







八、值函数近似(Value function approximation)
前面介绍的所有方法都是基于表格的,即所有的 s t a t e v a l u e state \ value state value 或者 a c t i o n v a l u e action \ value action value 都是放在 Q − t a b l e Q-table Q−table 里的。此方法存在维度灾难的问题,当问题的 s t a t e / a c t i o n s p a c e state/action \ space state/action space 非常大或者 s t a t e state state 是连续的时候,基于表格的方法就没办法解决问题。如何把离散的点转换为连续的呢,可以考虑用曲线拟合。
假设用一条直线来拟合 s t a t e v a l u e state \ value state value:
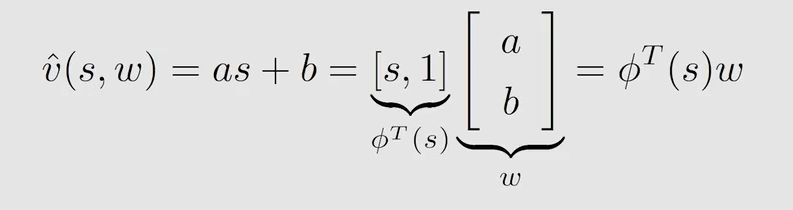
v ^ \hat v v^ 是 v π v_{\pi} vπ 的估计值, w w w 是参数,所要存储的就是这个 w w w, ϕ ( s ) \phi(s) ϕ(s) 是特征向量
曲线拟合有两个好处:一是可以解决维度的问题,可以用较小的存储来得到所有状态的估计;二是可以根据曲线来更新那些在一个 e p i s o d e episode episode 中没有被访问到的状态的 s t a t e / a c t i o n v a l u e state/action \ value state/action value。
但也存在问题:如果曲线拟合的不完美,估计值与真实值偏差就会较大。
我们的目的就是找到最优的 w w w,让 v ^ ( s , w ) \hat v(s,w) v^(s,w) 能够最好的估计 s t a t e v a l u e state \ value state value。
8.1 目标函数介绍
目标函数如下:

现在问题转换为找到最优的 w w w,使得 J ( w ) J(w) J(w) 最小。式中 S S S 是随机变量,即可能是状态空间中任意一个状态。因为是 m o d e l − f r e e model-free model−free 的,所以并不知道状态的概率分布,那应该怎么计算这个期望呢?有两种方法定义这个概率分布。
f i r s t w a y : u n i f o r m d i s t r i b u t i o n first \ way:uniform \ distribution first way:uniform distribution
平均分布,每个状态的概率都是相同的,很容易将期望转化为求和取均值的情况
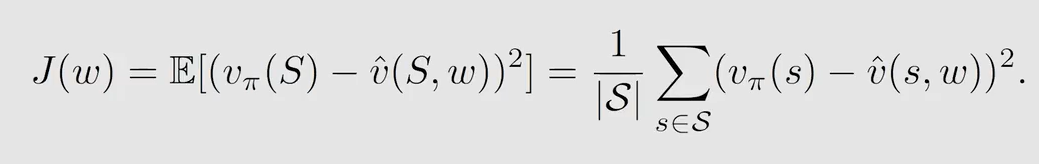
但是在实际问题中,状态转移的概率往往是不同的。
s e c o n d w a y : s t a t i o n a r y d i s t r i b u t i o n second \ way:stationary \ distribution second way:stationary distribution
d π ( s ) d_{\pi}(s) dπ(s) 是指由给定的策略 π \pi π,在经过很长的 e p i s o d e episode episode 达到平稳状态之后后,得到的在每个 s s s 的概率,可以看作是权重。
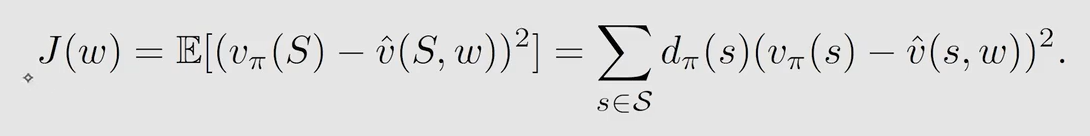
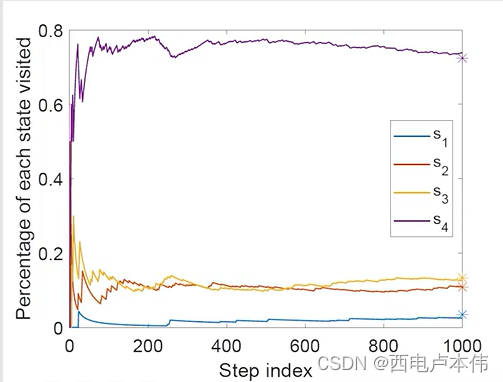
一个例子解释 d π ( s ) d_{\pi}(s) dπ(s):

