







目录
任务描述
给定金融数据,预测贷款用户是否会逾期。(status是标签:0表示未逾期,1表示逾期。)
Misson1 - 构建逻辑回归模型进行预测
Misson2 - 构建SVM和决策树模型进行预测
Misson3 - 构建xgboost和lightgbm模型进行预测
Mission4 - 记录五个模型关于precision,rescore,f1,auc,roc的评分表格,画出auc和roc曲线图
Mission5 - 关于数据类型转换以及缺失值处理(尝试不同的填充看效果)以及你能借鉴的数据探索
Mission6 - 使用网格搜索对模型进行调优并采用五折交叉验证的方式进行模型评估
Mission7 - 用你目前评分最高的模型作为基准模型,和其他模型进行stacking融合,得到最终模型及评分
Mission8 - 分别用IV值和随机森林挑选特征,再构建模型,进行模型评估
特征工程
由于特征工程比较浩大,所以新开一文章用以记录
1. 删除无用变量
首先剔除一些明显无用的特征,如 id_name, custid, trade_no, bank_card_no,
这些变量类似一个人的唯一信息,如果加入模型训练且对最终模型生效的话,很可能就是出现了过拟合
X.drop(['id_name', 'custid', 'trade_no', 'bank_card_no'], axis=1, inplace=True)2. 特征类型划分
数值型特征
取出数值型特征,观察缺失及分布情况
# 取出数值型变量
X_num = X.select_dtypes('number').copy()
# 查看缺失情况
num_miss_rate = 1 - X_num.count() / len(X_num)
num_miss_rate.sort_values(ascending=False, inplace=True)
print(num_miss_rate[:10])
num_miss_rate.plot()
# 观察数据分布
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
for i, col in enumerate(X_num.columns[:5]):
plt.figure(i + 1, figsize=(10, 5))
# # 密度分布图
# sns.distplot(X_num[col][y==1].dropna(), hist=True, kde=True)
# sns.distplot(X_num[col][y==0].dropna(), hist=True, kde=True)
# 分箱图
# sns.boxplot(y=X_num[col], x=y)
# 小提琴图
sns.violinplot(y=X_num[col], x=y)

