







并行仿真的关键在于同时执行多个计算,因此可以用于任何迭代顺序与计算无关的场景,例如:
- 参数扫描
- 蒙特卡洛分析
- 梯度计算中的局部优化问题
- 全局优化问题
- 模型测试
Simulink的并行计算的关键在于parsim/parfor命令与Simulink.SimulationInput对象的使用,同时还涉及到并行池及workers与CPU核心数的关系。
本期将介绍Simulink并行计算的一些概念。
1. 有效核心数
进行并行计算的前提就是确认计算机或服务器集群的有效核心数。
MATLAB并行计算以物理核心数作为有效核心数,对于现在的桌面处理器而言,一般都带有超线程(Hyper Threadin)功能,而超线程功能带来的额外的逻辑核心是无法作为有效核心进行并行计算的。
对于Intel处理器而言,还存在"大小核"(P核与E核)之分,因此确认当前计算环境的有效核心数是十分有必要的。
通过feature函数可以对CPU的相关参数进行检测,以确定如何设置并行计算
%%检查处理器型号
>> feature('GetCPU')
ans =
'13th Gen Intel(R) Core(TM) i9-13900H'
%%检查核心数和线程数
>> feature('NumCores')
MATLAB detected: 14 physical cores.
MATLAB detected: 20 logical cores.
MATLAB was assigned: 20 logical cores by the OS.
MATLAB is using: 14 logical cores.
MATLAB is not using all logical cores because hyper-threading is enabled.
ans =
14
2. 并行池与workers
并行池(Parallel Pool)是计算集群或桌面上的一组 MATLAB 工作线程,默认情况下,并行池会在并行功能(例如 parfor )需要时自动启动。
worker指的是用于并行计算的 MATLAB 计算引擎,它们在后台运行以执行任务,并行池就是由多个workers组成的集合
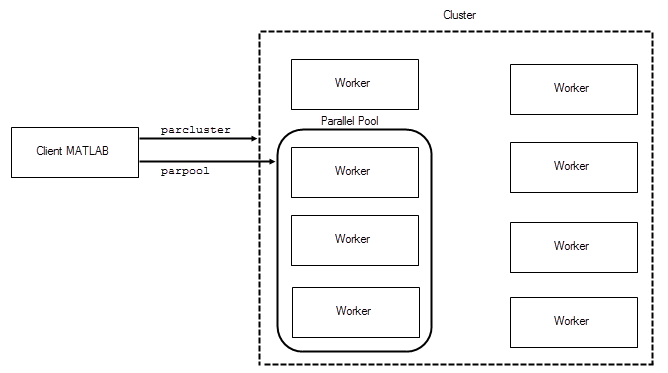
默认情况下,MATLAB 会将 worker 数指定为 CPU 的有效核心数。
对于Intel处理器,从MATLAB 2024a版开始会默认将worker 数指定为CPU的P核(大核)的数量
使用 parpool 函数创建并行池并自定义worker的数量,例如:
-
使用默认设置创建并行池
parpool -
指定 worker 数量
parpool(4) % 创建一个包含4个 worker 的并行池 -
关闭并行池
delete(gcp)
3. 线程和进程
在 MATLAB 中,线程(Threads)和进程(Processes)是两种不同的并行计算环境,它们各有优缺点,适用于不同的计算需求。
需要注意的是,MATLAB默认创建的并行池是进程池(ProcessPool), 可在MATLAB的预设项中进行修改。
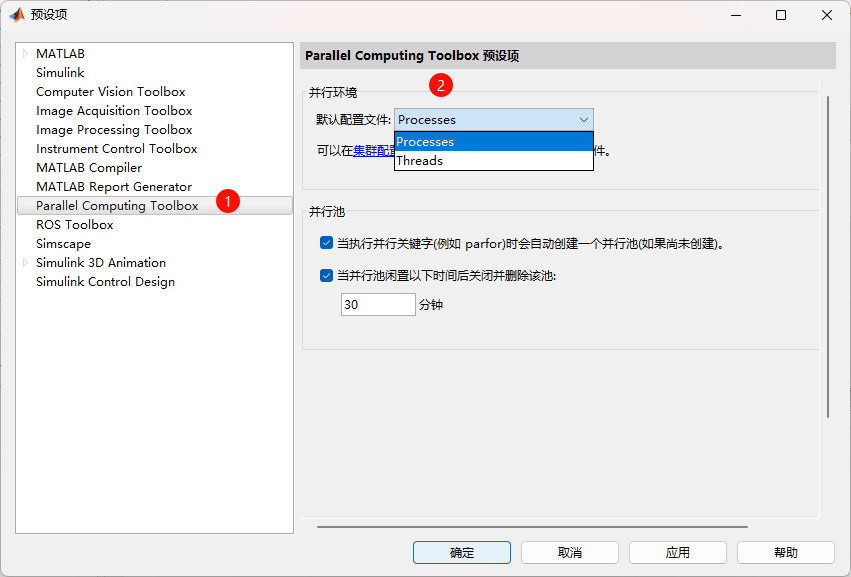
Threads(线程):
基于线程的环境的特点有:
- 内存共享:线程在同一个进程中运行,因此它们可以共享内存,这减少了数据传输的开销。由于数据无需在不同进程间复制,线程的内存使用效率更高。
- 调度开销低:线程的调度开销比进程低,这意味着在某些计算任务中,线程可能比进程更快。
- 适用场景:适合内存使用量大且需要频繁数据传输的任务。例如,处理较轻量的 I/O 密集型任务时,线程通常表现更好。
创建线程池的示例代码:
parpool('Threads'); % 创建一个线程 worker 的并行池
parpool('Threads', 4) % 创建一个包含4个线程 worker 的并行池
Processes(进程):
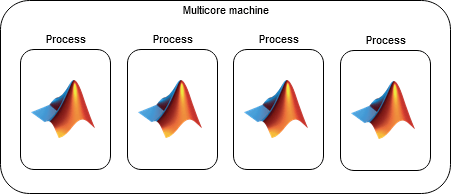
基于进程的环境的特点有:
- 独立运行:每个进程都有独立的内存空间,适合计算密集型任务,因为进程间的干扰较少。
- 隔离性强:进程之间的隔离性强,某个进程的崩溃不会影响到其他进程的运行,这对长时间运行的任务尤为重要。
- 适用场景:适合计算密集型任务或需要高可靠性的任务。因为进程独立运行,能更好地利用多核 CPU 的性能。
创建进程池的示例代码:
parpool('Processes'); % 创建一个进程 worker 的并行池
parpool('Processes', 4) % 创建一个包含4个进程 worker 的并行池
性能对比
