






摘要
我们在之前
PP-YOLOv2
的基础上进行了优化,使用
无锚
范式,更强大的主干和颈部配备了
CSPRepResStage
。
ET-head
和动态标签分配算法
TAL
。
1
、介绍
受
YOLOX
的启发,我们进一步优化了之前的工作
PP-YOLOv2
。
PP-YOLOv2
是一款高性能单级探测器。基于PP-YOLOv2
,我们提出了一个
YOLO
的进化版本,命名为
PP-YOLOE
。
PP-YOLOE
避免使用像可变形 卷积和矩阵NMS
这样的运算符来在各种硬件上得到很好的支持。此外,
PP-YOLOE
可以很容易地扩展到 具有不同计算能力的各种硬件的一系列模型。这些特性进一步推动了PP-YOLOE
在更广泛的实际场景中 的应用。
2
、方法
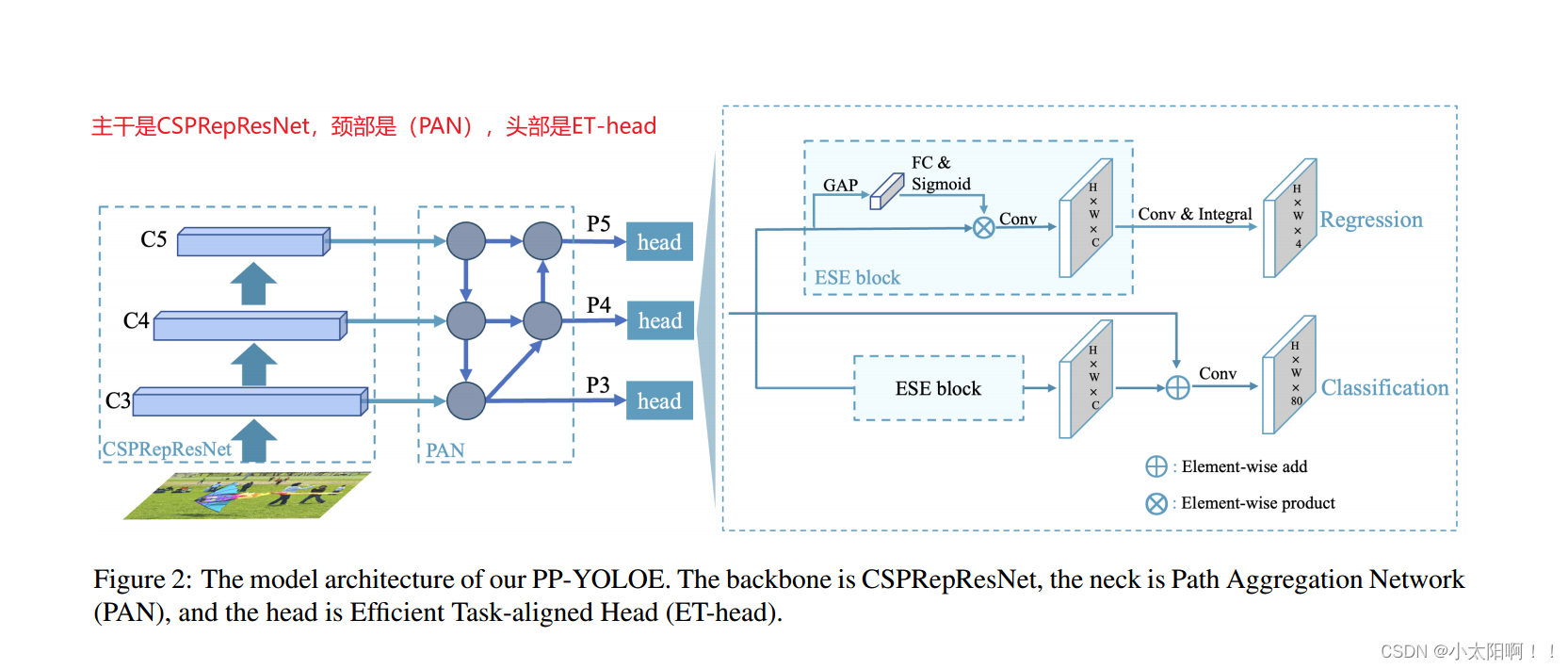
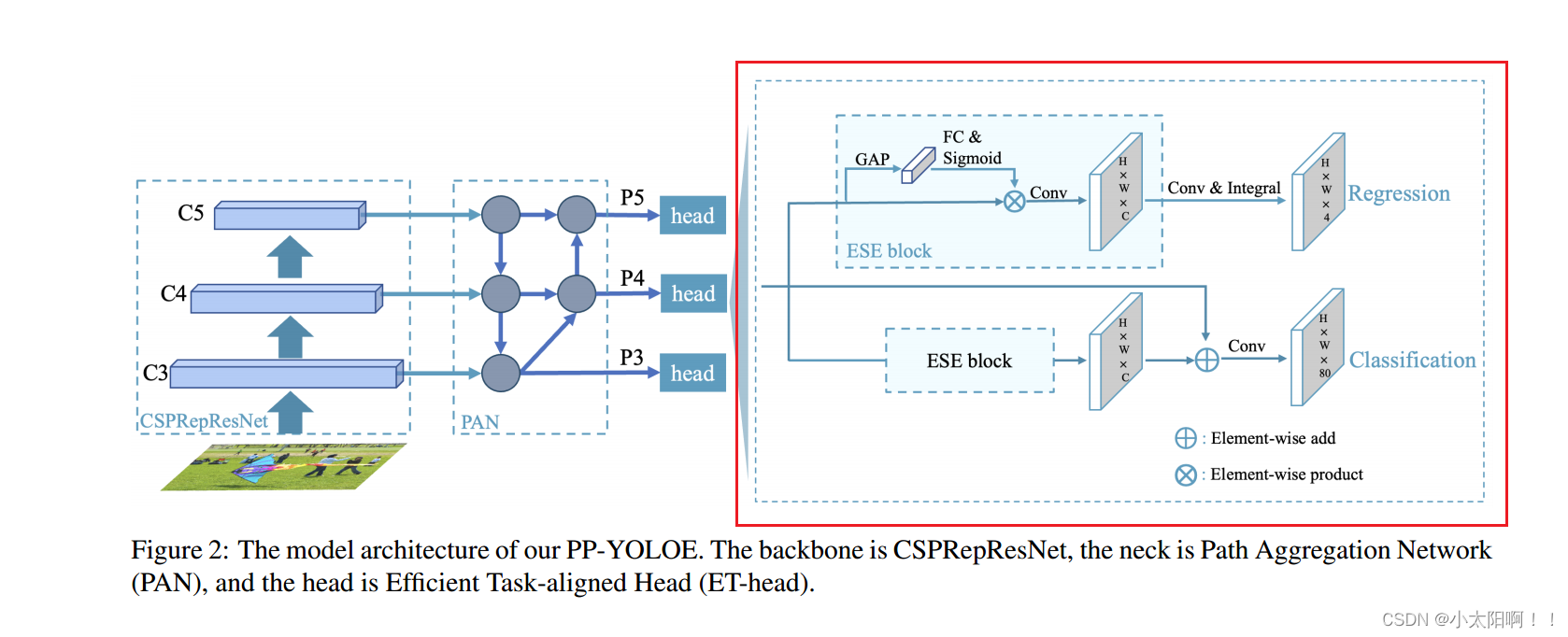
本节中,我们将首先回顾我们的基线模型,然后从网络结构、标签分配策略、头部结构和损失函数等方面详细介绍PP-YOLOE
的设计,如图
2
所示。
2.1PP-YOLOv2
简介
PP-YOLOv2
的整体架构包括具有可变形卷积的
ResNet50-vd
