






 欢迎来到雲闪世界。神经网络是一种机器学习模型。这只是我计划撰写的关于深度学习的整个系列文章的第一篇。它将重点介绍一个简单的人工神经网络如何学习,并为您提供对神经网络如何逐个神经元构建的深入(哈哈,双关语)理解,这在我们继续构建这些知识时至关重要。
欢迎来到雲闪世界。神经网络是一种机器学习模型。这只是我计划撰写的关于深度学习的整个系列文章的第一篇。它将重点介绍一个简单的人工神经网络如何学习,并为您提供对神经网络如何逐个神经元构建的深入(哈哈,双关语)理解,这在我们继续构建这些知识时至关重要。
你可能会想:我们为什么需要神经网络?有这么多机器学习算法可用,为什么选择神经网络?这个问题的答案很多,而且讨论得也很广泛,所以我们就不深入探讨了。但值得注意的是,神经网络非常强大。它们可以识别传统算法难以处理的数据中的复杂模式,解决高度复杂的机器学习问题(如自然语言处理和图像识别),并减少对大量特征工程和手动工作的需要。
但综上所述,神经网络问题基本上可以归结为两个主要类别 - 分类,预测给定输入的离散标签(例如:这是一张猫还是狗的照片?这个电影评论是正面的还是负面的?)或回归,预测给定输入的连续值(例如:天气预报 - 明天的气温是多少?)。
