







文章目录
- 摘要
- 零、一些基础
- 1.MoE混合专家
- 一、介绍
- 二、相关工作
- (1)神经VRP求解器
- (2)混合专家系统
- 三、准备工作
- (1)VRP变体
- (2)学习以求解VRPs
- 四、方法论
- 1.带有MoEs的多任务VRP求解器
- (1)多任务VRP求解器
- (2)混合专家
- (3)MVMoE
- 2.门机制
- (1)节点级门控
- (2)分级门控
- 五、实验
- 0.基础
- (1)baseline
- (2)训练
- (3)推理
- 1.经验结果
- (1)训练好的VRPs上的表现
- (2)未知VRPs上的泛化性能
- 2.MoEs消融研究
- (1)MoE的位置
- (2)专家数量
- (3)门控机制
- 3.额外结果
- (1)先进门控
- (2)训练效率
- (3)基准表现
- (4)伸缩性能
- 六、结论
- 七、附录
- A 实例增加
- A.1 应用想法
- 八、代码解析
- 相关领域
摘要
学习解决车辆路径问题(VRPs)已经引起了广泛的关注。然而,大多数神经求解器只是在特定问题上进行结构和训练,这使得它们不那么通用和实用。在本文中,我们的目标是开发一个统一的神经求解器,可以同时处理一系列的VRP变体。具体地说,我们提出了一种具有专家混合功能的多任务车辆路由求解器(MVMoE),它在不按比例提高计算量的情况下,大大提高了模型的容量。我们进一步为MVMoE开发了一种分层门控机制,在经验性能和计算复杂性之间提供了良好的权衡。在实验中,我们的方法显著提高了在10个看不见的VRP变量上的zero-shot泛化性能,并在few-shot设置和真实世界的基准测试实例上显示了良好的结果。我们进一步对MoE配置在解决VRPs中的影响进行了广泛的研究,并观察了在面对分布外数据时分层门控的优越性。
零、一些基础
1.MoE混合专家
一、介绍
车辆路径问题(VRPs)是运筹学和计算机科学中的一类典型的组合优化问题(COPs),具有广泛的应用前景在物流(Cattaruzza等,2017年)、运输(Wu等,2023年)和制造(Zhang等,2023年)方面的应用。固有的NP-hard性质使得VRPs难以被精确求解器求解。作为一种替代方案,启发式求解器可以在合理的时间内提供次优的解决方案,但需要为每个问题设计大量的领域专业知识。最近,学习解决VRPs受到了广泛关注(Bengio等人,2021;博格巴耶娃等人,2024),富有成效的神经解决器正在开发中。其中的大多数应用深度神经网络通过各种训练范式(例如,强化学习(RL))来学习解决方案构建策略。除了获得良好的性能外,它们的特点是比传统的求解器具有更少的计算开销和领域专业知识。然而,流行的神经求解器仍然需要为每个特定的VRP进行独立定制和训练的网络结构,这在面对多个VRP时,引发了高昂的训练开销和较低的实用性。
在本文中,我们的目标是开发一个统一的神经求解器,它可以训练同时求解一系列VRP变量,并在不可见的VRPs上具有良好的zero-shot泛化能力。最近的一些研究探讨了类似的问题设置。Wang & Yu(2023)应用multi-armed
bandits解决多个VRPs,Lin等人(2024)采用一个基地VRP预训练的模型,通过高效微调目标VRPs。由于依赖于为预定的问题变量而构建的网络,它们无法实现对看不见的vrp的zero-shot泛化。Liu等人(2024)通过组合zero-shot学习(Ruis等人,2021),该学习将VRP变体视为一组潜在属性的不同组合,并使用共享网络来学习它们的表示。然而,它仍然利用了现有的为简单vrp提出的网络结构,这受到其模型容量和经验性能的限制。
受最近大型语言模型(LLMs)发展的推动(Kaplan等人,2020年;弗洛里迪和奇里亚蒂,2020年;Touvron等人,2023年),我们提出了一种具有专家混合的多任务VRP求解器(MVMoE)。通常,在基于变压器的模型中,混合专家(MoE)层用几个“专家”取代前馈网络(FFN),这些专家是一组具有各自可训练参数的ffn。到MoE层的输入通过门控网络路由到特定的专家,并且只包含选定的专家中的参数被激活(即条件计算(Jacobs等人,1991年;Jordan & Jacobs,1994))。这样,部分激活的参数可以有效地提高模型容量,而不需要按比例增加计算量,使llm的训练和部署可行。因此,对于一个更通用和更强大的神经求解器,我们首先提出了一个基于moe的神经VRP求解器,并提出了一种分层门控机制,以便在经验性能和计算复杂度之间进行良好的权衡。我们选择Liu等人(2024)的设置作为测试台,因为它有可能解决新VRP的指数变量作为潜在属性的任何组合。