的主干、具有
SPP
层和
DropBlock
的
PAN
颈部以及轻量级IoU
感知头。在
PP-YOLOv2
中,
ReLU
激活功能用于主干,而
mish
激活功能用于颈部。在YOLOv3之后,
PP-YOLOv2
仅为每个
ground truth
对象分配一个
anchor
盒。除了分类损失、回归损失和对象损失外,PP-YOLOv2
还使用
IoU
损失和
IoU
感知损失来提高性能。
2.2 PP-YOLOE
的改进
anchor free
。如上所述,
PP-YOLOv2
以基于锚的方式分配
ground truth
,然而,
anchor
机制引入了许多超参数,并依赖手工设计,这可能无法在其他数据集上很好的推广。基于上述原因,在PP-YOLOv2
中 引入了无锚方法。在
FCOS
之后,我们为三个检测头设置上限和下限,以将
ground truth
分配给相应的
特征图
。
然后,计算边界框的中心,以选择最近的像素作为正样本
。在
YOLO
系列之后,预测
4D
向量 (x,y,w,h)
用于回归。尽管根据
PP-YOLOv2
的锚点大小仔细设置了上下限,但基于锚点和无锚点的方式之间的分配结果仍然存在小的不一致,这可能会导致精度下降。
Backbone
和
Neck
.
