







FFmpeg学习之 一 (音视频理论知识)
1. 音视频理论知识
1.1 基本概念
1.1.1 音视频必备的基本概念
常用的视频封装格式
1)AVI 格式(后缀为 .avi)
2)DV-AVI 格式(后缀为 .avi)
3)QuickTime File Format 格式(后缀为 .mov)
4)MPEG 格式(文件后缀可以是 .mpg .mpeg .mpe .dat .vob .asf .3gp .mp4等)
5)WMV 格式(后缀为.wmv .asf)
6)Real Video 格式(后缀为 .rm .rmvb)
7)Flash Video 格式(后缀为 .flv)
8)Matroska 格式(后缀为 .mkv)
9)MPEG2-TS 格式 (后缀为 .ts)
常用的视频编码器
1)H.264/AVC
2)HEVC/H.265
3)VP8
4)VP9
5)FFmpeg
FFmpeg 是一个开源框架,可以运行音频和视频多种格式的录影、转换、流功能,包含了 libavcodec: 这是一个用于多个项目中音频和视频的解码器库,以及 libavformat 一个音频与视频格式转换库。
目前支持 Linux ,Mac OS,Windows 三个主流的平台,也可以自己编译到 Android 或者 iOS 平台。
如果是 Mac OS ,可以通过 brew 安装 brew install ffmpeg --with-libvpx --with-libvorbis --with-ffplay
常用的音频编程器:
Mp3
AAC
视频流 裸数据YUV
-
YUV简介
YUV虽说是视频帧的裸数据,YUV数据是不能直接用于渲染,还是要转换为RGB的形式才可以渲染,YUV主要应用于优化彩色视频信号的传输。YUV应该是RGB存储形式和编码存储的一种折衷吧。YUV比RGB省空间,有没有编码后数据那么耗内存去解码,只要简单作个转换就可以变成RGB信号。 -
YUV视频渲染方式
一个图像最终要变成RGB的表现方式才可以渲染到显示屏上。而一个RGB形式的图片是超级耗空间,所以编程时注意bitmap对象的回收。我们可以通过yuv转化为RGB图片显示,但这种方式非常消耗CPU性能。一般都通过opengl文理利用GPU直接渲染,这样对CPU的消耗就会少很多。
具体YUV怎么通过openGL渲染请参考我的另一篇博客:
FFmpeg学习之二 (yuv视频渲染) -
RGB 和 YUV的区别
-
RGB
我们先来看一下RGB的定义:
RGB是红绿蓝三原色的意思,R=Red、G=Green、B=Blue。
计算机显示彩色图像的时,最终显示的时候,要控制一个像素中Red,Green,Blue的值,来确定这个像素的颜色。计算机中无法模拟连续的存储从最暗到最亮的量值,而只能以数字的方式表示。于是,结合人眼睛的敏感程度,使用3个字节(3*8位)来分别表示一个像素里面的Red,Green和Blue的发光强度数值,这就是常见的RGB格式。我们可以打开画图板,在自定义颜色工具框中,输入r,g,b值,得到不同的颜色。
但是对于视频捕获和编解码等应用来讲,这样的表示方式数据量太大了。需要想办法在不太影响感觉的情况下,对原始数据的表示方法进行更改,减少数据量。
无论中间处理过程怎样,最终都是为了展示给人观看,这样的更改,也是从人眼睛的特性出发,和发明RGB三原色表示方法的出发点是一样的。
于是我们使用Y,Cb,Cr模型来表示颜色。Iain的书中写道:The human visual system (HVS) is less sensitive to colour than to luminance (brightness).人类视觉系统(其实就是人的眼睛)对亮度的感觉比对颜色更加敏感。
在RGB色彩空间中,三个颜色的重要程度相同,所以需要使用相同的分辨率进行存储,最多使用RGB565这样的形式减少量化的精度,但是3个颜色需要按照相同的分辨率进行存储,数据量还是很大的。所以,利用人眼睛对亮度比对颜色更加敏感,将图像的亮度信息和颜色信息分离,并使用不同的分辨率进行存储,这样可以在对主观感觉影响很小的前提下,更加有效的存储图像数据。 -
YUV
YCbCr色彩空间和它的变形(有时被称为YUV)是最常用的有效的表示彩色图像的方法。Y是图像的亮度(luminance/luma)分量,使用以下公式计算,为R,G,B分量的加权平均值:
Y = kr R + kgG + kbB
其中k是权重因数。
上面的公式计算出了亮度信息,还有颜色信息,使用色差(color difference/chrominance或chroma)来表示,其中每个色差分量为R,G,B值和亮度Y的差值:
Cb = B -Y
Cr = R -Y
Cg = G- Y
其中,Cb+Cr+Cg是一个常数(其实是一个关于Y的表达式),所以,只需要其中两个数值结合Y值就能够计算出原来的RGB值。所以,我们仅保存亮度和蓝色、红色的色差值,这就是(Y,Cb,Cr)。
相比RGB色彩空间,YCbCr色彩空间有一个显著的优点。Y的存储可以采用和原来画面一样的分辨率,但是Cb,Cr的存储可以使用更低的分辨率。这样可以占用更少的数据量,并且在图像质量上没有明显的下降。所以,将色彩信息以低于量度信息的分辨率来保存是一个简单有效的图像压缩方法。
在COLOUR SPACES .17 ITU-R recommendation BT.601 中,建议在计算Y时,权重选择为kr=0.299,kg=0.587,kb=0.114。于是常用的转换公式如下:
Y = 0.299R + 0.587G + 0.114B
Cb = 0.564(B - Y )
Cr = 0.713(R - Y )
R = Y + 1.402Cr
G = Y - 0.344Cb - 0.714Cr
B = Y + 1.772Cb
有了上面这个公式,我们就能够将一幅RGB画面转换成为YUV画面了,反过来也可以。
下面将画面数据究竟是以什么形式存储起来的。
在RGB24格式中,对于宽度为w,高度为h的画面,需要wh3个字节来存储其每个像素的rgb信息,画面的像素数据是连续排列的。按照r(0,0),g(0,0),b(0,0);r(0,1),g(0,1),b(0,1);…;r(w-1,0),g(w-1,0),b(w-1,0);…;r(w-1,h-1),g(w-1,h-1),b(w-1,h-1)这样的顺序存放起来。
在YUV格式中,以YUV420格式为例。宽度为w高度为h的画面,其亮度Y数据需要wh个字节来表示(每个像素点一个亮度)。而Cb和Cr数据则是画面中4个像素共享一个Cb,Cr值。这样Cb用wh/4个字节,Cr用wh/4个字节。
YUV文件中,把多个帧的画面连续存放。就是YUV YUV YUV……这样的不断连续的形式,而其中每个YUV,就是一幅画面。
在这单个YUV中,前wh个字节是Y数据,接着的wh/4个字节是Cb数据,再接着的wh/4个字节为Cr数据。
在由这样降低了分辨率的数据还原出RGB数据的时候,就要依据像素的位置找到它对应的Y,Cb,Cr值,其中Y值最好找到,像素位置为x,y的话,Y数据中第ywidth+x个数值就是它的Y值。Cb和Cr由于是每2x2像素的画面块拥有一个,这样Cb和Cr数据相当于两个分辨率为w/2 * h/2的画面,那么原来画面中的位置为x,y的像素,在这样的低分辨率画面中的位置是x/2,y/2,属于它的Cb,Cr值就在这个地方:(y/2)(width/2)+(x/2)。
为了直观起见,再下面的图中,分别将Y画面(Cb,Cr=0)和Cb,Cr画面(Y=128)显示出来,可见Cb,Cr画面的分辨率是Y画面的1/4。但是合成一个画面之后,我们的眼睛丝毫感觉不到4个像素是共用一个Cb,Cr的。
Cb,Cr画面
将Cb,Cr画面放大观察,里面颜色相同的块都是2x2大小的。
附件为Windows Mobile上使用公式进行YUV到RGB转换的程序。其中需要注意的是Cb,Cr在计算过程中是会出现负数的,但是从-128到127这些数值都用一个字节表示,读取的时候就映射0到255这个区间,成为了无符号的值,所以要减去128,才能参与公式计算。这样的运算有浮点运算,效率是比较低的,所以要提高效率的话,一般在实用程序中使用整数计算或者查表法来代替。还有,运算后的r,g,b可能会超过0-255的区间,作一个判断进行调整就可以了。
什么是YUV/YCbCr/YPbPr?
