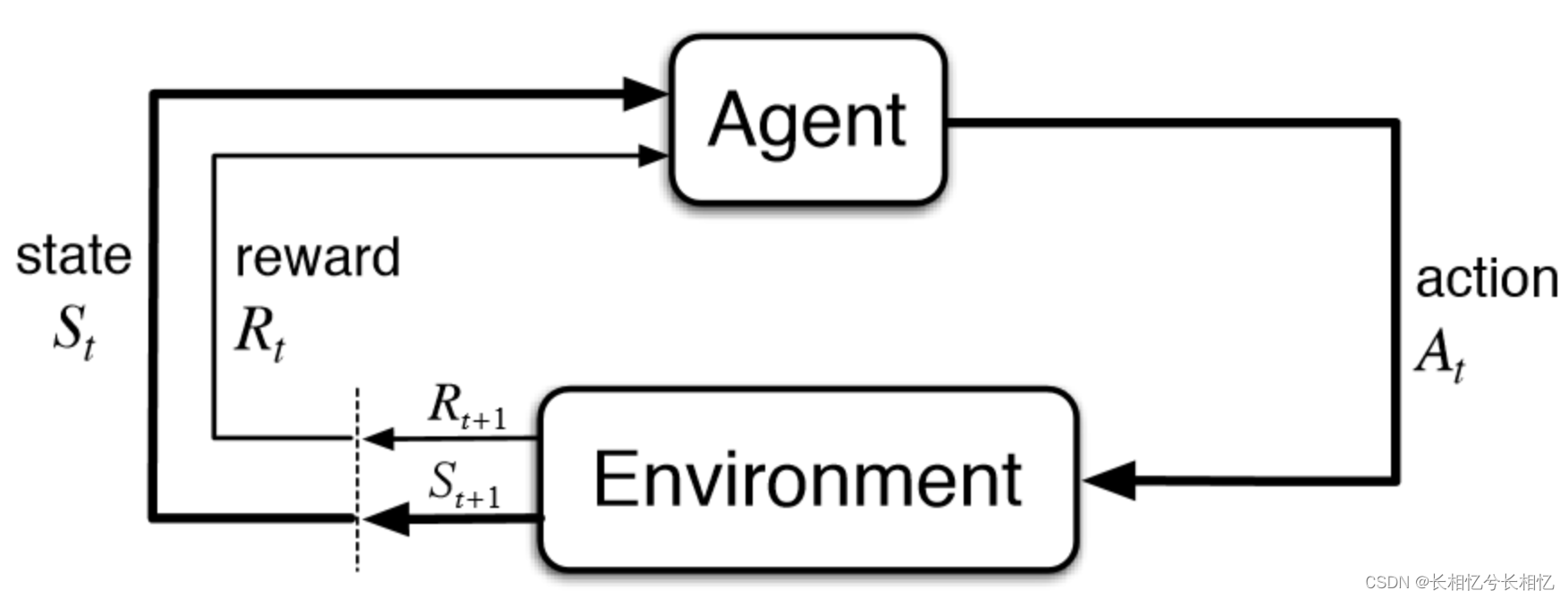
算法执行个体(Agent)来做决策,即选择一个合适的动作(Action)𝐴𝑡。选择了动作𝐴𝑡后,环境的状态(State)会发生改变,变为为𝑆𝑡+1,同时也可以得到采取动作𝐴𝑡的延时奖励(Reward)𝑅𝑡+1。然后个体可以继续选择下一个合适的动作,然后环境的状态又会发生改变,又有新的奖励值。
1.4 强化学习的一些特点
- 强化学习没有监督标签,只会对当前状态进行奖惩和打分,其本身并不知道什么样的动作才是最好的。
- 强化学习的评价有延迟,往往需要过一段时间,已经走了很多步后才知道当时选择是好是坏。有时候需要牺牲一部分当前利益以最优化未来奖励。
- 强化学习有一定的时间顺序性,每次行为都不是独立的数据,每一步都会影响下一步。目标也是如何优化一系列的动作序列以得到更好的结果,即应用场景往往是连续决策问题。
二、强化学习术语
2.1 强化学习基本术语
- 智能体-Agent:强化学习中的Agent可以理解为是采取行动的智能个体。
- 动作-Action:Action是智能体可以采取的动作的集合。一个动作(action)几乎是一目了然的,但是应该注意的是智能体是在从可能的行动列表中进行选择。
- 环境-Environment:指的就是智能体行走于其中的世界。这个环境将智能体当前的状态和行动作为输入,输出是智能体的奖励和下一步的状态。
- 状态-State:一个状态就是智能体所处的具体即时状态;也就是说,一个具体的地方和时刻,这是一个具体的即时配置,它能够将智能体和其他重要的失事物关联起来,例如工具、敌人和或者奖励。它是由环境返回的当前形势。
- 奖励-Reward:奖励是我们衡量某个智能体的行动成败的反馈,通常是一个标量。面对任何既定的状态,智能体要以行动的形式向环境输出,然后环境会返回这个智能体的一个新状态(这个新状态会受到基于之前状态的行动的影响)和奖励(如果有任何奖励的话)。奖励可能是即时的,也可能是迟滞的。它们可以有效地评估该智能体的行动。