我们的贡献总结如下。1)我们提出了一个统一的神经求解器MVMoE来求解多个VRPs,这首先将MoEs引入到COPs的研究中。唯一的MVMoE可以在不同的VRP变体上进行训练,并在不可见的VRP上促进强大的zero-shot泛化能力。2)我们为MVMoE开发了一种分层门控机制,以在经验性能和计算开销之间获得良好的平衡。令人惊讶的是,它表现出比基底门控更强的分布外泛化能力。3)大量的实验表明,MVMoE显著提高了10个不可见的VRP变量的基线的zero-shot泛化,并在few-shot设置和真实实例上取得了不错的结果。我们进一步研究了广泛的MoE构型(如MoE的位置、专家的数量和门控机制)对zero-shot泛化性能的影响。
二、相关工作
(1)神经VRP求解器
神经VRP求解器。在关于学习解决vrp的文献中存在两个主流: 1)基于构造的求解器,它们学习以端到端方式构建解决方案的策略。Vinyals等人(2015)提出指针网络以自回归方式估计旅行销售员问题(TSP)的最优解。后续工作应用RL来探索TSP(Bello等人,2017)和有能力的车辆路线问题(CVRP)(Nazari等人,2018)的更好的近似解决方案。Kool等人(2018)提出了一种基于注意力的模型(AM),该模型使用变压器独立解决一系列vrp。Kwon等人(2020)提出了多重优化策略优化(POMO),以进一步提高求解TSP和CVRP的性能。其他基于结构的求解器通常在AM和POMO之上开发(Kwon等人,2021年;李等人,2021年;金等人,2022年;Berto等人,2023年;陈等人,2023年;格林茨坦等人,2023年;查鲁莫等人,2023年;Hottung等人,2024年)。除了自回归方式之外,一些作品构建热图以非自回归的方式解决VRPs(Joshi等,2019;傅等,2021;Kool等,2022;邱等人,2022;孙&杨,2023;Min等人,2023;叶等人,2023;Kim等人,2024年)。2)基于改进的求解器,学习策略迭代细化初始解,直到满足终止条件。策略通常采用经典本地搜索(克罗斯,1958年;肖,1998)或专业启发式求解器(赫尔斯高,2017),以获得更有效的搜索组件(陈和田,2019;陆等,2020;东和蒂尼,2020;dO科斯塔等,2020;吴等人,2021;辛等人,2021;哈德逊等人,2022;周等人,2023a;马等人,2023)。一般来说,基于构造的求解器可以有效地实现期望的性能,而基于改进的求解器有可能在较长时间的推理时间下提供更好的解决方案。
最近的研究揭示了神经求解器的泛化能力不足,导致未知数据的性能急剧下降(Joshi et al.,2021)。以往的工作主要集中在交叉尺寸泛化(傅等,2021;侯等,2023;2023;孙等,2023;罗等,2023;德拉等,2023)或交叉分布泛化(张等,2022;盖斯勒等,2022;比等,2022;江等,2023)或两者(曼昌达等,2022;周等,2023b;王等,2023b,2024)。在本文中,我们进一步探索了不同VRP变体之间的泛化性(Wang & Yu,2023;Liu等人,2024;Lin等人,2024)。
(2)混合专家系统
MoEs的最初想法是在30年前提出的(Jacobs et al.,1991;Jordan & Jacobs,1994)。在早期的概念中,专家被定义为一个完整的神经网络,因此MoEs类似于一个神经网络的集合。Eigen等人(2013)开创了研究人员开始将MoEs作为神经网络组成部分的时代。作为MoEs应用于大型神经网络中的早期成功,Shazeer等人(2017)在语言建模和机器翻译中引入了稀疏门控的MoEs,在计算效率方面只有很小的损失,实现了当时最先进的结果。后续工作主要集中于改进门控机制(刘易斯等人,2021;辊等,2021;左等,2022;2022;周等,2024;薛等人,2024)或应用于其他领域(Lepikhin等人,2020年;里克尔梅等人,2021年;Fedus等人,2022b)。我们建议感兴趣的读者参考Yuksel等人(2012);Fedus等人(2022a)进行全面调查。
三、准备工作
在本节中,我们首先介绍CVRP的定义,然后引入附加约束的变体。之后,我们描述了最近基于构建的基于构建的神经求解器(Kool等人,2018;Kwon等人,2020)。
(1)VRP变体

我们定义一个
n
n
n个节点的图
G
=
{
V
,
E
}
\mathcal{G} =\{\mathcal{V},\mathcal{E}\}
G={V,E},其中
V
V
V包含一个仓库节点
v
0
v_0
v0和客户节点
{
v
i
}
i
=
1
n
\{v_i\}^n_{i=1}
{vi}i=1n,而
E
E
E包含节点
v
i
v_i
vi和
v
j
(
i
≠
j
)
v_j(i ≠ j)
vj(i=j)之间的边
e
(
v
i
,
v
j
)
e(v_i,v_j)
e(vi,vj)。每个客户节点都与一个需求δi相关联,并为每辆车设置了一个容量限制