今天我们将重点讨论回归问题。考虑一个简单的场景:我们最近搬到了一个新城市,目前正在寻找新家。然而,我们注意到该地区的房价差异很大。
由于我们对这座城市不熟悉,我们唯一的信息来源就是在网上找到的信息。我们偶然发现了一栋令我们感兴趣的房子,但不确定它的价格是否合理。
因此,我们决定建立一个神经网络,根据某些特征预测房价——房屋面积(单位为平方英尺)、位置(1=城市、2=郊区、3=农村)、房龄和卧室数量。我们的目标是利用这些特征来预测房价。
我们做的第一件事是收集有关附近房屋及其售价的数据。
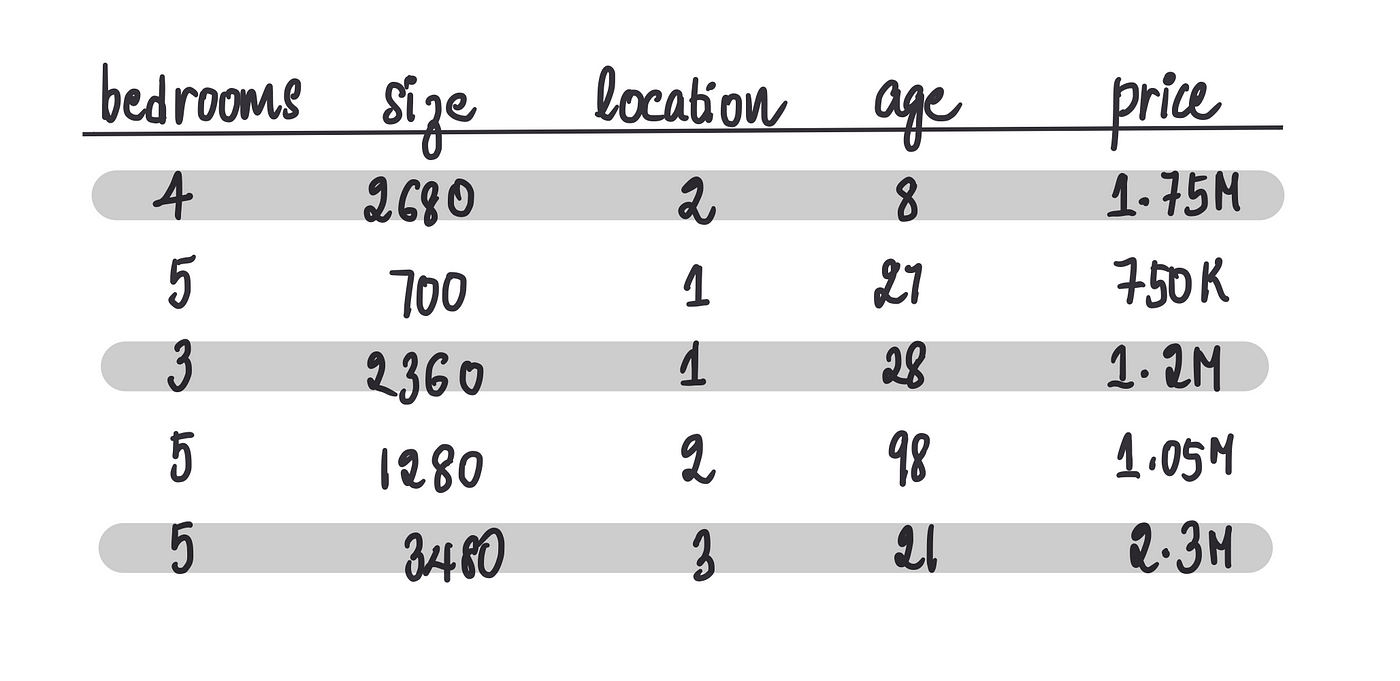
接下来,我们要训练一个神经网络。训练包括将数据集输入到模型中,模型会学习数据中的模式。
术语 segue:由于我们使用上述数据集来训练模型,因此它被称为训练数据。通常我们的训练数据将包含 1000 行甚至 100000 行,但目前我们先简单介绍一下。
