







台大李宏毅机器学习课程之BERT记录
0 前言
本文是对台大李宏毅老师机器学习课程BERT部分的记录,视频链接如下:
自监督式学习(二)-BERT简介
1 总结
1)BERT是自监督的学习,不需要人工标注的标签,所以其实也是无监督学习的一种方式
2)BERT的主干网络就是tranformer的encoder部分,所以BERT使用了self-attention的机制
3)BERT主要采用完形填空的方式。就是输入一句话,随机遮住某个词,然后预测遮住的词。这种方式其实很好的考虑了上下文,或者说就是基于上下文的语境来表示词的意思。实验证明这种方式得到了一种很好的embedding的方式
4)BERT可以很好的用于下游任务
2 正文
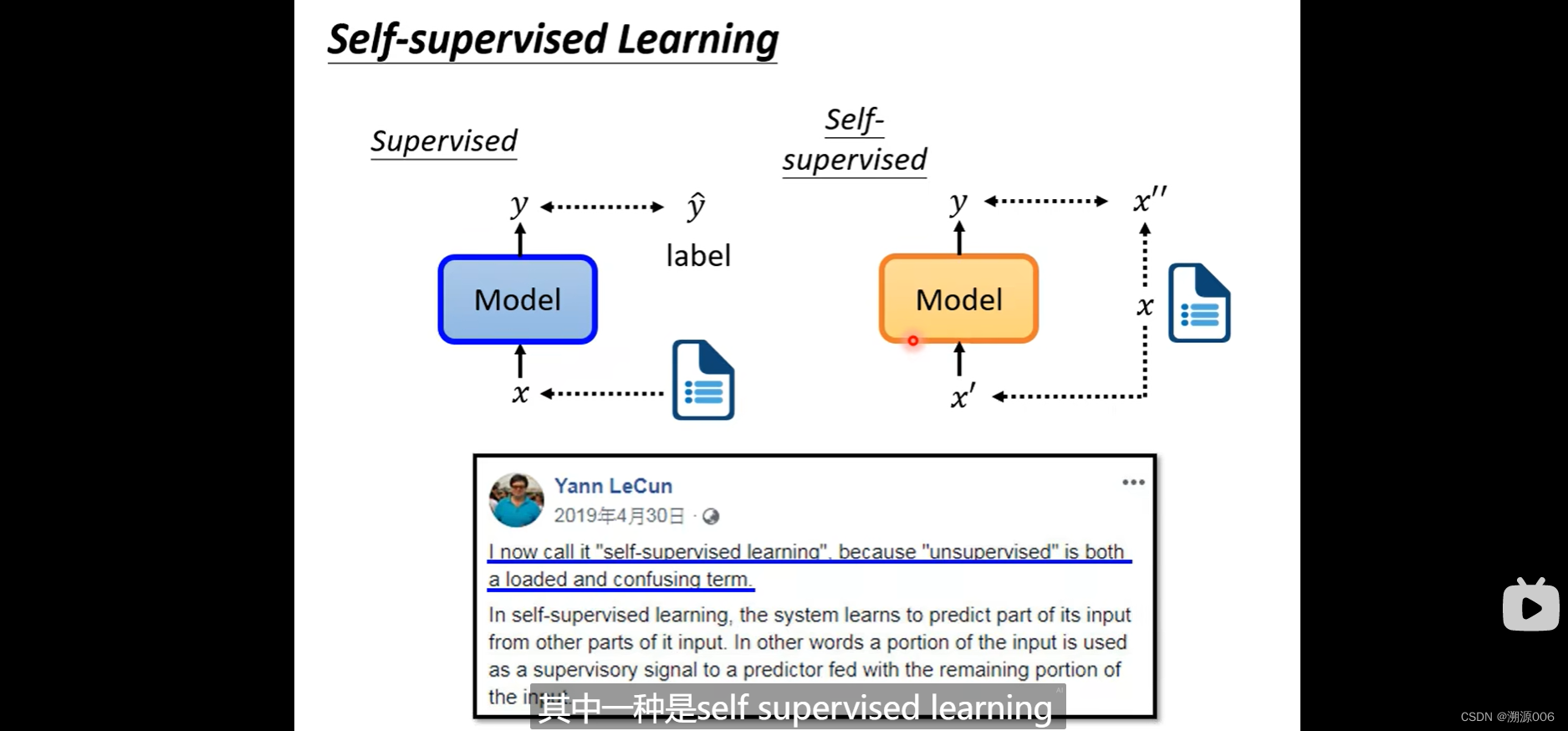