Q
Q
Q。解决方案(即tour)
τ
τ
τ表示为一个节点序列,由多个子节点组成。每个子行程表示车辆从仓库开始,访问客户节点的一个子集,并返回仓库。如果每个客户节点只访问一次,并且每个子行程的总需求不超过容量限制
q
q
q,则该解决方案是可行的。我们考虑欧氏空间,成本函数
c
(
⋅
)
c(·)
c(⋅)定义为访问的总长度。目标是以最小的成本找到最优的行程
τ
∗
τ∗
τ∗:
τ
∗
=
arg min
τ
∈
Φ
c
(
τ
∣
G
)
τ∗= \text{arg min} _{τ∈Φ}c(τ|\mathcal{G})
τ∗=arg minτ∈Φc(τ∣G),其中
Φ
Φ
Φ是包含所有可行行程的离散搜索空间。
在CVRP(以容量约束( C C C)为特征)之外,几个VRP变体涉及额外的实际约束。1)开放路线( O O O):拜访客户后车辆无需返回车站 v 0 v_0 v0;2)回程( B B B):CVRP中需求 δ i δ_i δi为正,表示车辆在客户节点卸车。在实践中,客户可能会有负需求,要求车辆装载货物。我们将 δ i > 0 δ_i > 0 δi>0的客户节点命名为直线节点, δ i < 0 δ_i < 0 δi<0的客户节点命名为回程节点。因此,带回程的VRP允许车辆以混合的方式穿越直线运输和回程,它们之间没有严格的优先级;3)时间限制( L L L):为了保持合理的工作量,每条路线的成本(即长度)上限有一个预定义的阈值;4)时间窗口( T W TW TW):每个节点 v i ∈ V v_i∈\mathcal{V} vi∈V与一个时间窗口 [ e i , l i ] [e_i,l_i ] [ei,li]和服务时间 s i s_i si相关联。车辆必须在从 e i e_i ei到l_i的时间段内开始服务客户 v i v_i vi。如果车辆比 e i e_i ei更早到达,它必须等到 e i e_i ei。所有车辆必须在不迟于 l 0 l_0 l0之前返回车辆段 v 0 v_0 v0。上述约束条件如图1所示。通过结合它们,我们可以得到16个典型的VRP变异,总结如表3所示。请注意,该组合并不是对不同约束的简单添加。例如,当开放路线与时间窗耦合时,车辆不需要返回仓库,因此放宽了在仓库中由 l 0 l_0 l0施加的约束。我们在附录A中提供了VRP变体和相关数据生成过程的更多细节。
(2)学习以求解VRPs
典型的神经求解器(Kool等人,2018;Kwon等人,2020)通过基于注意力的神经网络 π θ π_θ πθ参数化解决方案构建策略,该网络被训练以自回归的方式生成解决方案。在解码过程中,通过掩蔽机制保证了所生成的解决方案的可行性。在不丧失一般性的情况下,我们考虑了RL训练范式,其中求解的构造过程被表述为一个马尔可夫决策过程(MDP)。给定一个输入实例,编码器对其进行处理并获得所有节点嵌入,这些节点嵌入通过所构建的部分之旅的上下文表示来表示当前状态。解码器将它们作为输入,并输出要选择的有效节点(即动作)的概率。构建一个完整的解τ后,其概率可以通过链规则分解, p θ ( τ ∣ G ) = ∏ t = 1 T p θ ( π θ ( t ) ∣ π θ ( < t ) , G ) p_θ(τ|\mathcal{G})=\prod_{t=1}^T p_θ(π^{(t)}_θ |π^{(<t)}_θ,\mathcal{G}) pθ(τ∣G)=∏t=1Tpθ(πθ(t)∣πθ(<t),G),其中 π θ ( t ) π^{(t)}_θ πθ(t)和 π θ ( < t ) π^{(<t)}_θ πθ(<t)表示选择节点和构建部分旅游在步骤 t t t,和 T T T是总步骤的数量。
奖励被定义为负的旅行长度,即
R
=
−
c
(
τ
∣
G
)
\mathcal{R}=−c(τ|\mathcal{G})
R=−c(τ∣G)。给定一个训练稳定性的基线函数
b
(
⋅
)
b(·)
b(⋅),策略网络
π
θ
π_θ
πθ通常通过强化(Willims,1992)算法进行训练,该算法应用预期奖励的估计梯度来优化策略,如下所示:
∇
θ
L
a
(
θ
∣
G
)
=
E
p
θ
(
τ
∣
G
)
[
(
c
(
τ
)
−
b
(
G
)
)
∇
θ
log
p
θ
(
τ
∣
G
)
]
.
\nabla_\theta \mathcal{L}_a(\theta \mid \mathcal{G})=\mathbb{E}_{p_\theta(\tau \mid \mathcal{G})}\left[(c(\tau)-b(\mathcal{G})) \nabla_\theta \log p_\theta(\tau \mid \mathcal{G})\right] .
∇θLa(θ∣G)=Epθ(τ∣G)[(c(τ)−b(G))∇θlogpθ(τ∣G)].
