







PP-YOLOE
简介
2022.3.24,百度飞浆推出PP-YOLOE,作为22年的第一个YOLO改进版,官方号称测试性能(在MS COCO上)全面领先YOLOX。
尤其是速度方面,在-s模型上达到208FPS,相较于YOLOX-s的119FPS,几乎翻倍!
而在性能上,以PP-YOLOE-x为例,在MS COCO上的mAP达到52.2%,毫无疑问是目前综合性能最好的yolo版本。

由于paddledetdction中只提供了训练和推理的接口,并没有源代码,所以本文将从论文出发,对比分析PP-YOLOE的各项改进。
改进
分五个部分进行对比分析。
1.针对泛化性
PP-YOLOE去除了可变卷积(deformable convolution)和Matrix NMS,从而在各种硬件上得到很好的支持,进一步提升了泛化性能。支持TensorRT 和 ONNX。
1)可变卷积(deformable convolution)
可变卷积在普通的卷积层上增加位移变量,这个变量根据数据的情况学习,偏移后,相当于卷积核每个方块可伸缩的变化,从而改变了感受野的范围,感受野成了一个多边形。
结构图如下:

虽然有助于提高精度,但额外增加的一个卷积层用来学习offset,增加了许多的计算负担,并且飞浆认为这样不利于模型部署。
2)Matrix NMS
利用排序过后的上三角化的IoU矩阵,并且将mask IoU并行化,然后论文同样采取了得分惩罚机制来抑制冗余mask。
优点:
- 实现了mask IoU的并行计算,对于box-free的密集预测实例分割模型很有使用价值。
- 与Fast NMS一样,只需一次迭代。
缺点:
- 与Fast NMS一样,直接从上三角IoU矩阵出发,可能造成过多抑制。
- 同样的,飞浆不认为这个操作带来的性能提升优于其带来的额外计算负担,并且为了便于部署,将其舍弃。
2. Anchor-free
作为PP-YOLOv2的改进版本,PP-YOLOE与其最大的不同之处就体现在基于Anchor-free,根据FCOS的思想,对每一个目标像素设置一个锚点,将 ground truths分配给相应的特征图。此举使得模型损失了0.3的AP,但提升了模型速度。
这个部分没啥好讲的,FCOS用语义分割的像素级处理方式处理目标检测,相比于传统的Anchor-based大大减少了运算量和参数量,实际效果上算是拿精度换速度了。
感兴趣的小伙伴可以 戳这里(FCOS论文)
3. 骨干网络和Neck
使用飞浆自己改进的 RepResBlock构造骨干网络,命名CSPRepResNet,采用和ResNet一样的结构,包含一个由三个卷积层和四个后续阶段组成的stem,这四个后续阶段由 RepResBlock堆叠而成。
1)RepResBlock
RepResBlock源自TreeBlock,首先将其简化成如下形式,其中圆圈C代表连接运算(concatenation opearation)
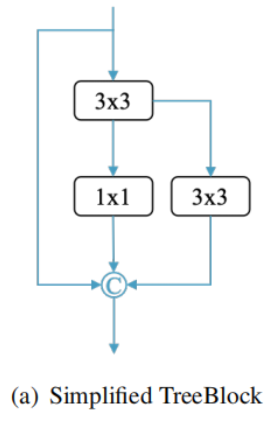
由于连接运算(concatenation operation)和元素加运算(element-wise add operation)之间的相似性已经在
Rmnet论文中得到证实(具体细节不展开,我也没看懂😓),所以飞浆将其进行替换,得到训练阶段的RepResBlock,如下图所示,其中圆圈+代表元素加运算。

然后,又将训练阶段的 RepResBlock进行重参数化( re-parameterizes),得到一个符合RepVGG风格的基本残差块,并在推理阶段使用,如下图所示

而在骨干网络中,飞浆使用两个trick对RepResBlock进行了改造,分别是跨阶段部分连接(cross stage partial connections)和ESE(Effective Squeeze and Extraction),
2)跨阶段部分连接(cross stage partial connections)
由CSPNet提出,CSP即Cross Stage Partial的缩写。
在resnet的基础上,将每一个stage的头尾两部分的特征图集成起来,用于减少在网络优化的过程中花费在重复的梯度信息上的计算。
与ResNet的结构对比如下图

3)ESE (Effective Squeeze and Extraction)

综合上述两种trick,得到最终在三个卷积层后进行堆叠的CSPRepResStage,如下图所示。

其中的ResBlock在推理阶段和训练阶段稍有不同,差别在于重参数化后,推理阶段的ResBlock少了一条带有1*1卷积的残差边。
backbone和neck的宏观结构如下:

4. Task Alignment Learning (TAL).
对标YOLOX的标签分配策略SimOTA。
为了更进一步克服分类和定位的错位,飞浆在PP-YOLOE中使用TOOD中提出的task alignment learning (任务对齐学习)。
Task Alignment Learning (TAL) 显式的把两个任务的最优anchor拉近。这是通过设计一个样本分配策略和任务对齐loss来实现的。样本分配器计算每个anchor的任务对齐度,同时任务对齐loss可以逐步将分类和定位的最佳anchor统一起来。

1)任务对齐样本分配
anchor对齐度量
用分类得分和预测框和gt的IoU的高阶组合来表示这个度量:
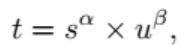
这里α和β可以用来控制得分和IoU对这个指标的影响程度。
训练样本分配
对于每个gt,我们选择m个具有最大t值的anchor作为正样本点,其余的为负样本。另外,训练的时候还会计算一个新loss,用来对齐分类和定位。
2) Task-aligned Loss
分类目标函数
为了显式的增加对齐的anchor的得分,减少不对齐的anchor的得分,我们用t来代替正样本anchor的标签。我们发现,当α和β变换导致正样本的标签变小之后,模型无法收敛,因此,我们使用了归一化的t,这个归一化有两个性质:1)确保可以有效学习困难样本,2)保持原来的排序。

公式中tˆ,是标准化后的t,来替换损失中的目标。
TOOD文中其实还有借鉴focal loss的思想,得到最后的损失函数,但PP-YOLOE中没有提及,我也就不放到本文中了。
消融实验
不同分配策略在COCO train2017上训练36epochs的结果。

5. ET-head(Efficient Task-aligned Head)
T-head:
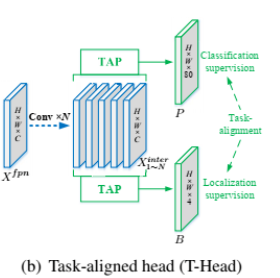
飞浆在T-head的基础上,改进得到ET-head。

对比可以看到,飞浆使用ESE代替TOOD中的层注意,将分类分支的对齐简化为shortcut,用分布焦点损失(DFL)层代替回归分支的对齐。
对于分类任务和定位任务的学习,作者分别选择了Varifocal Loss(VFL)(来自论文VarifocalNet)戳这里和Distribution focal loss(DFL)(来自论文Generalized Focal Loss)戳这里
1)Varifocal Loss(VFL)
Varifocal Loss由Focal Loss演化而来,
其中,α是用来平衡正负样本的权重, 和 用来调制每个样本的权重,使得困难样本有较高的权重,避免大量的简单的负样本主导了训练时候的loss。借用了Focal Loss中的这种加权的思想,用Varifocal Loss来训练回归连续的IACS,和Focal Loss不一样的是,Focal Loss对于正负样本的处理是相同的,而这里是不对等的,所以Varifocal Loss定义为:
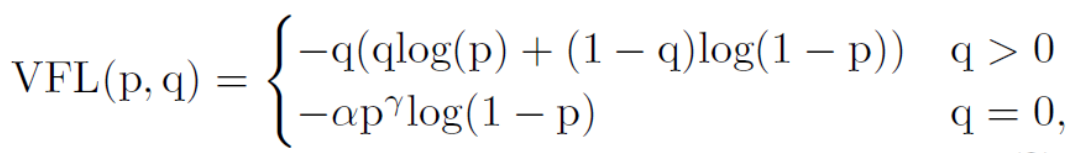
其中p是预测的IACS,q是目标IoU得分,对于正样本,q是预测包围框和gt框之间的IoU,对于负样本,q为0。
2)Distribution focal loss(DFL)
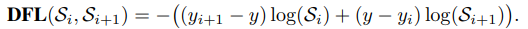
其中:
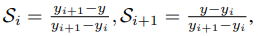
消融实验

性能

笔者思考总结
1.关于PP-YOLOE速度上的提升
PP-YOLOE和YOLOX整体的结构相差不大,但在速度上有很大的提高,在-s模型上,甚至提升了74%!
这么大的提高,我认为除了模型本身的优化和tricks的使用外,残差结构的大量使用,也有一定影响。模型中所有部件,从backbone和neck中的RepResBlock、CSPRepResStage到ET-head中的shortcut和ESEBlock,无不使用或借鉴了残差结构。
虽然残差结构的主要作用是解决网络退化问题,使得层间信息传播更加顺畅,但在较高层间使用残差结构,不可置否地使得计算开销减小。
2.关于PP-YOLOE精度上的提升
因为还没有完全开源的代码(再吐槽一下飞浆只给接口😓),不好直接debug各个部件进行对比,以后有机会再将此部分补充完整。

















 1604
1604











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