图中给定了策略,用 n π ( s ) n_{\pi}(s) nπ(s) 来表示在一个非常长的 e p i s o d e episode episode 中访问到 s s s 的次数,那么 d π ( s ) d_{\pi}(s) dπ(s) 就可以表示为:
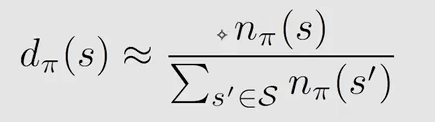
可以看到当 e p i s o d e episode episode 很长时,访问到 s s s 的概率会趋于稳定:
8.2 优化目标函数与函数选择
采用梯度下降的算法来优化上述目标函数:
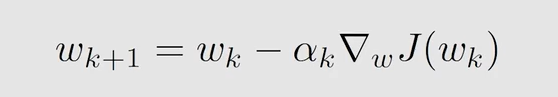
可得真实的梯度为:
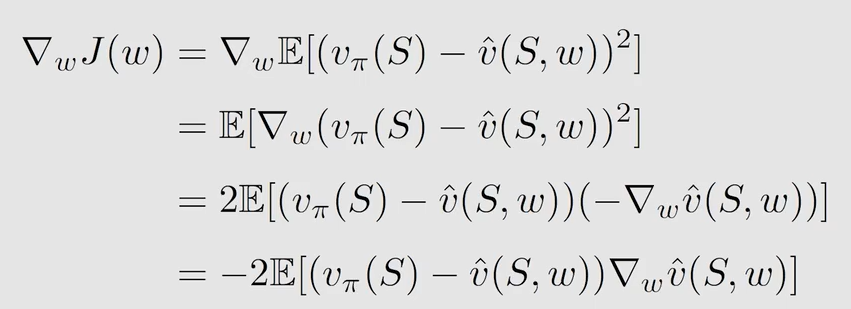
式中有期望不好求,用随机梯度代替真实梯度,即使用随机梯度下降求解:

式中 s t s_t st 是 S S S 的采样,且把 2 α k 2\alpha_k 2αk 合并为 α k \alpha_k αk
但是 v π ( s t ) v_{\pi}(s_t) vπ(st) 是不知道的,因为它是真实的 s t a t e v a l u e state \ value state value,可以用两种方法代替。
-
M o n t e C a r l o l e a r n i n g w i t h f u n c t i o n a p p r o x i m a t i o n Monte \ Carlo \ learning \ with \ function\ approximation Monte Carlo learning with function approximation
用 g t g_t gt 表示一个从状态 s t s_t st 出发经过一个 e p i s o d e episode episode 得到的 d i s c o u n t e d r e t u r n discounted \ return discounted return 来近似 v π ( s t ) v_{\pi}(s_t) vπ(st)
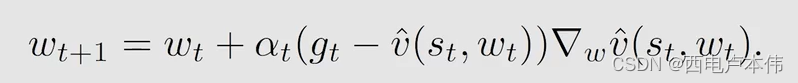
-
T D l e a r n i n g w i t h f u n c t i o n a p p r o x i m a t i o n TD \ learning \ with \ function\ approximation TD learning with function approximation
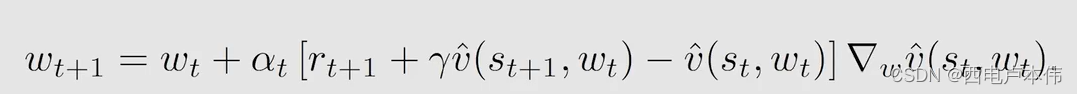
还有一个问题,式中还需要求 v ^ \hat v v^ 的梯度,求梯度需要只要曲线的表达式,在实际问题中应该如何选取表达式呢?
-
使用线性函数

可以算出梯度 ∇ w v ^ ( s , w ) = ϕ ( s ) \nabla_w \hat v(s,w)=\phi(s) ∇wv^(s,w)=ϕ(s)
带入到上述 T D l e a r n i n g w i t h f u n c t i o n a p p r o x i m a t i o n TD \ learning \ with \ function\ approximation TD learning with function approximation 中,得到 T D − L i n e a r TD-Linear TD−Linear
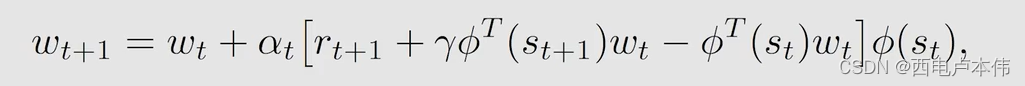
-
使用神经网络
神经网络的输入为 s s s,输出为 v ^ ( s , w ) \hat v(s,w) v^(s,w),网络参数为 w w w
8.3 Sarsa & Q-Learning和值函数近似相结合
S a r s a & Q − L e a r n i n g Sarsa \ \& \ Q-Learning Sarsa & Q−Learning 都是求 a c t i o n v a l u e action \ value action value
s a r s a w i t h f u n c t i o n a p p r o x i m a t i o n sarsa \ with \ function \ approximation sarsa with function approximation
同上, q ^ \hat q q^ 的选取要么是线性函数,要么是神经网络
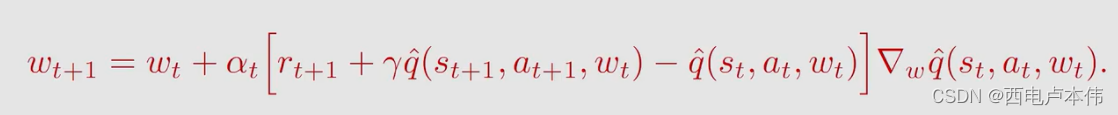
伪代码如下:

Q − L e a r n i n g w i t h f u n c t i o n a p p r o x i m a t i o n Q-Learning\ with \ function \ approximation Q−Learning with function approximation
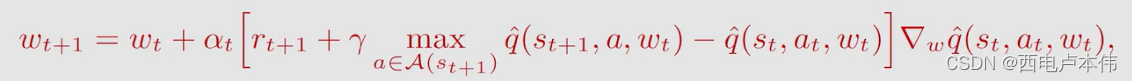
伪代码如下:

8.4 Deep Q-network
D e e p Q − n e t w o r k Deep \ Q-network Deep Q−network 的目的是最小化一个目标函数(或者说是损失函数):
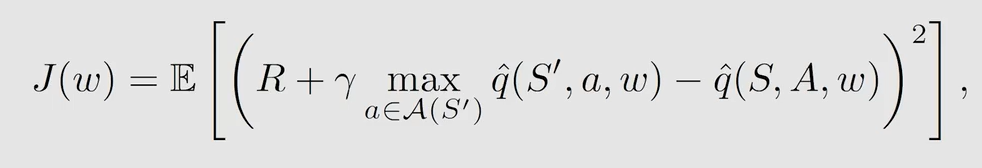
如何最小化 J ( w ) J(w) J(w),当然是梯度下降了。但是式子中有两处关于 w w w 的表达式,导致梯度不好计算。
为此, D e e p Q − n e t w o r k Deep \ Q-network Deep Q−network 引入了两个网络:
- m a i n n e t w o r k main \ network main network:代表 q ^ ( s , a , w ) \hat q(s,a,w) q^(s,a,w)
- t a r g e t n e t w o r k target \ network target network:代表 q ^ ( s , a , w T ) \hat q(s,a,w_T) q^(s,a,wT)
目标函数转换为:
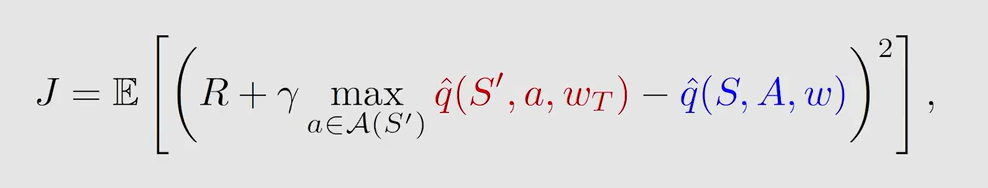
优化过程如下:先假设 w T w_T wT 是固定的(保持不变,不用更新),对 m a i n n e t w o r k main \ network main network 中的 w w w 进行更新来优化 J J J,经过一段时间之后将 w w w 的赋值给 w T w_T wT,最终 w w w 与 w T w_T wT 都能收敛到最优值。
由于假设 w T w_T wT 是固定的,可计算出梯度:

总体算法流程:根据给定策略采样 { ( s , a , r , s ′ ) } \{(s,a,r,s')\} {(s,a,r,s′)},神经网络的输入为 s , a s,a s,a,输出 q ^ \hat q q^ 并计算 y T = r + γ max a ∈ A ( s ′ ) q ^ ( s ′ , a , w T ) y_T=r+\gamma \max_{a \in A(s')}\hat q(s',a,w_T) yT=r+γmaxa∈A(s′)q^(s′,a,wT) ,更新网络参数 w w w 来最小化损失函数 ( y T − q ^ ( s , a , w ) ) 2 (y_T-\hat q(s,a,w))^2 (yT−q^(s,a,w))2 ,一段时间后用更新的 w w w 来更新 w T w_T wT。
除了使用两个网络, D e e p Q − n e t w o r k Deep \ Q-network Deep Q−network 还使用了经验回放。
-
什么是经验回放?
我们并不需要将收集到的 e x p e r i e n c e experience experience 按序输入神经网络,而是将这些采样放到 r e p l a y b u f f e r replay \ buffer replay buffer 中,训练时按批次取(服从均匀分布,即取得概率相同)
-
为什么需要经验回放?
由于 a g e n t agent agent 与环境交互得到的训练样本并不是独立同分布的,利用 r e p l a y b u f f e r replay \ buffer replay buffer 将过去的 e x p e r i e n c e experience experience 和目前的 e x p e r i e n c e experience experience 混合,降低了数据相关性。并且经验回放还使得样本可重用,从而提高学习效率。
伪代码:

九、策略函数近似(梯度)方法(Policy function approximation / gradient)
9.1 策略梯度的基本思想
值函数近似的思想解决了维度灾难的问题,同样策略函数近似也是将基于表格的策略转换为用函数(通常用神经网络)进行表示: π ( a ∣ s , θ ) \pi(a|s,\theta) π(a∣s,θ)

