







在实际系统我们会接触到许许多多的文本类型数据。如何将这部分数据用于作为机器学习模型的输入呢?一个常用的方法是将文本转化为一个能很好的表示它的向量,这里将称该向量称作为文本向量。本文将以尽可能少的数学公式介绍目前业界比较流行的基于神经网络进行文本特征提取,得到文本向量的方案。
1. 背景知识
这部分内容将介绍线性回归、梯度下降、神经网络、反向传播。对于有基础的同学这部分可以跳过,对于之前没有接触过相关知识点的同学,我会用尽可能少的公式去介绍。希望能讲明白 ==
1.1 线性回归模型
其实线性回归模型很简单,它类似于我们中学学的多元一次方程的形式,如:
![]()

1.2 梯度下降
哪我们如何找到最佳的参数W和b呢?业界最流行的方法就是使用梯度下降。 
梯度下降法的形象化说明: 
在这个碗形图中,横轴表示参数W和b,在实践中,可以是更高的维度。
如图那个小红点,采用随机初始化的方法初始化的参数W和b:

我们的目标是将它下落到碗形图的最底部,即min(J(w,b)):
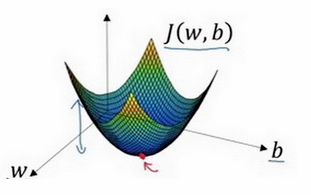
那红点会怎么下落呢?回想下中学学的物理就很形象了,我们先只看ww轴。没错,沿着斜率方向下降,红点会快的接近碗底。

当然,如何一直沿着最初的斜率方向走是不能到达碗底的,而应该一小步一小步的走,每走一步调整方向为当前的斜率方向:
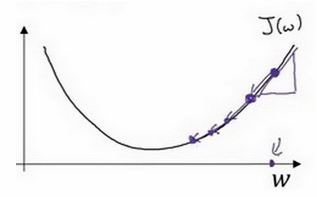
对于b轴也类似,那么红点就会如下图一步一步的下降:

于是每一步我们更新参数为:

其中 α 为每一步的步长。
这样不断的迭代,不断的下降,参数W和b的取值就不断的被优化了。
1.3 神经网络
我们先来介绍单个神经元的模型结构,如下图:


1.3.1 激活函数
唯一不同的是神经元里面还可以存在激活函数,如果神经元没激活函数,那么就和上文讲的线性回归模型基本上一模一样。常见的激活函数有:
- sigmoid函数

-Tanh函数

-ReLU函数

![]()
为什么需要有这么多激活函数呢?激活函数是为了让神经网络具有非线性的拟合能力。其实激活函数的选择也还在不断演进,是学术界热门研究方向,我们也可以自己创造激活函数。激活函数适用也不同,如ReLU函数能有效的预防梯度消失问题,而sigmoid函数能讲回归问题转化为二分类问题。
1.3.2 神经网络介绍
理解了基础的神经元模型,神经网络就很好理解了。神经元就像一块乐高积木,而神经网络就是搭的积木。

如上图,x那一列,我们称为输入层,输出y^那列称为输出层,中间那列称为隐藏层。隐藏层可以有多个,而且每个隐藏层有多少个神经元也都是可以自主调整的。经典的神经网络中,当前层的神经元会后后一层的各个神经元进行连接,这也称为全连接。
1.3.2.1 前向传播
上图是形象化的神经网络模型结构图,那实际上模型的特征输入到预测输出,在数学上、在内存里是怎么实现的呢?这里我们来介绍下从输入层到第一个隐藏层的向前传播的过程。
首先,输入的特征向量(数组):
![]()
它会与权重矩阵(二维数组)相乘

加上偏置向量(数组):