四、方法论
在本节中,我们介绍了带有MoEs的多任务VRP求解器(MVMoE),并介绍了门控机制。在不丧失一般性的情况下,我们的目标是学习一个基于构造的神经求解器(Kool等人,2018年;Kwon等人,2020年),用于处理在第3节中引入的五个约束条件下的VRP变体。MVMoE的结构如图2所示。
1.带有MoEs的多任务VRP求解器
(1)多任务VRP求解器
给定一个特定的VRP变体实例,每个节点 v i v_i vi的静态特征由 S i = { y i , δ i , e i , l i } \mathcal{S}_i = \{y_i,δ_i,e_i,l_i\} Si={yi,δi,ei,li}表示,其中 y i , δ i , e i , l i y_i,δ_i,e_i,l_i yi,δi,ei,li分别表示坐标、需求、时间窗的开始时间和结束时间。编码器将这些静态节点特征作为输入,并输出 d d d维节点嵌入 h i h_i hi。在第 t t t个解码步骤,解码器将节点嵌入和上下文表示作为输入,包括嵌入最后选择的节点和动态特征 D t = { c t , t t , l t , o t } Dt = \{c_t,t_t,l_t,o_t\} Dt={ct,tt,lt,ot},其中 c t , t t , l t , o t c_t,t_t,l_t,o_t ct,tt,lt,ot分别表示车辆的剩余容量、当前时间、当前部分路径的长度和开放路径的存在指标。然后,解码器输出节点的概率分布,从中选择一个有效的节点并附加到部分解中。通过迭代解码过程,以自回归的方式构造了一个完整的解。
在每个训练步骤中,我们随机选择一个VRP变体,并训练神经网络在一批中解决相关实例。通过这种方式,MVMoE能够学习一个统一的策略,可以处理不同的VRP任务。如果在当前选定的VRP变体中只涉及静态或动态特性的一个子集,那么其他特性将被填充到默认值(例如,零)。例如,给定一个CVRP实例,第i个客户节点的静态特征为 S i ( C ) = { y i , δ i , 0 , 0 } S_i^{(C)} = \{y_i,δ_i,0,0\} Si(C)={yi,δi,0,0},第 t t t个解码步骤的动态特征为 D t ( C ) = { c t , 0 , l t , 0 } D_t^{(C)} = \{c_t,0,l_t,0\} Dt(C)={ct,0,lt,0}。总之,由于不同的VRP变体可能包含一些共同的属性(例如,坐标、需求),我们将静态和动态特征定义为所有VRP变体中存在的属性的并集。通过对一些具有这些属性的一些VRP变体进行训练,策略网络有可能解决看不见的变量,这些变量的特征是这些属性的不同组合,即zero-shot泛化能力(Liu et al.,2024)。
(2)混合专家
通常,一个MoE层由 1)
m
m
m个专家
{
E
1
,
E
2
,
…
,
E
m
}
\{E_1,E_2,…,E_m\}
{E1,E2,…,Em},每个是一个线性层或FFN具有独立的可训练参数,2)一个由
W
G
W_G
WG参数化的门网络
G
G
G,它决定输入如何分配给专家。给定一个输入
x
x
x,
G
(
x
)
G (x)
G(x)和
E
j
(
x
)
E_j (x)
Ej(x)分别表示门控网络的输出(即
m
m
m维向量)和第
j
j
j个专家的输出。据此,计算出一个MoE层的输出值为:
MoE
(
x
)
=
∑
j
=
1
m
G
(
x
)
j
E
j
(
x
)
\operatorname{MoE}(x)=\sum_{j=1}^m G(x)_j E_j(x)
MoE(x)=j=1∑mG(x)jEj(x)直观地说,一个稀疏向量
G
(
x
)
G (x)
G(x)只激活了一小部分具有部分模型参数的专家,因此节省了计算量。通常,一个
Top
K
\text{Top}K
TopK算子可以通过只保持
k
k
k-最大值,而将其他值设置为负无穷大来实现这种稀疏性。在这种情况下,门控网络计算输出为
G
(
x
)
=
Softmax
(
Top
K
(
x
⋅
W
G
)
)
G (x) = \text{Softmax}(\text{Top}K(x·W_G))
G(x)=Softmax(TopK(x⋅WG))。考虑到更大的稀疏模型并不总是能带来更好的性能(Zuo et al.,2022),设计有效的门控机制,赋予每个专家得到足够的训练数据是至关重要的,但也是棘手的。为此,一些工作已经在语言和视觉领域被提出,如设计一个辅助损失(Shazeer et al.,2017)或将其表述为一个线性分配问题(Lewis等人,2021),以追求负载平衡。