有监督的学习比较常见,需要训练数据有标签
y
^
\hat{y}
y^,然后损失函数的目标是让模型的预测
y
y
y与标签
y
^
\hat{y}
y^尽可能的接近,这些标签需要人工去标注,也就是说监督学习的监督信号来自于人工。而自监督模型的监督信号
x
′
′
x''
x′′完全来自己已有的数据(所以自监督学习的代理任务就是要从已有数据中构造监督信号),所以叫自监督。显然,自监督学习是无监督学习的一种。
transformer的encoder就是BERT的网络的构架。输入一排向量,输出一排向量,输入多长就输出多长。一排向量可以是文字,可以是语音,甚至是图像。这里以文字为例。 有两种训练方式,如下:
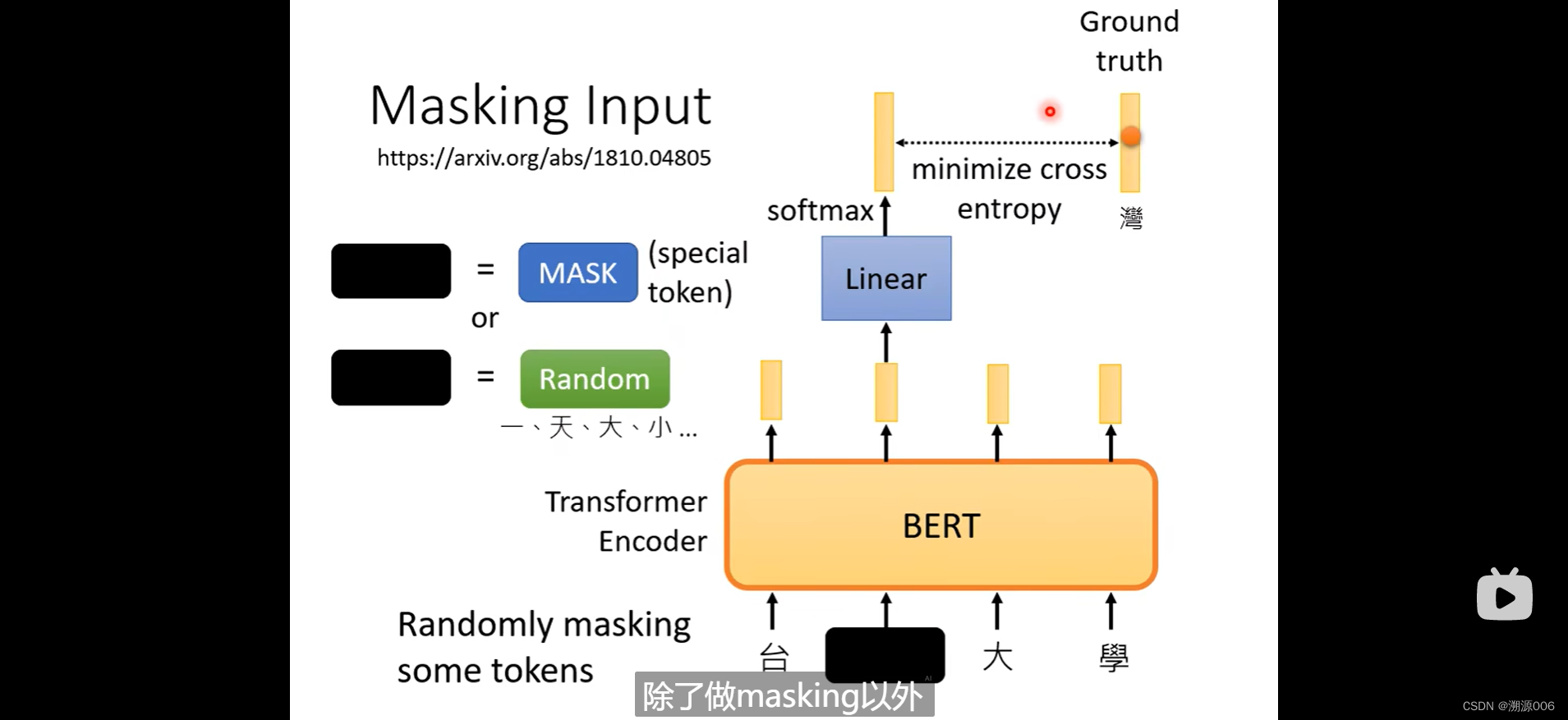