最后送入激活函数,如tanh函数:
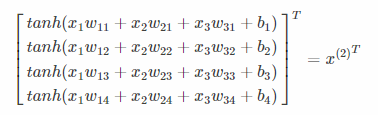
1.3.2.2 反向传播
神经网络这么多参数该如何优化呢?其实和上文说的一样,我们还是使用梯度下降的方法。最后一层的权重调整我们可以与梯度下降的方法求出。最后第二层我们可以基于最后一层的权重调整,利用链式求导的方式求出。就这样从后往前的调整,这就是所谓的反向传播。
2. 词汇特征表示
完成我们的背景知识回顾学习之后,就进入我们正式要讲解的内容了。
2.1 语言模型
这里我们先介绍一个概念——语言模型。简单来讲,语言模型就是一个想让机器学会说话的模型。它会基于给定的上文,预测出最有可能的下文。比如说,“I want a glass of orange __ ”,输入前文,模型将预测出空格可能的单词为“juice”。
2.2 词嵌入
现在我们有一个词典,如:【a,apple,…,zoo,】,其中代表未知单词。假设我们的词典里里面一个有10000个单词,那如何用生成某个词汇特征表示呢?一个很容易想到的方法就是one-hot:用一个10000维的向量来表示一个词语。 
但是这种方法有两个致命缺点:
- 第一,向量实在是太长了,而且词汇量增加,向量维度也要跟着增加。
- 第二,该向量部分表示出词汇之间的关系。如我们给出“I want a glass of orange juice”作为训练数据,模型是学不到“I want a glass of apple _”该填什么的。因为orange的特征表示和apple的特征表示之间没有任何的关系。
为了解决上述缺点,我们可以手工的做词嵌入:
Topic| Man | Woman|King|Queen|Apple|Orange
|:-|:-|:-|:-|:-|:-|:-
Gender |-1| 1 |-0.95|0.97|0.00|0.01
Royal | 0.01 | 0.02 |0.93|0.95|-0.01|0.00
Age | 0.03 | 0.02|0.7|0.69|0.03|-0.02
Food | 0.09 | 0.01|0.02|0.01|0.95|0.97
…|…|…|…|…|…|…
我们选取几个Topic,每行是各个单词关于该Topic的相关系数。这样一来,我们可以看到向量的维度大小得到了控制,而且词与词有明显的关系。我们还能惊喜的发现King的向量减去Man的向量,再加上Woman的向量,就约等于Queen的向量!
3 word2vector
词嵌入固然好,但手工的为10000个词语关于各个Topic打相关系数 ,这需要耗费巨大的人力,而且要求非常深厚的语言词汇知识。
Google大神们提出了目前非常流行的训练词向量的算法——word2vector[1]word2vector[1]。我们先来看看word2vector强大的的效果吧:

上表是783M的单词,训练出的300维度的词向量,得到的对应关系。比如,使用vParis−vFrance+vItalyvParis−vFrance+vItaly得到的向量v1v1,在字典里查询与它最相似的是向量vRomevRome(可以用cos相似度进行度量)。
3.1 基于神经网络语言模型的词向量生成
再讲word2vector之前,我们先来讲讲另外一种模型——基于神经网络语言模型[2]。其实Google大佬在论文【1】中也实验了用该模型生成词向量,word2vector算法也就是在这个基础上进行的变形、优化。模型结构如下: 
- 第一层:上图中绿色的小方块就是我们每个单词的onehot后的向量,比如说我们想语言模型要预测“I want a glass of apple _”问题,我们固定4个单词的窗口,那么就有4个绿色小方块的特征输入,即分别为“a”,“glass”,“of”,“ apple”对应的one-hot向量。
- 第二层:各个one-hot向量(10000维)会乘以10000∗300大小的共享矩阵CC。其实这里的CC就是我们前文的词嵌入矩阵的转置。每列类别代表一个Topic,只是里我们并不知道其具体含义。而每一行就是对应单词的词向量。
- 第三层:乘完的向量(300维)会将其连接起来(4∗300=1200维),并代入tanh函数得到值作为该层的输出。
- 第四层:第四层有10000个神经元,第三层到第四层使用的是全连接,而且神经元非常多,需要很大的计算资源。
- Softmax:我们最后输出的是一个向量V(10000维),Vi表示V中的第i个元素,那么这个元素的Softmax值就是 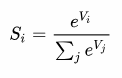
也就是说,是该元素的指数,与所有元素指数和的比值。这样一来,向量S的各个元素就表示预测为对应位置单词的概率。真实值yy这里将是单词,如“juice”,所对应的one-hot向量。
这么一来,我们就可以使用反向传播与梯度下降优化调整网络中的参数,同时也就调整生成了共享矩阵C,即我们的词向量矩阵。
3.2 word2vector
其实理解了基于神经网络语言模型的词向量生成模型,word2vector模型就非常好理解了。word2vector有两种形式——CBOW 和 Skip-gram。
3.2.1 CBOW模型
不同于神经网络语言模型去上文的单词作为输入,CBOW模型获得中间词两边的的上下文,然后用周围的词去预测中间的词。
与神经网络语言模型还有点不同的是:经过词嵌入后,CBOW模型不是将向量合并,而是将向量按位素数相加。
3.2.2 Skip-gram模型
Skip-gram模型正好和CBOW模型相反,输入为中间的词,使用预测两边的的上下文的单词。
3.2.3 加速Softmax
从上文我们可以看到,最后的输出层有10000个节点,显然这部分需要消耗非常大的计算资源。这里介绍两种加速的方法:
- hierarchical softmax:softmax不再使用one-hot编码,而是利用哈夫曼编码,这可以使得复杂度降低到log2V,其中V为字典长度。
- 负采样:负采样是将模型变成只用一个输出节点的2分类任务模型。我们将单词与其一个附近的单词向量连接,如[Vorange,Vjuice],作为特征输入,Label为1。再将该单词与其不它附近的单词向量连接,如[Vorange,Vman],Label为0。我们使用这样构造出数据集进行词向量的训练。
4 文本向量
现在我们有了词向量,那对于一个文本,如何用一个向量来表示它呢?
4.1 fastText模型
Facebook的大牛们基于word2vector词向量设计了fastText文本分类模型[3][3]。其实它的结构也很简单,就是将各个词向量相加,作为其文本的向量表示: 
除此之外, fastText还添加了N-gram特征,这里就不再介绍,感兴趣的同学可见【3】
4.2 文本分布表示
fastText是目前非常流行的文本分类的模型,但是直接将各个词向量相加存在一个很大的缺点,就是消除了词序的特征。如“mother loves dad”和“dad loves mother”,在这种文本特征生成方案下,它们的文本向量就一模一样了。
Google的大牛们基于word2vector模型也设计出了文本向量生成的方案。该方案的核心思想就是:将文档看做一个特殊的单词。该方案有两种形式——分布记忆模型和分布词包模型[4]。
4.2.1 分布记忆模型
分布记忆模型将文档id看做一个特殊的单词,设窗口大小为3,那么输入的特征为文档id和该文本的三个单词(按顺序),Label则是下一个单词。不断迭代,直到窗口移动到文末。所有文档训练结束后,文档id所对应的词向量就是该文档的文本向量。该方案保留了词语间的词序信息: 
4.2.2 分布词包模型
分布词包模型也将文档id看做一个特殊的单词,不同的是,它套用了Skip-gram的结构。该方案不保留了词语间的词序信息:

4.3 深度学习模型
最近深度学习非常热门,输入词向量特征,基于深度学习模型也可以进行文本的特征学习:
- CNN:卷积神经网络模型可以抽取部分单词作为输入特征,类似于n-grams的思想 [5]:

4.4 简单词嵌入模型
无论是文本分布表示还是上深度学习模型,对于在线实时预测的机器学习系统都有较大的性能挑战。今年最新提出的简单词嵌入模型(SWEM)关注到了这个问题,论文提出了更加简单轻量的文本向量生成方案[7][7]:
- SWEM-aver:就是平均池化,对词向量的按元素求均值。这种方法相当于考虑了每个词的信息。
- SWEM-max:最大池化,对词向量每一维取最大值。这种方法相当于考虑最显著特征信息,其他无关或者不重要的信息被忽略。
- SWEM-concat:考虑到上面两种池化方法信息是互补的,这种变体是对上面两种池化方法得到的结果进行拼接。
- SWEM-hier:上面的方法并没有考虑词序和空间信息,提出的层次池化先使用大小为 n 局部窗口进行平均池化,然后再使用全局最大池化。该方法其实类似我们常用的 n-grams 特征。
论文将SWEM方案生成文本向量,输入到神经网络分类器:隐藏层[100, 300, 500, 1000]与一个softmax输出层。论文将它和其他模型在不同数据集上进行了文本分类预测正确率的对比:
可见,SWEM-concat 和 SWEM-hier 表现非常的优秀,甚至超过了复杂的深度学习模型。
参考文献
【1】Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013). Efficient estimation of word representations in vector space. Computer Science.
【2】Bengio, Yoshua, et al. A neural probabilistic language model.. Innovations in Machine Learning. Springer Berlin Heidelberg, 2006:137-186.
【3】Joulin A, Grave E, Bojanowski P, et al. Bag of Tricks for Efficient Text Classification[J]. 2016:427-431.
【4】Le Q, Mikolov T. Distributed representations of sentences and documents[C] International Conference on International Conference on Machine Learning. JMLR.org, 2014:II-1188.
【5】Kim Y. Convolutional Neural Networks for Sentence Classification[J]. Eprint Arxiv, 2014.
【6】Vinyals O, Le Q. A Neural Conversational Model[J]. Computer Science, 2015.
【7】Shen D, Wang G, Wang W, et al. Baseline Needs More Love: On Simple Word-Embedding-Based Models and Associated Pooling Mechanisms[J]. 2018.















 3197
3197











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









