







Dropout 的学习笔记,主要参考文章:
1. 简介
深度学习训练模型的一个主要挑战是协同适应,这意味着神经元之间是相互依赖的,也就是相对于输入它们还不够独立,而且经常会有一些神经元具有更重要的预测能力,这可能导致模型会过度依赖个别的神经元的输出。
但这种情况应该要避免,权重必须具有一定的分布,从而防止过拟合。通常可以采用正则化的方法来避免过拟合,正则化能调节某些神经元的协同适应和高预测能力。最常用的一种正则化方法就是 Dropout。
Dropout,中文是随机失活,是一个简单又机器有效的正则化方法,可以和L1正则化、L2正则化和最大范数约束等方法互为补充。
接下来将介绍不同的 Dropout 方法,并且在不同深度网络结构上也会有区别,比如在 CNN,还是在 RNN 上:
-
标准的 Dropout 方法
-
标准 Dropout 的变体
-
用在CNNs上的dropout方法:标准的 Dropout 对卷积层的效果并没有很好,原因是因为每个特征图的点都对应一个感受野范围,只是随机丢弃某个像素不能降低特征图学习的特征范围,网络还可以通过失活位置相邻像素学习对应的语义信息;
-
用在RNNs上的dropout方法
-
其他的dropout应用(蒙特卡洛和压缩)
2. 标准的 Dropout 方法
最常用的 dropout 方法是 Hinton 等人在 2012 年推出的Standard dropout。通常简单地称为“Dropout”,由于显而易见的原因,在本文中我们将称之为标准的Dropout。

标准的 Dropout 方法主要应用在训练阶段,避免该阶段的过拟合问题,而且通常设置一个概率 p,表示每次迭代中,每个神经元被去掉的概率,如上图所示,设置的 p=0.5。在 Hinton 论文中建议输入层的 p=0.2,隐藏层的 p=0.5,然后输出层是不需要采用 Dropout,毕竟需要的就是输出层的结果。
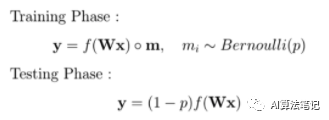
数学上表示如上所示,每个神经元丢弃概率遵循概率为 p 的伯努利分布,所以用一个 mask 对神经元向量进行了一个元素级操作,其中每个元素都是遵循伯努利分布的随机变量。
在训练过程中,Dropout会随机失活,可以被认为是对完整的神经网络的一些子集进行训练,每次基于输入数据只更新子网络的参数。
在测试阶段则是没有采用 Dropout。所有的神经元都是活跃的。为了补偿与训练阶段相比较的额外信息,用出现的概率来平衡加权权重。所以神经元没有被忽略的概率,是“1 - p”。
在论文中,作者通过实验表明了 Dropout 的有效性原因是在两方面:
-
Dropout 可以破坏神经元之间的协同适应性,使得在使用Dropout后的神经网络提取的特征更加明确,增加了模型的泛化能力;
-
从神经元之间的关系来说,则是 Dropout 能够随机让一些神经元临时不参与计算,这样的条件下可以减少神经元之间的依赖,权值的更新不再依赖固有关系的隐含节点的共同作用,这样会迫使网络去学习更加鲁棒的特征。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