因此,该模型能够根据现有数据预测新房的价格。
但在进入模型构建和训练之前,让我们先了解一下为什么它被称为神经网络。
背景
神经网络使计算机能够以类似人脑的方式处理数据。它利用层层排列的相互连接的神经元,类似于人脑的结构。
这是一个生物神经元。

它接收输入,处理接收到的输入或数据(这种处理简直是神奇的),并生成输出。
就像人类的大脑通过接收输入和产生输出来处理数据一样,神经网络的运行方式也类似。

这里的蓝线代表神经元的输入。在房屋定价的背景下,这些输入可以被视为不同的特征变量,而输出将是预测的房价。
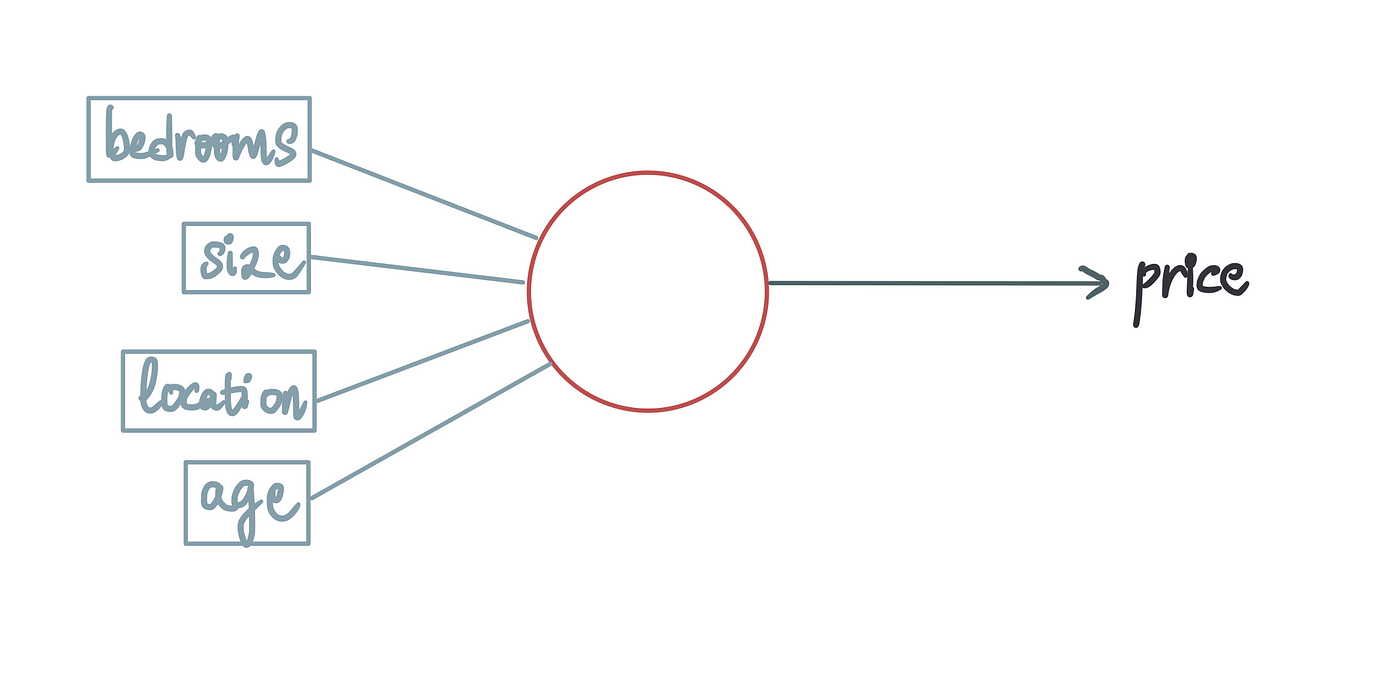
每个输入都与一个称为权重的常数项相关联。因此,让我们将它们添加到我们的人工神经元中。

这些权重的目的是表明输入的重要性。权重值越高,表示输入被认为越重要。因此,如果年龄的权重高于位置的权重,则意味着房屋年龄比房屋位置更重要。
现在,就像生物神经元中发生的一些魔法一样,这种魔法在人工神经元中也是这样的。

当我们放大时,我们看到这个魔法本质上是 2 个数学步骤。
