







#include<stdio.h>
#include<stdlib.h>
#include<CL/cl.hpp>
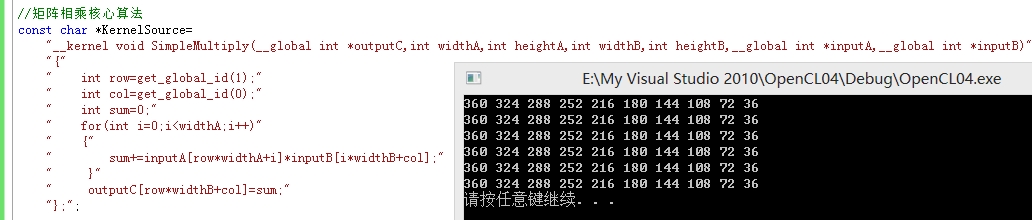
//矩阵相乘核心算法
const char *KernelSource=
"__kernel void SimpleMultiply(__global int *outputC,int widthA,int heightA,int widthB,int heightB,__global int *inputA,__global int *inputB)"
"{"
" int row=get_global_id(1);"
" int col=get_global_id(0);"
" int sum=0;"
" for(int i=0;i<widthA;i++)"
" {"
" sum+=inputA[row*widthA+i]*inputB[i*widthB+col];"
" }"
" outputC[row*widthB+col]=sum;"
"};";
int main()
{
const int heightA=6;
const int widthA=8;
const int heightB=8;
const int widthB=10;
const int heightC=6;
const int widthC=10;
int i,j,k;
int A[heightA][widthA]=
{
1,2,3,4,5,6,7,8,
1,2,3,4,5,6,7,8,
1,2,3,4,5,6,7,8,
1,2,3,4,5,6,7,8,
1,2,3,4,5,6,7,8,
1,2,3,4,5,6,7,8
};
int B[heightB][widthB]=
{
10,9,8,7,6,5,4,3,2,1,
10,9,8,7,6,5,4,3,2,1,
10,9,8,7,6,5,4,3,2,1,
10,9,8,7,6,5,4,3,2,1,
10,9,8,7,6,5,4,3,2,1,
10,9,8,7,6,5,4,3,2,1,
10,9,8,7,6,5,4,3,2,1,
10,9,8,7,6,5,4,3,2,1
};
int C[heightC][widthC];
cl_int err;
cl_platform_id platform;
err=clGetPlatformIDs(1,&platform,NULL);
cl_device_id device;
err=clGetDeviceIDs(platform,CL_DEVICE_TYPE_GPU,1,&device,NULL);
cl_context context;
context=clCreateContext(NULL,1,&device,NULL,NULL,&err);
cl_command_queue cmdQueue;
cmdQueue=clCreateCommandQueue(context,device,NULL,&err);
cl_mem BufferA;
cl_mem BufferB;
cl_mem BufferC;
BufferA=clCreateBuffer(context,CL_MEM_READ_ONLY,sizeof(int)*widthA*heightA,NULL,&err);
BufferB=clCreateBuffer(context,CL_MEM_READ_ONLY,sizeof(int)*widthB*heightB,NULL,&err);
BufferC=clCreateBuffer(context,CL_MEM_WRITE_ONLY,sizeof(int)*widthC*heightC,NULL,&err);
err=clEnqueueWriteBuffer(cmdQueue,BufferA,CL_TRUE,0,sizeof(int)*widthA*heightA,A,0,NULL,NULL);
err=clEnqueueWriteBuffer(cmdQueue,BufferB,CL_TRUE,0,sizeof(int)*widthB*heightB,B,0,NULL,NULL);
cl_program program;
program=clCreateProgramWithSource(context,1,&KernelSource,NULL,&err);
err=clBuildProgram(program,1,&device,NULL,NULL,NULL);
cl_kernel kernel;
kernel=clCreateKernel(program,"SimpleMultiply",&err);
err=clSetKernelArg(kernel,0,sizeof(cl_mem),&BufferC);
err=clSetKernelArg(kernel,1,sizeof(int),&widthA);
err=clSetKernelArg(kernel,2,sizeof(int),&heightA);
err=clSetKernelArg(kernel,3,sizeof(int),&widthB);
err=clSetKernelArg(kernel,4,sizeof(int),&heightB);
err=clSetKernelArg(kernel,5,sizeof(cl_mem),&BufferA);
err=clSetKernelArg(kernel,6,sizeof(cl_mem),&BufferB);
//size_t localWorkSize[2]={16,16};
size_t globalWorkSize[2]={widthC,heightC};
err=clEnqueueNDRangeKernel(cmdQueue,kernel,2,NULL,globalWorkSize,NULL,0,NULL,NULL);
err=clEnqueueReadBuffer(cmdQueue,BufferC,CL_TRUE,0,sizeof(int)*widthC*heightC,C,0,NULL,NULL);
for(i=0;i<heightC;i++)
{
for(j=0;j<widthC;j++)
{
printf("%d ",C[i][j]);
}
printf("\n");
}
system("pause");
}














 751
751











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