(3)MVMoE
通过对上述各部分的整合,我们得到了具有MoEs的多任务VRP求解器。整体模型结构如图2所示,其中我们在编码器和解码器中都使用了MoEs。具体来说,我们用MoEs代替编码器中的FFN层,用MoEs代替解码器中最终的多线性多头注意层。我们将MVMoE结构的更多细节参考附录B。根据经验,我们发现,我们的设计在生成高质量的解决方案方面是有效的,特别是在解码器中使用MoEs往往会对性能产生更大的影响(见第5.2节)。我们共同优化了所有可训练的参数Θ,其目标表述如下:
min
Θ
L
=
L
a
+
α
L
b
,
\min _{\Theta} \mathcal{L}=\mathcal{L}_a+\alpha \mathcal{L}_b,
ΘminL=La+αLb,其中,
L
a
\mathcal{L}_a
La表示VRP求解器的原始损失函数(例如,用于训练解决等式中VRP变量的策略的强化损失(1)),
L
b
\mathcal{L}_b
Lb表示与MoEs相关的损失函数(例如,用于确保等式中的负载平衡的辅助损失(19)在附录B中),而
α
α
α是一个控制其强度的超参数。
2.门机制
我们主要考虑节点级(或令牌级)门,通过这个门,每个节点被独立路由给专家。对于每一个MoE层,额外的计算来自于门控网络的前向传递和节点向所选专家的分布。虽然在解码器中使用MoEs可以显著提高性能,解码步数 T T T随着问题大小 n n n的增加而增加。这表明,与固定门步 N ( ≪ T ) N(≪T) N(≪T)的编码器相比,在解码器中应用MoEs可能会大大增加计算复杂度。鉴于此,我们提出了一种分层门控机制,以更好地利用解码器中的MoEs,以获得经验性能和计算复杂度之间的良好权衡。接下来,我们详细介绍了节点层和分层的控制机制。
(1)节点级门控
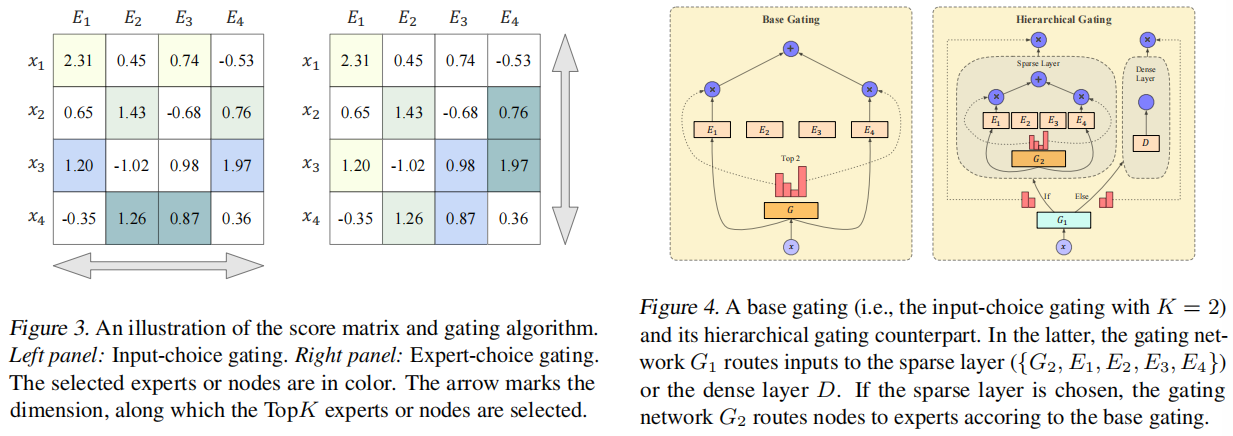
节点级的门控以节点的粒度路由输入。设 d d d表示隐藏维数, W G ∈ R d × m W_G∈\mathbb{R}^{d×m} WG∈Rd×m表示MVMoE中门控网络的可训练参数。给定一批输入 X ∈ R I × d X∈\mathbb{R}^{I×d} X∈RI×d, I I I是节点的总数(即批大小 B × B× B×问题规模 n n n),每个节点路由选择专家基于分数矩阵 H = ( X ⋅ W G ) ∈ R I × m H =(X·W_G)∈\mathbb{R}^{I×m} H=(X⋅WG)∈RI×m预测门网络。图3中分数矩阵的一个例子,其中 x i x_i xi表示第 i i i个节点, E j E_j Ej表示节点级门控中的第 j j j个专家。
在本文中,我们主要考虑两种流行的门控算法(Shazeer等al.,2017;Zhou等,2022): 1)输入选择门控:每个节点基于 h h h选择 Top K \text{Top}K TopK专家。通常将 K K K设置为1或2,以保持合理的计算复杂度。输入选择门控如图3的左面板所示,其中每个节点被路由给得分最大的两个专家(即 Top 2 \text{Top}2 Top2)。但是,这种方法并不能保证负载平衡。一个专家可能比其他节点收到更多的节点,导致一个占主导地位的专家,而留下其他节点不合适。为了解决这个问题,大多数工作都采用了一个辅助损失来平衡在训练期间发送给不同专家的节点数量。在这里,我们使用重要性和负载损失(Shazeer et al.,2017)作为等式中的 L b \mathcal{L}_b Lb(3)以减轻负载不平衡(见附录B)。2)专家选择门控:每位专家选择基于 H H H的 Top K \text{Top}K TopK节点。通常, K K K被设置为 I × β I×β I×β,其中 β β β是反映一个节点使用的平均专家数量的容量因子。专家选择门控如图3的右面板所示,每个专家选择了在给定 β = 2 β = 2 β=2时得分最大的两个节点。虽然这种门控算法显式地确保了负载平衡,但有些节点可能不会被任何专家选择。我们将上述门控算法的更多细节参考附录B。
(2)分级门控
在VRP域中,在每个解码步骤中使用MoEs的计算代价很高,因为1)解码步骤 T T T随着问题大小 n n n的增加而增加;2)在解码过程中必须满足特定问题的可行性约束。为了解决这些挑战,我们建议只在部分解码步骤中使用MoE。因此,我们提出了一种分层门控,它学习在解码过程中有效地利用MoEs。