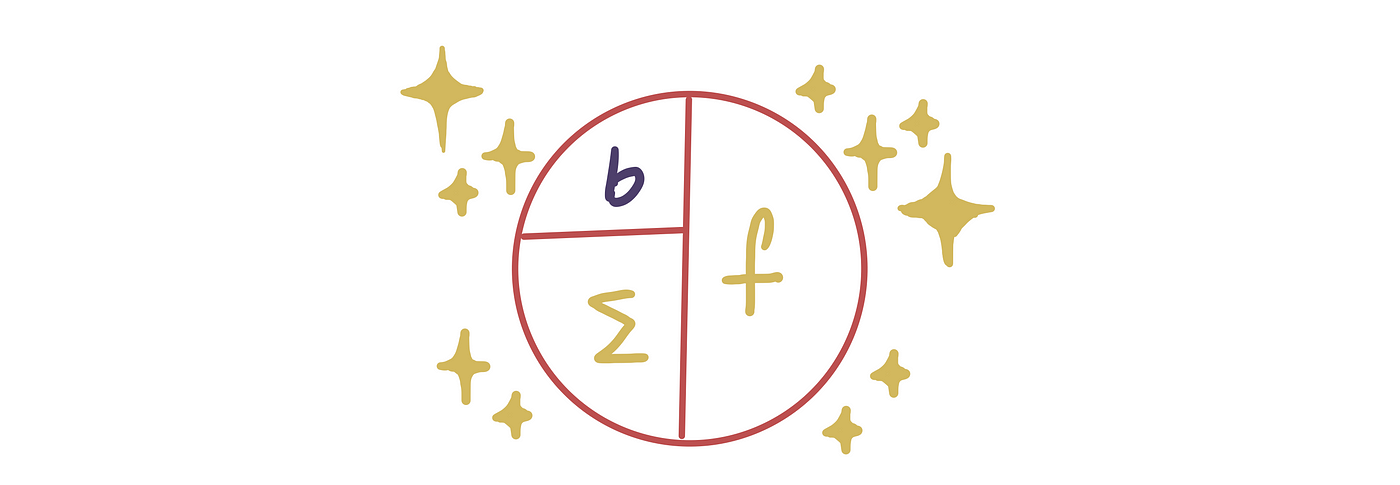
魔术,第一部分:求和
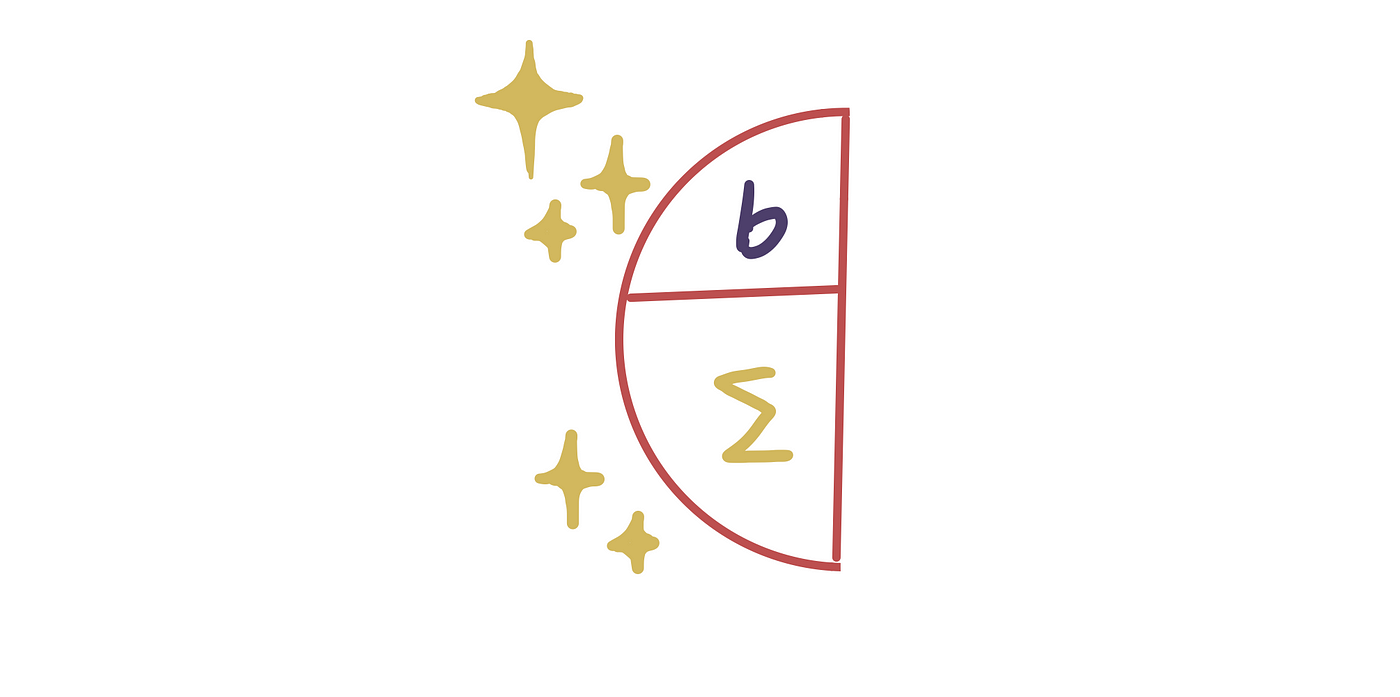
第一部分是求和。在这里,我们将每个输入乘以其相应的权重,然后将它们相加。

您可能还注意到顶部有一个小b 。这称为偏差项,它是一个常数值。我们将此值添加到加权和中以完成求和。

从数学上来说:
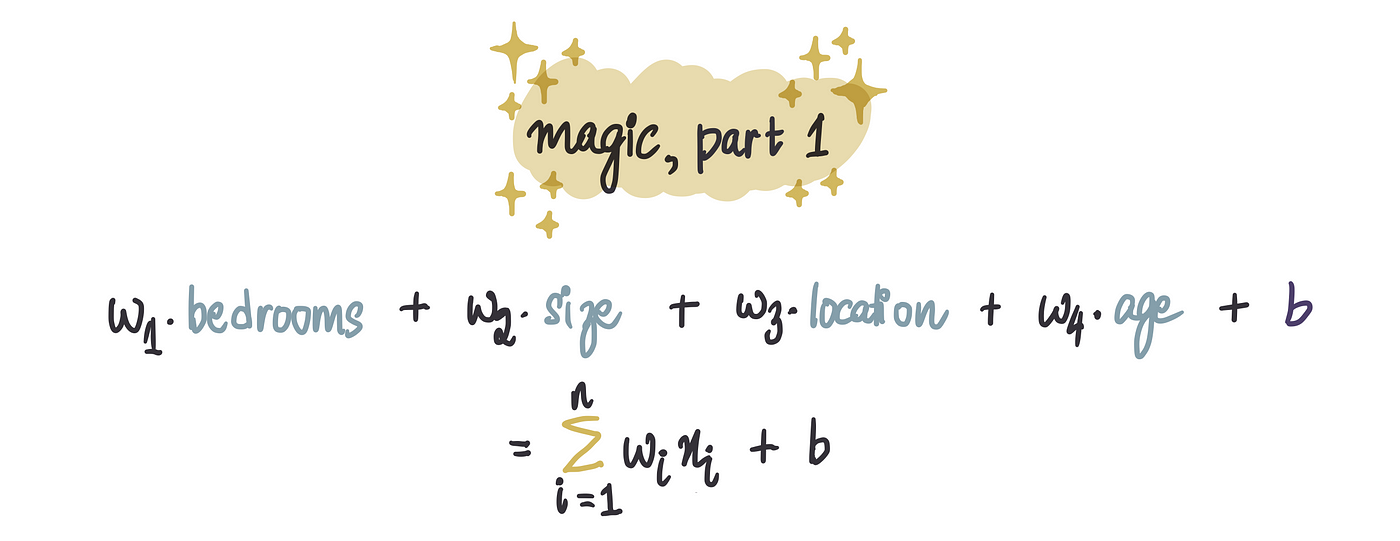
其中特征用 xᵢ 表示,n = 特征数量
魔法,第 2 部分:激活函数
这里,上述总和是通过所谓的激活函数输入的。
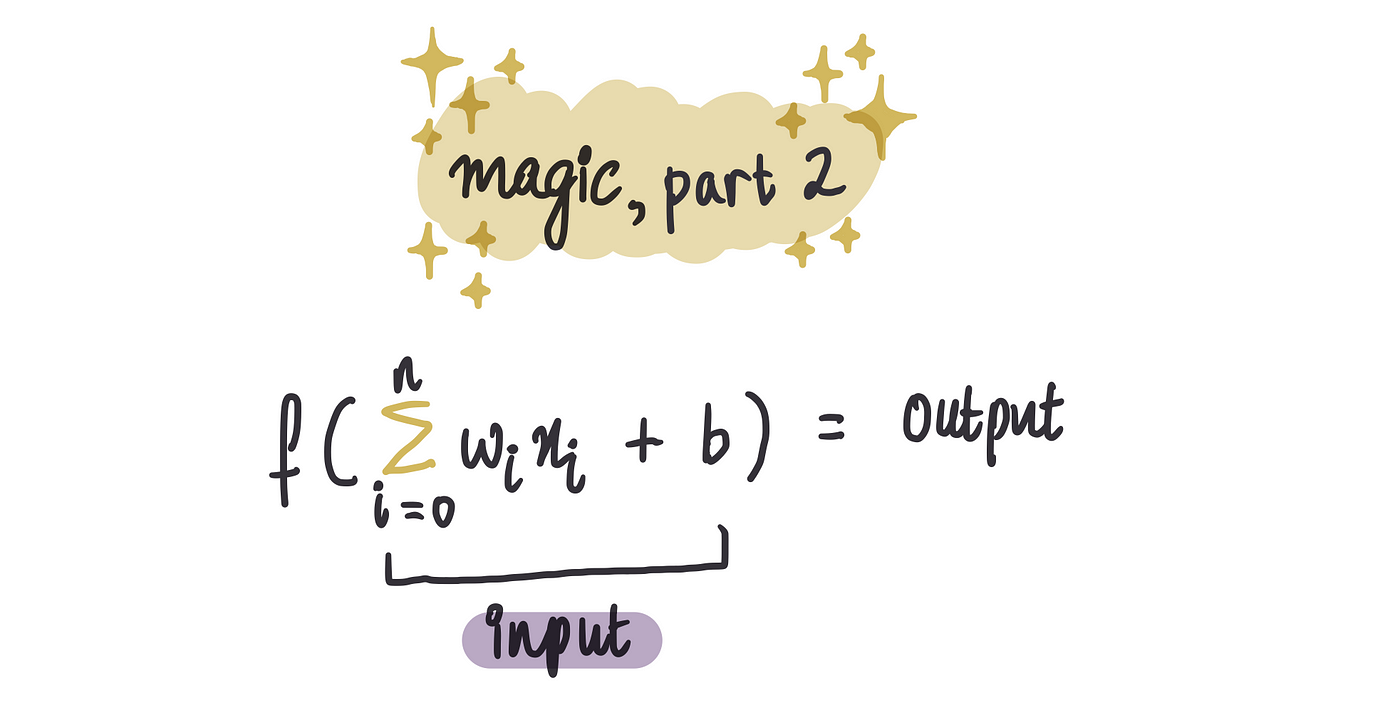
激活函数可以视为将原始数据转化为有意义见解的转换器。它们将上一步的总结转化为对我们的特定任务有用的输出。
让我们从二元阶跃函数开始。它很简单:如果您的输入(我们称之为 x)等于或大于 0,则函数输出 1;否则,它会给出 0。当您需要明确的决定(如是或否)时,这非常方便。例如,根据输入,这栋房子会卖吗?