亮度信号经常被称作Y,色度信号是由两个互相独立的信号组成。视颜色系统和格式不同,两种色度信号经常被称作U和V或Pb和Pr或Cb和Cr。这些都是由不同的编码格式所产生的,但是实际上,他们的概念基本相同。在DVD中,色度信号被存储成Cb和Cr(C代表颜色,b代表蓝色,r代表红色)
yuv中什么是4:4:4、4:2:2、4:2:0?
在最近十年中,视频工程师发现人眼对色度的敏感程度要低于对亮度的敏感程度。在生理学中,有一条规律,那就是人类视网膜上的视网膜杆细胞要多于视网膜锥细胞,说得通俗一些,视网膜杆细胞的作用就是识别亮度,而视网膜锥细胞的作用就是识别色度。所以,你的眼睛对于亮和暗的分辨要比对颜色的分辨精细一些。正是因为这个,在我们的视频存储中,没有必要存储全部颜色信号。既然眼睛看不见,那为什么要浪费存储空间(或者说是金钱)来存储它们呢?
像Beta或VHS之类的消费用录像带就得益于将录像带上的更多带宽留给黑—白信号(被称作“亮度”),将稍少的带宽留给彩色信号(被称作“色度”)。
在MPEG2(也就是DVD使用的压缩格式)当中,Y、Cb、Cr信号是分开储存的(这就是为什么分量视频传输需要三条电缆)。其中Y信号是黑白信号,是以全分辨率存储的。但是,由于人眼对于彩色信息的敏感度较低,色度信号并不是用全分辨率存储的。
色度信号分辨率最高的格式是4:4:4,也就是说,每4点Y采样,就有相对应的4点Cb和4点Cr。换句话说,在这种格式中,色度信号的分辨率和亮度信号的分辨率是相同的。这种格式主要应用在视频处理设备内部,避免画面质量在处理过程中降低。当图像被存储到Master Tape,比如D1或者D5,的时候,颜色信号通常被削减为4:2:2。
其次就是4:2:2,就是说,每4点Y采样,就有2点Cb和2点Cr。在这种格式中,色度信号的扫描线数量和亮度信号一样多,但是每条扫描线上的色度采样点数却只有亮度信号的一半。当4:2:2信号被解码的时候,“缺失”的色度采样,通常由一定的内插补点算法通过它两侧的色度信息运算补充。
看 4:2:2格式亮度、色度采样的分布情况。在这里,每个象素都有与之对应的亮度采样,同时一半的色度采样被丢弃,所以我们看到,色度采样信号每隔一个采样点才有一个。当着张画面显示的时候,缺少的色度信息会由两侧的颜色通过内插补点的方式运算得到。就像上面提到的那样,人眼对色度的敏感程度不如亮度,大多数人并不能分辨出4:2:2和4:4:4颜色构成的画面之间的不同。
色度信号分辨率最低的格式,也就是DVD所使用的格式,就是4:2:0了。事实上4:2:0是一个混乱的称呼,按照字面上理解,4:2:0应该是每4点Y采样,就有2点Cb和0点Cr,但事实上完全不是这样。事实上,4:2:0的意思是,色度采样在每条横向扫描线上只有亮度采样的一半,扫描线的条数上,也只有亮度的一半!换句话说,无论是横向还是纵向,色度信号的分辨率都只有亮度信号的一半。举个例子,如果整张画面的尺寸是720480,那么亮度信号是720480,色度信号只有360*240。在 4:2:0中,“缺失”的色度采样不单单要由左右相邻的采样通过内插补点计算补充,整行的色度采样也要通过它上下两行的色度采样通过内插补点运算获得。这样做的原因是为了最经济有效地利用DVD的存储空间。诚然,4:4:4的效果很棒,但是如果要用4:4:4存储一部电影,我们的DVD盘的直径至少要有两 英尺(六十多厘米)!
概念上4:2:0颜色格式非交错画面中亮度、色度采样信号的排列情况。同4:2:2格式一样,每条扫描线中,只有一半的色度采样信息。与4:2:2不同的是,不光是横向的色度信息被“扔掉”了一半,纵向的色度信息也被“扔掉”了一半,整个屏幕中色度采样只有亮度采样的四分之一。请注意,在4:2:0颜色格式中,色度采样被放在了两条扫描线中间。
什么是YV12,什么是YUY2?
