







更多目标检测和图像分类识别项目可看我主页其他文章
功能演示:
基于yolov8的生猪姿态,行为检测系统,支持图像、视频和摄像实时检测【pytorch框架、python源码】_哔哩哔哩_bilibili
(一)简介
基于yolov8的生猪姿态,行为检测系统是在pytorch框架下实现的,这是一个完整的项目,包括代码,数据集,训练好的模型权重,模型训练记录,GUI界面和各种模型指标(准确率、精确率、召回率等)等。
GUI界面由pyqt5设计实现,可用笔记本摄像头或者外接USB摄像头
该项目是在pycharm和anaconda搭建的虚拟环境执行,pycharm和anaconda安装和配置可观看教程:
超详细的pycharm+anaconda搭建python虚拟环境-CSDN博客
(二)项目介绍
1. 模型训练、验证
该项目可以使用已经训练好的模型权重,也可以自己重新训练,自己训练也比较简单:
第一步:修改data/data.yaml中的数据集路径
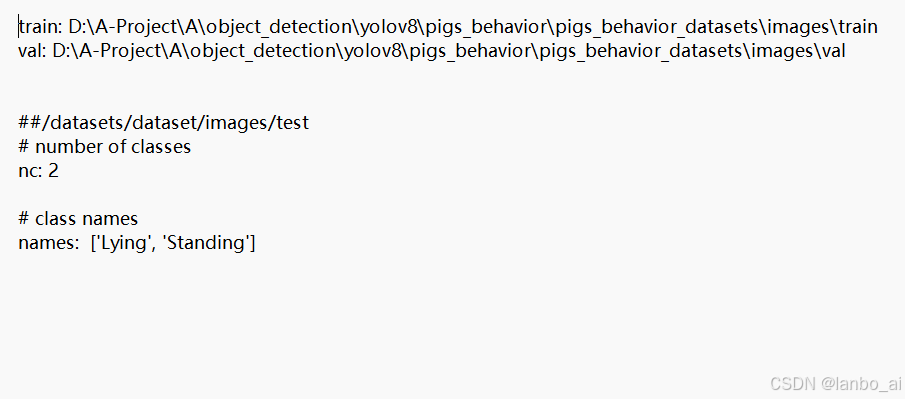
第二步:模型训练与验证,即运行train.py文件
第三步:使用模型,即运行gui.py文件即可通过GUI界面来展示模型效果
2. 数据集

部分数据展示:

3.GUI界面(技术栈:pyqt5+python)
a.GUI初始界面

b.图像检测界面
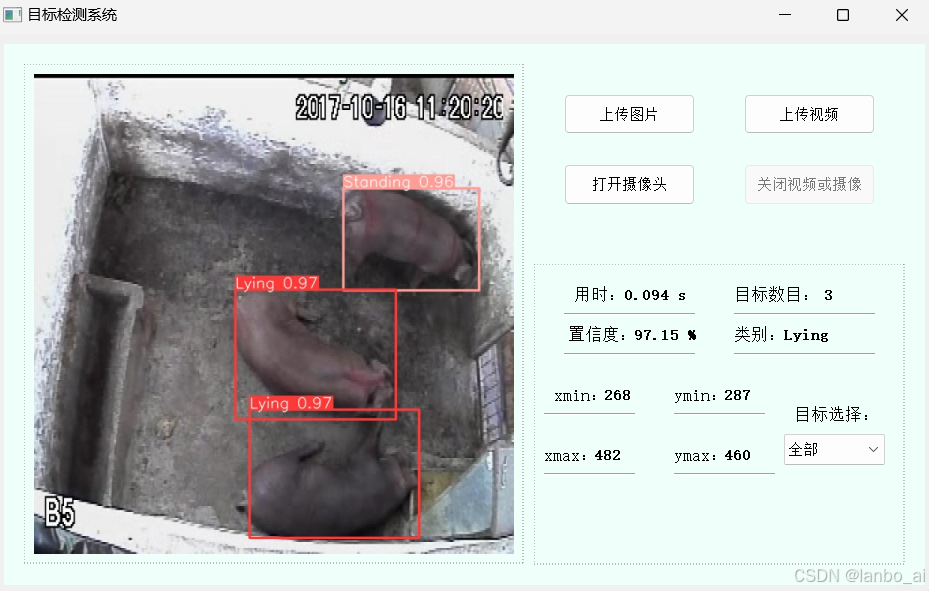