2.1 masking
首先,对输入进行随机的mask。这个随机的mask有两种做法。一种就是把要盖住的token换成一个特殊的符号(这个特殊的符号和其他符号不一样,可以认为就是表示mask)。另外一种就是随机换成其他token。这两种方法都可以用,甚至是合起来用,随机决定用哪一种。
BERT输出一排向量,然后对盖住的向量对应的输出向量进行线性变换,然后做softmax,得到一个输出的分布(如下图所示,是在一个vocabulary上的分布,每个字对应一个分数)。目标就是让这个分布与ground truth的one-hot向量尽量接近。本质上是在做一个分类,类别数目是vocabulary的size。对盖住的向量做分类预测。训练的时候BERT与后面的线性变换层一起训练。

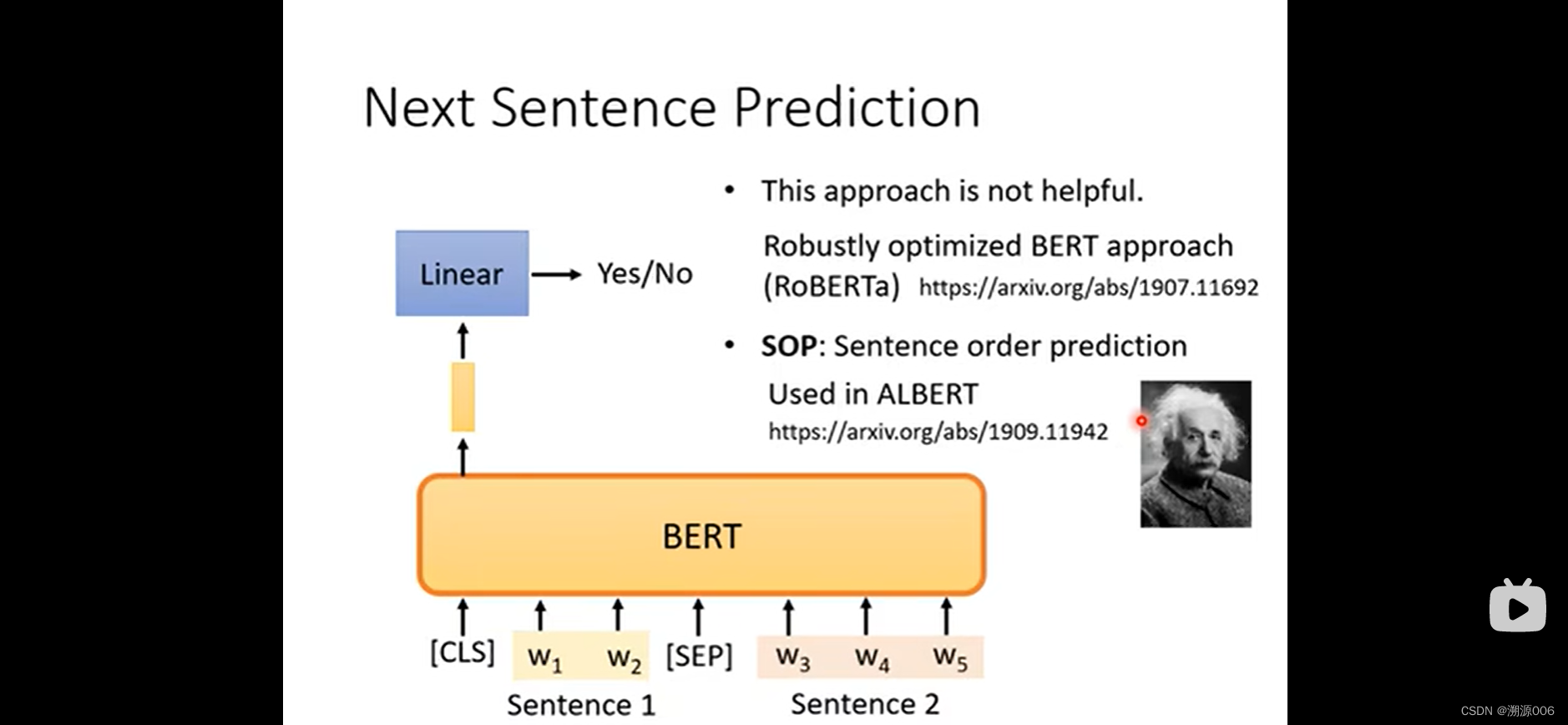
2.2 Next sentence prediction
2.3 BERT 的使用方式(下游任务,微调)
预测两个句子是否应该被接在一起。
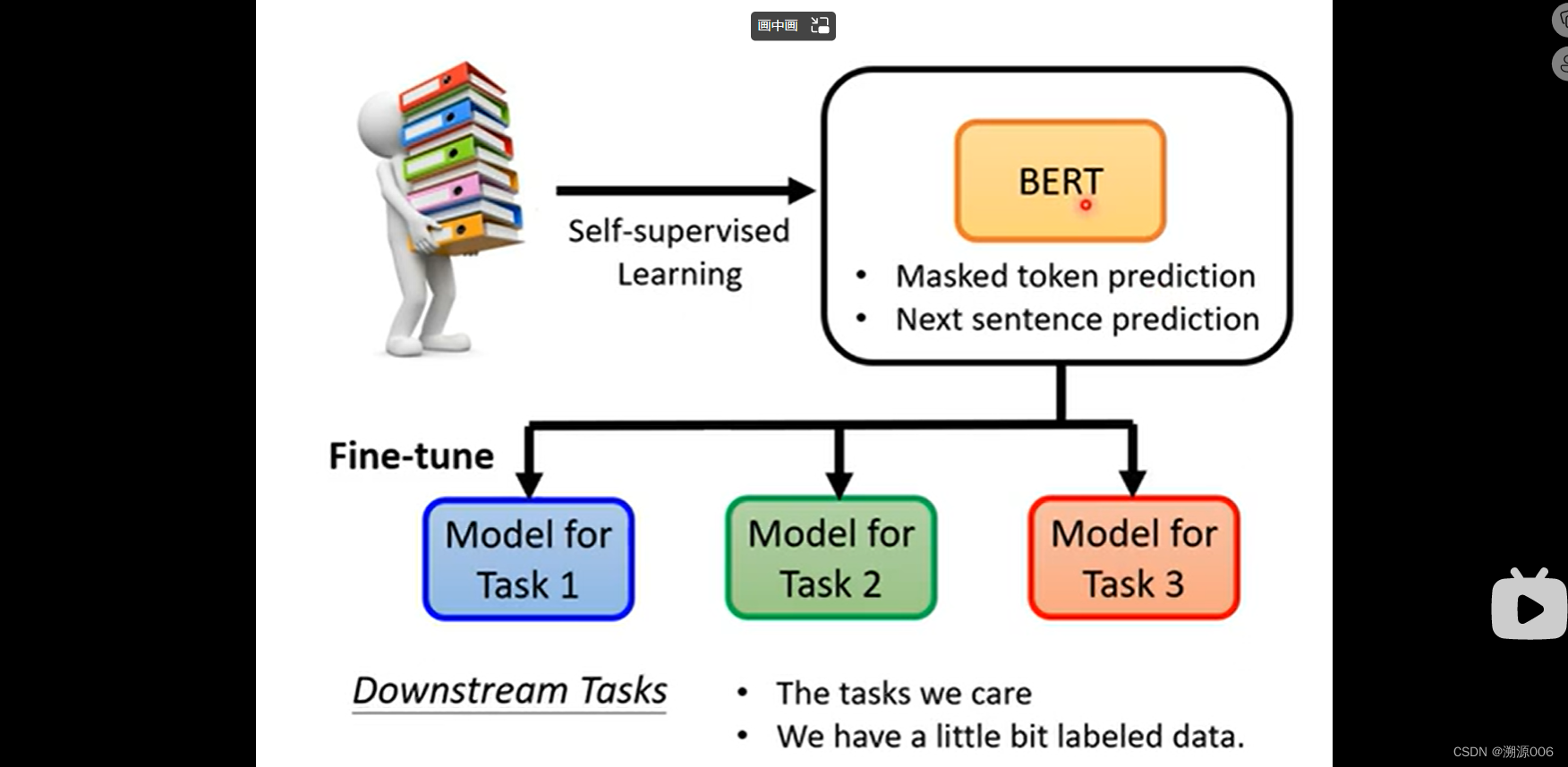
BERT的主要功能是可以针对不同的下游任务做微调,用到不同的任务上。训练BERT的过程是预训练,训练下游任务的过程是fine-tune
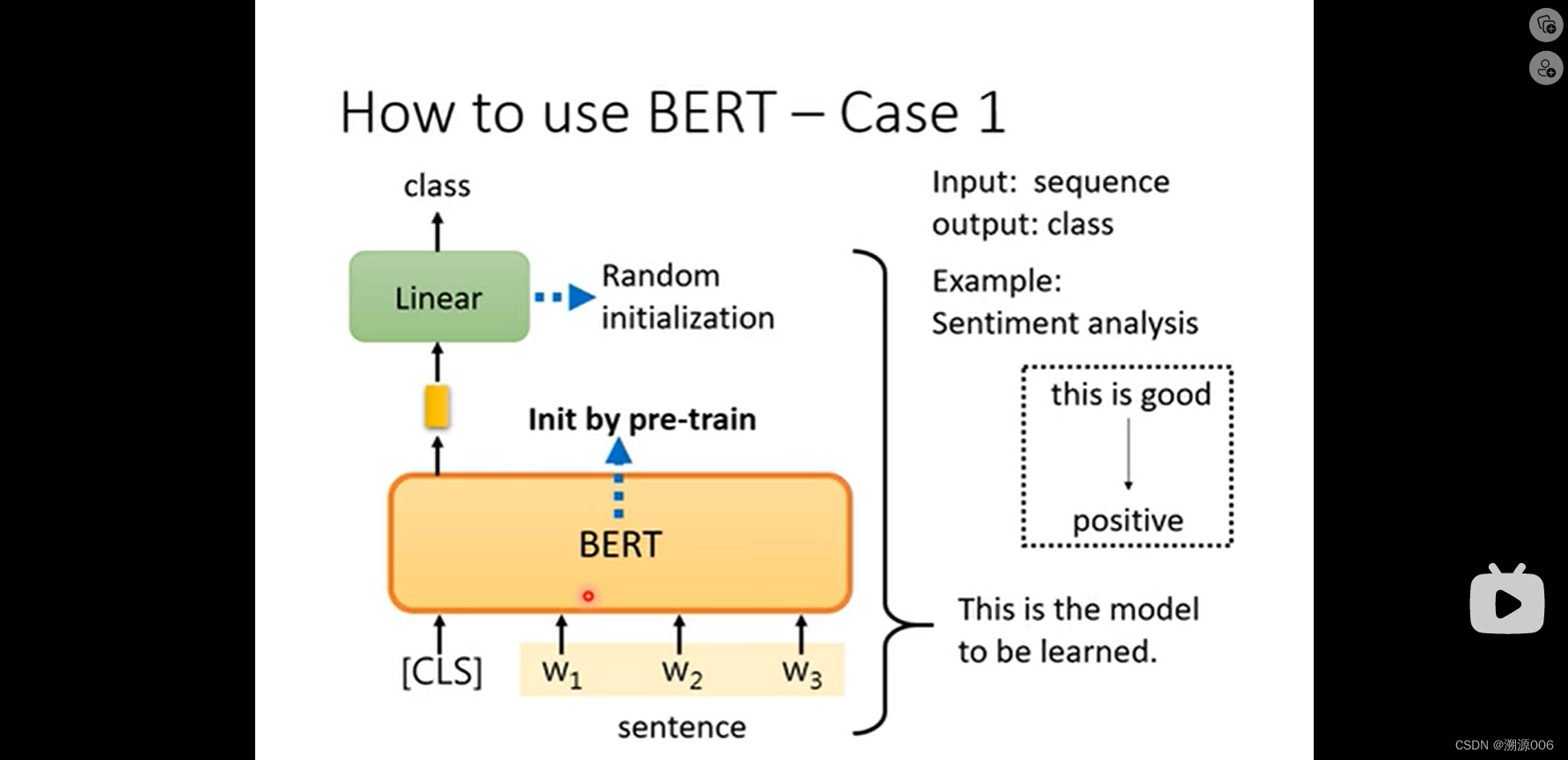
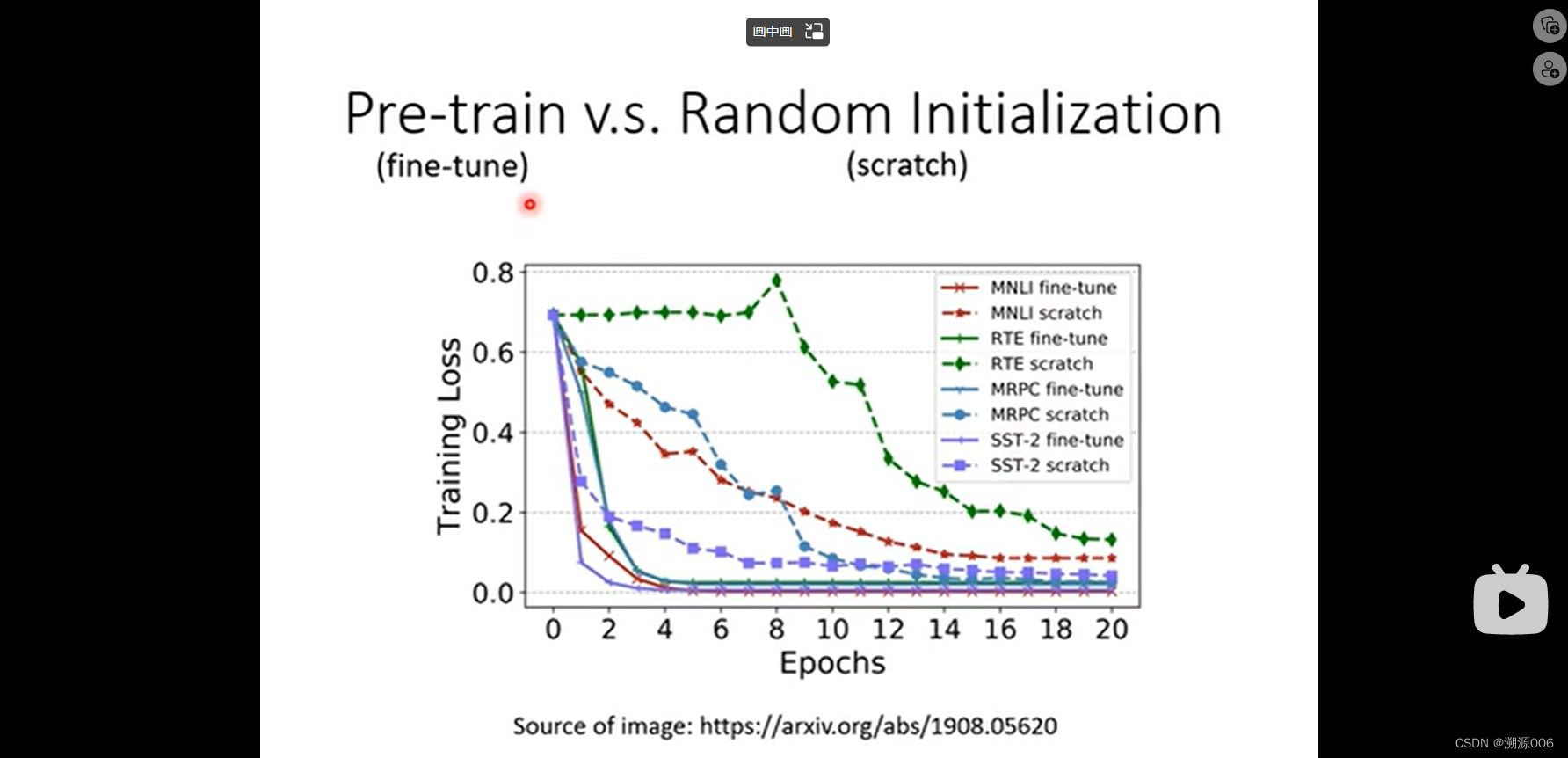
Case1是句子分析,输入时句子序列,输出是类别。这个时候把[CLS]+句子作为BERT输入,然后BERT产生同样多的向量,把[CLS]对应的输出向量接linear层然后输出预测类别。