我们在图4中说明了所提出的分层门控。具有分层门控的MoE层包括两个门控网络 { G 1 , G 2 } \{G_1,G_2\} {G1,G2}、 m m m个专家 { E 1 , E 2 , … , E m } \{E_1,E2,…,E_m\} {E1,E2,…,Em}和一个密集层 D D D(例如,一个线性层)。给定一批输入 X ∈ R I × d X∈\mathbb{R}^{I×d} X∈RI×d,分层门控将它们分为两个阶段。在第一阶段, G 1 G_1 G1决定根据问题级表示 X 1 X_1 X1将输入 X X X分配到稀疏层或稠密层。具体来说,我们通过沿 X X X的第一维应用平均池得到 X 1 X_1 X1,并将其处理得到得分矩阵 H 1 = ( X 1 ⋅ W G 1 ) ∈ R 1 × 2 H_1 =(X_1·W_{G_1})∈\mathbb{R}^{1×2} H1=(X1⋅WG1)∈R1×2。然后,我们通过从概率分布 G 1 ( X ) = Softmax ( H 1 ) G_1(X) = \text{Softmax}(H_1) G1(X)=Softmax(H1)中采样,将一批输入 X X X路由到稀疏或稠密层。在这里,我们使用 G 1 G_1 G1中的问题级门控来提高分层门控的通用性和效率(进一步的讨论见附录D)。在第二阶段,如果 X X X被路由到稀疏层,则门网络 G 2 G_2 G2被激活,通过使用上述门算法(例如,输入选择门算法)将节点路由到节点级的专家。否则, X X X被路由到致密层 D D D,并转换为 D ( X ) ∈ R I × d D(X)∈\mathbb{R}^{I×d} D(X)∈RI×d。总的来说,分层门控学习输出 G 1 ( X ) 0 ∑ j = 1 m G 2 ( X ) j E j ( X ) G_1(X)_0 \sum_{j=1}^m G_2(X)_j E_j(X) G1(X)0∑j=1mG2(X)jEj(X) 或 G 1 ( X ) 1 D ( X ) G_1(X)_1 D(X) G1(X)1D(X)同时基于问题级和节点级的表示形式。
总的来说,分层门控提高了计算效率,但对经验性能的损失较小。为了平衡MVMoE的效率和性能,我们在编码器中使用基本门控,在解码器中使用其对应的分层门控。需要注意的是,分层门控适用于不同的门控算法,如输入选择门控(Shazeer等人,2017)和专家选择门控(Zhou等人,2022)。我们还探索了一种更先进的门控算法(Puigcerver et al.,2024),以减少路由节点的数量,从而减少计算复杂度。但它在VRP领域的经验性能并不令人满意(见第5.3节)。
五、实验
在本节中,我们通过实证验证了所提出的MVMoE的优越性,并为MoEs在解决VRPs中的应用提供了见解。我们考虑了16个具有5个约束条件的VRP变体。由于页面限制,我们在附录c中给出了更多的实验结果。所有实验都是在使用NVIDIA Ampere A100-80GB GPU卡和AMD EPYC 7513 CPU为2.6 GHz的机器上进行的。
0.基础
(1)baseline
传统的求解器:我们使用HGS(Vidal,2022)来解决具有默认超参数的CVRP和VRPTW实例(即,没有改进的最大迭代次数是20000)。我们运行LKH3(Helsgaun,2017)来解决具有10000条路径和1次运行的CVRP、OVRP、VRPL和VRPTW实例。OR-Tools(Furnon & Perron,2023)是一个针对复杂优化问题的开源求解器。它比LKH和HGS更通用,可以解决本文中考虑的所有16个VRP变体。我们使用并行最便宜的插入作为第一个解决方案策略,并在OR-Tools中使用引导的局部搜索作为局部搜索策略。对于n个= 50/100,我们将搜索时间限制设置为20s/40s来求解一个实例,并提供其给定200s/400s的结果(即OR-Tools (x10))。对于所有传统的求解器,我们在Kool等人(2018)之后,使用它们在32个CPU核上并行解决32个实例。
神经求解器:我们将我们的方法与POMO(Kwon等人,2020年)和POMO-MTL(Liu等人,2024年)进行了比较。POMO在每个VRP上进行训练,而POMO-MTL通过多任务学习在多个VRP上进行训练。请注意,POMO-MTL是MVMoE的密集模型对应物,MVMoE由密集层(如FFNs)而不是稀疏的MoEs构成。具体来说,POMO-MTL和MVMoE/4E拥有1.25M和3.68M的参数,但它们为每个单一输入激活了相似数量的参数。
(2)训练