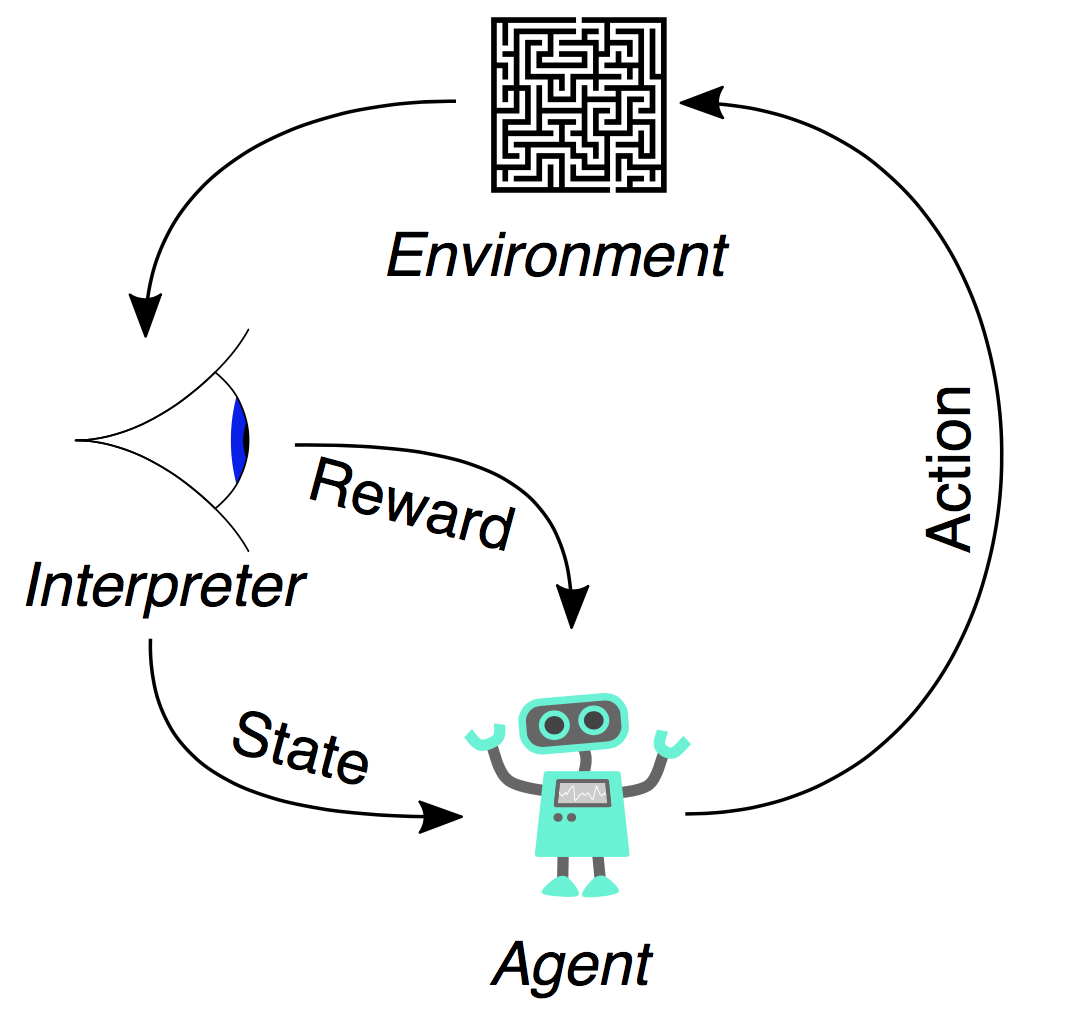
强化学习的基本流程图:
强化学习动作者主体的构成:
策略-Policy:动作者的行为函数,策略是动作者的行为决策来源。
值函数-Value Function:评价每一步的状态或者动作,值函数是对未来累计奖励的预测。
模型-Model:动作者对环境的建模表示,预测环境接下来要发生什么。
强化学习基本要素:
- 环境状态𝑆, t时刻环境的状态𝑆𝑡是它的环境状态集中某一个状态。
- 个体的动作𝐴, t时刻个体采取的动作𝐴𝑡是它的动作集中某一个动作。
- 环境的奖励𝑅,t时刻个体在状态𝑆𝑡采取的动作𝐴𝑡对应的奖励𝑅𝑡+1会在t+1时刻得到。
-
个体的策略(policy)𝜋,它代表个体采取动作的依据,即个体会依据策略𝜋来选择动作。最常见的策略表达方式是一个条件概率分布𝜋(𝑎|𝑠),即在状态𝑠时采取动作𝑎的概率。即𝜋(𝑎|𝑠)=𝑃(𝐴𝑡=𝑎|𝑆𝑡=𝑠),此时概率大的动作被个体选择的概率较高。
-
个体在策略𝜋和状态𝑠时,采取行动后的价值(value),一般用𝑣𝜋(𝑠)表示。这个价值一般是一个期望函数。虽然当前动作会给一个延时奖励𝑅𝑡+1,但是光看这个延时奖励是不行的,因为当前的延时奖励高,不代表到了t+1,t+2,...时刻的后续奖励也高。比如下象棋,我们可以某个动作可以吃掉对方的车,这个延时奖励是很高,但是接着后面我们输棋了。此时吃车的动作奖励值高但是价值并不高。因此我们的价值要综合考虑当前的延时奖励和后续的延时奖励。价值函数𝑣𝜋(𝑠)一般可以表示为下式(𝛾为衰减因子):
![]()
-
环境的状态转化模型,可以理解为一个概率状态机,它可以表示为一个概率模型ÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2410
2410

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









