









1、题记
这是stackoverflow上一篇精彩的问答。
原文不大好理解,我做了梳理+图解;
原文是ES早期版本,部分写法已不适用,所有DSL我在6.X上进行了重写和验证;
针对原文内容做了扩展。
2、知识库全文检索问题抛出
重新审视一个停滞不前的项目,并寻求建议,对数千个“旧”文档进行现代化改造,
最终期望效果:通过网络访问这些文档。
文档以各种格式存在,有些已经过时:
- .doc,
- PageMaker,
- 硬拷贝hardcopy (OCR),
- PDF
- ……
很多文档已经被转化成扫描版的PDF,之前我们认为PDF类型是最终的文档格式,现在看来,我们想听听建议(比如:xml是不是更好呢?)
核心需求点:
1、一旦所有文档都采用通用格式,我们希望通过网页界面提供其内容并提供搜索服务。
2、我们希望通过搜索,能够灵活地只返回整个文档的部分页面(我相信的Lucene / elasticsearch使这成为可能?!?)
3、如果所有文档是XML是否会更加灵活?
4、如何存储、在哪里存储XML?是直接存储在数据库中还是存储成文件系统中的文件?关于文档中的嵌入式图像/图表呢?
以上,希望得到回复。
注解:xml只是提问者的当时初步的理解。
3、精彩回复
我将推荐ElasticSearch,我们先解决这个问题并讨论如何实现它:
这有几个部分:
- 从文档中提取文本以使它们可以索引(indexable),以备检索;
- 以全文搜索形式提供此文本;
- 高亮显示文档片段;
- 知道文档中的哪些段落可用于分页;
- 返回完整的文档。
ElasticSearch可以提供什么:
- ElasticSearch(如Solr)使用Tika从各种文档格式中提取文本和元数据;
- Elasticsearch提供了强大的全文搜索功能。它可以配置为以适当的语言分析每个文档,它可以借助boost提高某些字段的权重(例如,标题比内容更重要),ngrams分词等标准Lucene操作;
- Elasticsearch可以高亮显示搜索结果;
- Elasticsearch不知道这些片段在您的文档中出现的位置;
- Elasticsearch可以将原始文档存储为附件,也可以存储并返回提取的文本。但它会返回整个文档,而不是一个页面。
【直译】您可以将整个文档作为附件发送到ElasticSearch,并且可以进行全文搜索。但是关键点在于上面的(4)和(5):知道你文档中的位置,并返回文档的某些部分。存储单个页面可能足以满足您的“我在哪里”的目的,但是您希望将它们分组,以便在搜索结果中返回文档,即使搜索关键字出现在不同的页面上。
任务分解:
3.1、索引部分——将文档存储在ElasticSearch中。
使用Tika(或任何你喜欢的)来从每个文档中提取文本。将其保留为纯文本或HTML格式以保留一些格式。
(忘记XML,不需要它)。
每个文档提取元数据:标题,作者,章节,语言,日期等。
将原始文档存储在您的文件系统中,并记录路径,以便以后可以使用。
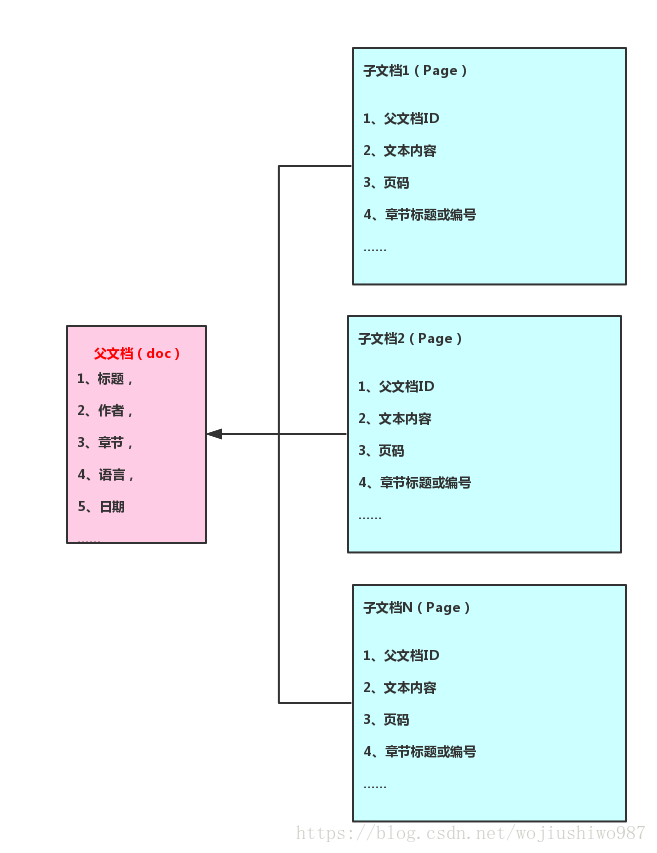
在ElasticSearch中,索引包含所有元数据和可能的章节列表的“doc”文档。
将每个页面索引为“page”文档,其中包含:
- 包含“doc”文档ID的父字段(请参阅下面的“父子关系”)
- 文本
- 页码
- 也许章节标题或编号
- 您想要搜索的任何元数据
存储必备——父子文档关系:
通常,在ES(和大多数NoSQL解决方案)中,每个文档/对象都是独立的 - 没有真正的关系。
通过建立“doc”和“page”之间的父子关系,ElasticSearch确保子文档(即“页面”)与父文档(“doc”)存储在同一分片上。
这使您能够运行has_child等的查询方式,它将根据“page”的内容找到最匹配的“doc”。
图解示例:
二、检索部分——
现在进行搜索。
你如何做到这一点取决于你想如何展示你的结果
- 按页面page分组,
- 按文档doc分组。
通过页面的结果很容易。
此查询返回匹配页面的列表(每个页面全部返回)以及页面中高亮显示的片段列表。
举例如下:
POST /my_index/page/_search?pretty=1
{
"query" : {
"match" : {
"text" : "interesting keywords"
}
},
"highlight": {
"pre_tags": [