YUV 格式通常有两大类:打包( packed )格式和平面( planar )格式。前者将 YUV 分量存放在同一个数组中,通常是几个相邻的像素组成一个宏像素( macro-pixel );而后者使用三个数组分开存放 YUV 三个分量,就像是一个三维平面一样。表 2.3 中的 YUY2 到 Y211 都是打包格式,而 IF09 到 YVU9 都是平面格式。(注意:在介绍各种具体格式时,
YUV 各分量都会带有下标,如 Y0 、 U0 、 V0 表示第一个像素的YUV 分量, Y1 、 U1 、 V1 表示第二个像素的 YUV 分量,以此类推。) YUY2 (和 YUYV )格式为每个像素保留 Y 分量,而 UV 分量在水平方向上每两个像素采样一次。一个宏像素为 4 个字节,实际表示 2 个像素。( 4:2:2 的意思为一个宏像素中有 4 个 Y 分量、 2 个 U 分量和 2个 V 分量。)图像数据中 YUV 分量排列顺序如下:
Y0 U0 Y1 V0 Y2 U2 Y3 V2 …
YVYU 格式跟 YUY2 类似,只是图像数据中 YUV 分量的排列顺序有所不同:
Y0 V0 Y1 U0 Y2 V2 Y3 U2 …
UYVY 格式跟 YUY2 类似,只是图像数据中 YUV 分量的排列顺序有所不同:
U0 Y0 V0 Y1 U2 Y2 V2 Y3 …
AYUV 格式带有一个 Alpha 通道,并且为每个像素都提取 YUV 分量,图像数据格式如下:
A0 Y0 U0 V0 A1 Y1 U1 V1 …
Y41P (和 Y411 )格式为每个像素保留 Y 分量,而 UV 分量在水平方向上每 4 个像素采样一次。一个宏像素为 12 个字节,实际表示 8 个像素。图像数据中 YUV 分量排列顺序如下:
U0 Y0 V0 Y1 U4 Y2 V4 Y3 Y4 Y5 Y6 Y8 …
Y211 格式在水平方向上 Y 分量每 2 个像素采样一次,而 UV 分量每 4 个像素采样一次。一个宏像素为 4 个字节,实际表示 4 个像素。图像数据中 YUV 分量排列顺序如下:
Y0 U0 Y2 V0 Y4 U4 Y6 V4 …
YVU9 格式为每个像素都提取 Y 分量,而在 UV 分量的提取时,首先将图像分成若干个 4 x 4 的宏块,然后每个宏块提取一个 U 分量和一个 V 分量。图像数据存储时,首先是整幅图像的 Y 分量数组,然后就跟着 U 分量数组,以及 V 分量数组。 IF09 格式与 YVU9 类似。
IYUV 格式为每个像素都提取 Y 分量,而在 UV 分量的提取时,首先将图像分成若干个 2 x 2 的宏块,然后每个宏块提取一个 U 分量和一个 V 分量。 YV12 格式与 IYUV 类似。
YUV411 、 YUV420 格式多见于 DV 数据中,前者用于 NTSC 制,后者用于 PAL 制。 YUV411 为每个像素都提取 Y 分量,而 UV 分量在水平方向上每 4 个像素采样一次。 YUV420 并非 V 分量采样为 0 ,而是跟YUV411 相比,在水平方向上提高一倍色差采样频率,在垂直方向上以 U/V 间隔的方式减小一半色差采样
- YUV和RGB转换
计算机彩色显示器显示色彩的原理与彩色电视机一样,都是采用R(Red)、G(Green)、B(Blue)
相加混色的原理:
通过发射出三种不同强度的电子束,使屏幕内侧覆盖的红、绿、蓝磷光材料发光而产生色彩。这种色彩的表示方法称为RGB色彩空间表示(它也是多媒体计算机技术中用得最多的一种色彩空间表示方法)。
根据三基色原理,任意一种色光F都可以用不同分量的R、G、B三色相加混合而成。
F = r [ R ] + g [ G ] + b [ B ]
其中,r、g、b分别为三基色参与混合的系数。当三基色分量都为0(最弱)时混合为黑色光;而当三基色分量都为k(最强)时混合为白色光。调整r、g、b三个系数的值,可以混合出介于黑色光和白色光之间的各种各样的色光。
那么YUV又从何而来呢?
在现代彩色电视系统中,通常采用三管彩色摄像机或彩色CCD摄像机进行摄像,然后把摄得的彩色图像信号经分色、分别放大校正后得到 RGB,再经过矩阵变换电路得到亮度信号Y和两个色差信号R-Y(即U)、B-Y(即V),最后发送端将亮度和色差三个信号分别进行编码,用同一信道发送出去。这种色彩的表示方法就是所谓的YUV色彩空间表示。
采用YUV色彩空间的重要性是它的亮度信号Y和色度信号U、V是分离的。如果只有Y信号分量而没有U、V分量,那么这样表示的图像就是黑白灰度图像。彩色电视采用YUV空间正是为了用亮度信号Y解决彩色电视机与黑白电视机的兼容问题,使黑白电视机也能接收彩色电视信号。
YUV与RGB相互转换的公式
如下(RGB取值范围均为0-255):
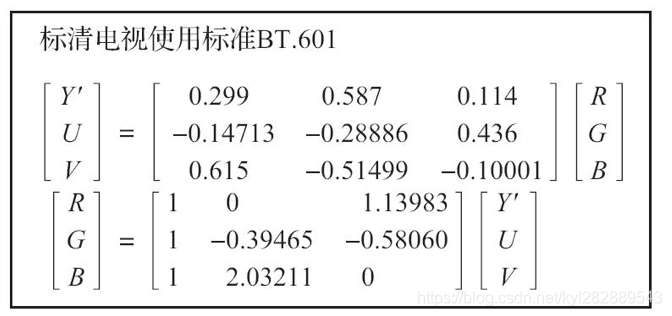
下面代码使用“BT.601标准"
Y = 0.299R + 0.587G + 0.114B
U = -0.147R - 0.289G + 0.436B
V = 0.615R - 0.515G - 0.100B
R = Y + 1.14V
G = Y - 0.39U - 0.58V
B = Y + 2.03U
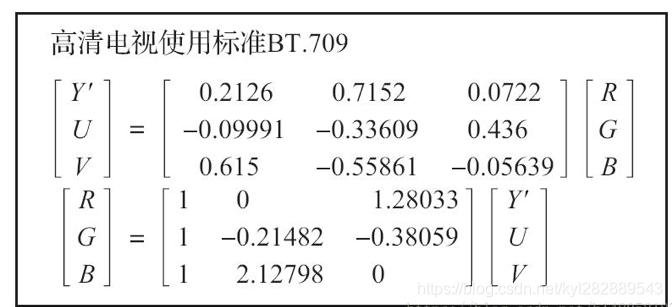
公式在不同电视使用标准是不同的
RGB->YUV
C语言代码如下:
Y = 0.299R + 0.587G + 0.114B
Cb = 0.564(B − Y )
Cr = 0.713(R − Y )
代码:
uint8_t COL_RgbToYuv(uint8_t R,uint8_t G,uint8_t B, uint8_t *y,int8_t *u,int8_t *v)
{
float rr=R,bb=B,gg=G;
float yy,uu,vv;
yy=0.299*rr+ 0.587*gg+ 0.114*bb;
uu=-0.169*rr+ -0.331*gg+ 0.5*bb;
vv=0.5*rr+ -0.419*gg+ -0.081*bb;
if(uu>127) uu=127;
if(uu<-127) uu=-127;
*u=(int8_t)floor(uu);
if(vv>127) vv=127;
if(vv<-127) vv=-127;
*v=(int8_t)floor(vv);
if(yy>255) yy=255;
if(yy<0) yy=0;
*y=(uint8_t)floor(yy);
return 1;
}
YUV->RGB
c 语言代码如下:
R = Y + 1.402Cr
G = Y − 0.344Cb − 0.714Cr
B = Y + 1.772Cb
代码:
uint8_t COL_YuvToRgb( uint8_t y,int8_t u,int8_t v,uint8_t *r,uint8_t *g,uint8_t *b)
{
float rr,bb,gg;
float yy=y,uu=u,vv=v;
rr= yy+ 1.402*vv;
gg= yy+ -0.344*uu+ -0.714*vv;
bb= yy+ 1.772*uu ;