残差连接和密集连接已被广泛用于现代卷积神经网络。
残差连接
引入了
缓解梯度消
失问题的捷径
,也可以被视为一种模型集成方法。
密集连接聚合
了具有
不同感受野的中间特征
,在对象检测任务中表现出良好的性能。CSPNet
利用跨级密集连接在不损失精度的情况下降低计算负担,这在YOLOv5、
YOLOX
等有效物体探测器中很受欢迎。
VoVNet
和随后的
TreeNet
在对象检测和实例分割方面也表现出优异得性能。受这些工作的启发,我们提出了一种新的RepResBlock
,将残差连接和密集连接相结合,用于我们的主干和颈部。源自TreeBlock
,我们的
RepResBlock
如图
3(b)
所示,在训练阶段,在推理阶段如图3(c)
所示。首先,我们
简化了原始
TreeBlock
(如图
3(a)
)。然后,我们
将级联运算替换为
逐元素加法运算
(图
3
(
b))
,因为这两个运算在某种程度上是近似的,如
RMNet
。因此,在推理阶段, 我们将RepResBlock
重新参数化为基本残差块(图
3(c))
,由
ResNet-34
以
RepVGG
风格使用。我们
使用建
议的
RepResBlock
来构建主干和颈部
。与
ResNet
类似,我们的
主干名为
CSPRepResNet
,
包含一个由
三个卷积层组成的主干和由我们的
RepResBlock
堆叠的四个后续阶段,如图
3(d)
所示。
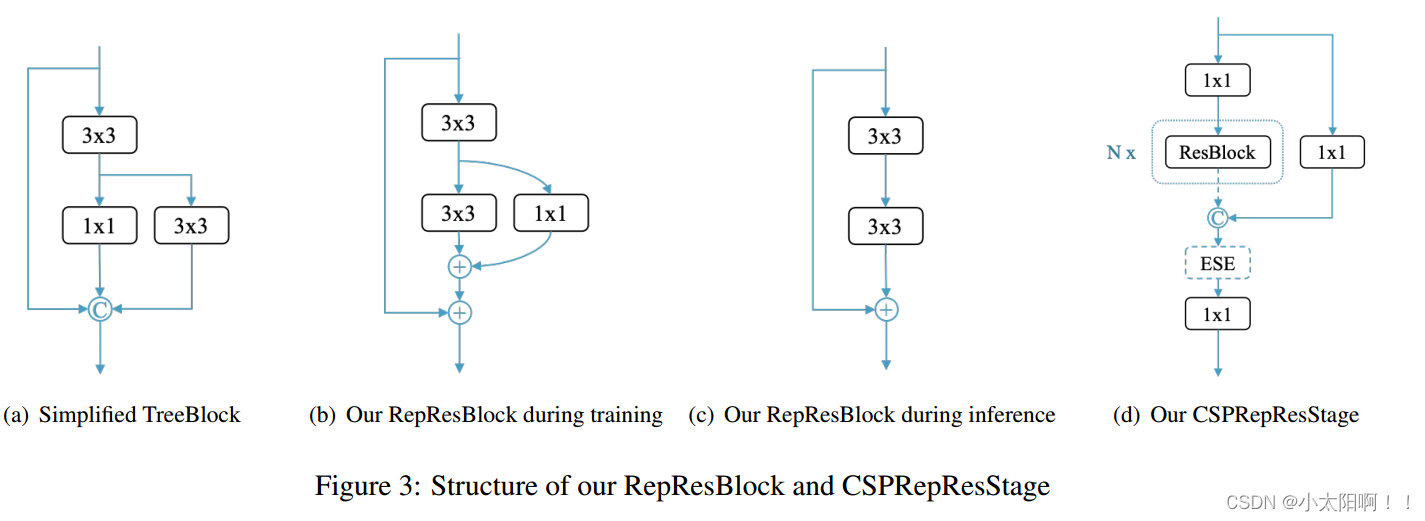
在每个阶段,使用跨阶段部分连接来避免大量
3x3
卷积层带来的大量参数和计算负担。
ESE
(有效挤压和
提取)层也用于在每个
CSPRepResStage
中施加通道注意力
,同时构建主干。我们在
PP-YOLOv2
之后使用拟议的RepResBlock
和
CSPRepResBlock
构建颈部。与主干不同,
推理阶段,
RepResBlock
中的快捷
方式和
CSPRepResStage
中的
ESE
层在颈部被删除
。
我们使用宽度系数
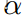 和
深度系数
和
深度系数
 来
联合缩放基本骨干和颈部,如
YOLOv5
。因此,我们可以得到一
系列具有不同参数和计算成本的检测网络。基于主干的宽度设置为
[64,128,256,512,1024]
。除主干外
基本主干的深度设置为
[3,6,6,3]
。基本颈部的宽度设置和深度设置分别为
[192,384,768]
和
3.