其中的linear层是随机初始化,BERT是采用预训练的参数。在fine-tune的过程中整个模型同时训练。原因是。用预训练的BERT参数性能比随机初始化要好。具体即使收敛的更快,loss也更小。具体可见下图:
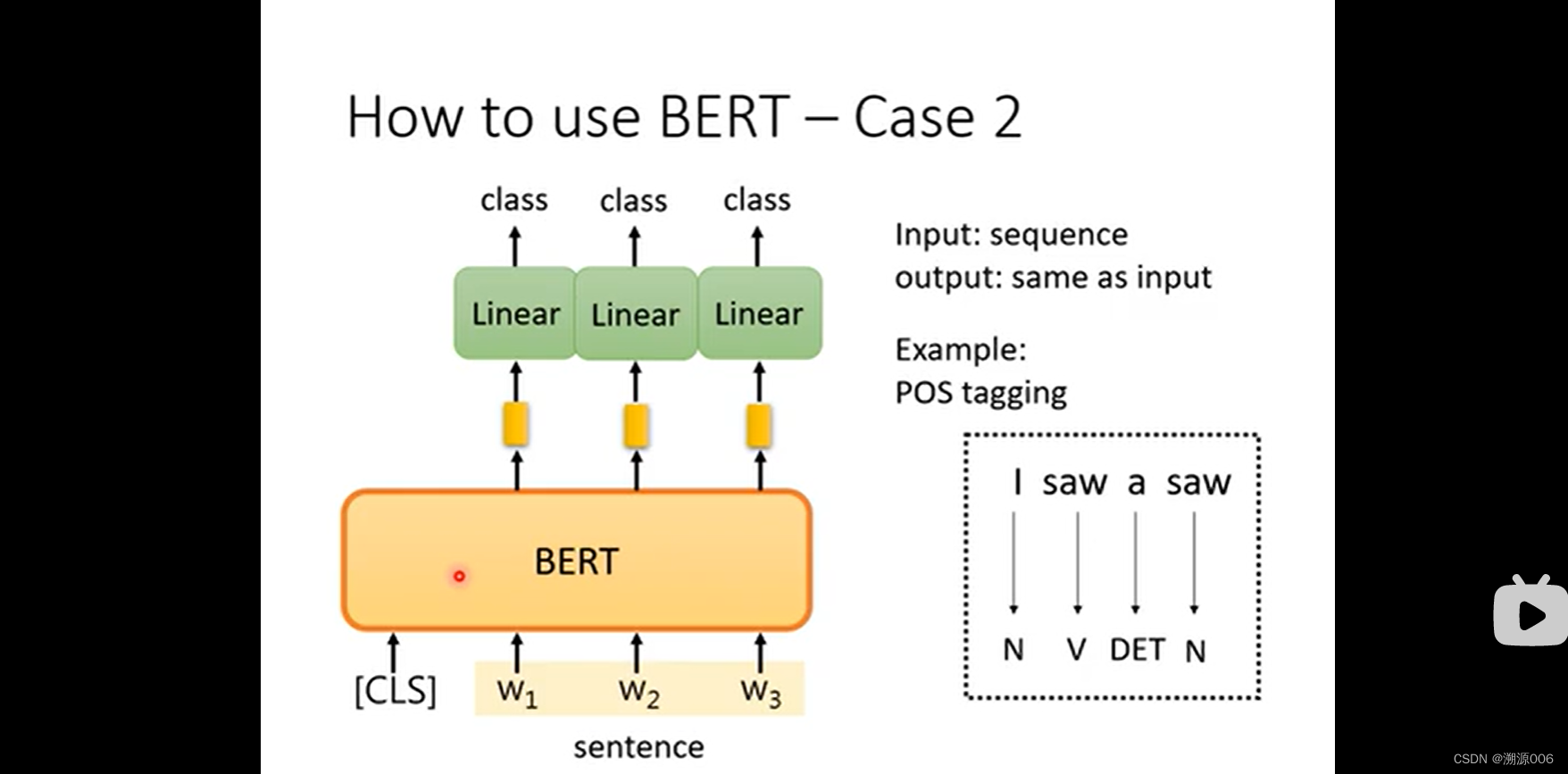
case2:词性标注。输入时一个序列,输出也是一个序列。输入与输出长度一致。分别对每个BERT输出的向量接linear层,然后预测类别。其他与case1一致。
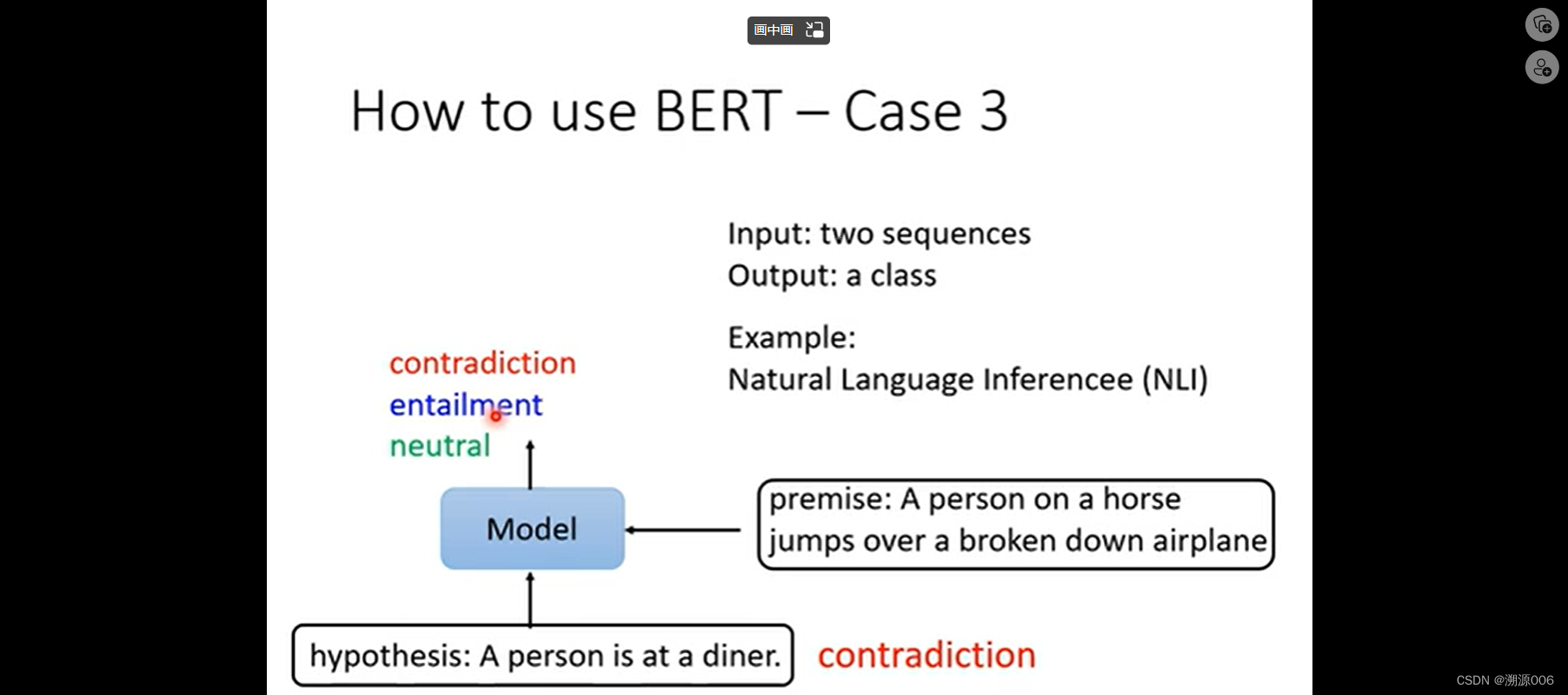
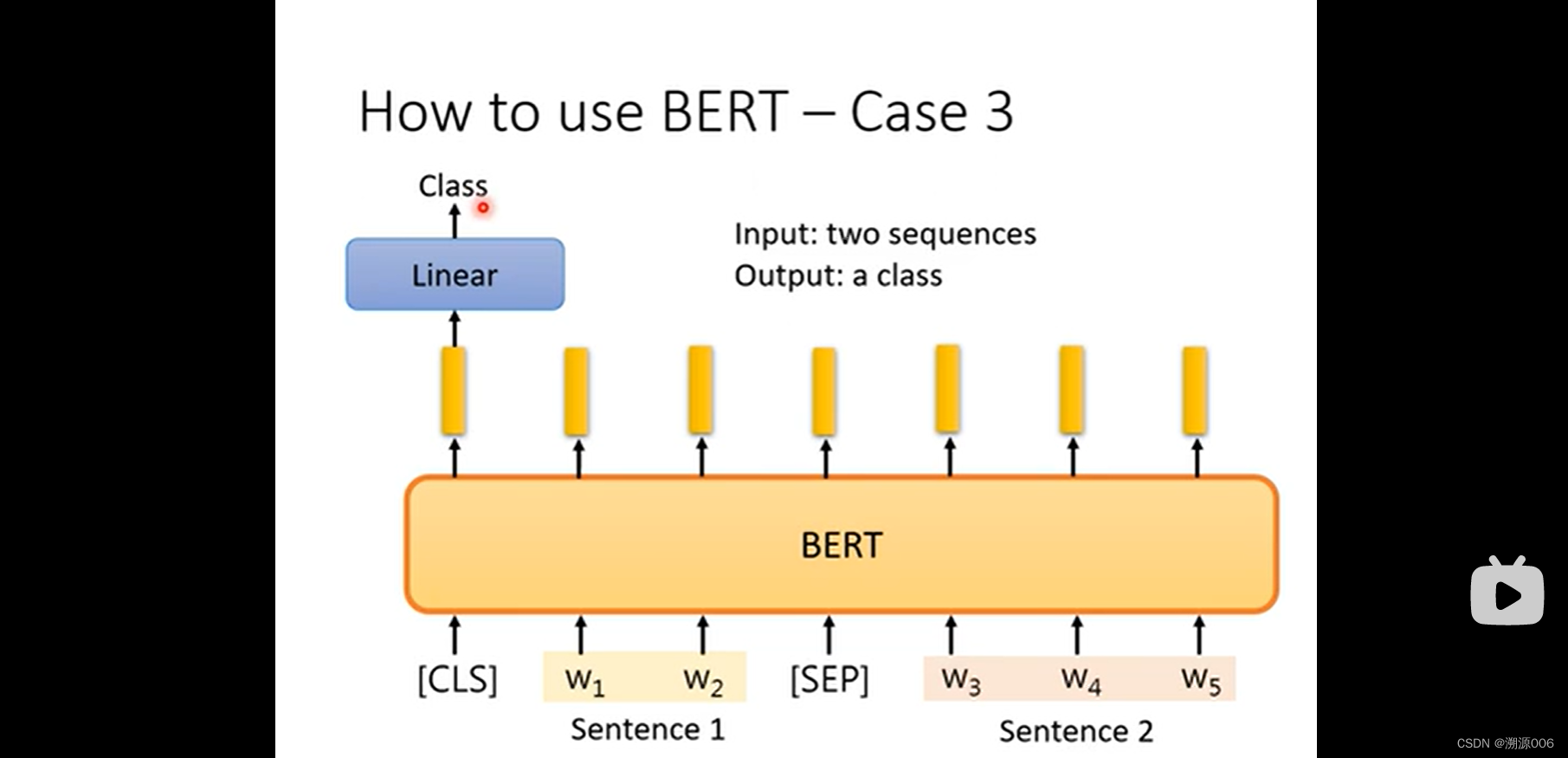
