







Special Applications: Face Recognition & Neural Style Transfer
- Face verification and face recognition are the two most common names given to the task of comparing a new picture against one person’s face. True/False?
- False
- True
- You want to build a system that receives a person’s face picture and determines if the person is inside a workgroup. You have pictures of all the faces of the people currently in the workgroup, but some members might leave, and some new members might be added. Which of the following do you agree with?
- It is best to build a convolutional neural network with a softmax output with as many outputs as members of the group.
- This can be considered a one-shot learning task.
解释: Since we might have only one example of the person we want to recognize.
- It will be more efficient to learn a function d(img1,img2) for this task.
解释:Since this is a one-shot learning task this function will allow us to compare two images to verify identity.
- This can’t be considered a one-shot learning task since there might be many members in the workgroup.
- You want to build a system that receives a person’s face picture and determines if the person is inside a workgroup. You have pictures of all the faces of the people currently in the workgroup, but some members might leave, and some new members might be added. To train a system to solve this problem using the triplet loss you must collect pictures of different faces from only the current members of the team. True/False?
- False
- True
解释:Although it is necessary to have several pictures of the same person, it is not absolutely necessary that all the pictures only come from current members of the team.
- Which of the following is a correct definition of the triplet loss? Consider that α > 0 \alpha>0 α>0. (We encourage you to figure out the answer from first principles, rather than just refer to the lecture.)
- max ( ∥ f ( A ) − f ( P ) ∥ 2 − ∥ f ( A ) − f ( N ) ∥ 2 − α , 0 ) \max (\left \| f(A)-f(P) \right \|^{2} - \left \| f(A)-f(N) \right \|^{2} - \alpha ,0) max(∥f(A)−f(P)∥2−∥f(A)−f(N)∥2−α,0)
- max ( ∥ f ( A ) − f ( P ) ∥ 2 − ∥ f ( A ) − f ( N ) ∥ 2 + α , 0 ) \max (\left \| f(A)-f(P) \right \|^{2} - \left \| f(A)-f(N) \right \|^{2} + \alpha ,0) max(∥f(A)−f(P)∥2−∥f(A)−f(N)∥2+α,0)
- max ( ∥ f ( A ) − f ( N ) ∥ 2 − ∥ f ( A ) − f ( P ) ∥ 2 + α , 0 ) \max (\left \| f(A)-f(N) \right \|^{2} - \left \| f(A)-f(P) \right \|^{2} + \alpha ,0) max(∥f(A)−f(N)∥2−∥f(A)−f(P)∥2+α,0)
- max ( ∥ f ( A ) − f ( N ) ∥ 2 − ∥ f ( A ) − f ( P ) ∥ 2 − α , 0 ) \max (\left \| f(A)-f(N) \right \|^{2} - \left \| f(A)-f(P) \right \|^{2} - \alpha ,0) max(∥f(A)−f(N)∥2−∥f(A)−f(P)∥2−α,0)
- Consider the following Siamese network architecture:
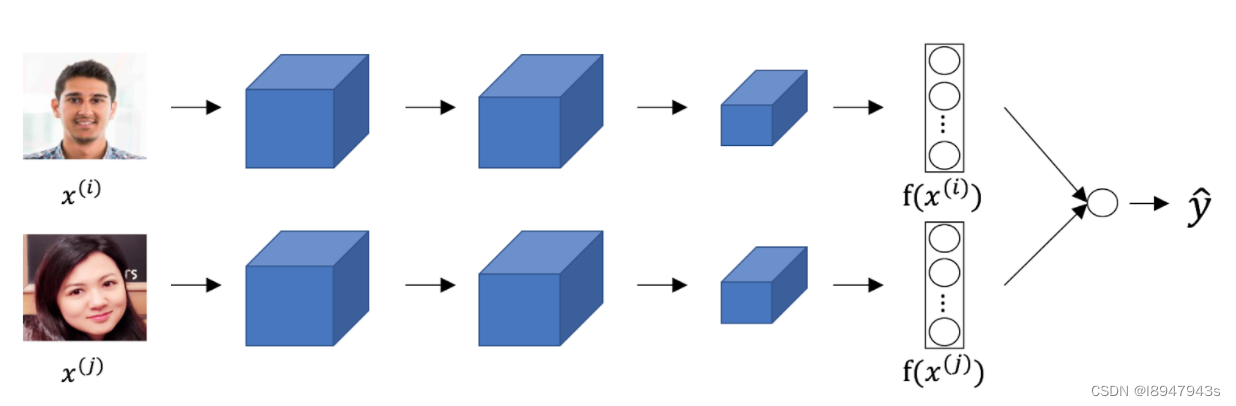
The upper and lower networks share parameters to have a consistent encoding for both images. True/False?
- False
- True
解释:Part of the idea behind the Siamese network is to compare the encoding of the images, thus they must be consistent.
- Our intuition about the layers of a neural network tells us that units that respond more to complex features are more likely to be in deeper layers. True/False?
- False
- True
解释:Neurons that understand more complex shapes are more likely to be in deeper layers of a neural network.
- Neural style transfer uses images Content C, Style S. The loss function used to generate image G is composed of which of the following: (Choose all that apply.)
- J c o n t e n t Jcontent Jcontent that compares C C C and G G G.
解释:in neural style transfer we are interested in the similarity between S and G, and the similarity between G and C.
- J s t y l e Jstyle Jstyle that compares S and G.
解释:Correct, in neural style transfer we are interested in the similarity between S and G, and the similarity between G and C.
- J c o r r Jcorr Jcorr that compares C and S.
- T T T that calculates the triplet loss between S, G, and C.
- In neural style transfer, we define style as:
- The correlation between the activation of the content image C and the style image S.
- ∥ a [ l ] ( S ) − a [ l ] ( G ) ∥ 2 \left \| a^{[l](S)} - a^{[l](G)} \right \| ^2 ∥ ∥a[l](S)−a[l](G)∥ ∥2 the distance between the activation of the style image and the content image.
- The correlation between the generated image G and the style image S.
- The correlation between activations across channels of an image
- In neural style transfer, we can’t use gradient descent since there are no trainable parameters. True/False?
- False
- True
- You are working with 3D data. The input “image” has size 32 × 32 × 32 × 3 32\times32\times32\times3 32×32×32×3, if you apply a convolutional layer with 16 filters of size 4 × \times × 4 × \times × 4, zero padding and stride 1. What is the size of the output volume?
- 29×29×29×16
- 29×29×29×13
- 29×29×29×3
- 31×31×31×16
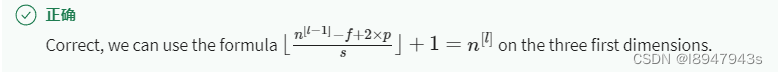















 220
220











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