基本思想:
- 定义一个目标函数来表示最优策略 J ( θ ) J(\theta) J(θ)
- 使用梯度上升最大化目标 θ t + 1 = θ t + α ∇ θ J ( θ t ) \theta_{t+1}=\theta_t+\alpha \nabla_{\theta}J(\theta_t) θt+1=θt+α∇θJ(θt)
与值函数近似面临的问题一样:
- 如何选取目标函数
- 如何计算目标函数的梯度
9.2 目标函数的选取
-
A v e r a g e v a l u e Average \ value Average value
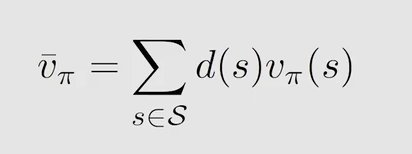
v − π \overset{-}{v}_{\pi} v−π 表示 s t a t e v a l u e state \ value state value 的加权平均, d ( s ) d(s) d(s) 表示权重(或者说是状态的概率分布)。该式也可以表示为: v − π = E [ v π ( S ) ] \overset{-}{v}_{\pi}=\mathbb{E}[v_{\pi}(S)] v−π=E[vπ(S)]
矩阵形式表示为:
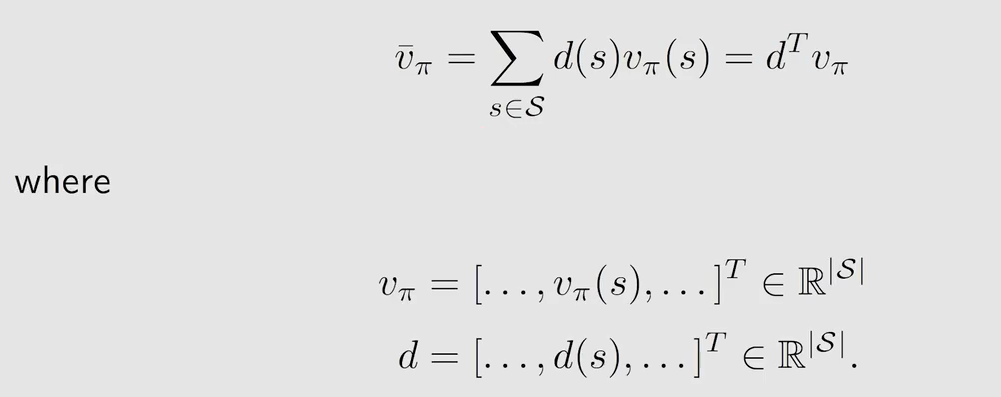
r − π \overset{-}{r}_{\pi} r−π 另外一种表示:

