






摘要
在各种类型的数据中,机载3D点云可以精确记录建筑物的高度信息,因此对于检测倒塌的建筑物特别有用。然而,现有的方法是基于通用的点云分析技术,没有明确考虑建筑物损坏的性质。在这项研究中,我们提出了损害敏感网络(DS-Net),这是一种用于倒塌建筑物检测的专用方法。DS-Net 的核心是拉普拉斯单元 (LU),这是一个简单而有效的 3D 点云模块,旨在增强受损部件的特征表示,以促进倒塌建筑物的检测。我们进行了大量的实验,并证明DS-Net与现有方法相比具有更高的性能。特别是,DS-Net 与 PointNet++(DS-Net 设计所基于的标准网络)的详细比较发现,DS-Net 在检测倒塌建筑物方面比 PointNet++ 提高了 8.3% 的精度、3.0% 的召回率和 6.4% 的 IoU 增益。此外,还验证了随着计算资源的增加,检测性能可以进一步提高。定性分析表明,DS-Net 擅长检测表现为屋顶变形、碎屑和倾斜的损坏。此外,由于 LU 的自适应特性,与基线相比,DS-Net 可以生成更平滑的预测和更清晰的边界。此外,基于Grad-CAM的可视化解释分析,分析DSNet如何理解建筑物损坏情况。结果表明,DS-Net能够准确定位各种建筑物损坏。
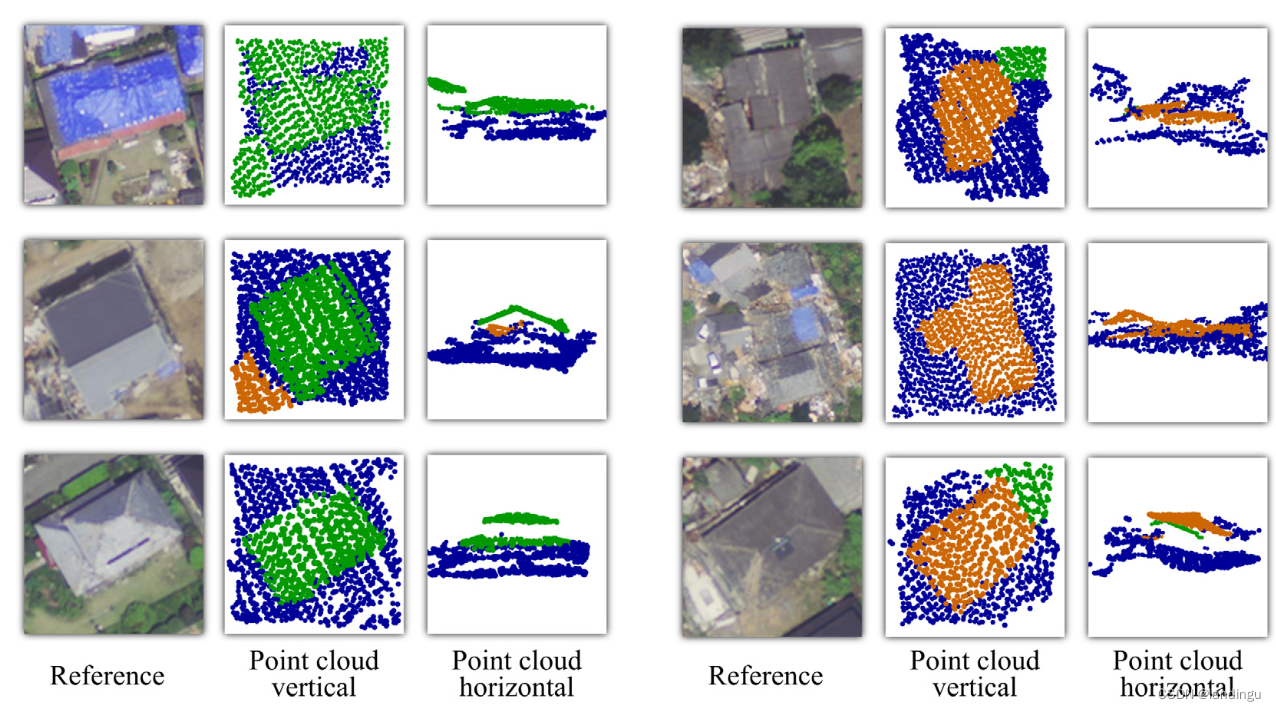
 绿色、棕色和蓝色点分别表示未倒塌的建筑物、倒塌的建筑物和背景的点。红色框表示目标建筑物,红色箭头表示倾斜度。
绿色、棕色和蓝色点分别表示未倒塌的建筑物、倒塌的建筑物和背景的点。红色框表示目标建筑物,红色箭头表示倾斜度。
引言
图中可以看出,倒塌建筑物的屋顶形变并没有想象中的大,因此从二维影像判断灾损有一定困难,但是其高度上变化比较大,因此,从点云中判断损失有天然优势
在最近的研究中,损伤检测通常被表述为建筑物定位和损伤分类的组合(Shen et al., 2021)。在此管道中,检测到感兴趣建筑物的建筑物定位后,然后是损坏分类,该分类估计每个检测到的建筑物的类别标签(即损坏级别)。在实践中,这两个子任务通常被组合成一个语义分割任务(Weber 和 Kané,2020 年),其中为输入的每个元素分配一个类别标签。因此,我们也遵循了最近的实践,将倒塌的建筑物检测定义为语义分割任务。具体而言,任务的输入是一个建筑面片,其中的点由其 3D 坐标表示。该网络使用输入并生成每个点的预测,其中为每个点分配一个类别标签。如表2和图3所述,包括三类:倒塌的建筑物、非倒塌的建筑物和背景。
方法
1.倒塌建筑的特征
2.LU单元的具体设计
3.DS-Unet架构
1.倒塌建筑的特征
3D点云描述的建筑物严重结构损坏模式具有一定的可预测行为。具体来说,严重损坏通常表现为点的完全或部分不规则分布,代表变形的建筑结构或碎片。相反,非坍塌的屋顶由平滑分布在屋顶上的点组成,这些点通常与地平面水平
文章通过离散拉普拉斯用数字描述损伤特征
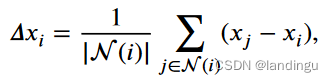
N(i)表示i点的空间最邻近点的集合,|N(i)|表示相邻要素的总数量。离散拉普拉斯量描述了中心点与其相邻点的不同之处。换句话说,它表示中心点周围区域的平滑度。即倒塌建筑中的离散拉普拉斯分布更加不规则
因此,亮点表示非光滑(大差异)区域,而暗点表示光滑(小差异)区域。为清楚起见,背景点(例如,地面)的值归零。
2.拉普拉斯单元的改进点
离散拉普拉斯会混淆建受损建筑和其他物体如树木
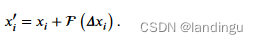
通过加上一个可学习的F映射来增强离散拉普拉斯对损坏的敏感性,F的具体组成有线性层、BN层、ReLU层