#define CLIP(x) if(x>255) x=255; else if (x<0) x=0;x=x+0.49;
#define CVT(x,y) CLIP(x);*y=(uint8_t)floor(x);
CVT(rr,r);
CVT(gg,g);
CVT(bb,b);
return 1;
}
- 常用的YUV,RGB格式
在DirectShow 中,常见的RGB格式有RGB1、RGB4、RGB8、RGB565、RGB555、RGB24、RGB32、ARGB32等;常见的YUV格式有 YUY2、YUYV、YVYU、UYVY、AYUV、Y41P、Y411、Y211、IF09、IYUV、YV12、YVU9、YUV411、 YUV420等。作为视频媒体类型的辅助说明类型(Subtype)。
| 名称 | 格式 | 表示 | 是否需要调色板 |
|---|---|---|---|
| MEDIASUBTYPE_RGB1 | 2色, | 每个像素用1位表示, | 需要调色板 |
| MEDIASUBTYPE_RGB4 | 16色, | 每个像素用4位表示, | 需要调色板 |
| MEDIASUBTYPE_RGB8 | 256色, | 每个像素用8位表示, | 需要调色板 |
| MEDIASUBTYPE_RGB565 | 每个像素用16位表示, | RGB分量分别使用5位、6位、5位 | |
| MEDIASUBTYPE_RGB555 | 每个像素用16位表示, | RGB分量都使用5位(剩下的1位不用) | |
| MEDIASUBTYPE_RGB24 | 每个像素用24位表示, | RGB分量各使用8位 | |
| MEDIASUBTYPE_RGB32 | 每个像素用32位表示, | RGB分量各使用8位(剩下的8位不用) | |
| MEDIASUBTYPE_ARGB32 | 每个像素用32位表示, | RGB分量各使用8位(剩下的8位用于表示Alpha通道值) | |
| MEDIASUBTYPE_YUY2 | YUY2格式, | 以4:2:2方式打包 | |
| MEDIASUBTYPE_YUYV | YUYV格式 | (实际格式与YUY2相同) | |
| MEDIASUBTYPE_YVYU | YVYU格式, | 以4:2:2方式打包 | |
| MEDIASUBTYPE_UYVY | UYVY格式 | ,以4:2:2方式打包 | |
| MEDIASUBTYPE_AYUV | 带Alpha通道的4:4:4 YUV格式 | ||
| MEDIASUBTYPE_Y41P | Y41P格式, | 以4:1:1方式打包 | |
| MEDIASUBTYPE_Y411 | Y411格式 | (实际格式与Y41P相同) | |
| MEDIASUBTYPE_Y211 | Y211格式 | ||
| MEDIASUBTYPE_IF09 | IF09格式 | ||
| MEDIASUBTYPE_IYUV | IYUV格式 | ||
| MEDIASUBTYPE_YV12 | YV12格式 | ||
| MEDIASUBTYPE_YVU9 | YVU9格式 |
- 各种RGB格式
¨ RGB1、RGB4、RGB8都是调色板类型的RGB格式,在描述这些媒体类型的格式细节时,通常会在BITMAPINFOHEADER数据结构后面跟着一个调色板(定义一系列颜色)。它们的图像数据并不是真正的颜色值,而是当前像素颜色值在调色板中的索引。以RGB1(2色位图)为例,比如它的调色板中定义的两种颜色值依次为0x000000(黑色)和0xFFFFFF(白色),那么图像数据001101010111…(每个像素用1位表示)表示对应各像素的颜色为:黑黑白白黑白黑白黑白白白…。
¨ RGB565使用16位表示一个像素,这16位中的5位用于R,6位用于G,5位用于B。程序中通常使用一个字(WORD,一个字等于两个字节)来操作一个像素。当读出一个像素后,这个字的各个位意义如下:
高字节 低字节
R R R R R G G G G G G B B B B B
可以组合使用屏蔽字和移位操作来得到RGB各分量的值:
#define RGB565_MASK_RED 0xF800
#define RGB565_MASK_GREEN 0x07E0
#define RGB565_MASK_BLUE 0x001F
R = (wPixel & RGB565_MASK_RED) >> 11; // 取值范围0-31
G = (wPixel & RGB565_MASK_GREEN) >> 5; // 取值范围0-63
B = wPixel & RGB565_MASK_BLUE; // 取值范围0-31
¨ RGB555是另一种16位的RGB格式,RGB分量都用5位表示(剩下的1位不用)。使用一个字读出一个像素后,这个字的各个位意义如下:
高字节 低字节
X R R R R G G G G G B B B B B (X表示不用,可以忽略)
可以组合使用屏蔽字和移位操作来得到RGB各分量的值:
#define RGB555_MASK_RED 0x7C00
#define RGB555_MASK_GREEN 0x03E0
#define RGB555_MASK_BLUE 0x001F
R = (wPixel & RGB555_MASK_RED) >> 10; // 取值范围0-31
G = (wPixel & RGB555_MASK_GREEN) >> 5; // 取值范围0-31
B = wPixel & RGB555_MASK_BLUE; // 取值范围0-31
RGB24使用24位来表示一个像素,RGB分量都用8位表示,取值范围为0-255。注意在内存中RGB各分量的排列顺序为:BGR BGR BGR…。通常可以使用RGBTRIPLE数据结构来操作一个像素,它的定义为:
typedef struct tagRGBTRIPLE {
BYTE rgbtBlue; // 蓝色分量
BYTE rgbtGreen; // 绿色分量
BYTE rgbtRed; // 红色分量
} RGBTRIPLE;
¨ RGB32使用32位来表示一个像素,RGB分量各用去8位,剩下的8位用作Alpha通道或者不用。(ARGB32就是带Alpha通道的 RGB32。)注意在内存中RGB各分量的排列顺序为:BGRA BGRA BGRA…。通常可以使用RGBQUAD数据结构来操作一个像素,它的定义为:
typedef struct tagRGBQUAD {
BYTE rgbBlue; // 蓝色分量
BYTE rgbGreen; // 绿色分量
BYTE rgbRed; // 红色分量
BYTE rgbReserved; // 保留字节(用作Alpha通道或忽略)
} RGBQUAD;
1.1.2 音视频常见处理
采集
- 为什么要采集数据
无论是iOS平台,还是安卓平台,我们都是需要借助官方的API实现一系列相关功能.首先我们要明白我们想要什么,最开始我们需要一部手机,智能手机中摄像头是不可缺少的一部分,所以我们通过一些系统API获取就要可以获取物理摄像头将采集到的视频数据与麦克风采集到的音频数据.
