






1. 引入:为什么传统搜索和大模型都不够好?
1.1 传统搜索引擎的局限
我们每天都使用搜索引擎(比如谷歌、bing、百度)来查找信息。假设你遇到一个问题:“我的智能家居设备连接不上Wi-Fi,怎么办?”
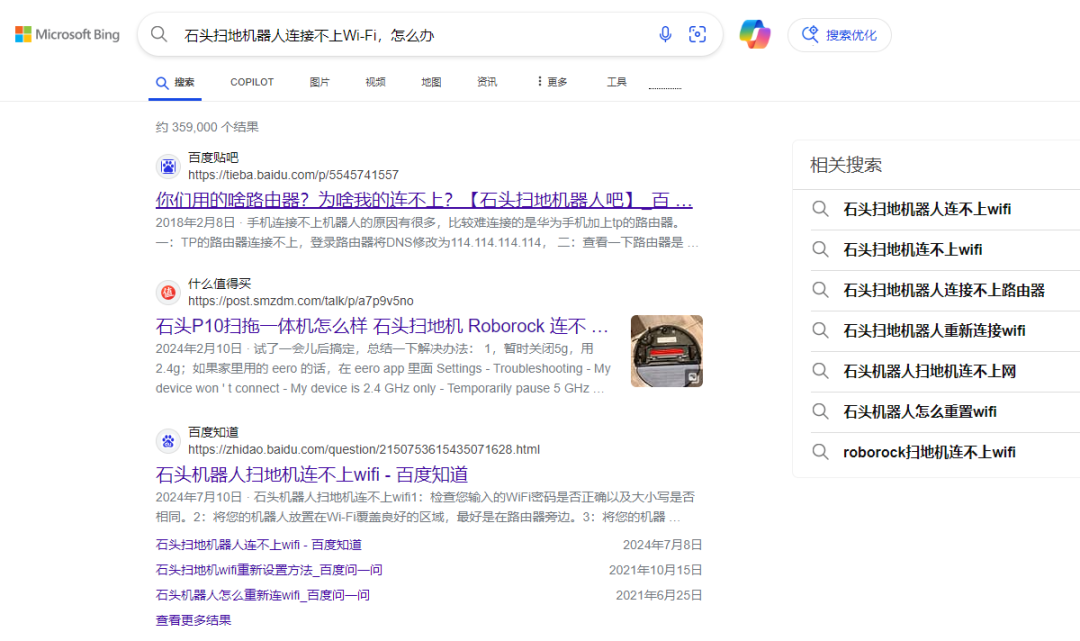
bing搜索
问题:如果你输入的关键词不够精准,或者信息不够详细,搜索引擎返回的结果可能就不完全符合你的需求。
搜索引擎通常依赖于精确的关键词匹配,这就要求你明确知道自己想查的具体内容。
如果你对问题描述不够清楚,找到准确的答案就变得困难。
1.2 直接大模型的局限
现在有了像ChatGPT、Kimi、豆包、通义千问等大模型,大家可能会直接问:“那直接找个大模型不行吗?”
问题:大模型的确可以根据训练数据回答各种问题,但它的知识库是有限的,而且不能实时更新。
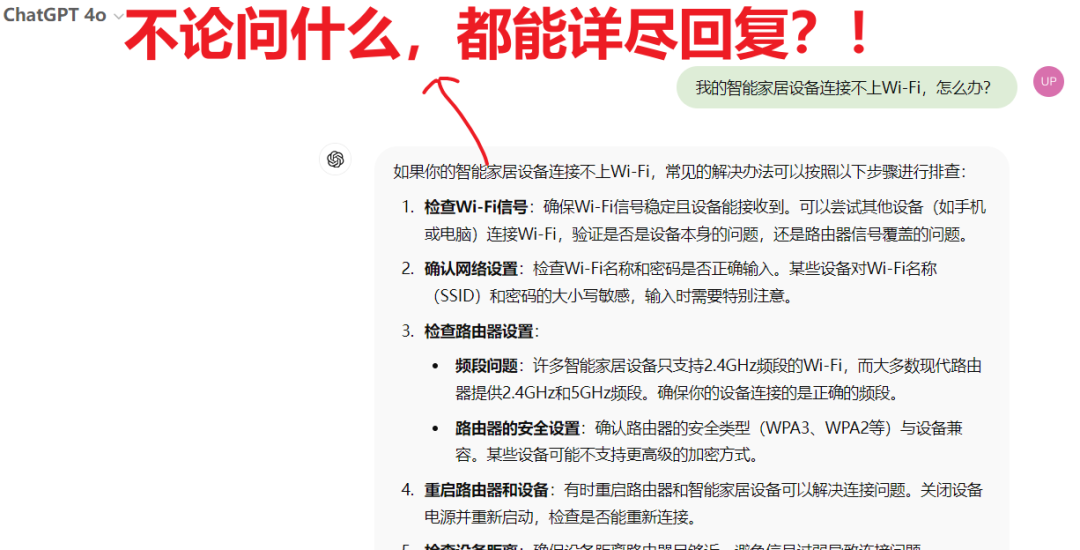
ChatGPT 01模型
例如,今天的网络设备问题或者技术支持,大模型可能无法给出最准确、最实时的答案,尤其当问题涉及到一些新的技术细节或复杂的实际场景时。
我这边近 2 年+ ChatGPT 付费使用感受就是,当某个知识库大模型相对不完备、且互联网上能搜到资源非常有限的时候,大模型就捉襟见肘了。
比如你公司内部不公开文档、内部论坛相关技术问题(公司不开放外网权限),再厉害的大模型也搞不定。
比如搜索最近濒临倒闭大火的某越汽车的某零部件换修保养,估计就很难找到资料。
1.3 这时候就需要 RAG(检索增强生成) 技术
那么,有没有一种方法,既能避免搜索引擎要求精确关键词的麻烦,又能克服大模型只能给出过时信息的缺点呢?
答案就是 RAG技术,它通过实时检索相关信息,并结合大模型生成能力,给你提供更加精准、实时、丰富的答案。
2. 向量检索——RAG技术的核心推动力
RAG 能够在大规模的数据中快速检索最相关的内容,背后起关键作用的就是向量检索。
向量检索的工作原理
向量检索通过将文本转化为向量(数字表示),计算文本之间的相似度,从而找到最相关的信息。
在吴恩达的Coursera《机器学习》课程中,向量化被描述为将原始数据转化为机器学习算法能够理解和处理的数字格式。