首先,对数据进行缺失值填充。因为 student_feature 缺失值较多,使用0值填充;对于其他变量,分别尝试使用 均值、中位数 填充。一般情况下,选择用中位数填充可以较少极端值的影响。
当然,也可以使用模型填充的方法,这一点相对复杂,往后再进行讨论。
# student_feature
X_num.fillna({'student_feature': 0}, inplace=True)
# 其他数值型变量使用统计量填充
# X_num.fillna(X_num.mean(), inplace=True) # 均值
X_num.fillna(X_num.median(), inplace=True) # 中位数从图像可以看出,数据中含有极端值的比较多,可使用 IQR 方法对极端值进行处理。也就是说,分别使用 Q3 + 1.5IQR和 Q1 - 1.5IQR 对上下极端值进行修正。
# 极端值处理函数
def iqr_outlier(x, thre=1.5):
x_cl = x.copy()
q25, q75 = x.quantile(q=[0.25, 0.75])
iqr = q75 - q25
top = q75 + thre * iqr
bottom = q25 - thre * iqr
x_cl[x_cl > top] = top
x_cl[x_cl < bottom] = bottom
return x_cl
# 对进行缺失值填充后的数据集进行极端值修正
X_num_cl = pd.DataFrame()
for col in X_num.columns:
X_num_cl[col] = iqr_outlier(X_num[col])
X_num = X_num_cl字符型特征
取出字符型变量,观察缺失及分布情况
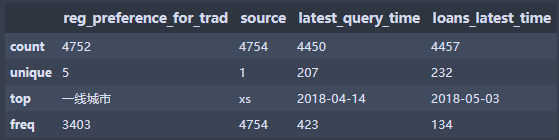
由上面得出结论:
1. source只有一个值,无意义可剔除。
2. reg_preference_for_trad表示城市类型,仅有两个缺失,用众数填充后分别使用 哑变量 或 编码 的形式进行数据装换
3. latest_query_time,loans_latest_time 数据日期型,在下一步再进行操作
下面对 reg_preference_for_trad 进行处理:
# 众数填充
X_str['reg_preference_for_trad'] = X_str['reg_preference_for_trad'].fillna(X_str['reg_preference_for_trad'].mode()[0])
# 哑变量
X_str_dummy = pd.get_dummies(X_str['reg_preference_for_trad'])
# 数字编码
X_str_map = X_str['reg_preference_for_trad'].map({'一线城市': 0, '二线城市': 1,'三线城市': 2, '其他城市': 3, '境外': 4})日期/时间型特征
这类特征可以做如下变换:
1. 取出日期,可分别构建如 年、月、日、工作日、周数 等;
2. 如有时间,可分别构建如 小时、分钟 等;
3. 两两日期或时间可根据业务知识相互做差,求出相差天数,小时数等(此处先跳过,偷懒了,哈哈)
X_date = pd.DataFrame()
X_date['latest_query_time_month'] = pd.to_datetime(X_str['latest_query_time']).dt.month # 月份
X_date['latest_query_time_weekday'] = pd.to_datetime(X_str['latest_query_time']).dt.weekday # 星期几
X_date['loans_latest_time_month'] = pd.to_datetime(X_str['loans_latest_time']).dt.month # 月份
X_date['loans_latest_time_weekday'] = pd.to_datetime(X_str['loans_latest_time']).dt.weekday # 星期几
X_date.fillna(X_date.median(), inplace=True)特征合并
合并各类特征
X_cl = pd.concat([X_num, X_str_dummy, X_date], axis=1, sort=False)
X_cl.shape
(4754, 89)3. 特征衍生
略略略
4. 特征筛选
4.1 使用 IV 值进行筛选
IV 值是判断特征重要性的一种常用方法
# 计算 IV 函数
def cal_iv(x, y, n_bins=6, null_value=np.nan,):
# 剔除空值
x = x[x != null_value]
# 若 x 只有一个值,返回 0
if len(x.unique()) == 1 or len(x) != len(y):
return 0
if x.dtype == np.number:
# 数值型变量
if x.nunique() > n_bins:
# 若 nunique 大于箱数,进行分箱
x = pd.qcut(x, q=n_bins, duplicates='drop')
# 计算IV
groups = x.groupby([x, list(y)]).size().unstack().fillna(0)
t0, t1 = y.value_counts().index
groups = groups / groups.sum()
not_zero_index = (groups[t0] > 0) & (groups[t1] > 0)
groups['iv_i'] = (groups[t0] - groups[t1]) * np.log(groups[t0] / groups[t1])
iv = sum(groups['iv_i'])
return iv得出每个特征的 iv 后,筛选出高于 0.01 的特征
# 统计每个特征对应的 iv 值
fea_iv = X_cl.apply(lambda x: cal_iv(x, y), axis=0).sort_values(ascending=False)
# 筛选 IV > 0.1 的特征
imp_fea_iv = fea_iv[fea_iv > 0.05].index
imp_fea_iv选出来特征如下:
'trans_fail_top_count_enum_last_1_month', 'history_fail_fee', 'loans_score', 'apply_score', 'loans_overdue_count', 'trans_fail_top_count_enum_last_12_month', 'latest_one_month_fail', 'trans_fail_top_count_enum_last_6_month', 'latest_one_month_suc', 'rank_trad_1_month', 'max_cumulative_consume_later_1_month', 'trans_day_last_12_month', 'top_trans_count_last_1_month', 'consfin_avg_limit', 'pawns_auctions_trusts_consume_last_1_month'
4.2 使用 随机森林 进行筛选
构建随机森林,使用其中的 特征重要性(feature_importances_) 对特征进行打分,选出最高的 15个特征
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier()
rf.fit(X_cl, y)
rf_impc = pd.Series(rf.feature_importances_, index=X_cl.columns).sort_values(ascending=False)
# 筛选 重要性前十五 个特征
imp_fea_rf = rf_impc.index[:15]选出来特征如下:
'trans_fail_top_count_enum_last_1_month', 'history_fail_fee', 'apply_score', 'loans_score', 'latest_one_month_fail', 'trans_fail_top_count_enum_last_6_month', 'loans_overdue_count', 'max_cumulative_consume_later_1_month', 'trans_amount_3_month', 'avg_price_last_12_month', 'historical_trans_amount', 'loans_latest_day', 'repayment_capability', 'first_transaction_day', 'trans_days_interval_filter'
4.3 合并特征
将上面方法特出的特征进行合并,取并集
# 合并特征并筛选出有用特征
imp_fea = list(set(imp_fea_iv) | set(imp_fea_rf))
X_imp = X_cl[imp_fea]
X_imp.shape
(4754, 22)性能评估
1. 在完成 Mission5 后,评估各模型效果,发现各模型 auc 均有 0.5% - 1% 的提升。预计接下来的处理会对模型结果产生更大的影响。
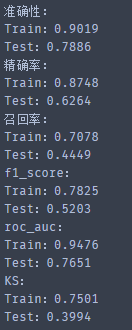
2. 完成Mission8后,结合前面的模型融合,最终得分如下,AUC提升 0.003:

参考
1. 数据可视化:https://www.cnblogs.com/jin-liang/p/9011771.html
More
代码参见 Github:https://github.com/LongJH/ALittleTarget/tree/master/Mission1















 2847
2847











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