- 如何采集数据
首先要对模拟信号进行采样,所谓采样就是在时间轴上对信号进行数字化。根据奈奎斯特定理(也称为采样定理),按比声音最高频率高2倍以上的频率对声音进行采样(也称为AD转换),1.1节中提到过,对于高质量的音频信号,其频率范围(人耳能够听到的频率范围)是20Hz~20kHz,所以采样频率一般为44.1kHz,这样就可以保证采样声音达到20kHz也能被数字化,从而使得经过数字化处理之后,人耳听到的声音质量不会被降低。而所谓的44.1kHz就是代表1秒会采样44100次
量化:
量化是指在幅度轴上对信号进行数字化,比如用16比特的二进制信号来表示声音的一个采样,而16比特(一个short)所表示的范围是[-32768,32767],共有65536个可能取值,因此最终模拟的音频信号在幅度上也分为了65536层。
编码:所谓编码,就是按照一定的格式记录采样和量化后的数字数据,比如顺序存储或压缩存储,等等。
音频的裸数据格式就是脉冲编码调制(Pulse Code Modulation,PCM)数据。描述一段PCM数据一般需要以下几个概念:量化格式(sampleFormat)、采样率(sampleRate)、声道数(channel)。以CD的音质为例:量化格式(有的地方描述为位深度)为16比特(2字节),采样率为44100,声道数为2,这些信息就描述了CD的音质。而对于声音格式,还有一个概念用来描述它的大小,称为数据比特率,即1秒时间内的比特数目,它用于衡量音频数据单位时间内的容量大小。而对于CD音质的数据,比特率为多少呢?计算如下:
44100 * 16 * 2 = 1378.125kbps
那么在1分钟里,这类CD音质的数据需要占据多大的存储空间呢?计算如下:
1378.125 * 60 / 8 / 1024 = 10.09MB
如果sampleFormat更加精确(比如用4字节来描述一个采样),或者sampleRate更加密集(比如48kHz的采样率),那么所占的存储空间就会更大,同时能够描述的声音细节就会越精确。
音频采集:
音频数据既能与图像结合组合成视频数据,也能以纯音频的方式采集播放,后者在很多成熟的应用场景如在线电台和语音电台等起着非常重要的作用。音频的采集过程主要通过设备将环境中的模拟信号采集成 PCM 编码的原始数据,然后编码压缩成 MP3 等格式的数据分发出去。常见的音频压缩格式有:MP3,AAC,HE-AAC,Opus,FLAC,Vorbis (Ogg),Speex 和 AMR等。
音频采集和编码主要面临的挑战在于:延时敏感、卡顿敏感、噪声消除(Denoise)、回声消除(AEC)、静音检测(VAD)和各种混音算法等。
图像采集:
将图像采集的图片结果组合成一组连续播放的动画,即构成视频中可肉眼观看的内容。图像的采集过程主要由摄像头等设备拍摄成 YUV 编码的原始数据,然后经过编码压缩成 H.264 等格式的数据分发出去。常见的视频封装格式有:MP4、3GP、AVI、MKV、WMV、MPG、VOB、FLV、SWF、MOV、RMVB 和 WebM 等。
图像由于其直观感受最强并且体积也比较大,构成了一个视频内容的主要部分。图像采集和编码面临的主要挑战在于:设备兼容性差、延时敏感、卡顿敏感以及各种对图像的处理操作如美颜和水印等。
视频采集:
摄像头采集
屏幕录制
从视频文件推流
- 注意点
处理
- 常见的数据处理
音频和视频原始数据本质都是一大段数据,系统将其包装进自定义的结构体中,通常都以回调函数形式提供给我们,拿到音视频数据后,可以根据各自项目需求做一系列特殊处理,如: 视频的旋转,缩放,滤镜,美颜,裁剪等等功能, 音频的单声道降噪,消除回声,静音等等功能.

-
数据处理工具
-
注意点
编码
- 为什么要编码数据
原始数据做完自定义处理后就可以进行传输,像直播这样的功能就是把采集好的视频数据发送给服务器,以在网页端供所有粉丝观看,而传输由于本身就是基于网络环境,庞大的原始数据就必须压缩后才能带走,可以理解为我们搬家要将物品都打包到行李箱这样理解.
