







文章目录
Edible Instruction
More Mathematics knowledges, pls refer to https://blog.csdn.net/landian0531/article/details/118145417
- Too many formulations and equations, so screen shots of PPT is necessary.
- My mathematics sucks, so you 'll see many mathematical knowledge interspersed in my all ML learning session.
- Don’t be afraid of any mathematical symbol, just BAIDU the definition.
1. Review
Based on previous Intro, in step 3, we have to solve the following optimization problem
the formula in the picture should be argmin
arg: argument
argmin means: the value of variable when the latter formula reaches the minimum
argminL( θ \theta θ) means: the minimum value of formula of L( θ \theta θ)
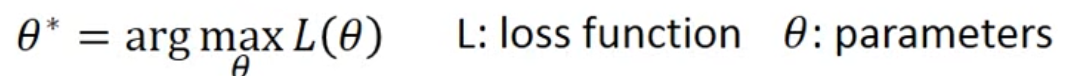
Suppose the variables
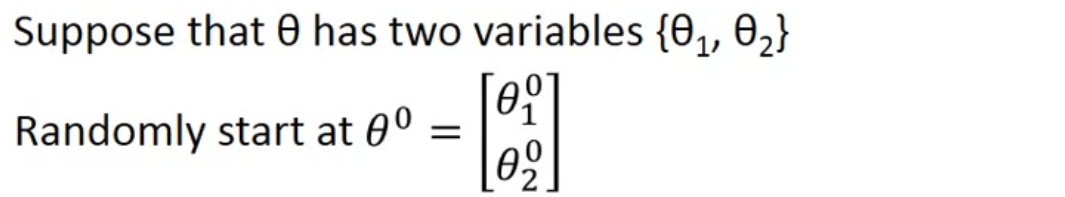
Partial differential equation(偏微分方程)
derivative (导数)
Learning rate η \eta η
Gradient ∇ \nabla ∇


2. Gradient Descent Tips
Tips1: Tuning your learning rate
Set the learning rate η \eta η carefully

The graph is more efficient when you

Adaptive Learning Rates

Adagrad
Reference SGD Adagrad Adam
Good at concept explanation https://zhuanlan.zhihu.com/p/61955391
Good at Visalized https://zhuanlan.zhihu.com/p/32626442



Contradiction? (矛盾吗?)

Intuitive Reason(直观解释)


Tips2: Stochastic Gradient Descent



Tips3: Feature Scaling(特征缩放)


How to Scaling: Normalization
Easier edition: Z-Score https://zhuanlan.zhihu.com/p/364338617
More details edition: https://zhuanlan.zhihu.com/p/265411459

















 160
160











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