如何选择概率分布 d d d ?
-
d
d
d 与策略
π
\pi
π 无关
- d d d 被写作 d 0 d_0 d0, v − π \overset{-}{v}_{\pi} v−π 被写作 v − π 0 \overset{-}{v}^0_{\pi} v−π0
- d 0 d_0 d0 要么取均匀分布,每个状态的概率都是 1 n \frac{1}{n} n1;那么只关心某一个状态,比如是 s 0 s_0 s0,使得 d 0 ( s 0 ) = 1 d_0(s_0)=1 d0(s0)=1, d 0 ( s ≠ s 0 ) = 0 d_0(s \neq s_0)=0 d0(s=s0)=0
-
d
d
d 与策略
π
\pi
π 有关
- d d d 被写作 d π ( s ) d_{\pi}(s) dπ(s),是策略 π \pi π 下的 s t a t i o n a r y d i s t r i b u t i o n stationary \ distribution stationary distribution
- 在8.1节已经介绍过,简而言之就是用一个策略不断与环境交互生成 e p i s o d e episode episode,就可以预测 a g e n t agent agent 在某个状态的概率是多少。访问次数多的状态对应的 d π ( s ) d_{\pi}(s) dπ(s) 值大。
-
d
d
d 与策略
π
\pi
π 无关
-
A v e r a g e r e w a r d Average \ reward Average reward
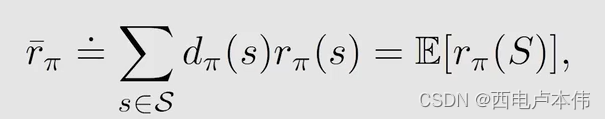
式中 r π ( s ) r_{\pi}(s) rπ(s) 表示从状态 s s s 出发,采取不同动作所能获得的即刻奖励,这个是在状态 s s s 获得的即刻奖励, d π ( s ) d_{\pi}(s) dπ(s) 是策略 π \pi π 下的 s t a t i o n a r y d i s t r i b u t i o n stationary \ distribution stationary distribution
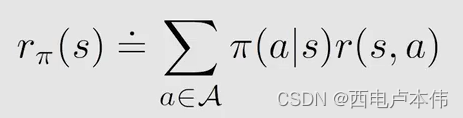
式中 r ( s , a ) r(s,a) r(s,a) 也是服从概率分布的( r e w a r d p r o b a b i l i t y reward \ probability reward probability)表示为,这个是在动作 a a a 获得的即刻奖励:
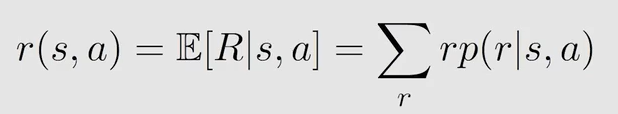
r − π \overset{-}{r}_{\pi} r−π 另外一种表示:
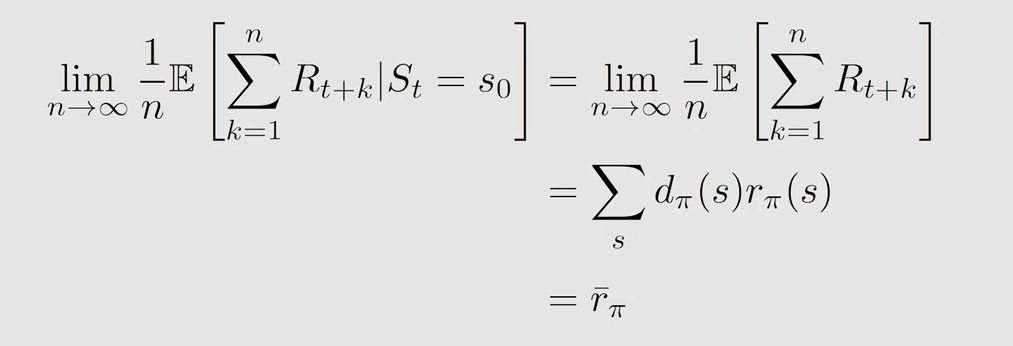
关于目标函数的补充说明:
- v − π \overset{-}{v}_{\pi} v−π 和 r − π \overset{-}{r}_{\pi} r−π 都是关于策略 π \pi π 的函数
- π \pi π 是关于 θ \theta θ 的参数,所以 v − π \overset{-}{v}_{\pi} v−π 和 r − π \overset{-}{r}_{\pi} r−π 也是关于 θ \theta θ 的函数
- 不同的 θ \theta θ 对应不同的 v − π \overset{-}{v}_{\pi} v−π 和 r − π \overset{-}{r}_{\pi} r−π ,因此需要找到最优的 θ \theta θ 取最大化 v − π \overset{-}{v}_{\pi} v−π 和 r − π \overset{-}{r}_{\pi} r−π
- r − π = ( 1 − γ ) v − π \overset{-}{r}_{\pi}=(1-\gamma)\overset{-}{v}_{\pi} r−π=(1−γ)v−π
9.3 目标函数的梯度计算
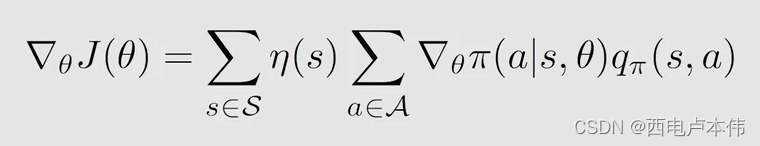
式中目标函数 J ( θ ) J(\theta) J(θ) 可以为 v − π \overset{-}{v}_{\pi} v−π 、 r − π \overset{-}{r}_{\pi} r−π 和 v − π 0 \overset{-}{v}^0_{\pi} v−π0, η \eta η 为状态 s s s 的权重。式中的 = = = 也分三种情况:严格 = = =, ≈ \approx ≈ 和比例等于。具体地:
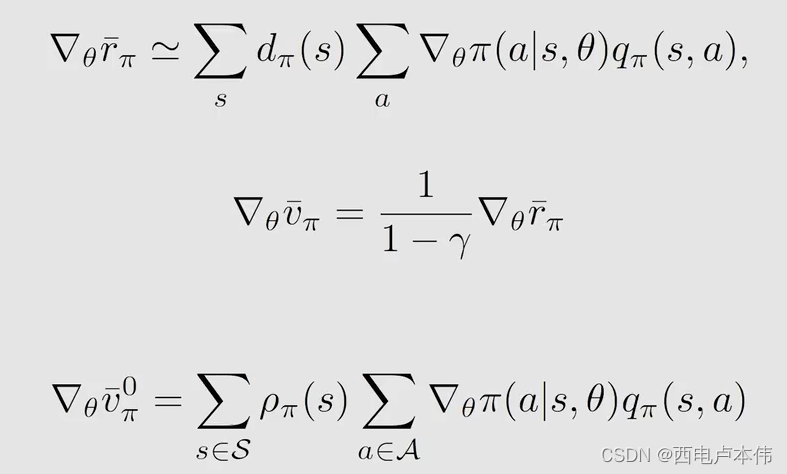
可以把上式中求和转化为期望:

然后使用随机梯度思想,用采样来代替分布:
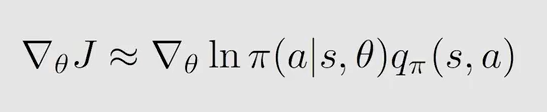
观察式子发现为了使 l n ln ln 有意义, π ( a ∣ s , θ ) \pi(a|s,\theta) π(a∣s,θ) 必须大于0,所以要使用归一化(神经网络的输出加上一个 s o f t m a x softmax softmax 层),即让所有动作选择的概率统一到 ( 0 , 1 ) (0,1) (0,1) 这个区间。因为对于所有的动作 π ( a ∣ s , θ ) > 0 \pi(a|s,\theta)>0 π(a∣s,θ)>0,所以这个策略是 s t o c h a s t i c stochastic stochastic 的并且是有探索性的。且此式不能计算有无穷多个 a c t i o n action action 的情况。
9.4 梯度上升和REINFORCE
用梯度上升算法求解 θ \theta θ:
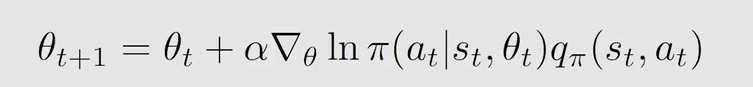
式中 q π q_{\pi} qπ 是 a c t i o n v a l u e action \ value action value 是未知的,用 q t q_t qt 代替。 q t q_t qt 可以用蒙特卡洛估计的方法来得到,也可以通过 T D TD TD 算法来得到,同8.2节介绍的一样。
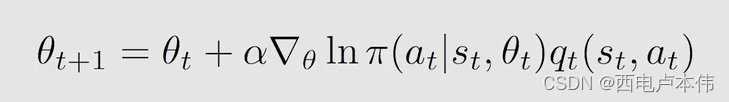
如果 q t q_t qt 是通过蒙特卡洛估计得到的,那么此策略梯度的算法被称作 R E I N F O R C E REINFORCE REINFORCE,它是 o n − p o l i c y on-policy on−policy 的,伪代码如下:

十、演员-评论家方法(Actor-Critic Methods)
- a c t o r actor actor 对应 p o l i c y u p d a t e policy \ update policy update
- c r i t i c critic critic 对应 p o l i c y e v a l u a t i o n / v a l u e e s t i m a t i o n policy \ evaluation \ / \ value \ estimation policy evaluation / value estimation
10.1 最简单的 Actor-Critic(QAC)
在第九节中介绍的 R E I N F O R C E REINFORCE REINFORCE 中, q t q_t qt 这个估计值是根据蒙特卡洛估计得到的。如果 q t q_t qt 是通过 T D TD TD 算法得到的,就将其称之为 A c t o r − C r i t i c Actor-Critic Actor−Critic

说明:
- 将值函数近似(求得 q q q )与策略梯度(更新 θ \theta θ )相结合
- c r i t i c critic critic 对应 s a r s a + v a l u e f u n c t i o n a p p r o x i m a t i o n sarsa+value \ function \ approximation sarsa+value function approximation
- a c t o r actor actor 对应梯度上升,用于更新策略
- 是 o n − p o l i c y on-policy on−policy 的
10.2 Advantage Actor-Critic
A d v a n t a g e A c t o r − C r i t i c Advantage \ Actor-Critic Advantage Actor−Critic 是 A c t o r − C r i t i c Actor-Critic Actor−Critic 的一个推广,引入了一个偏置量 b a s e l i n e baseline baseline 来减小估计的方差。
通常认为最好的 b a s e l i n e baseline baseline: b ( s ) = v π ( s ) b(s)=v_{\pi}(s) b(s)=vπ(s)

式中 δ π ( S , A ) \delta_{\pi}(S,A) δπ(S,A) 被称为 a d v a n t a g e f u n c t i o n advantage \ function advantage function,它描述了在某一状态下 a c t i o n v a l u e action \ value action value 和 s t a t e v a l u e state \ value state value 的差值 :
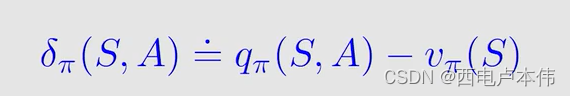
通过采样得到:
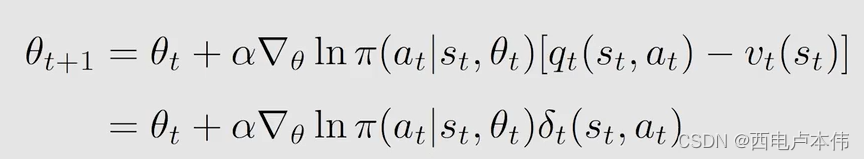
δ t \delta_t δt 也可以用 T D E r r o r TD \ Error TD Error 表示:
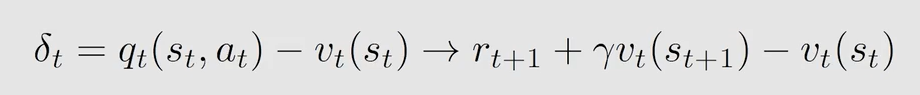
A d v a n t a g e A c t o r − C r i t i c Advantage \ Actor-Critic Advantage Actor−Critic 伪代码如下:

10.3 重要性采样
考虑有随机变量
X
∈
χ
=
{
−
1
,
+
1
}
X \in \chi=\{-1,+1\}
X∈χ={−1,+1},且满足概率分布
p
0
p_0
p0,有
p
0
(
X
=
+
1
)
=
0.5
,
p
0
(
X
=
−
1
)
=
0.5
p_0(X=+1)=0.5,\quad p_0(X=-1)=0.5
p0(X=+1)=0.5,p0(X=−1)=0.5
则可以求得期望
E
X
∼
p
0
[
X
]
=
(
+
1
)
∗
0.5
+
(
−
1
)
∗
0.5
=
0
\mathbb{E}_{X \sim p_0}[X]=(+1)*0.5+(-1)*0.5=0
EX∼p0[X]=(+1)∗0.5+(−1)∗0.5=0
如果
X
X
X 满足概率分布
p
1
p_1
p1,有:
p
0
(
X
=
+
1
)
=
0.8
,
p
0
(
X
=
−
1
)
=
0.2
p_0(X=+1)=0.8,\quad p_0(X=-1)=0.2
p0(X=+1)=0.8,p0(X=−1)=0.2
则可以求得期望
E
X
∼
p
1
[
X
]
=
(
+
1
)
∗
0.8
+
(
−
1
)
∗
0.2
=
0.6
≠
E
X
∼
p
0
[
X
]
\mathbb{E}_{X \sim p_1}[X]=(+1)*0.8+(-1)*0.2=0.6 \neq \mathbb{E}_{X \sim p_0}[X]
EX∼p1[X]=(+1)∗0.8+(−1)∗0.2=0.6=EX∼p0[X]
不同概率分布下求得的期望当然是不同的,有什么方法可以使得在概率分布为 p 1 p_1 p1 的情况话求得 p 0 p_0 p0 的期望吗?
可以使用重要性采样的方式:
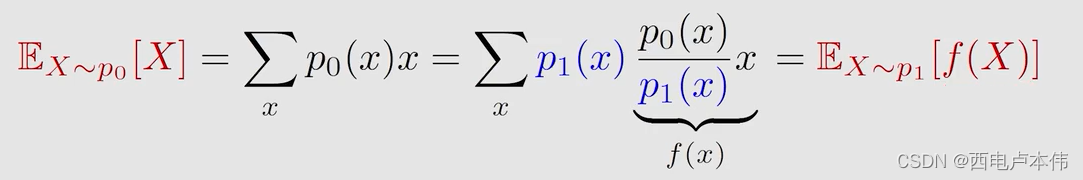
这样就可以用 E X ∼ p 1 [ f ( X ) ] \mathbb{E}_{X \sim p_1}[f(X)] EX∼p1[f(X)] 来估计 E X ∼ p 0 [ X ] \mathbb{E}_{X \sim p_0}[X] EX∼p0[X]
如何求 E X ∼ p 1 [ f ( X ) ] \mathbb{E}_{X \sim p_1}[f(X)] EX∼p1[f(X)] ?
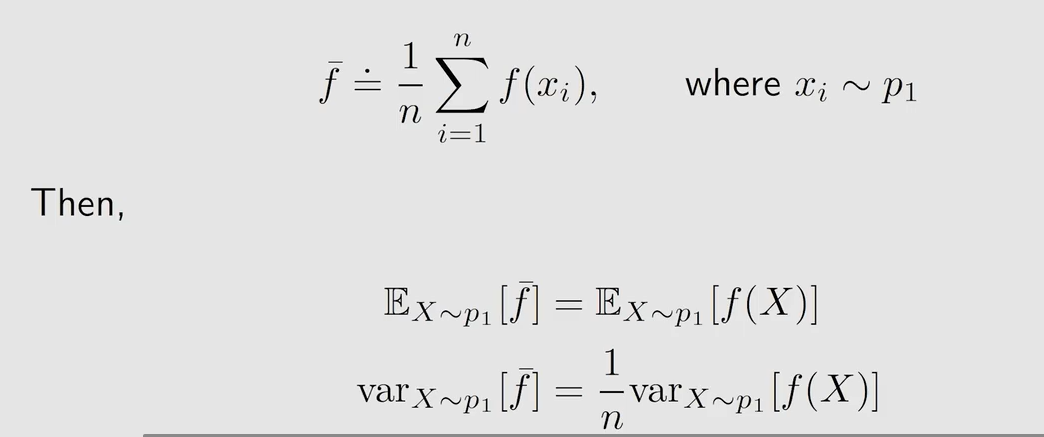
故得:

式中 p 0 ( x i ) p 1 ( x i ) \frac{p_0(x_i)}{p_1(x_i)} p1(xi)p0(xi) 为重要性权重
总的来说:

10.4 off-policy 的策略梯度
前几节所述的策略梯度和 AC 算法都是 o n − p o l i c y on-policy on−policy 的。现介绍 o f f − p o l i c y off-policy off−policy 的策略梯度。
-
假设 β \beta β 是 b e h a v i o r p o l i c y behavior \ policy behavior policy 用于生成 e x p e r i e n c e s a m p l e s experience \ samples experience samples
-
我们的目标是更新 t a r g e t p o l i c y π target \ policy \ \pi target policy π,通过最大化这个目标函数:
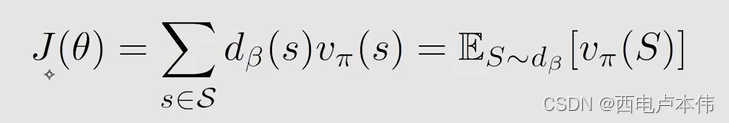
式中 θ \theta θ 是关于 t a r g e t p o l i c y π target \ policy \ \pi target policy π 的参数, d β ( s ) d_{\beta}(s) dβ(s) 是在策略 β \beta β 下的 s t a t i o n a r y d i s t r i b u t i o n stationary \ distribution stationary distribution,相当于权重。
-
目标函数的梯度为:
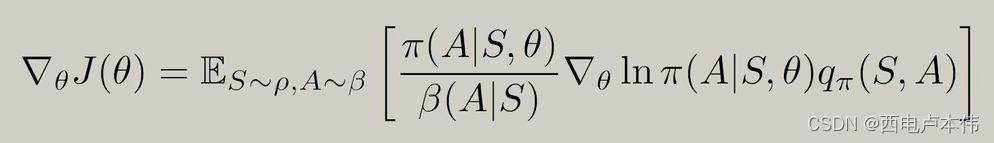
式中 π ( A ∣ S , θ ) β ( A ∣ S ) \frac{\pi(A|S,\theta)}{\beta(A|S)} β(A∣S)π(A∣S,θ) 实际上就是重要性采样, π ( A ∣ S , θ ) \pi(A|S,\theta) π(A∣S,θ) 对应 p 0 p_0 p0, β ( A ∣ S ) \beta(A|S) β(A∣S) 对应 p 1 p_1 p1
-
然后就是用梯度上升找到最优的 θ \theta θ,同样是采用随机梯度用采样代替期望:
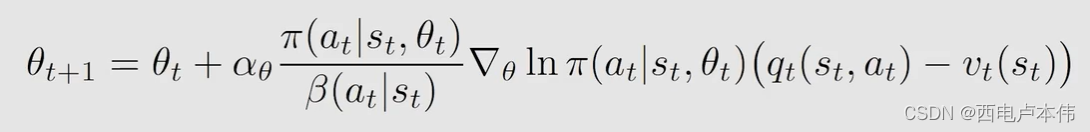
式中是加了 b a s e l i n e baseline baseline 的情况,用来减少估计的方法。
同 A d v a n t a g e A c t o r − C r i t i c Advantage \ Actor-Critic Advantage Actor−Critic 一样,可以用 δ t \delta_t δt 来描述在某一状态下 a c t i o n v a l u e action \ value action value 和 s t a t e v a l u e state \ value state value 的差值 :
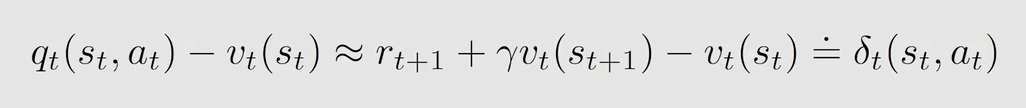
进而:
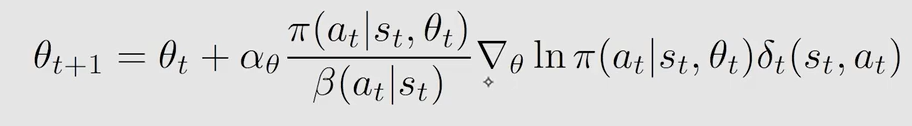
算法对应伪代码如下:

10.5 Deterministic Actor-Critic
对于前面的策略梯度和 AC 算法,都有 π ( a ∣ s , θ ) > 0 \pi(a|s,\theta)>0 π(a∣s,θ)>0,即策略是 s t o c h a s t i c stochastic stochastic 的,也提到了是不能计算有无穷多个 a c t i o n action action 的情况(见9.3节)。
采用 d e t e r m i n i s t u c p o l i c y deterministuc \ policy deterministuc policy 就可以解决这样的问题。
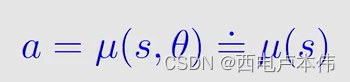
策略为 μ \mu μ,输出不再是采用动作的概率,而是直接输出应该执行的动作。
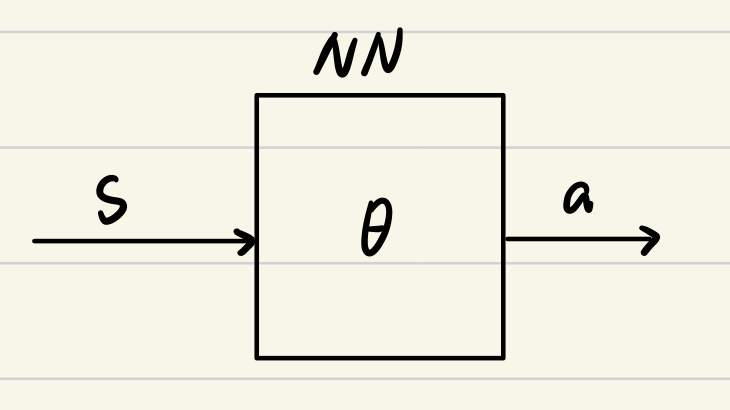
跟前面一样,也是采用梯度上升找到最优的 θ \theta θ 进而找到最优的策略。
第一步选取目标函数:
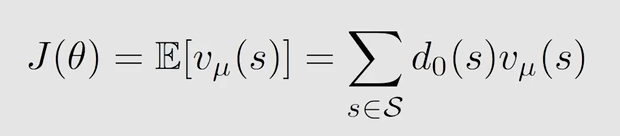
d 0 d_0 d0 的选取有两种情况:
- 只关心某一个状态,比如是 s 0 s_0 s0,使得 d 0 ( s 0 ) = 1 d_0(s_0)=1 d0(s0)=1, d 0 ( s ≠ s 0 ) = 0 d_0(s \neq s_0)=0 d0(s=s0)=0
- d 0 d_0 d0 是 b e h a v i o r p o l i c y behavior \ policy behavior policy(例如 β \beta β) 下的 s t a t i o n a r y d i s t r i b u t i o n stationary \ distribution stationary distribution,这意味着此算法是 o f f − p o l i c y off-policy off−policy 的
第二步求梯度:
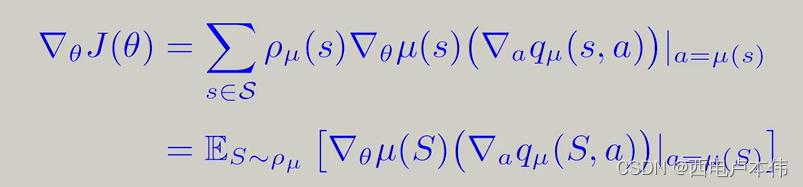
第三步梯度上升:
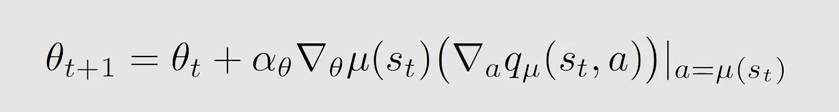
伪代码如下:















 3780
3780











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