原始视频数据存储空间大,一个 1080P 的 7 s 视频需要 817 MB
原始视频数据传输占用带宽大,10 Mbps 的带宽传输上述 7 s 视频需要 11 分钟
而经过 H.264 编码压缩之后,视频大小只有 708 k ,10 Mbps 的带宽仅仅需要 500 ms ,可以满足实时传输的需求,所以从视频采集传感器采集来的原始视频势必要经过视频编码。
- 编码原理
为什么巨大的原始视频可以编码成很小的视频呢?这其中的技术是什么呢?核心思想就是去除冗余信息:
1)空间冗余:图像相邻像素之间有较强的相关性
2)时间冗余:视频序列的相邻图像之间内容相似
3)编码冗余:不同像素值出现的概率不同
4)视觉冗余:人的视觉系统对某些细节不敏感
5)知识冗余:规律性的结构可由先验知识和背景知识得到 - 常用编码工具
视频编码器:
1)H.264/AVC
2)HEVC/H.265
3)VP8
4)VP9
5)FFmpeg - 音频编码:
WAV
Mp3
AAC
G711
G726
Ogg
CD音质的数据采样格式,曾计算出每分钟需要的存储空间约为10.1MB,如果仅仅是将其存放在存储设备(光盘、硬盘)中,可能是可以接受的,但是若要在网络中实时在线传播的话,那么这个数据量可能就太大了,所以必须对其进行压缩编码。压缩编码的基本指标之一就是压缩比,压缩比通常小于1(否则就没有必要去做压缩,因为压缩就是要减小数据容量)。压缩算法包括有损压缩和无损压缩。无损压缩是指解压后的数据可以完全复原。在常用的压缩格式中,用得较多的是有损压缩,有损压缩是指解压后的数据不能完全复原,会丢失一部分信息,压缩比越小,丢失的信息就越多,信号还原后的失真就会越大。根据不同的应用场景(包括存储设备、传输网络环境、播放设备等),可以选用不同的压缩编码算法,如PCM、WAV、AAC、MP3、Ogg等。
压缩编码的原理实际上是压缩掉冗余信号,冗余信号是指不能被人耳感知到的信号,包含人耳听觉范围之外的音频信号以及被掩蔽的音频信号等。人耳听觉范围之外的音频信号在1.2节中已经提到过,所以在此不再赘述。而被掩蔽掉的音频信号则主要是因为人耳的掩蔽效应,主要表现为频域掩蔽效应与时域掩蔽效应,无论是在时域还是频域上,被掩蔽掉的声音信号都被认为是冗余信息,不进行编码处理。
(1)WAV编码
PCM(脉冲编码调制)是Pulse Code Modulation的缩写。前面已经介绍过PCM大致的工作流程,而WAV编码的一种实现(有多种实现方式,但是都不会进行压缩操作)就是在PCM数据格式的前面加上44字节,分别用来描述PCM的采样率、声道数、数据格式等信息。
特点:音质非常好,大量软件都支持。
适用场合:多媒体开发的中间文件、保存音乐和音效素材。
(2)MP3编码
MP3具有不错的压缩比,使用LAME编码(MP3编码格式的一种实现)的中高码率的MP3文件,听感上非常接近源WAV文件,当然在不同的应用场景下,应该调整合适的参数以达到最好的效果。
特点:音质在128Kbit/s以上表现还不错,压缩比比较高,大量软件和硬件都支持,兼容性好。
适用场合:高比特率下对兼容性有要求的音乐欣赏。
(3)AAC编码
AAC是新一代的音频有损压缩技术,它通过一些附加的编码技术(比如PS、SBR等),衍生出了LC-AAC、HE-AAC、HE-AAC v2三种主要的编码格式。LC-AAC是比较传统的AAC,相对而言,其主要应用于中高码率场景的编码(≥80Kbit/s);HE-AAC(相当于AAC+SBR)主要应用于中低码率场景的编码(≤80Kbit/s);而新近推出的HE-AAC v2(相当于AAC+SBR+PS)主要应用于低码率场景的编码(≤48Kbit/s)。事实上大部分编码器都设置为≤48Kbit/s自动启用PS技术,而>48Kbit/s则不加PS,相当于普通的HE-AAC。
特点:在小于128Kbit/s的码率下表现优异,并且多用于视频中的音频编码。
适用场合:128Kbit/s以下的音频编码,多用于视频中音频轨的编码。
(4)Ogg编码
Ogg是一种非常有潜力的编码,在各种码率下都有t匕较优秀的表现,尤其是在中低码率场景下。Ogg除了音质好之外,还是完
全免费的,这为Ogg获得更多的支持打好了基础》Ogg有着非常出色的算法,可以用更小的码率达到更好的音质,l28Kbit/s的Ogg比192Kbit/s甚至更高码率的MP3还要出色。但目前因为还没有媒体服务软件的支持,因此基于Ogg的数字广播还无法实现。Ogg目前受支持的情况还不够好,无论是软件上的还是硬件上的支持,都无法和MP3相提并论。
特点:可以用比MP3更小的码率实现比MP3更好的音质,高中低码率下均有良好的表现,兼容性不够好,流媒体特性不支持。
适用场合:语音聊天的音频消息场景。
-
视频编码
-
IOS平台编码方式
iOS上编解码分为两种,硬编解码和软编解码,可以参考下表:
| 类型 | 工具 | 硬件支持 | 后台 | 思路 | 备注 |
|---|---|---|---|---|---|
| 硬编解码 | VideoToolBox | 非CPU或者专用处理器 | 编码(iOS>=10.0),解码不支持 | VideoVTToolBox | - |
| 硬编解码 | AVAssetWriter | 非CPU或者专用处理器 | 支持编码 | 需要将视频写入本地文件,然后通过实时监听文件内容的改变,读取文件并处理封包 | - |
| 软编解码 | FFmpeg | CPU | 支持 | - | - |
-
常用编码算法
-
注意点
传输
- 常用的传输协议
编码后的音视频数据通常以RTMP协议进行传输,这是一种专门用于传输音视频的协议,因为各种各样的视频数据格式无法统一,所以需要有一个标准作为传输的规则.协议就起到这样的作用.
常用传输协议:RTMP, FTP, TCP/IP, HTTP, XMMP
常用数据封装:json, xml,
-
传输数据过程
-
常用工具
-
注意点
解码
- 为什么要解码数据
服务端接收到我们送过去的编码数据后,需要对其解码成原始数据,因为编码的数据直接送给物理硬件的设备是不能直接播放的,只有解码为原始数据才能使用.
-
常用解码算法
-
常用解码工具
- H264/H265裸码流提取工具
工具下载地址:https://download.csdn.net/download/listener51/10952502
源码下载地址:https://github.com/fermay/open_media_demux
码流拖曳到软件中显示如下:

2.
-
解码原理
-
注意点
渲染
常用音频编码格式
常用视频编码格式
常用编解码算法
视频音频同步算法
- 音视频同步需求
解码后的每帧音视频中都含有最开始录制时候设置的时间戳,我们需要根据时间戳将它们正确的播放出来,但是在网络传输中可能会丢失一些数据,或者是延时获取,这时我们就需要一定的策略去实现音视频的同步,大体分为几种策略:缓存一定视频数据,视频追音频等等.