表
1
显示了不
同模型的宽度系数和深度系数的规格。如表
2
所示,此类修改可获得
0.7%
的
AP
性能改进。
来
联合缩放基本骨干和颈部,如
YOLOv5
。因此,我们可以得到一
系列具有不同参数和计算成本的检测网络。基于主干的宽度设置为
[64,128,256,512,1024]
。除主干外
基本主干的深度设置为
[3,6,6,3]
。基本颈部的宽度设置和深度设置分别为
[192,384,768]
和
3.
表
1
显示了不
同模型的宽度系数和深度系数的规格。如表
2
所示,此类修改可获得
0.7%
的
AP
性能改进。
TAL
(任务协调学习)
。为了进一步提升性能,标签分配是需要考虑的另一个方面。
YOLOX
使用
SimOTA
作为标签分配策略来提高性能。然而,为了进一步克服分类和定位的错位,
在
TOOD
中提出了任
务对齐学习(
TAL
)
,它由动态标签分配和任务对齐损失组成。动态标签分配意味着预测
/
损失感知。
根
据预测,它为每个
ground truth
分配动态数量的正锚
。
通过明确对齐这两个任务,
TAL
可以同时获得最
高的分类分数和最精确的边界框。
对于任务对齐损失,
TOOD
使用标准化的t,即
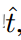 来替换
损失中的目标。它
采用每个实例中最大的
IoU
作
为规范化
。
分类的二进制交叉熵(
BCE
)可以重写为:
来替换
损失中的目标。它
采用每个实例中最大的
IoU
作
为规范化
。
分类的二进制交叉熵(
BCE
)可以重写为:

我们使用不同的标签分配策略来研究性能。我们在上述修改后的模型上进行了实验,该模型以
CSPRepResNet
为主干。使用
TAL
来取代
FCOS
风格的标签分配。
高效任务协调
Head
(
ET-head
)
。在目标检测这中,分类和定位之间的任务冲突是一个众所周知的问题。许多论文[5,33,16,31]
提出了相应的解决方案。
YOLOX
的解耦头借鉴了大多数一级和两级探测器的
经验
,并成功应用于
YOLO
模型,提高了精度。
然而
,
解耦的头部可能会使分类和定位任务分离和独
立,并且缺乏特定任务的学习
。
基于
TOOD
,我们改进了
head
,并提出了
ET-head
,目标是速度和准确性。如图2
所示,我们
使用
ESE
代替
TOOD
中的层注意力
,
将分类分支的对齐简化为快捷方式,并用分布
焦点损失(
DFL
)层代替回归分支的对齐
。经过上述变化,
ET
头在
v100
上增加了
0.9ms
对于分类和定位任务的学习,我们分别选择变焦距损失(
VFL
)和分布焦距损失(
DFL
)
。
PP-Picodet成功地将VFL
和
DFL
应用于物体探测器,并获得了性能的提高。对于
[33]
中的
VFL
,和
[16]
中的质量焦点损失(QFL
)不同,
VFL
使用目标分数来加权阳性样本的损失
。这种实现使得具有高
IoU
的正样本对损耗的贡献相对较大。这也使得模型在训练时更加关注高质量的样本,而不是那些低质量的样本。相同的是,两者都使用
IoU
感知分类得分(
IACS
)作为预测目标
。这可以有效地学习分类得分和定位质量估计的联合表示,从而实现训练和推理之间的高度一致性。对于DFL
,为了解决边界框表示不灵活的问题, [16]提出使用一般分布预测边界框。我们的模型受损失函数的监督:
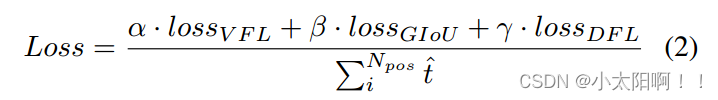















 178
178











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