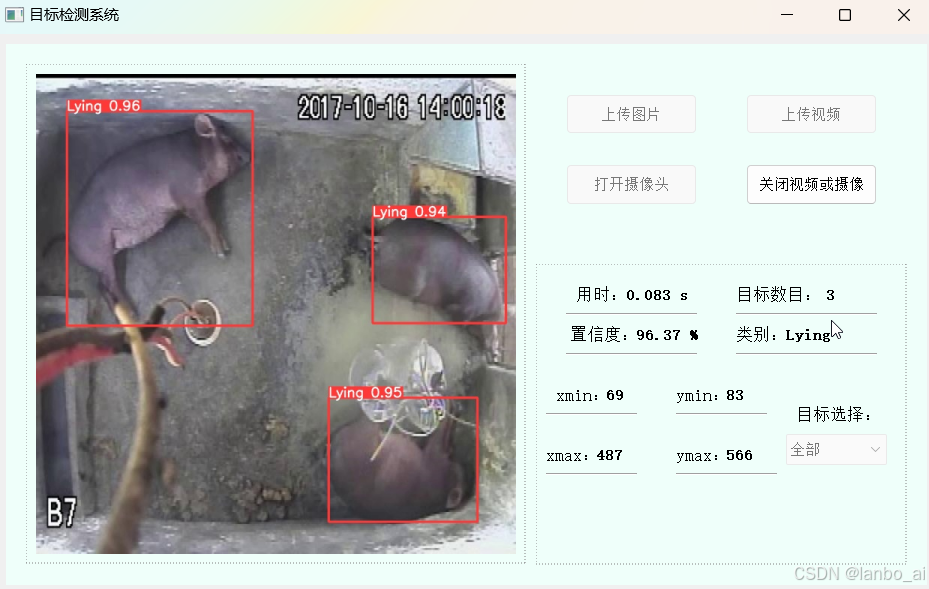
c.视频或摄像实时检测界面
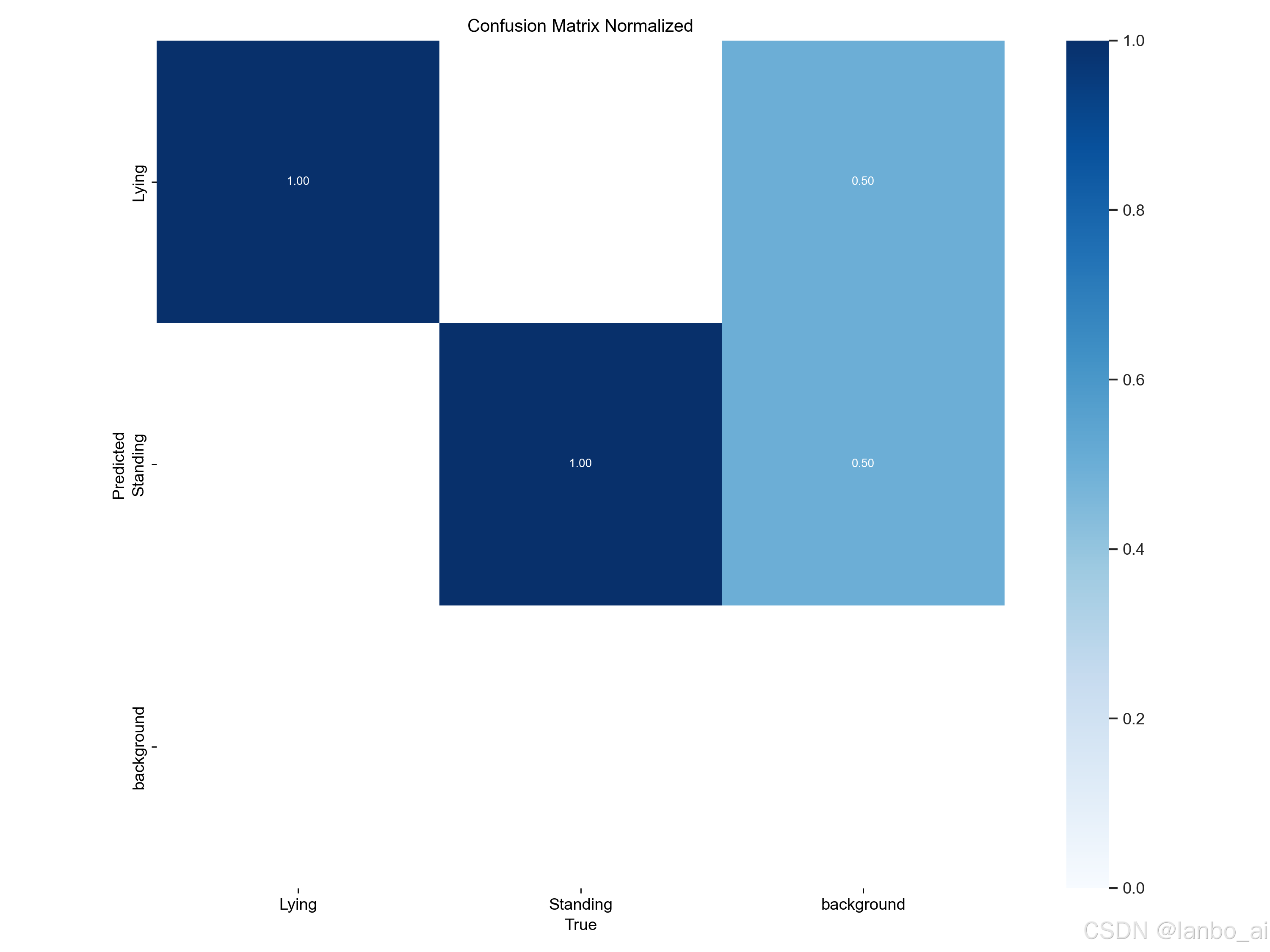
4.模型训练和验证的一些指标及效果