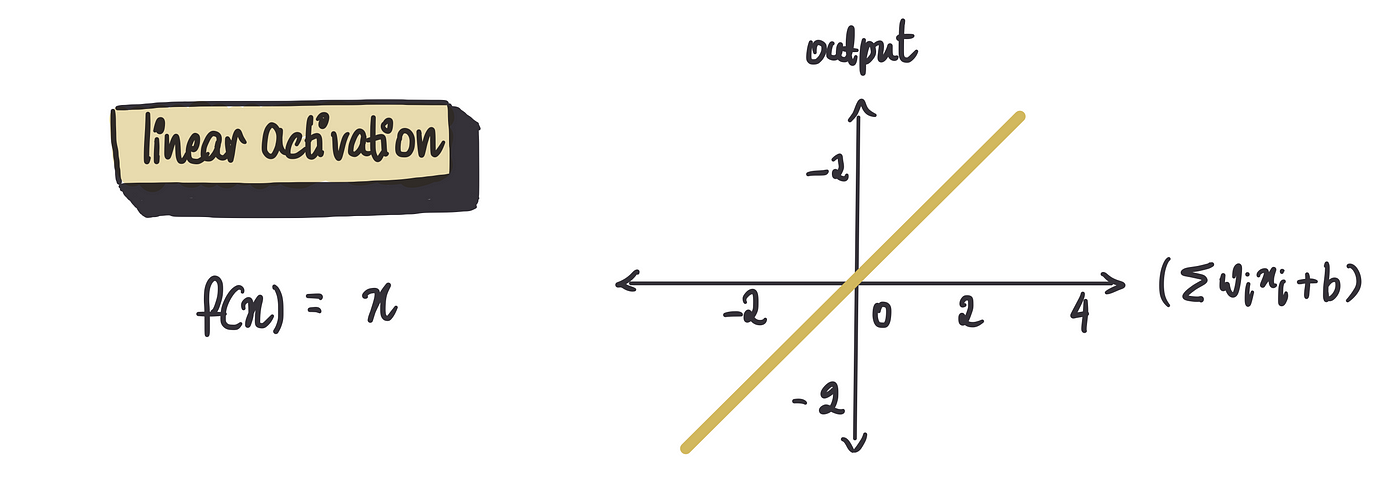
然后是线性函数,它直接给出结果。它只是返回它收到的任何值。因此,如果我们的和是 5,则输出也是 5。
接下来是 sigmoid 函数,这是一个真正的游戏规则改变者。它可以优雅地压缩任何输入值以适应 0 到 1 的范围。为什么这很棒?因为它非常适合基于概率的问题。例如,在特定条件下,房子出售的可能性有多大?

然后是双曲正切函数,简称 tanh。它与 S 型函数类似,但有一点不同:它输出的值范围从 -1 到 1。因此,较大的正输入徘徊在 1 附近,而较大的负输入接近 -1。
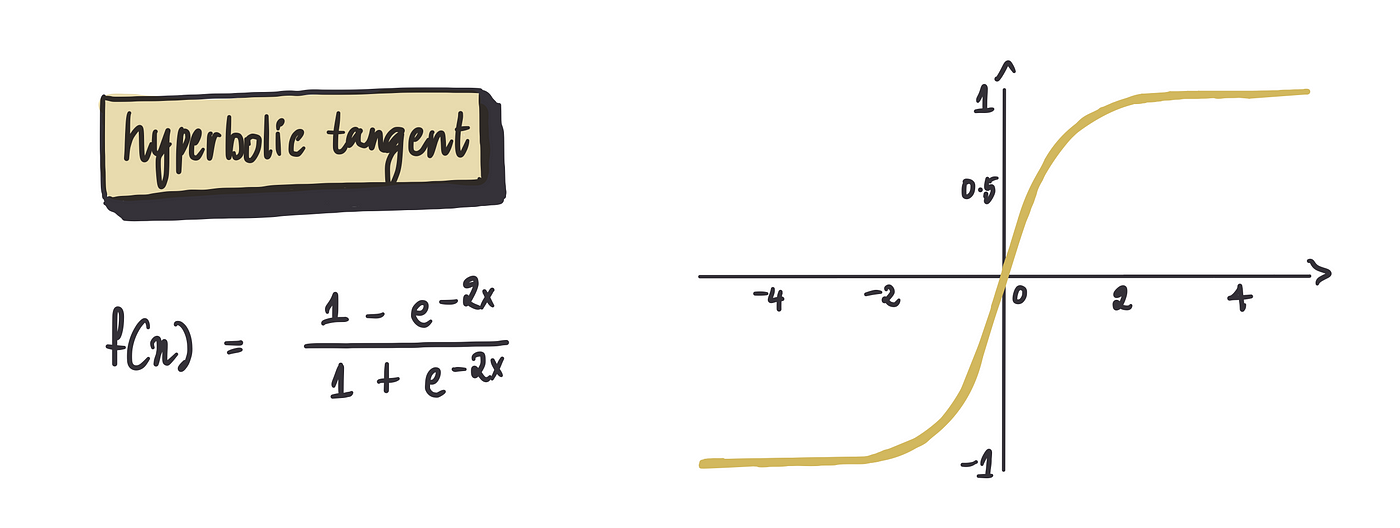