"<span style=\"color:red\">"
],
"post_tags": [
"</span>"
],
"require_field_match": true,
"fields": {
"title": {}
}
}
}显示包含文本高亮字段的“doc”分组有点棘手。 它不能用一个单一的查询来完成。
一种方法可能是:
第1步:通过对其子(“页面”)查询,返回最匹配的父级(“doc”)。
POST /my_index/doc/_search?pretty=1
{
"query": {
"has_child": {
"type": "page",
"query": {
"bool": {
"must": [
{
"match": {
"text": "interesting keywords"
}
},
{
"term": {
"type": "page"
}
},
{
"term": {
"factor": "5"
}
}
]
}
},
"score_mode": "sum"
}
}
}第2步:从上述查询中收集“doc”ID 发出新查询,从匹配的“页面”文档中获取片段。
GET /my_index/page/_search?pretty=1
{
"query" : {
"bool" : {
"must":{
"query" : {
"match" : {
"text" : "interesting keywords"
}
}},
"filter" : {
"terms" : {
"doc_id" : [1,2,3]
}
}
}
},
"highlight" : {
"fields" : {
"text" : {}
}
}
}第3步:在您的应用程序中,将上述查询的结果按doc分组并显示出来。
使用第二个查询的搜索结果,您已经拥有了可供显示的页面的全文。要转到下一页,您可以搜索它:
GET /my_index/page/_search?pretty=1
{
"query" : {
"constant_score" : {
"filter" :
[
{
"term" : {
"doc_id" : 1
}
},
{
"term" : {
"page" : 2
}
}
]
}
},
"size" : 1
}或者,给“页面”文档提供一个由doc_id _ doc_id _ page_num(例如123_2)组成的ID,然后您可以通过如下的检索获取该页面:
curl -XGET'http://127.0.0.1:9200/my_index/page/123_23、扩展
Tika是一个内容分析工具,自带全面的parser工具类,能解析基本所有常见格式的文件,得到文件的metadata,content等内容,返回格式化信息。总的来说可以作为一个通用的解析工具。特别对于搜索引擎的数据抓去和处理步骤有重要意义。
Tika是Apache的Lucene项目下面的子项目,在lucene的应用中可以使用tika获取大批量文档中的内容来建立索引,非常方便,也很容易使用。
Apache Tika toolkit可以自动检测各种文档(如word,ppt,xml,csv,ppt等)的类型并抽取文档的元数据和文本内容。
Tika集成了现有的文档解析库,并提供统一的接口,使针对不同类型的文档进行解析变得更简单。Tika针对搜索引擎索引、内容分析、转化等非常有用。
4、有没有现成的开源实现呢?
Ambar是一个开源文搜索引擎,具有自动抓取,OCR识别,标签分类和即时全文搜索功能。
Ambar定义了在工作流程中实现全文本文档搜索的新方法:
- 轻松部署Ambar和一个单一的docker-compose文件
- 通过文档和图像内容执行类似Google的搜索
- Ambar支持所有流行的文档格式,如果需要的话可以执行OCR
- 标记您的文件
- 使用简单的REST
- Api将Ambar集成到您的工作流程中
参考:
2018-06-07 22:43 思于家中床前
作者:铭毅天下
转载请标明出处,原文地址:
https://blog.csdn.net/laoyang360/article/details/80616320
如果感觉本文对您有帮助,请点击‘顶’支持一下,您的支持是我坚持写作最大的动力,谢谢!


















 1902
1902

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