self.varphi = nn.Sequential(
nn.Linear(d_in, d_in),
nn.BatchNorm1d(d_in),
nn.ReLU(inplace=True)
)
其中线性层用来提供拉普拉斯的可学习性,BN和ReLU用来促进训练。,Xi主要是起到残差连接保持全局信息的作用
3.网络图如下:
 N 和 C 分别表示输入点的数量和特征通道的维度。默认情况下,C 设置为 128。
N 和 C 分别表示输入点的数量和特征通道的维度。默认情况下,C 设置为 128。
编码器:
由 LU-MLP 和下采样模块的顺序应用组成。对于LU-MLP块,我们采用瓶颈残差结构(He et al., 2016a)来减少计算而不影响性能。组 MLP 在局部邻域中按点应用 MLP,该邻域由收集每个中心点的 k 个最近邻域形成。然后,将LU应用于嵌入点特征,以便适当增强损坏零件的特征表示。随后在 LU-MLP 模块之后应用下采样模块,以降低点的分辨率。通过重复上述过程,可以实现有效的分层学习,从而使生成的特征同时了解局部和全局特征。我们相信,将LU应用于不同的分辨率,使DS-Net能够学习建筑物损坏的多分辨率特征。最远点采样(Qi等人,2017b)算法用于下采样。
解码器:
如第 3.2 节所述,我们将倒塌的建筑物检测表述为语义分割。因此,除了编码器之外,我们还构建了一个分割头。在U-Net(Ronneberger等人,2015)之后,应用了一系列LU上采样模块来恢复点的原始分辨率。具体而言,如图 5 所示,每个 LU 上采样模块通过上采样操作重建高分辨率点特征。为了帮助重建,编码器上层的高分辨率特征与上采样特征相连。然后,LU进一步增强了上采样的特征,使损坏的部分在整个网络中保持突出。对于上采样,我们采用3-最近邻插值(Qi等人,2017b)。最后,生成每个点的预测,其中每个点都带有一个预测的建筑物类别。
这是一个高效的网络,作者还提供了其扩展版本,通过增加 DSNet 的深度和宽度来构建 DS-Net Large。具体而言,输入通道宽度C(如图5所示)从128增加到150。然后,通过在每个分辨率级别重复 LU-MLP 模块来增加网络的深度。因此,DSNet Large 被构建为 12 层网络(在第一、第二、第三和第四分辨率级别分别具有两个、两个、六个和两个 LU-MLP 块)。
4.训练设置
对于本研究中进行的实验,建筑点云的所有可用点都用作输入并输入到模型中。我们使用 3D 坐标作为输入特征。在训练过程中,我们通过将每个输入点云的质心转换为原点来归一化每个输入点云。输入随后被缩放成一个单位球,使得从原点到点的最远距离变为 1。[0.66, 1.5]范围内的随机各向异性缩放和随机垂直旋转用于数据增强

结果如上表所示
可视化结果:

5.问题

第一行中建筑应该都是倒塌,被判断成了两个建筑(看着也像两个)产生误报;
第二行中,树木被判断为了倒塌建筑
参考文献:https://doi.org/10.1016/j.jag.2022.103150
源代码:https://github.com/martianxiu/DS-Net
代码调试全过程:https://blog.csdn.net/landingu/article/details/136907910?spm=1001.2014.3001.5502
















 970
970











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