《机器学习》课程
例如,文本数据需要被转换成数值向量,以便进行分类、回归等任务。
在该课程中,吴恩达强调向量化是数据预处理中的关键步骤,它使得机器学习算法能够处理多维特征数据并从中提取模式和规律。
这种转化不仅限于文本数据,也适用于图像、语音等其他数据形式,目的是将复杂的信息表示为统一的数值形式,以便进行进一步的分析和建模。
这种方法的优势在于,不仅仅匹配表面上的关键词,而是通过语义匹配来找到真正相关的内容。
将问题和文档转化为向量
每个问题和每篇文档都会被转换成一个向量,这个向量表示了文本的语义信息。
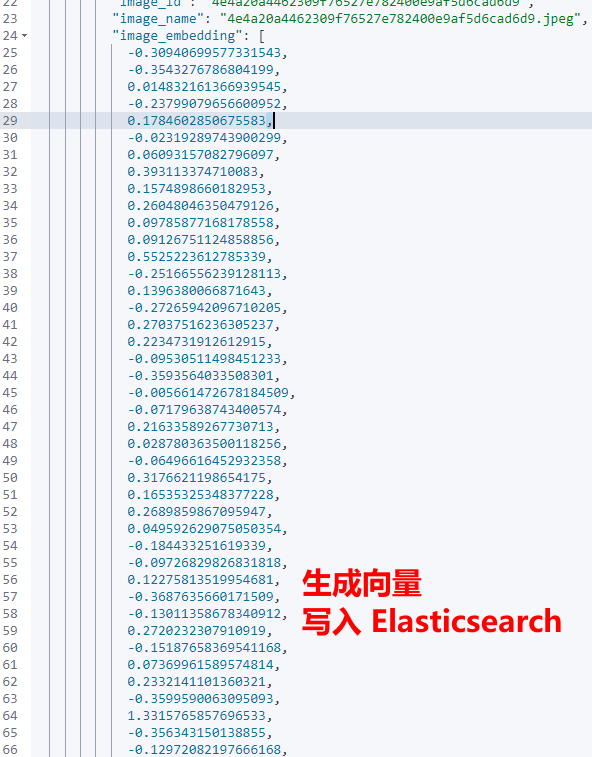
2. 计算向量之间的相似度
RAG通过计算问题向量与文档向量之间的相似度,快速找到最相关的资料。
图片来自网络
3. 通过高效的检索返回答案
向量检索能在海量数据中快速找到相关信息,避免了传统基于关键词的匹配方式,提升了检索的准确性和效率。
3. RAG 技术的工作流程
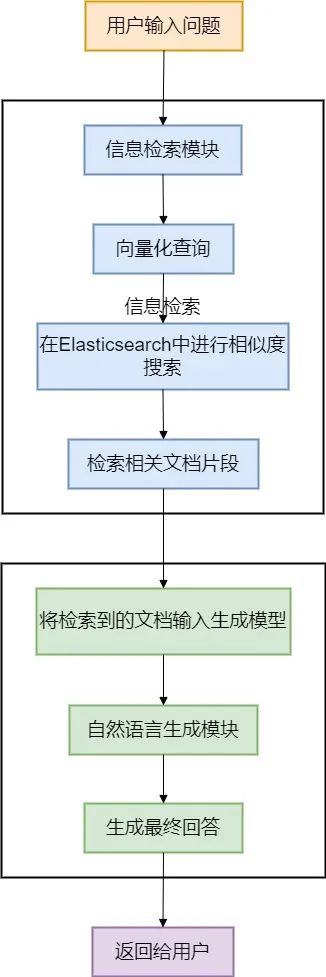
用Elasticsearch做RAG项目流程示意图
3.1 本地知识库向量化存储
在RAG技术的应用中,首先需要将本地知识库进行向量化存储。
这一步是将所有文档、手册、FAQ、历史解决方案等数据转化为计算机能够理解的数字格式(即向量)。
通过这种方式,RAG能够更快速、更精确地检索到与用户问题相关的内容。
如前所述,向量化的知识库让信息不再是原始的文本数据,而是可以通过向量搜索快速定位和检索的资源。这是信息检索效率的保障。
3.2 信息检索(Retrieval)
当我们提出问题时,例如:“我的智能家居设备连接不上Wi-Fi,怎么办?”
RAG会通过向量化存储的本地知识库来进行信息检索。
系统首先根据问题的关键词或语义,快速检索出相关的文档、故障排查手册、用户评论或设备技术规格等最新资料。这种检索方式不再依赖于精确的关键词匹配,而是通过语义理解来找到与问题最相关的信息,确保回答不仅是基于已有知识库,还包含了最新和最相关的数据(取决于我们知识库更新频率)。
3.3 生成回答(Generation)
接下来,RAG 将检索到的相关信息传递给一个大型语言生成模型(如阿里开源的通义千问Qwen-7B、Qwen-14B模型)。