请鼓掌,我们有整流函数,也称为 ReLU(整流线性单元)。这是神经网络世界中的一颗明星。它简单但有效:如果输入为正,它会保留它;如果为负,它会将其变为零。此功能使其在许多场景中非常有用。
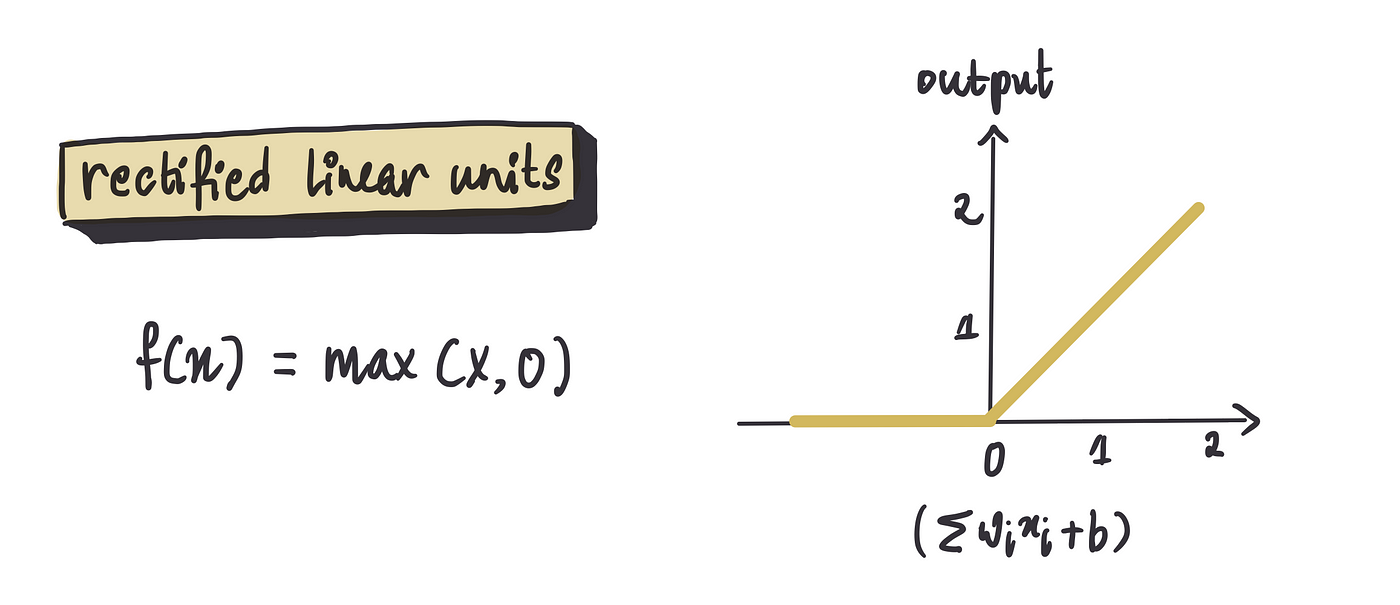
我们还有另一个称为 Leaky ReLU(Leaky Rectified Linear Unit,泄漏整流线性单元)的函数,它是常规 ReLU 的一个巧妙变体。虽然 ReLU 将所有负输入设置为零,但 Leaky ReLU 允许负输入产生较小的非零恒定输出。想象一下它就像一个稍微打开的水龙头,即使它基本关闭,也会让一小股水(或我们这里所说的数据)流过。

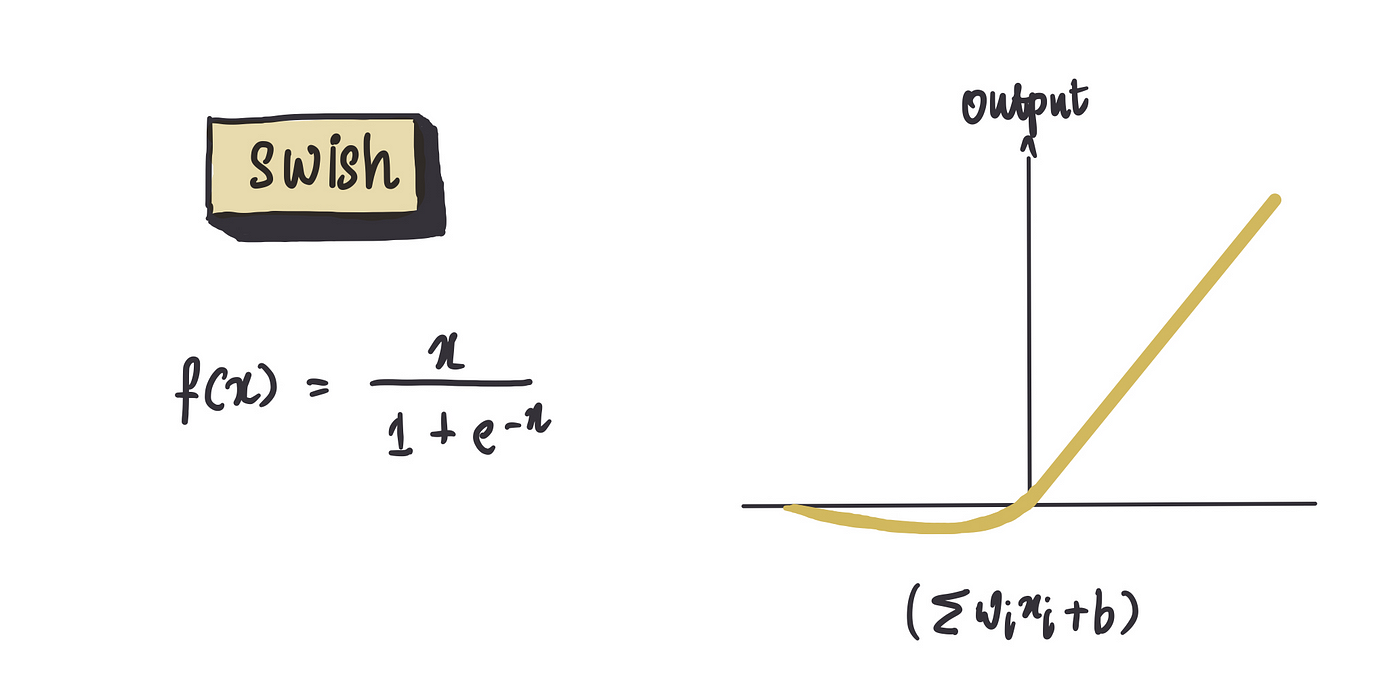
我们将要讨论的最后一个功能是最近变得越来越流行的 Swish 功能。
