







PP-YOLOE论文
论文地址:https://arxiv.org/abs/2203.16250
代码地址:https://github.com/PaddlePaddle/PaddleDetection
摘要
本文提出一种高性能、易部署的检测器PP-YOLOE,目前在产业界性能表现最佳。该算法基于 PP-YOLOv2算法进行优化,优化方法包括使用anchor-free 架构,以及CSPRepResStage、ET-head 和动态标签分配算法 TAL等更有效的backbone和neck。算法根据不同使用场景提出s/m/l/x 几种模型。PP-YOLOE-l 在COCO测试集上实现 51.4 mAP ,在Tesla V100速度为78.1 FPS, 相比于PP-YOLOv2精度提升1.9 AP, 速度提升13.35% ,相比于 YOLOX精度提升+1.3 AP, 速度提升24.96% 。此外,使用TensorRT的FP16精度后,推理速度达到149.2 FPS,详细代码参考此处。
1. Introduction
单阶段目标检测算法由于速度和精度的均衡而在实时检测应用广泛。单阶段算法中,性能最佳的检测器为YOLO系列。自从YOLOV1以来,YOLO系列算法在网络架构、标签分配等方面经历巨大的变化。目前,YOLOX在Tesla V100上取得50.1 mAP 和68.9 FPS 的速度,是目前表现最佳的算法。
YOLOX采用动态标签分配的anchor-free算法,精度方面超越YOLOV5,受YOLOX的启发,本文优化了之前的PP-YOLOv2。
PP-YOLOv2也是一个高性能的单阶段检测算法,在Tesla V100上取得49.5 mAP 和68.9 FPS 的速度。基于PP-YOLOv2本文提出了进化版本的PP-YOLOE。它没有使用deformable convolution和Matrix NMS策略,以便在不同的硬件平台部署。此外,PP-YOLOE易于针对不同算力性能的硬件扩展模型,因此, PP-YOLOE可以在众多实际场景中应用。图1是不同算法的性能对比,与YOLOV5类似,PP-YOLOE可以通过配置width multiplier 和depth multiplier参数来选择不同的模型,算法支持 TensorRT and ONNX格式。
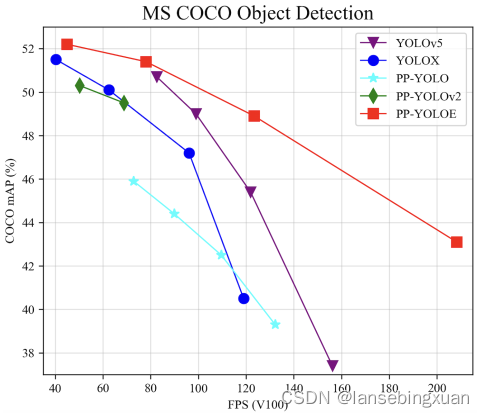
图1 COCO测试集上的算法性能比较
2. Method
本节首先回顾基本模型PP-YOLOv2,然后从网络结构、标签分配、head结构、loss函数几个方面介绍PP-YOLOE。
2.1. A Brief Review of PP-YOLOv2
PP-YOLOv2由带有可变形卷积的ResNet50 - vd组成的backbone,带有SPP和DropBlock的 PAN组成的neck,由轻量的IoU aware组成的head,并且在backbone中使用ReLU激活函数,在neck使用mish激活函数。与YOLOv3相同,对于每一个ground truth物体,PP-YOLOv2只分配一个anchor box。对于classification loss,regression loss 和 objectness loss,PP-YOLOv2 也使用IoU loss 和 IoU aware loss。
2.2. Improvement of PP-YOLOE
