







基于MOOC人工智能之模式识别的课程完成的第四次作业
MATLAB实现贝叶斯算法(MNIST数据集)
MOOC地址:人工智能之模式识别
贝叶斯方法是统计模式识别理论中最基础的一种方法,它通过样本的先验概率和条件概率计算后验概率,以此来判断在条件
生时,某结果发生的概率大小。
贝叶斯分类器的基础是贝叶斯公式。
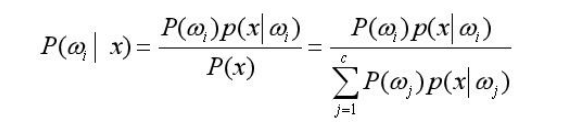
它的分类决策规则是:依据计算得到的后验概率对样本进行归类,而需要的条件是:先验概率和类条件概率已知。
因此,只要知道先验概率 P(ωj),类条件概率密度 p(x/ωj) 就可以设计出一个贝叶斯分类器。
而 P(ωj)、p(x/ωj)并不能预先知道,需要利用训练样本集的信息去进行估计。所以,贝叶斯分类器的训练,就是从样本集中估计出先验概率和类条件概率。
 Matlab 已经有贝叶斯模型相关函数,我们只需输入训练样本和相应的标签数据就可以训练得到分类器。
Matlab 已经有贝叶斯模型相关函数,我们只需输入训练样本和相应的标签数据就可以训练得到分类器。
data_proc.m 是对图像数据的预处理函数,主要是为了解决训练样本特征空间中有的列向量全部为零,这样在计算后验概率时会出现分母为零的情况。
% data_proc.m
% 函数功能:删除同类数据特征中方差为0的特征列
% 输入:行向量数据及标签
% 输出:删除列之后的数据以及删除的列标
function [output,position] = data_proc(data,label)
position = cell(1,10);
%创建cell存储每类中删除的列标
for i = 0:9
temp = [];
pos = [];
for rows = 1:size(data,1)
if label(rows)==i
temp = [temp;data(rows,:)];
end
end
for cols = 1:size(temp,2)
var_data = var(temp(:,cols));
if var_data==0
pos = [pos,cols];
end
end
position{i+1} = pos;
data(:,pos)=[];
end
output = data;
end
Bayesian.m 程序代码主要实现了数据集读入,贝叶斯分类器训练,测试及结果输出几个部分。
%Bayesian.m
clear
clc
load ('../test_images.mat');
load ('../test_labels.mat');
load ('../train_images.mat');
load ('../train_labels.mat');
train_num = 2000;
test_num = 200;
%训练数据
data_train = mat2vector(train_images(:,:,1:train_num),train_num);
%图像转向量
data_test = mat2vector(test_images(:,:,1:test_num),test_num);
% 这里对数据进行一次处理。贝叶斯分类器要求输入数据中同类别中一个特征的方差不能为0
% 由公式我们可以知道,计算后验概率时,如果某一列特征全部相同,那么后验概率计算时分母会变为0,
% 为了避免该种情况,需要对数据进行提前处理
[data_train,position] = data_proc(data_train,train_labels1(1:train_num)');
% 对训练数据进行处理后,同时也要对测试数据进行同样的处理
for rows = 1:10
data_test(:,position{1,rows})=[];
end
%模型部分
% 超参数全部取了默认值,比较重要的,如类别的先验概率,如果不进行修改,则计算输入数据中类别的频率
% 查看nb_model即可确认所使用的超参数
nb_model = fitcnb(data_train,train_labels1(1:train_num));
%训练模型
%测试结果
result = predict(nb_model,data_test);
result = result.';
fprintf('预测结果:');
result(1:20)
%取20个打印出来对比
fprintf('真实分布:');
test_labels1(1:20)
% 整体正确率
acc = 0.;
for i = 1:test_num
if result(i)==test_labels1(i)
acc = acc+1;
end
end
fprintf('精确度为:%5.2f%%\n',(acc/test_num)*100);
通过改变训练样本的数量,分类器识别精度也会随之改变,但他们的关系并不是单调的。
















 1004
1004











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