在某些情况下,线程池可以避免数据复制并减少调度开销。然而,线程池仅支持 MATLAB 支持的子集函数,并且共享内存的特性可能导致在特定情况下出现数据竞争问题。
进程池支持完整的并行功能同时向后兼容以前的版本,因此更适合计算密集型和需要高可靠性的任务,尽管它们的内存开销和数据传输开销较大。
4. parsim 和 batchsim的区别
在 MATLAB 中,parsim 和 batchsim 都用于运行多次仿真也都支持并行计算,但它们在使用方式和适用场景上有一些重要的区别:
parsim :
- 并行运行:
parsim函数用于在本地并行池上运行仿真。它适合在多核 CPU 上执行快速并行仿真,例如蒙特卡洛分析和参数扫描。 - 交互式使用:
parsim提供了实时监控仿真的功能,通过Simulation Manager可以查看仿真进度和结果。 - 在后台运行:通过设置
'RunInBackground', 'on',可以使仿真在后台运行,从而允许用户在仿真进行时执行其他 MATLAB 任务。 - 资源限制:关闭 MATLAB 会终止正在进行的仿真,因此适合在本地并行计算资源上运行的短时仿真任务。
batchsim :
- 离线运行:
batchsim用于将仿真任务提交到计算集群上运行,这使得用户可以在仿真进行期间关闭 MATLAB 客户端或执行其他任务。 - 批处理模式:适合需要长时间运行的仿真或需要大量计算资源的任务,可以利用 MATLAB Parallel Server 进行大规模并行仿真。
- 不支持实时监控:
batchsim不支持使用Simulation Manager实时监控仿真进度,但可以通过fetchOutputs函数在仿真完成后获取结果。 - 灵活的资源管理:允许指定集群和资源池大小,可以在多个计算节点上并行运行大量仿真任务 。
选择建议:
- 如果需要快速迭代并行仿真并且可以接受本地资源限制,
parsim是一个不错的选择。 - 如果仿真任务需要长时间运行或需要大规模的计算资源,
batchsim更为合适,因为它允许仿真任务在集群上离线运行。
总之,parsim 更适合交互式和快速迭代的仿真,而 batchsim 则适合大规模、长时间的批处理仿真。选择哪个函数取决于具体的仿真需求和计算资源环境。
5. SimulationInput对象
前文提到parsim 可以基于 Simulink.SimulationInput 对象实现使用不同的参数和值运行并行仿真。
SimulationInput对象相当于为当前的模型创建了一个副本,所有使用SimulationInput对象修改的初始状态、模型参数、模块参数、外部输入和变量等设置只会将暂时应用于模型。
可以将SimulationInput对象数组的设置为模拟集来运行多个模拟或并行仿真。
SimulationInput对象有以下方法和属性:
setVariables- 更改基础工作区、数据字典或模型工作区中的变量setBlockParameter- 更改模块参数setModelParameter- 更改模型参数setPreSimFcn- 指定在每次仿真之前先运行 MATLAB 函数,以在集群上进行自定义和后处理结果setPostSimFcn- 指定在每次仿真之后运行 MATLAB 函数,以在集群上进行自定义和后处理结果InitialState- 更改初始状态ExternalInput- 将数值数组、时间序列或数据集对象指定为模型的外部输入
SimulationInput的典型应用包括:
%%创建SimulationInput对象
mdl = "yourModelName";
simIn = Simulink.SimulationInput(mdl);
%%创建1x10的SimulationInput对象数组
mdl = "yourModelName";
simIn(1:10) = Simulink.SimulationInput(mdl);
%%使用 Simulink.SimulationInput 对象设置模块参数值并进行并行仿真
openExample("sldemo_househeat")
mdl = "sldemo_househeat";
simIn(1:10) = Simulink.SimulationInput(mdl);
for i = 1:10
simIn(i) = simIn(i).setBlockParameter('ex_sldemo_househeat/Set Point','Value',rand()*10+70);
end
out = parsim(simIn);















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