Case3:自然语言推理,输入两个句子,输出一个类别。推理这两个句子时矛盾的还是不矛盾的。通过上图的方式把两个句子连接成一个序列。然后和case1一样。
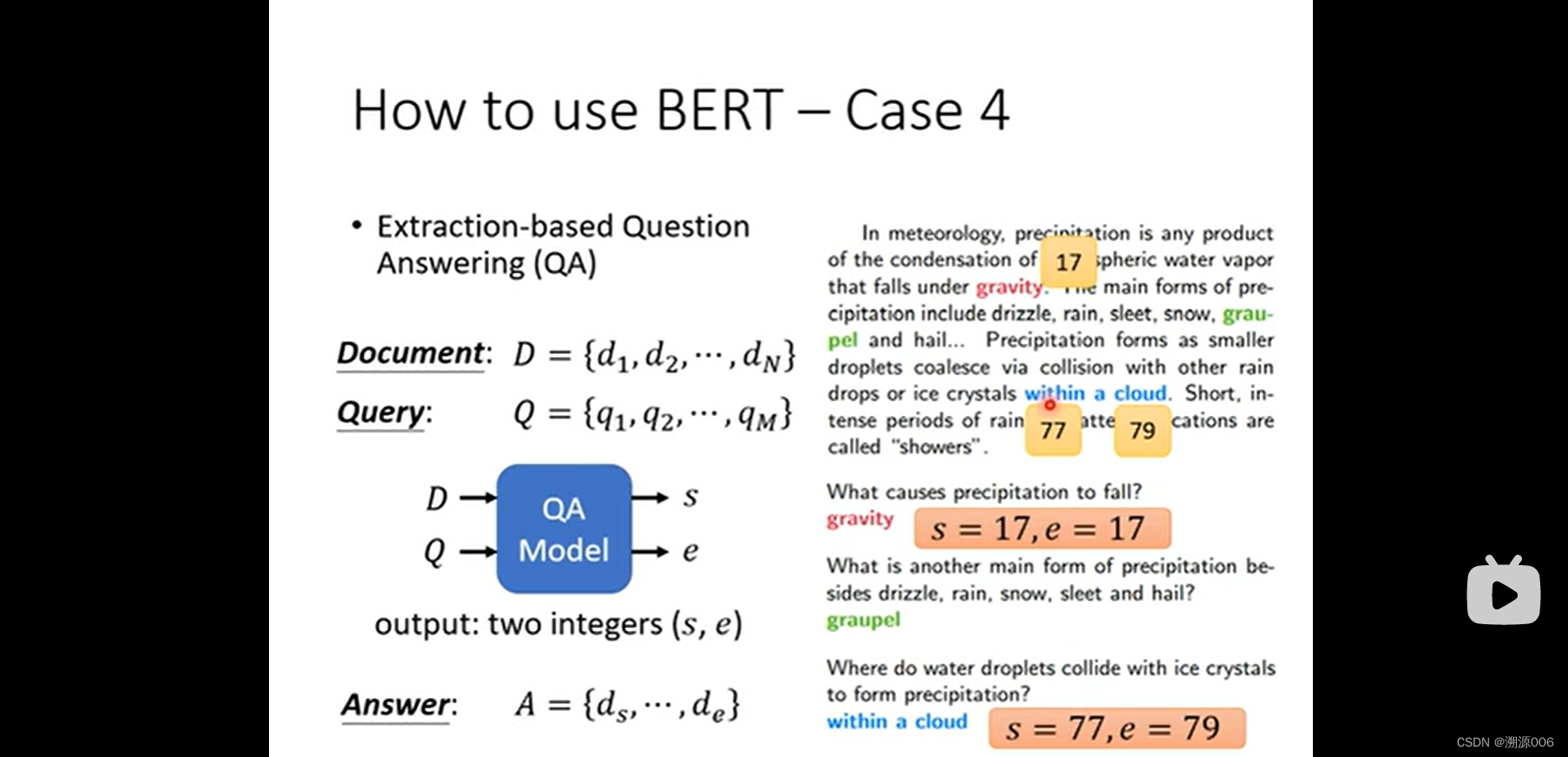
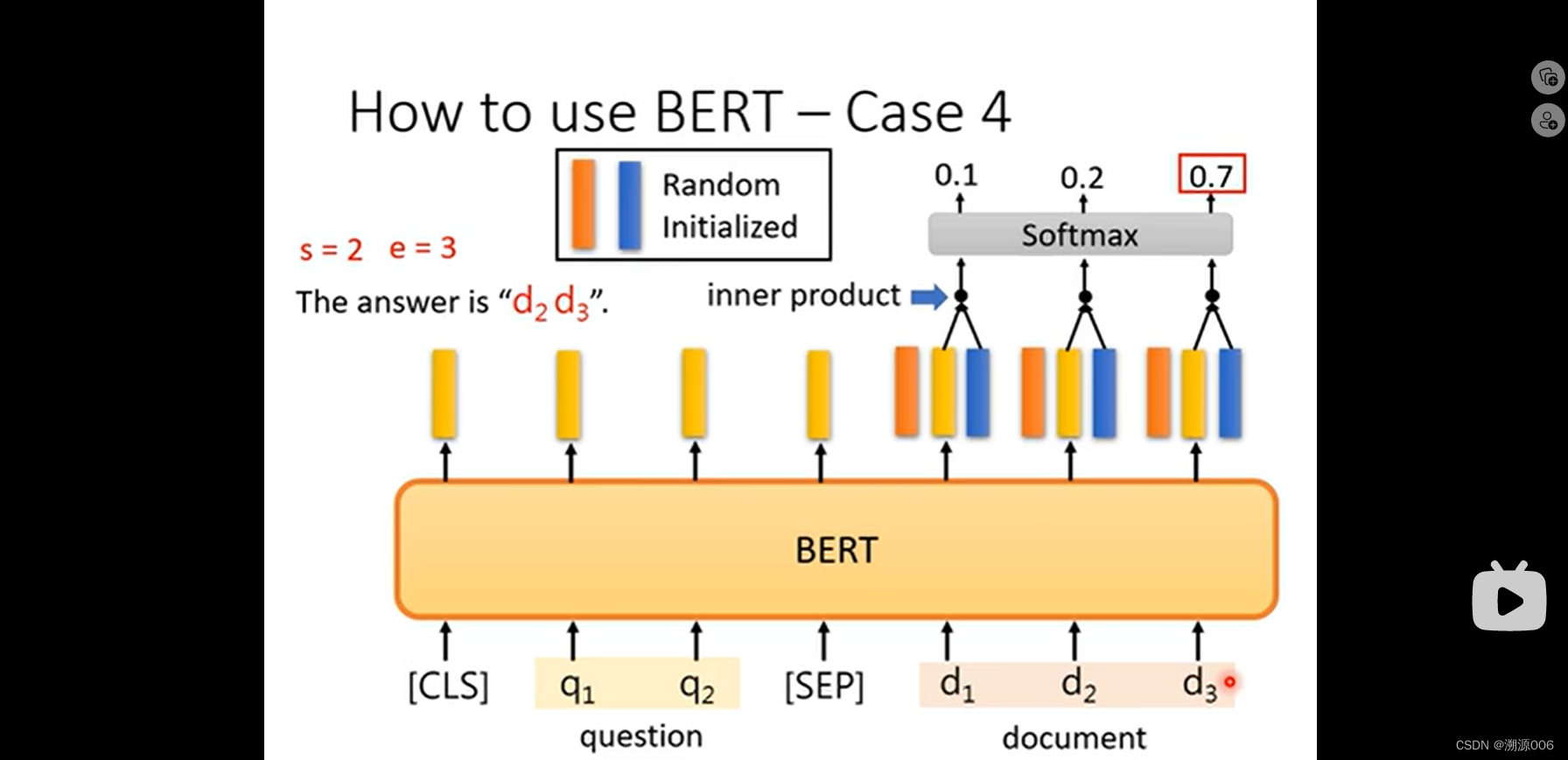
Case4:阅读理解QA(假设答案肯定在文章内部找到)。输入文章和问题,输出两个数字,第一个数字代表回答的起始词在文章的位置。第二个数字代表最后一个词的位置。训练方式,把问题和文章如上连接成一个序列。随机初始化两个向量(需要训练,可看成起始和结束的query),第一个向量与所有的文章的词的bert输出做内积,然后softmax。这是对应起始词。第二个向量与所有的文章的词的bert输出做内积,然后softmax。这是对应结束词。
