





LLVIP、KAIST、M3FD数据集
(可见光+红外,双模态数据集,已配准已对齐已清洗,已处理为txt格式,YOLO可直接训练)
电子产品,一经出售,概不退换
算法设计、毕业设计、期刊专利!感兴趣可以联系我。
🏆代码获取方式1:
私信博主
🏆代码获取方式2
利用同等价值的matlab代码兑换博主的matlab代码
先提供matlab代码运行效果图给博主评估其价值,可以的话,就可以进行兑换。
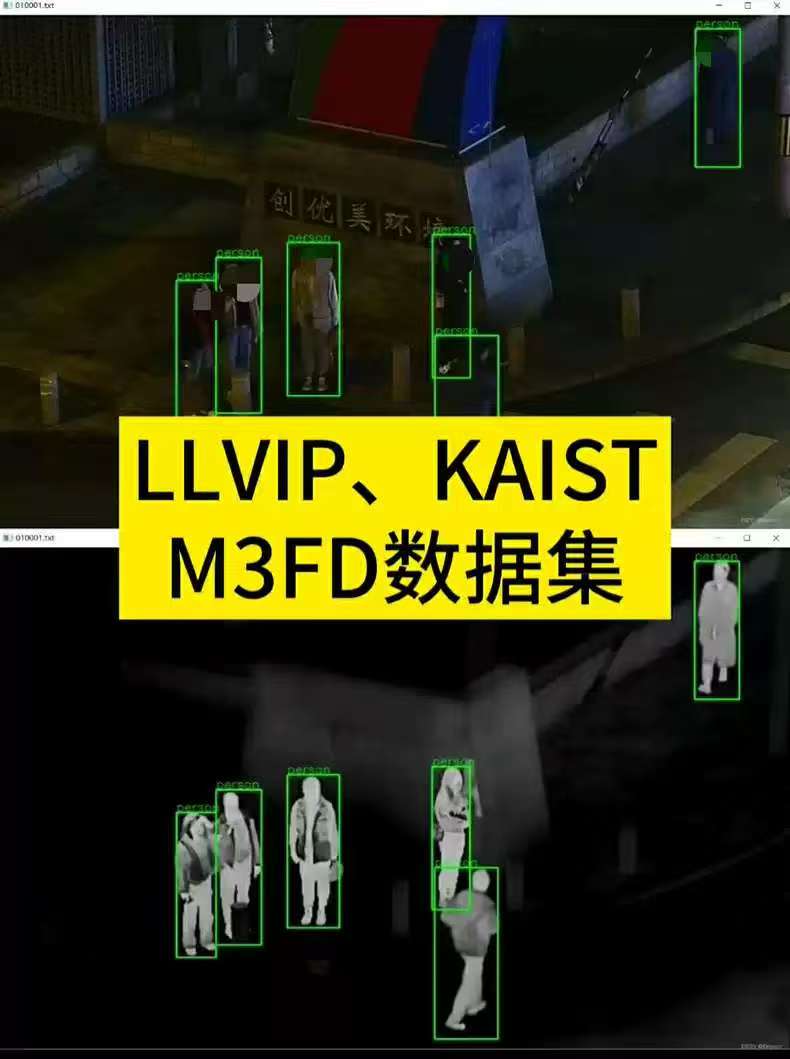

LLVIP、KAIST、M3FD数据集
(可见光+红外,双模态数据集,已配准已对齐已清洗,已处理为txt格式,YOLO可直接训练)
电子产品,一经出售,概不退换
算法设计、毕业设计、期刊专利!感兴趣可以联系我。
🏆代码获取方式1:
私信博主
🏆代码获取方式2
利用同等价值的matlab代码兑换博主的matlab代码
先提供matlab代码运行效果图给博主评估其价值,可以的话,就可以进行兑换。
 267
267

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