还有许多其他激活函数,每个函数都有独特的特性。但这些是最流行和用途最广泛的一些函数。(在此处阅读更多信息)
激活函数的妙处在于,它们可以根据我们的具体问题进行量身定制。例如,如果我们要预测连续的事物,如房价(回归问题),整流函数是一个很好的选择。它只给出正输出,与房价不为负的事实相吻合。但如果我们要估计概率,如房屋出售的可能性,那么 S 型函数就是我们的首选,其范围从 0 到 1,可以反映概率值。
让我们继续选择激活函数作为神经元中的整流函数,因为这似乎对我们的问题最有意义。
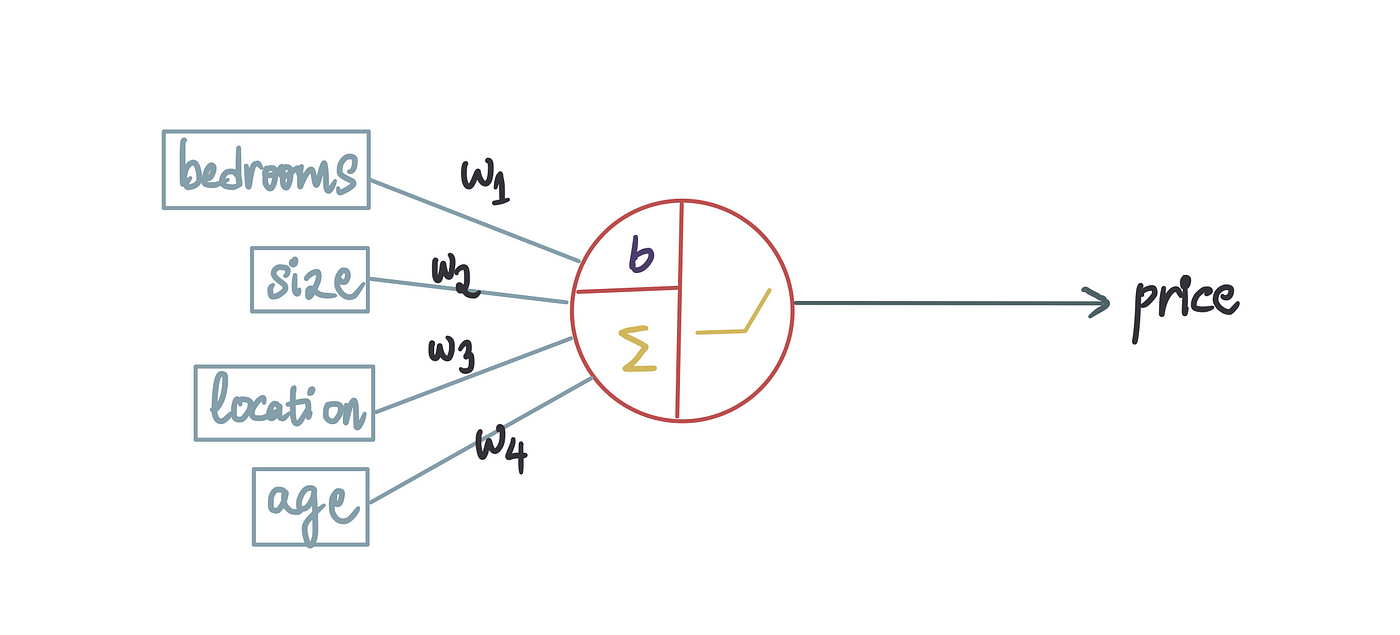
这被认为是一种神经网络模型(!),尽管是最简单的形式。它只包含 1 个神经元,但无论如何都是一个很好的起点。
接下来我们需要弄清楚的是权重和偏差项的值应该是多少。我们知道它们是常数项,但它们的值应该是多少?