该模型将这些信息综合整理,生成一个清晰、完整且连贯的回答。
通过生成模型,RAG能够结合外部检索到的信息生成一个更有深度和广度的回答。
例如提供Wi-Fi连接问题的具体排查步骤、常见设备设置问题、操作系统兼容性、可能的固件升级建议等,而不是仅仅生硬的、毫无情感的复述知识库中的内容。
4. 为什么 RAG 技术这么强大?
4.1 不依赖精确的关键词
传统的搜索引擎需要精确的关键词,而RAG不需要。你只需给出大概的描述,RAG就能通过向量检索找到最相关的信息。
例如:前文提及的“智能家居设备 连接不上Wi-Fi”——这个描述虽然不完全准确,但RAG依然能理解并找到相关资料,给出最合适的回答。
4.2 实时获取最新的信息
大模型只能回答基于自己训练时的数据内容,但这些内容通常是固定的,无法获取实时更新的信息。
而RAG通过实时检索知识库,能够为你提供最新的数据和信息。
比如,还是刚才的问题“我的智能家居设备连接不上Wi-Fi,怎么办?”时,RAG能基于本地知识库最新的设备故障排查资料,提供最准确、最实用的解决方案,而不是依赖老旧的、过时的技术支持信息。
也就是咱们本地知识库不能一成不变,要不定时更新知识库。
4.3 扩展知识面,覆盖更多领域
RAG 不仅依赖大模型自带的知识库,它还能借助用户更新的所谓“外部知识库”文档、网站、文章等资源进行检索,回答更多专业领域的问题。
比如,如果你问某个设备连接问题,RAG可以通过搜索设备手册、厂家论坛、其他用户的常见问题解答等,提供更加深刻的解决方案,
而不是简单地给出常见的“一刀切”答案。
4.4 减少错误
有时,传统大模型可能会“胡乱生成”答案,而RAG通过首先检索相关资料,确保答案来源有据可依。这样不仅减少了错误,也提高了答案的可信度。
4.5 答案来源透明,易于追溯
RAG的答案是基于检索到的资料生成的,所以你可以追溯到这些资料的来源,了解答案的出处。
这点对于需要高准确性和高可信度的场景尤其重要,例如技术支持、医疗咨询等。
5. 小结
RAG技术结合了信息检索和大模型生成的优点,突破了传统搜索和大模型的局限。

通过向量检索,它能够在模糊的查询中快速找到最相关的答案,同时提供最新、准确的信息。
这使得RAG不仅能处理复杂的查询,还能生成更加精准、丰富的回答。
不依赖精准关键词
实时更新信息
覆盖广泛领域
减少错误和偏差
答案来源清晰可追溯
如果你希望在企业中构建智能问答系统,或者提升技术支持效率,RAG技术无疑是一个非常有潜力的选择!
我自己也在做相关研究,欢迎大家有问题留言交流。
更多推荐

更短时间更快习得更多干货!
和全球超2000+ Elastic 爱好者一起精进!
elastic6.cn——ElasticStack进阶助手

抢先一步学习进阶干货!


















 1339
1339

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