-
常用音视频同步算法
-
音视频处理工具
-
注意点
录像
音频播放
视频播放
Android常用的播放本地视频方式:
1). 系统自带API方式
2)VLC+FFmpeg 方式
3)SDL+FFmpeg 方式
4)Vitamio以及ijkplayer等
Qt常用的播放本地视频方式:
1). 系统自带API方式
2)VLC+FFmpeg 方式
3)SDL+FFmpeg 方式
-
远程视频播放
-
直播
1.2 直播
1.2.1 推流
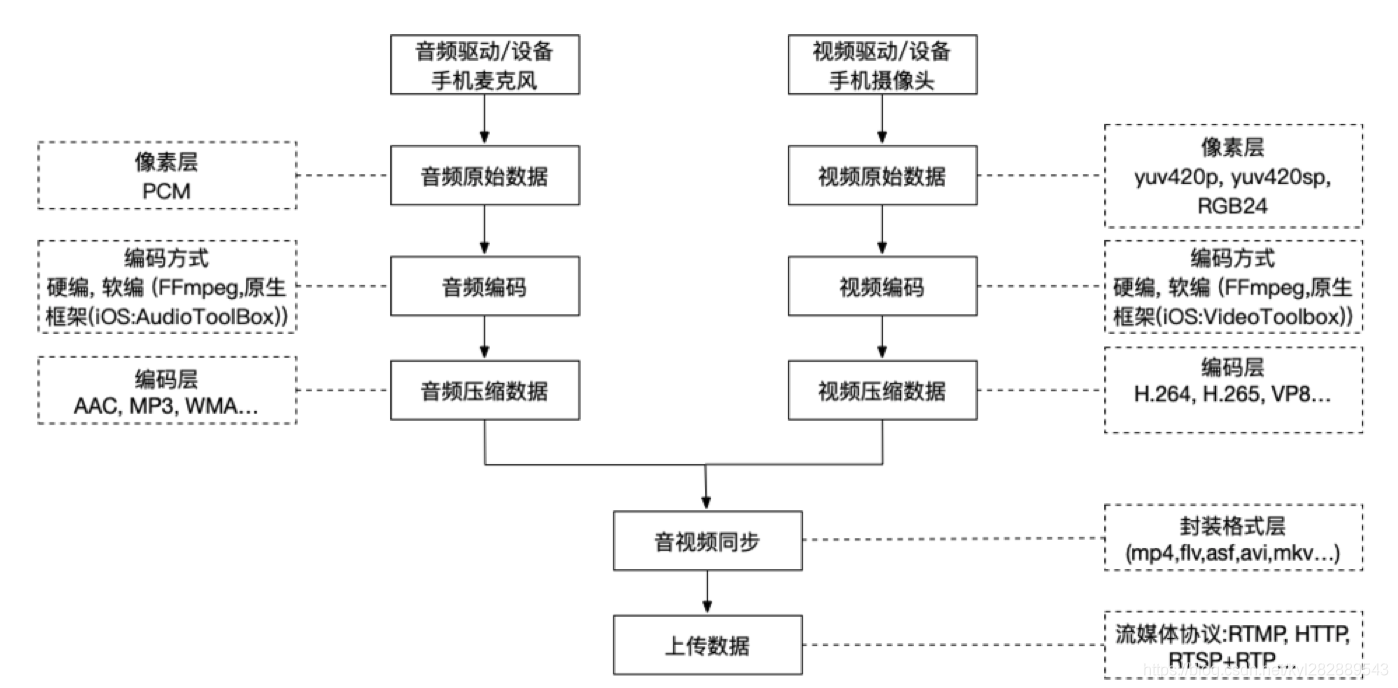
将手机采集到的视频数据传给后台播放端进行展示,播放端可以是windows, linux, web端,即手机充当采集的功能,将手机摄像头采集到视频和麦克风采集到的音频合成编码后传给对应平台的播放端。
流程图如下:
1.2.1.1 推流常用协议简介
推送协议主要有三种:
- RTSP(Real Time Streaming Protocol):实时流传送协议,是用来控制声音或影像的多媒体串流协议, 由Real Networks和Netscape共同提出的;
- RTMP(Real Time Messaging Protocol):实时消息传送协议,是Adobe公司为Flash播放器和服务器之间音频、视频和数据传输 开发的开放协议;
- HLS(HTTP Live Streaming):是苹果公司(Apple Inc.)实现的基于HTTP的流媒体传输协议;
-
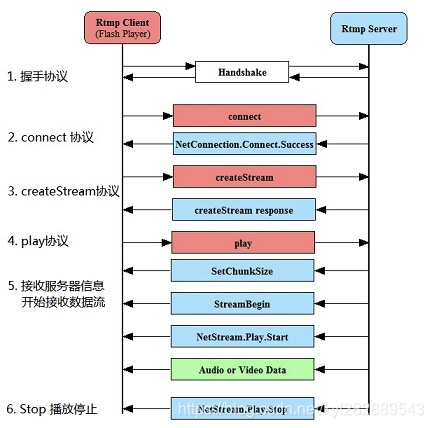
RTMP 协议
RTMP协议基于 TCP,是一种设计用来进行实时数据通信的网络协议,主要用来在 flash/AIR 平台和支持 RTMP 协议的流媒体/交互服务器之间进行音视频和数据通信。支持该协议的软件包括 Adobe Media Server/Ultrant Media Server/red5 等。
它有三种变种:
- RTMP工作在TCP之上的明文协议,使用端口1935;
- RTMPT封装在HTTP请求之中,可穿越防火墙;
- RTMPS类似RTMPT,但使用的是HTTPS连接;
RTMP 是目前主流的流媒体传输协议,广泛用于直播领域,可以说市面上绝大多数的直播产品都采用了这个协议。
RTMP协议就像一个用来装数据包的容器,这些数据可以是AMF格式的数据,也可以是FLV中的视/音频数据。一个单一的连接可以通过不同的通道传输多路网络流。这些通道中的包都是按照固定大小的包传输的。
大致流程图如下:
- HLS协议
1.2.2 拉流
将播放端传来的视频数据在手机上播放,推流的逆过程,即将windows, linux, web端传来的视频数据进行解码后传给对应音视频硬件,最终将视频渲染在手机界面上播放.