Anchor-free : 由于anchor 机制依赖于手工设计,并且引入一系列的超参数,因此,可能在其他数据集上的泛化性不佳。采用FCOS的方法,在每个像素上铺设一个anchor point,本文对3个检测头设置了上下边界,以便将ground truths分配到对应的特征图上。然后,计算bounding box的中心,以便选择最近的像素作为正样本,并且预测4D向量 (x, y, w, h)。如表2所示,上述修改损失 0.3 AP性能,但速度提升。尽管算法参考PPYOLOv2的anchor尺寸设置上下边界,但在anchor-based和anchor-free分配结果上,仍然有小的不连续,这可能是导致性能稍有下降的原因。
Backbone and Neck. Residual连接引入shortcut来缓解梯度消失问题,可以认为是模型组合的方法,Dense连接用不同的感受野聚集中间特征,在检测任务上表现较好。CSPNet利用交叉dense connections来降低计算量同时并没有降低性能。它在YOLOv5, YOLOX,VoVNet和subsequent TreeNet等检测分割网络应用广泛,性能较好。本文提出一种新的模块RepResBlock ,它结合residual connections 和 dense connections ,该模块在backbone和neck 中均有使用。
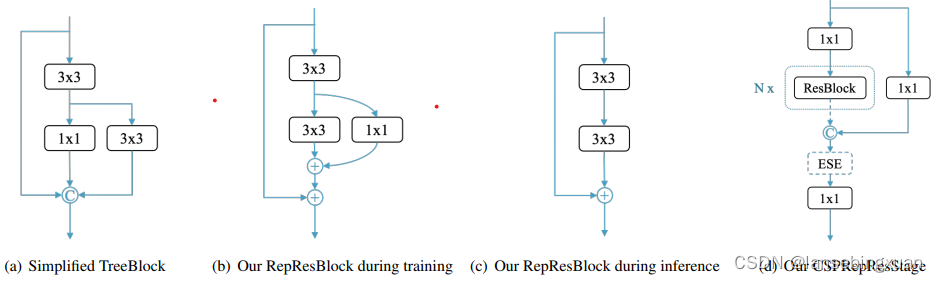
图3:RepResBlock 和 CSPRepResStage网络结构
RepResBlock 模块源于TreeBlock(图3(a) ),在训练阶段,它的结构如图3(b) ,在推理阶段,它的结构如图3( c ) 。如图3(b) 所示,由于RMNet 文章中显示两种操作某种程度上是类似的,因此本文用按元素加(element-wise add)操作替代concatenation 操作,这样,在推理阶段,就可以对RepResBlock 进行重参数化(re-parameterizes ),从而得到一个基本残差块。3( c )) 通常用在ResNet-34 中,本文以RepVGG 形式进行使用。
本文的backbone------CSPRepResNet 与ResNet类似,由3个卷积层,以及4个stage的RepResBlock(如图3(d))堆叠而成 。每个stage,使用部分交叉连接(cross stage partial connections )来减少卷积导致的大量参数和计算量。在backbone的每个CSPRepRes- Stage 中,还使用通道注意力ESE 。在neck部分,使用本文提出的RepResBlock 并沿用 PP-YOLOv2 中的CSPRepResStage 。与backbone不同的地方是,RepResBlock 和 CSP- RepResStage中的ESE层去掉了 shortcut层。
与YOLOv5类似,本文使用宽度倍率因子 α 和深度倍率因子β来调整backbone 和 neck,从而得到一系列不同参数量和计算量的检测网络。backbone 的宽度设置分别是[64, 128, 256, 512, 1024] ,深度设置是[3, 6, 6, 3] neck 的宽度和深度分别是 [192, 384,768] 和 3 。表1是参数的具体设置。这些修改得到0.7%的 AP性能提升,最终得到 49.5% AP 。