2.4 为什么BERT会work
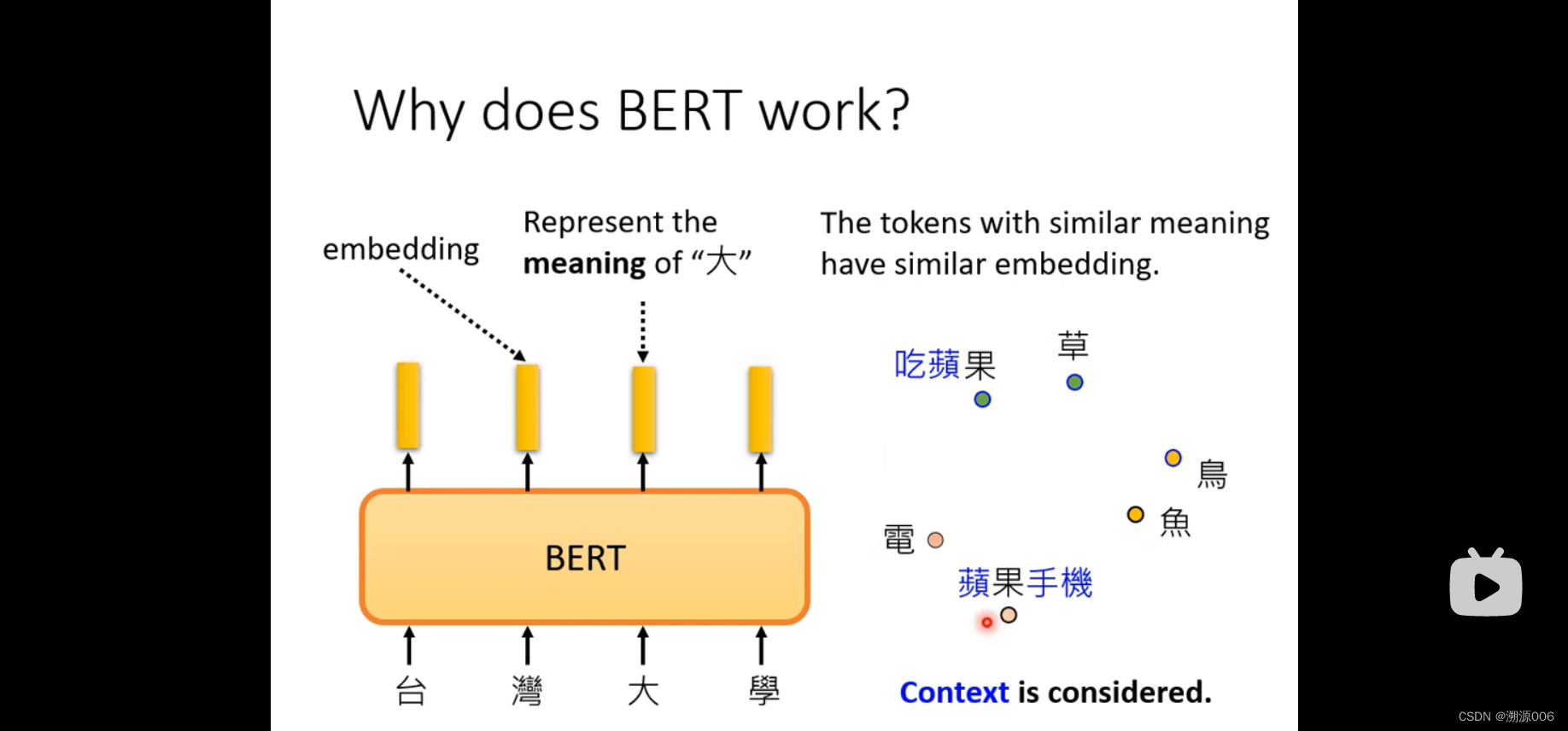
BERT的输出的每个向量可以代表对应的token的意思,而且考虑了上下文。比如同样是“果”,吃苹果和苹果手机这两个语境中的“果”是不一样的意思,所以输出的向量在表示空间的距离也比较大。
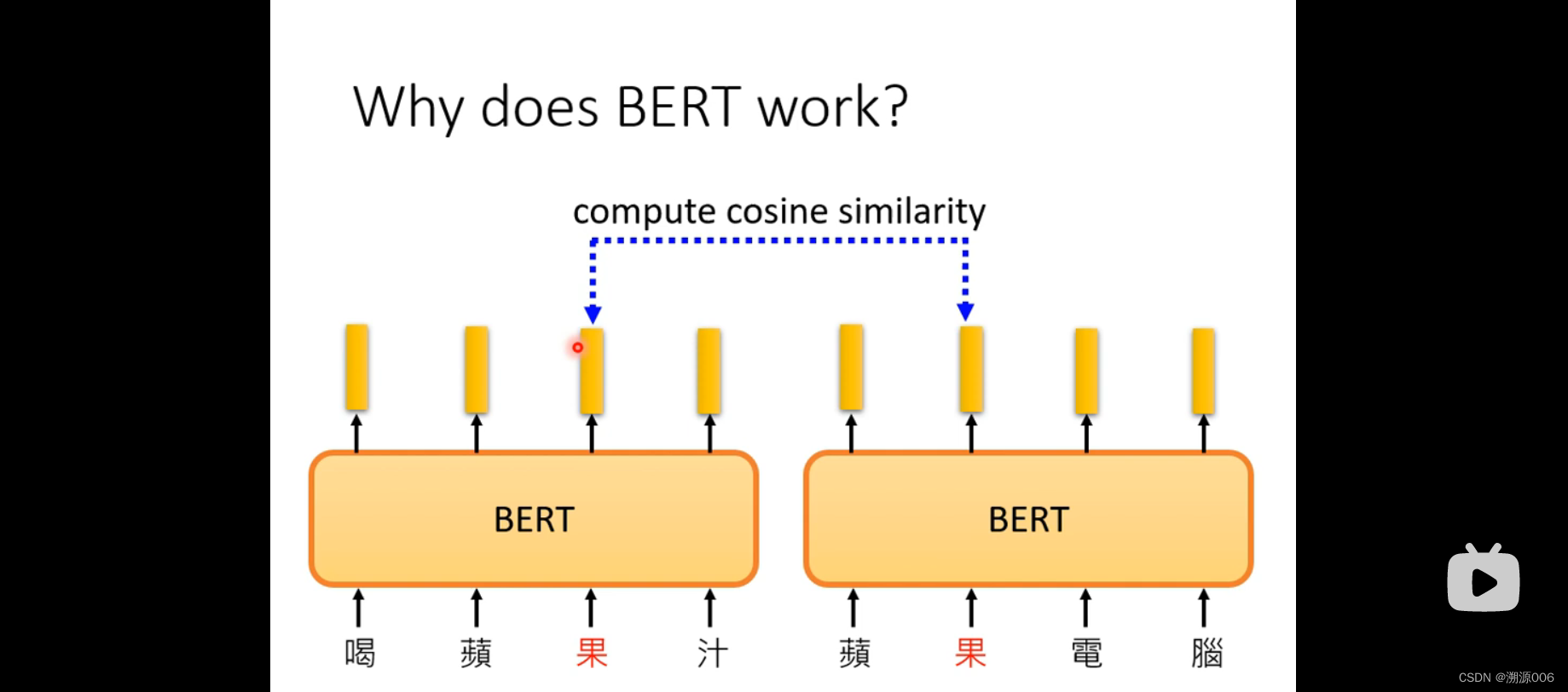
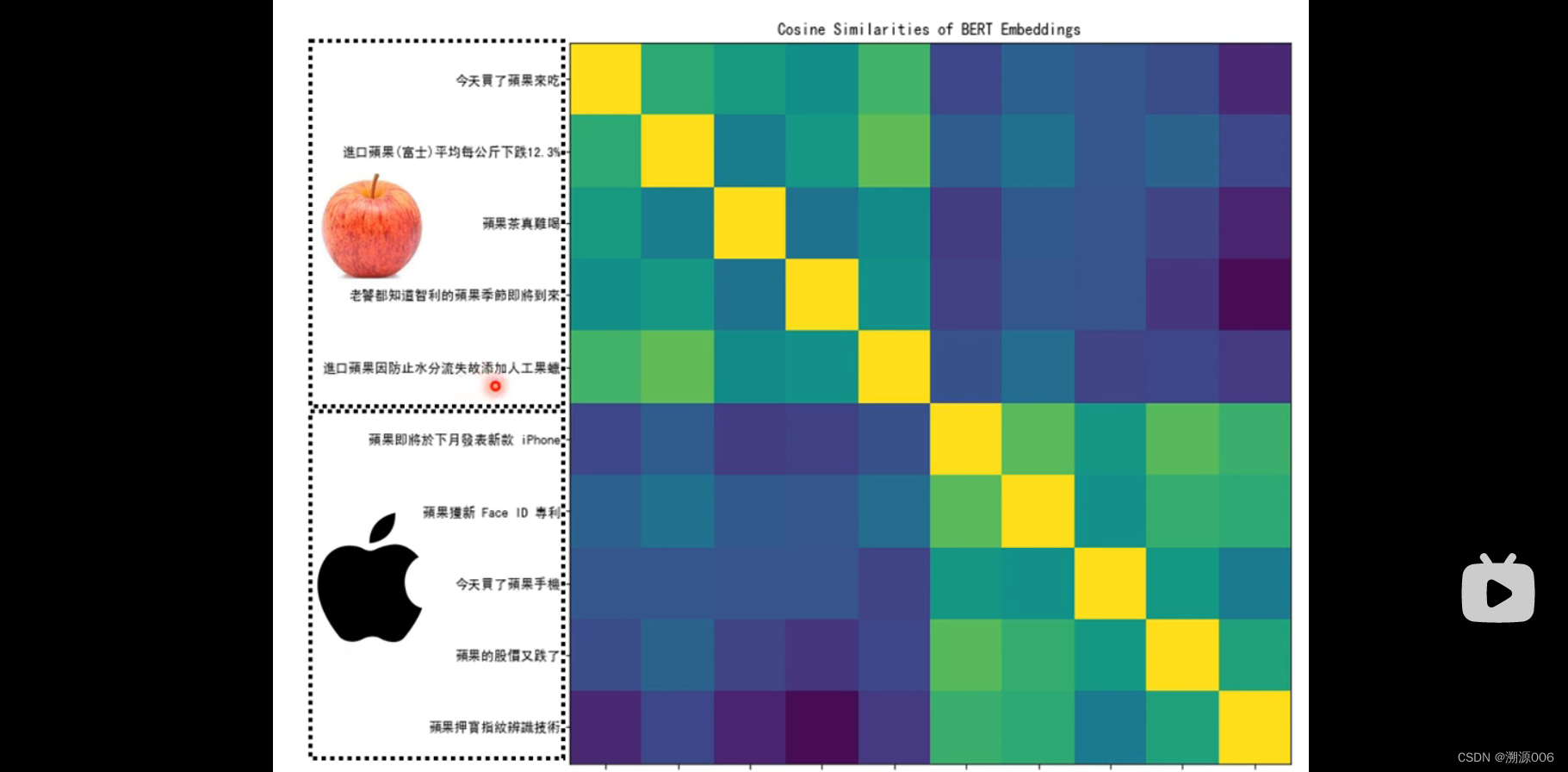
前5个“果”都是水果,后5个“果”都是苹果手机或者电脑。两两之间做相似度计算,得到10X10矩阵。前五个两两相似度高,后五个两两相似度高。但是彼此之间相似度低。
所以BERT在训练完形填空的过程中,学会了字的意思!!!!