流程图如下:
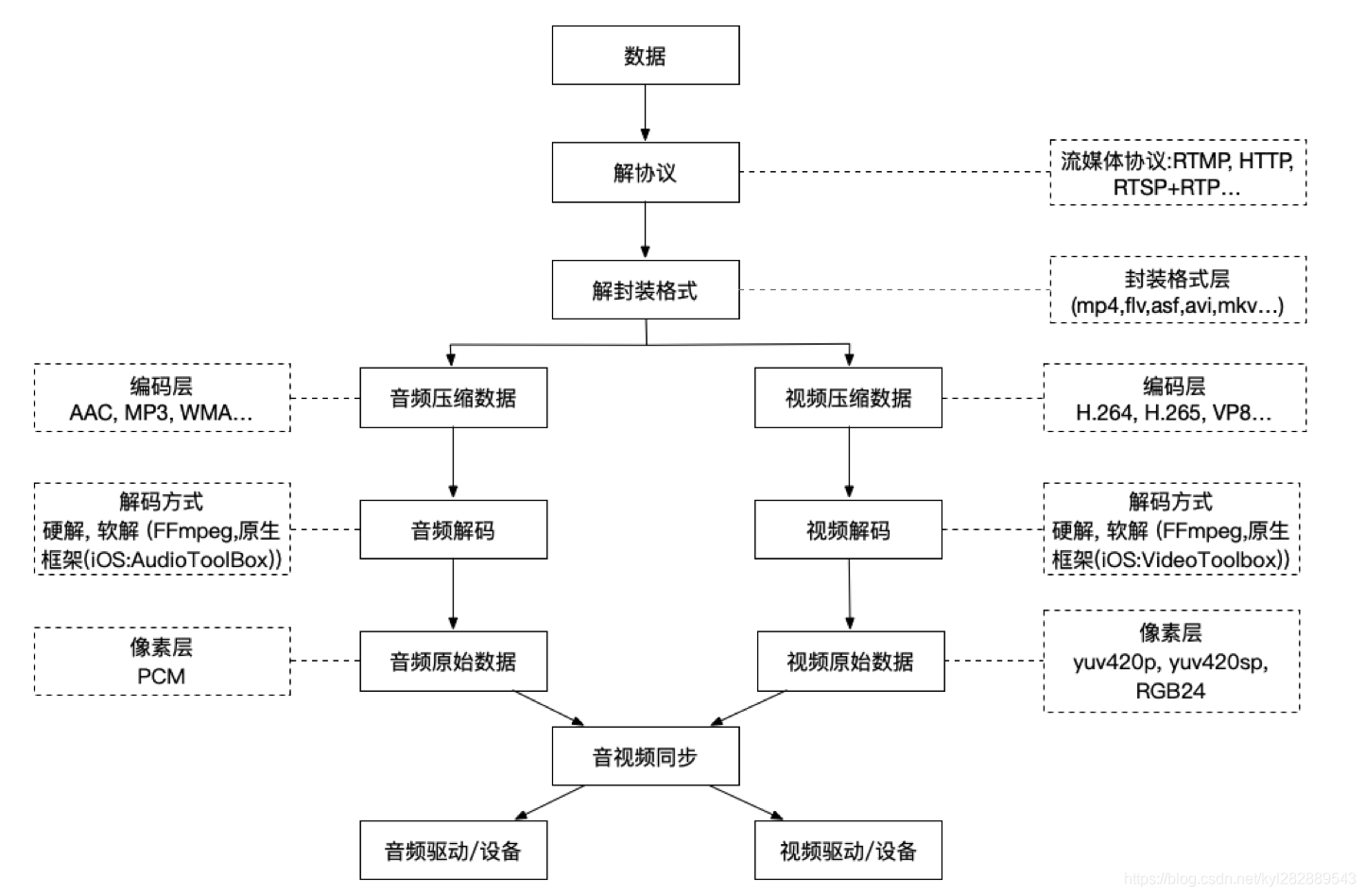
1.3. FFmpeg简介
FFmpeg 是一个自由软件,可以运行音频和视频多种格式的录影、转换、流功能,包含了libavcodec——这是一个用于多个项目中音频和视频的解码器库,以及libavformat——一个音频与视频格式转换库。
“FFmpeg”这个单词中的“FF”指的是“Fast Forward(快速前进)”。有些新手写信给“FFmpeg”的项目负责人,询问FF是不是代表“Fast Free”或者“Fast Fourier”等意思,“FFmpeg”的项目负责人回信说:“Just for the record, the original meaning of “FF” in FFmpeg is “Fast Forward”…”
这个项目最初是由Fabrice Bellard发起的,而现在是由Michael Niedermayer在进行维护。许多FFmpeg的开发者同时也是MPlayer项目的成员,FFmpeg在MPlayer项目中是被设计为服务器版本进行开发。
2011年3月13日,FFmpeg部分开发人士决定另组Libav,同时制定了一套关于项目继续发展和维护的规则
更多详情参考维基百科:FFmpeg简介
- 常用库
| 库名 | 用途 |
|---|---|
| ffmpeg | 一个命令行工具,用来对视频文件转换格式,也支持对电视卡即时编码 |
| ffserver | 一个HTTP多媒体即时广播流服务器,支持时光平移 |
| ffplay | 一个简单的播放器,基于SDL与FFmpeg库 |
| libavcodec | 包含全部FFmpeg音频/视频编解码库 |
| libavformat | 包含demuxers和muxer库 |
| libavutil | 包含一些工具库 |
| libpostproc | 对于视频做前处理的库 |
| libavutil | 包含一些工具库 |
| libswscale | 对于影像作缩放的库 |
- 主要参数
| 参数名 | 意义 |
|---|---|
| -i | 设置输入档名。 |
| -f | 设置输出格式。 |
| -y | 若输出文件已存在时则覆盖文件。 |
| -fs | 超过指定的文件大小时则结束转换。 |
| -ss | 从指定时间开始转换。 |
| -t | 从-ss时间开始转换(如-ss 00:00:01.00 -t 00:00:10.00即从00:00:01.00开始到00:00:11.00)。 |
| -title | 设置标题。 |
| -timestamp | 设置时间戳。 |
| -vsync | 增减Frame使影音同步。 |
| -c | 指定输出文件的编码。 |
| -metadata | 更改输出文件的元数据。 |
| -help | 查看帮助信息。 |
| 视频参数名 | 意义 |
|---|---|
| b:v | 设置视频流量,默认为200Kbit/秒。(单位请引用下方注意事项) |
| r | 设置帧率值,默认为25。 |
| s | 设置画面的宽与高。 |
| aspect | 设置画面的比例。 |
| vn | 不处理视频,于仅针对声音做处理时使用。 |
| vcodec( -c:v ) | 设置视频视频编解码器,未设置时则使用与输入文件相同之编解码器。 |
| 声音参数名 | 意义 |
|---|---|
| b:a | 设置每Channel(最近的SVN版为所有Channel的总合)的流量。(单位请引用下方注意事项) |
| ar | 设置采样率。 |
| ac | 设置声音的Channel数。 |
| acodec ( -c:a ) | 设置声音编解码器,未设置时与视频相同,使用与输入文件相同之编解码器。 |
| an | 不处理声音,于仅针对视频做处理时使用。 |
| vol | 设置音量大小,256为标准音量。(要设置成两倍音量时则输入512,依此类推。) |
- 查看 FFmpeg官方文档
- 查看h265的数据的基本信息
ffmpeg -i /Users/tomxiang/Desktop/h265/test_tomxiang.h265
- 用libx265转mp4.
ffmpeg -i /Users/tomxiang/Desktop/test_tomxiang.h265 -c:v libx265 /Users/tomxiang/xxtest/test265.mp4
- ffplay逐帧播放视频与显示视频帧序号
macOS下使用ffplay,按下s键可单帧播放视频,配合一个显示文字的视频滤镜即可显示当前画面的帧序号,命令示例如下所示:
ffplay -vf "drawtext=fontfile=/Library/Fonts/Arial.ttf:text=%{n}:box=1:x=(w-tw)/2:y=h-(2*lh)" sample.mp4
音视频专家博客收集:














 2880
2880











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