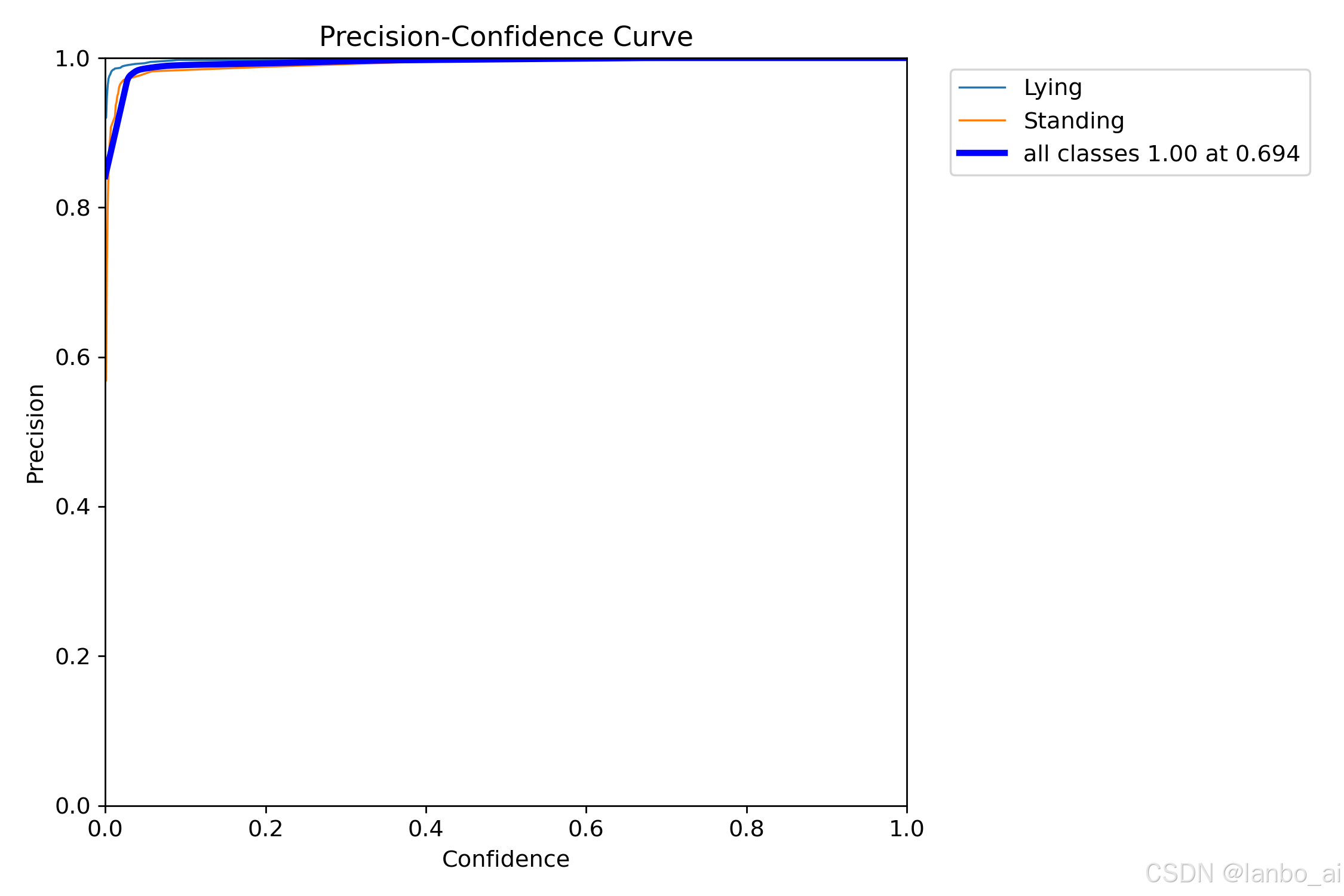

(三)代码
由于篇幅有限,只展示核心代码
def upload_img(self):
"""上传图片"""
# 选择录像文件进行读取
self.comboBox.setDisabled(False)
self.pushButton_4.setEnabled(False)
# 上传图像
fileName, fileType = QFileDialog.getOpenFileName(self, 'Choose file', '', '*.jpg *.png *.tif *.jpeg')
if fileName:
self.file_path = fileName
"""检测图片"""
org_path = self.file_path
# 目标检测
t1 = time.time()
# 图像检测
results = self.model.predict(source=org_path, imgsz=self.output_size, conf=self.conf_threshold)[0]
names = results.names
t2 = time.time()
self.label_6.setText('{:.3f} s'.format(t2 - t1))
now_img = results.plot()
# 调整图像大小
self.resize_scale = self.output_size / now_img.shape[0]
im0 = cv2.resize(now_img, (0, 0), fx=self.resize_scale, fy=self.resize_scale)
cv2.imwrite("images/tmp/single_result.jpg", im0)
# 自适应图像大小
self.label_3.setScaledContents(True)
# 显示图像
self.label_3.setPixmap(QPixmap("images/tmp/single_result.jpg"))
# 获取位置信息
location_list = results.boxes.xyxy.tolist()
location_list = [list(map(int, e)) for e in location_list]
# 获取类别信息
cls_list = results.boxes.cls.tolist()
cls_list = [int(i) for i in cls_list]
# 获取置信度信息
conf_list = results.boxes.conf.tolist()
conf_list = ['%.2f %%' % (each * 100) for each in conf_list]
# 目标总数
total_nums = len(location_list)
self.label_11.setText(str(total_nums))
choose_list = ['全部']
target_names = [names[id] + '_' + str(index) for index, id in enumerate(cls_list)]
choose_list = choose_list + target_names
# 复合框信息
self.comboBox.clear()
self.comboBox.addItems(choose_list)
self.results = results
self.names = names
self.cls_list = cls_list
self.conf_list = conf_list
self.location_list = location_list
# 显示目标框
if total_nums >= 1:
# 渲染类别和置信度信息
self.label_16.setText(names[cls_list[0]])
self.label_15.setText(str(conf_list[0]))
# 默认显示第一个目标框坐标
# 设置坐标位置值
self.label_13.setText(str(location_list[0][0]))
self.label_19.setText(str(location_list[0][1]))
self.label_21.setText(str(location_list[0][2]))
self.label_23.setText(str(location_list[0][3]))
else:
# 清空显示框
self.label_16.setText(' ')
self.label_15.setText(' ')
self.label_13.setText(' ')
self.label_19.setText(' ')
self.label_21.setText(' ')
self.label_23.setText(' ')(四)总结
以上即为整个项目的介绍,完整的项目包括代码,数据集,训练好的模型权重,模型训练记录,GUI界面和各种模型指标等
整个项目包含全部资料,一步到位,省心省力
若项目使用过程中出现问题,请及时交流!


















 2084
2084

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