表1:α 、 β 参数
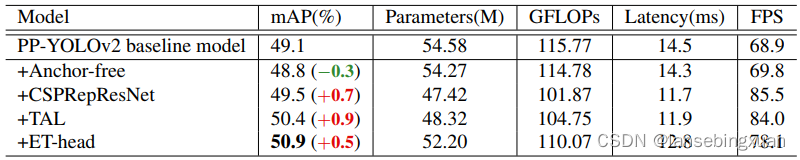
Table 2:PP-YOLOE-l 在 COCO val上的消融实验
Task Alignment Learning (TAL). YOLOX使用 SimOTA 的标签分配策略提高性能。TOOD论文中提出Task Alignment Learning (TAL)进一步分类定位的误分配问题。TAL由动态标签分配(dynamic label assignment)和分配任务损失(task aligned loss)两部分组成。动态标签分配意味着感知预测/损失。通过预测,它为每个ground-truth 动态分配正样本的数量。通过显式分配两个任务,TAL 能够得到最高的分类分手和最高的回归分数。
对于任务分配损失, TOOD使用t的归一化形式 t^,代替损失中的目标,它采用每个实例中的最大IoU作为归一化,分类的BCE 损失可以重写为如下形式

本文使用不同的标签分配策略来研究性能差异。实验采用如上所述的修改后的模型,即使用CSPRepResNet作为backbone。为了快速得到结果,实验只在COCO train2017训练了36 epochs,然后在COCO val上进行验证,如表3所示,TAL性能最佳,达到 45.2% AP。

Table 3:不同标签分配策略对比
**Efficient Task-aligned Head (ET-head).**总所周知,在目标检测中,分类和定位任务存在冲突。YOLOX从众多一阶段和二阶段算法中吸取经验,设计了 decoupled head,并用在YOLO模型中,提升了准确率。然而,decoupled head使得分类和定位任务相互独立,缺少特定任务的学习。基于TOOD,本文提出一种兼顾速度和精度的head-----ET-head。本文使用ESE代替TOOD中使用的注意力层,解决了分类分支和shortcut的对齐问题,并且用distribution focal loss (DFL)替换了回归分支的对齐。通过上述修改,ET-head 在V100上提升0.9ms。
对于分类任务和定位任务的学习,本文分别使用varifocal loss (VFL) 和 distribution focal loss(DFL) 。PP-Picodet[31]成功将VFL和 DFL 用在目标检测上,并且获得了性能提升。与QFL 不同点是,VFL用目标分数来对正样本损失加权。该操作使得高IOU的正样本对损失函数贡献度更大。同时,在训练阶段,模型更多注意高质量的正样本而非低质量的样本。与QFL 相同的是两者都采用IoU-aware classification score (IACS) 作为预测目标。该方法可以有效的学习分类分数和定位质量估计的联合表示,有助于保持训练和推理的高连续性。为解决bounding box固定表示的问题,DFL提出利用一般分布来预测bounding box 。模型的损失函数如下:
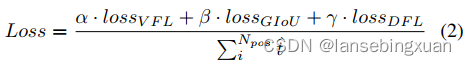
其中,t^表示目标分数的归一化,如公式1所示。如表2所示,ET-head 获得0.5%的 AP提升,达到 50.9% AP 。
3. Experiment
该章节介绍实验细节和结果。所有的实验使用MS COCO-2017训练集进行训练,该训练集包含80 个类别,118k 图像。对于消融实验,本文使用标准的 COCO AP标准衡量,并使用包含5000张图片的MS COCO-2017 验证集作为唯一的验证集。最终的结果使用MSCOCO-
2017 test-dev测试得到。
3.1. Implementation details
使用 momentum = 0.9,weight decay = 5e-4的stochastic gradient descent (SGD)训练。采用cosine learning rate ,训练300个epoch,warmup采用5个epoch,基础学习率是 0.01。在8 × 32 G V100 GPU上,总的batch size是 64,使用线性扩展规则来调整学习率。训练中也使用decay = 0.9998的exponential moving average (EMA)。本文只只用基本的数据增强,包括random crop, random horizontal flip, color distortion, and multi-scale,输入图像大小以32的步长均匀地从 320变化到768。
3.2. Comparsion with Other SOTA Detectors
Figure 1展示了PP-YOLOE和当前主流算法的对比,由于YOLOv5和YOLOX不定期更新,本文重新测试了他们的代码。本文使用batch size= 1来比较模型推理速度(不包括图像预处理和NMS)。不过,PP-YOLOE使用的是 paddle inference engine。为公平起见,本文在同样环境下基于tensorRT 6.0测试了FP16的推理速度。
4. Conclusion
本文对PPYOLOv2做了一系列改进,包括可扩展的backbone-neck结构、有效的任务分配head(task aligned head)、标签分配策略( label assignment strategy)以及目标损失函数(objective loss function),从而得到一个高性能目标检测器PP-YOLOE。本文提供s/m/l/x几种模型以适应不同的应用场景,在PaddlePaddle框架下可以方便的使用转换。
















 1592
1592











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