我们遵循了大多数设置(Kwon et al.,2020年)。1)对于所有的神经求解器:使用Adam优化器,学习速率为1e−4,权重衰减为1e−6,批量大小为128。该模型训练了5000个epoch,每个时代包含20000个训练实例(即总共100M个训练实例)。在最后10%的训练实例中,学习率下降了10。根据(Liu et al.,2024),我们考虑了两个问题尺度n∈{50,100})。2)对于多任务求解器:训练问题集包括CVRP、OVRP、VRPB、VRPL、VRPTW和OVRPTW(进一步讨论见附录C.1)。在每一批训练中,我们从集合中随机抽取一个问题,并生成其实例。生成过程详见附录A。3)对于我们的方法:我们在每个MoE层使用==β=2专家,将辅助损失Lb的权重α设为0.01。MVMOE/4E的默认门控机制是两个编码器中的节点级输入选择门控和解码器层。MVMoE/4E-L是一个计算上很轻的版本,它用解码器中的对应的等级门控取代了输入选择门控。
(3)推理
对于所有的神经求解器,我们在Kwon等人(2020年)之后使用了具有x8实例增强的贪婪推出。我们报告了包含1K个实例的测试数据集上的平均结果(即目标值和间隙),以及解决整个测试数据集的总时间。这些间隙是根据性能最好的传统VRP求解器(即表1和表2中的*)的结果来计算出来的。


1.经验结果

(1)训练好的VRPs上的表现
我们在6个经过训练的vrp上评估了所有的方法,并收集了表1中的所有结果。单任务神经求解器(即POMO)在每个单一问题上都比多任务神经求解器取得了更好的性能,因为它在每个VRP上都独立地进行了重构和重新训练。然而,正如附录C中的表4所示,它在所有训练过的VRP上的平均性能相当差,因为每个训练过的POMO都过于符合特定的VRP。例如,单独在CVRP上训练的POMO的平均性能为16.815%,而POMO-MTL和MVMoE/4E的平均性能分别为2.102%和1.925%。值得注意的是,我们的神经求解器始终优于POMO-MTL。MVMoE/4E的性能略好于MVMoE/4E-L,但牺牲了更多的计算量。尽管如此,MVMoE/4E-L比MVMoE/4E表现出更强的分布外泛化能力(见附录C中的表7和表8)。
(2)未知VRPs上的泛化性能
我们评估了10个不可见的VRP变体上的多任务求解器。1)zero-shot泛化:我们直接在看不见的VRPs上测试训练过的求解器。表2中的结果显示,所提出的MVMoE在所有VRP变量上都显著优于POMO-MTL。2)few-shot泛化:我们还考虑了n = 50上的few-shot设置,其中每个时期的训练求解器使用10K实例(占总训练实例的0.01%)对目标VRP进行微调。在不失一般性的情况下,我们在训练设置后在VRPBLTW和OVRPBLTW上进行了实验。图5中的结果显示MVMoE比POMO-MTL更有利。
2.MoEs消融研究
本文探讨了不同的MoE设置对神经求解器zero-shot泛化的影响,并为如何有效地应用MoEs求解VRPs提供了见解。由于快速收敛,我们将大小为n = 50的VRPs上的epoch数减少到2500,而保持其他设置不变。我们将MVMoE/4E设置为默认基线,并在下面的不同成分上进行消融。
(1)MoE的位置
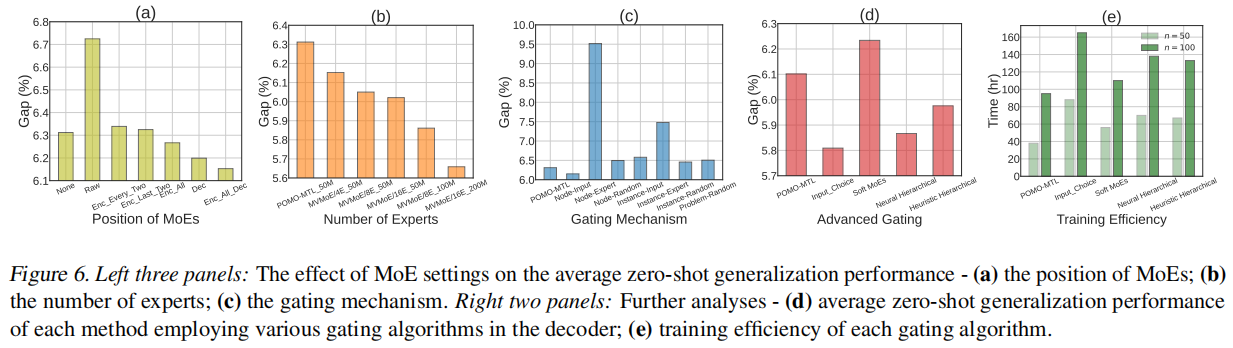
我们考虑了在神经求解器中应用MoEs的三个位置: 1)原始特征处理(原始特征处理):将原始特征投影到初始嵌入中的线性层被MoEs所取代。2)编码器(Enc):编码器层中的FFN被MoEs取代。通常,MoEs广泛应用于每两层或最后两层(即每两层或最后两层,索引为ℓ∈[0,N−1])(Riquelme等人,2021)。此外,我们进一步尝试在所有编码器层中使用MoEs。3)解码器(Dec):多头注意力的最终线性层被解码器中的MoEs所取代。我们在图6(a).中显示了10个未可见的vrp的平均性能结果表明,在浅层(如Raw)中应用MoEs可能会降低模型的性能,而在所有编码器层(Enc_All)或解码器(Dec)中使用MoEs则有利于zero-shot泛化。因此,在本文中,我们在编码器和解码器中都使用MoEs来追求一个强大的统一模型架构来解决各种vrp。
(2)专家数量
我们将每个MoE层的专家数量增加到8人和16人,并将导出的MVMoE/8E/16E模型与MVMoE/4E模型进行比较。我们首先使用相同数量(50M)的实例来训练所有的模型。在此之后,我们还用更多的数据和计算对MVMoE/8E/16E进行训练,以探索潜在的更好的结果(Kaplan et al.,2020)。具体来说,我们通过使用更大的批大小为MVMoE/8E/16E提供更多的数据,这与专家的数量呈线性增长(即,MVMoE/4E/8E/16E分别在50M/100M/200M实例上进行训练,批大小为128/256/512)。图6(b)的结果显示,随着训练数据的专家数量的增加,进一步释放了MVMoE的能力,表明MoE在解决VRPs方面的有效性