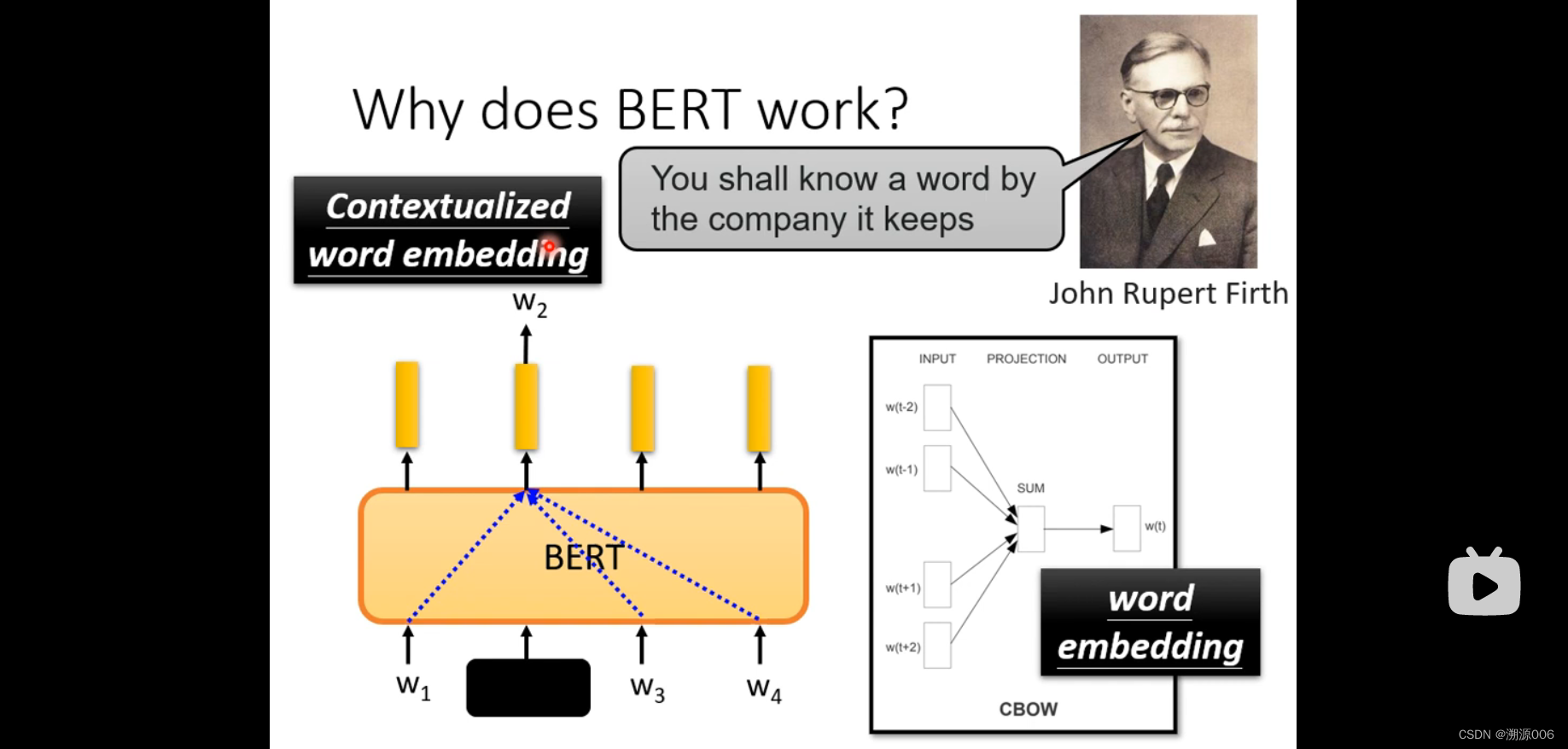
为什么BERT这种完型填空的形式可以学习到字的意思呢?因为有研究者说过,要了解一个字或者词的意思,需要通过他的上下文来体现。而BERT的主题网络构架是transformer的encoder部分,我们说过transformer主要用了self-attention的构架,self-attention就考虑了整个序列,也就是所遮住部分的上下文。其实这种完形填空的思路很早就有,比如CBOW,但是CBOW考虑到模型的复杂性用的简单的线性模型。BERT也被称为上下文的词嵌入。















 1466
1466











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