(3)门控机制
我们研究了不同的门控级别和算法的影响,包括三个级别(即节点级、实例级和问题级)和三种算法(即输入选择、专家选择和随机门控),详见附录b。如图6©所示,节点级输入选择门控表现最好,而节点级专家选择门控表现最差。有趣的是,我们观察到解码器中的专家选择门控使得MVMoE难以被优化。这可能表明,每个门控算法都可以有其最适合的位置来服务于MoEs。然而,在尝试调整该配置后(即仅在编码器中使用MoEs)后,其性能仍然低于基线,在不可见的vrp上的平均差距为7.190%。
3.额外结果
我们进一步提供了关于更先进的门控算法、训练效率、基准测试性能和可伸缩性的实验和讨论。我们请读者参考附录C中更多的实证结果(例如,敏感性分析)。
(1)先进门控
除了上述评估的输入选择和专家选择门控算法外,我们还进一步考虑了软MoEs(Puigcerver et al.,2024),这是一种最新的高级门控算法。具体来说,它通过将K个槽(即所有输入的凸组合)分配给每个专家来执行隐式软分配,而不是像传统的稀疏和离散门控网络那样在输入和专家之间进行硬分配。由于只有K(例如,1或2)插槽被分配给每个专家,它可以节省大量的计算。我们通过在解码器中使用节点级的软MoEs,在 n = 50 n= 50 n=50上训练MVMoE,并遵循训练设置。我们还展示了在解码器中使用启发式(随机)分层门控的结果。但其结果并不令人满意,如图6(d).所示
(2)训练效率
图6(e)显示了在解码器中使用每个门控算法的训练时间,结合图6(d)中报告的结果,展示了所提出的分层门控在减少训练开销方面的有效性,而性能损失很小。
(3)基准表现
我们进一步评估了在CVRPLIB基准测试实例上的所有神经求解器的外分布(OOD)泛化性能。详细的结果见附录c中的表7和表8。令人惊讶的是,我们观察到MVMoE/4E在大规模实例( n > 500 n>500 n>500)上表现不佳。这可能是由于稀疏MoE在转移到新的分布或域时的泛化问题引起的,这在MoE文献中仍然是一个开放的问题(Fedus et al.,2022a)。相比之下,MVMoE/4E-L的性能大多优于MVMoE/4E,显示了分层门控在促进OOD泛化能力方面更有利的潜力。值得注意的是,所有的神经求解器都只在大小为 n = 100 n = 100 n=100的简单均匀分布实例上进行训练。在多任务训练(交叉问题)中包含更多不同的问题大小(交叉大小)和属性分布(交叉分布)可能会进一步巩固它们的表现。
(4)伸缩性能
鉴于在目前的文献中,基于监督学习的方法似乎比基于rl的方法更具可扩展,我们试图建立在一种更可扩展的方法基础上,即LEHD(Luo et al.,2023)。具体地说,我们在CVRP上用4个专家LEHD/4E-L训练一个密集模型LEHD和一个光稀疏模型。训练设置与Luo等人(2023年)保持相同,只是我们只训练所有模型20个时期以提高训练效率。我们在LEHD/4E-L的每个解码器层中使用分层的MoE。结果如表8所示,这表明了MoE作为一种通用思想的潜力,可以进一步有利于最近的可扩展方法。此外,在解决方案构建过程中,最近的工作(Drakulic et al.,2023;Gao等人,2023)通常将搜索空间限制在当前选定节点的邻域内,这被证明在处理大规模实例方面是有效的。将MVMoE与这些简单而有效的技术集成可以进一步提高大规模性能。
六、结论
针对一个更通用和更强大的神经求解器,我们提出了一个具有MoEs的多任务车辆路由求解器(MVMoE),它可以同时解决一系列的VRPs,即使以zero-shot的方式。我们为如何在神经VRP求解器中应用MoEs提供了有价值的见解,并提出了一种有效有效的分层门控机制。根据经验,MVMoE在zero-shot、few-shot设置和真实世界的基准测试上显示了很强的泛化能力。尽管本文首次尝试了一个大的VRP模型,但参数的规模仍然远小于llm。我们离开1)在解决大规模的模型的发展,2)通用的风险表示不同的问题,3)的探索门机制(Nguyen et al.,2023;2024(4)和4)的调查(Krajewski等,2024)未来的工作。我们希望我们的工作能使COP社区在开发大型优化(或基础)模型方面受益。
七、附录
A 实例增加
A.1 应用想法
八、代码解析
相关领域
【待补充】

















 1459
1459

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