还记得我们之前讨论过如何训练神经网络吗?这意味着要确定权重和偏差项的最佳值。稍后我们将详细介绍这种训练的具体过程。
现在,我们假设我们已经训练了神经网络并获得了最优值。因此,让我们用这些最优值替换这些项。
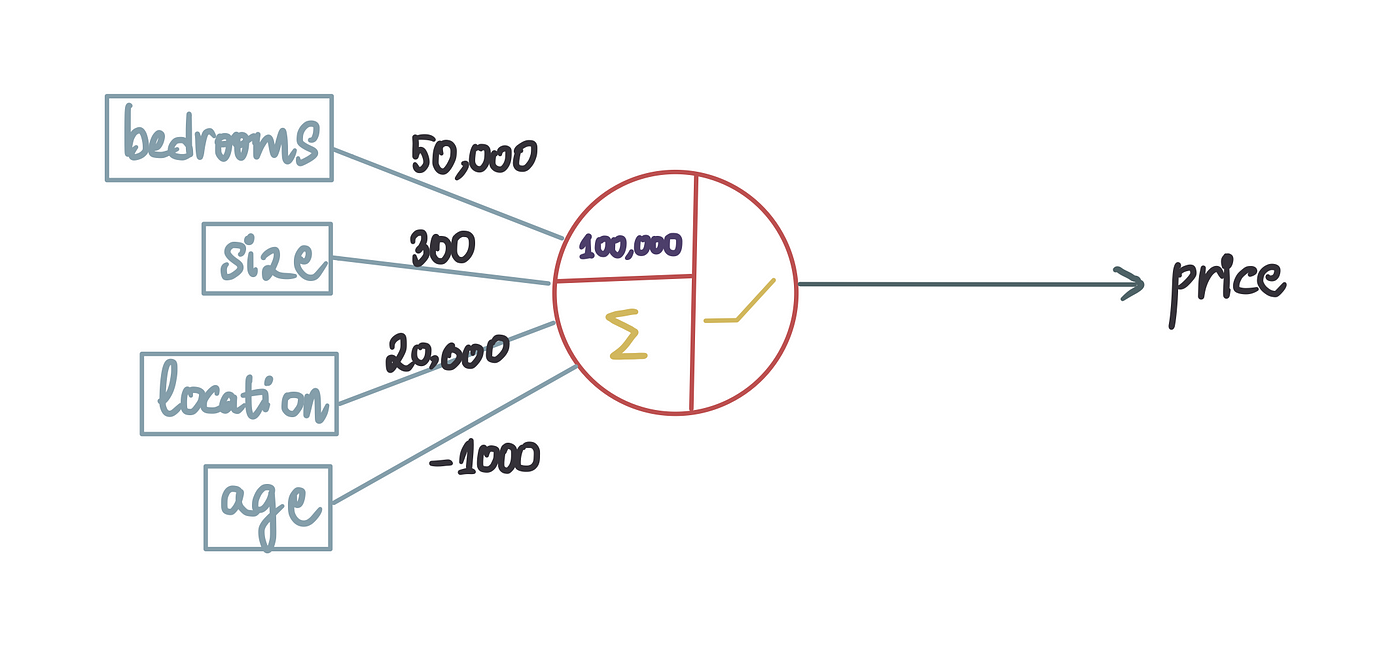
这就是我们所说的经过训练的、随时可以投入使用的神经网络。从本质上讲,这意味着我们利用现有数据,使用训练中的一个神经元创建了最有效的模型。现在,我们可以通过输入我们试图确定其价值的房屋的相关特征来预测房价。
让我们尝试预测训练数据集中第一套房子的价格。


当我们传入输入时,神奇的数据处理的第一部分是求和……
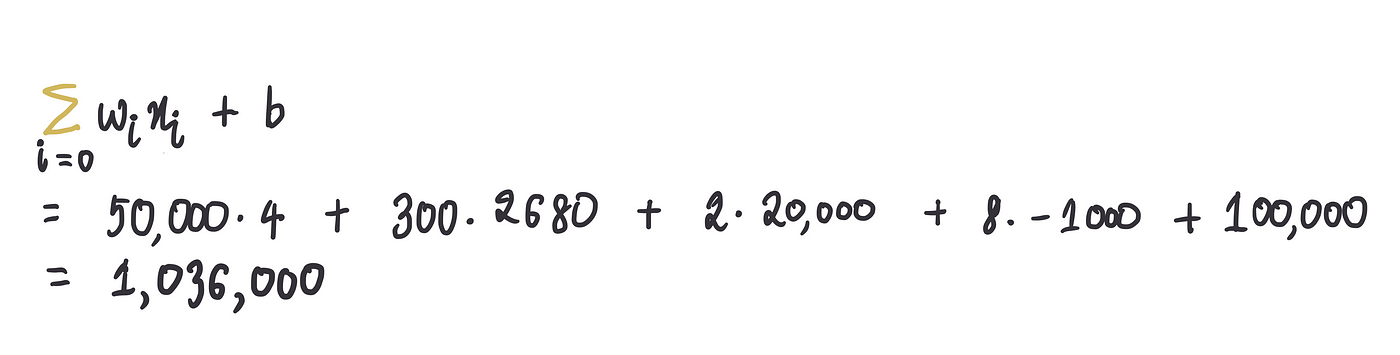
…第 2 部分是将这个总和值通过整流函数传递:
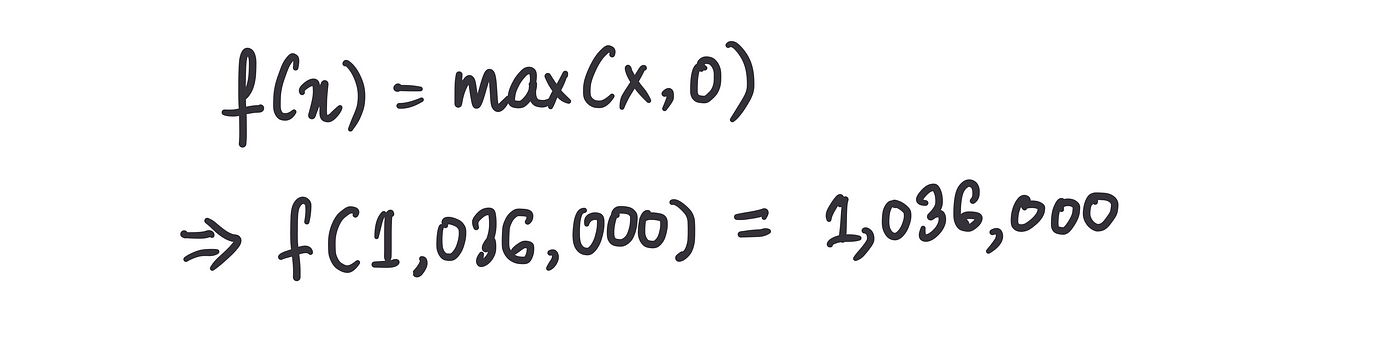
本质上,我们的模型将第一套房子的特征作为输入,并根据这些特征预测其价格为 1,036,000 美元。换句话说,它说:“考虑到这些房屋特征,我预测房屋价格为 1,036,000 美元。”
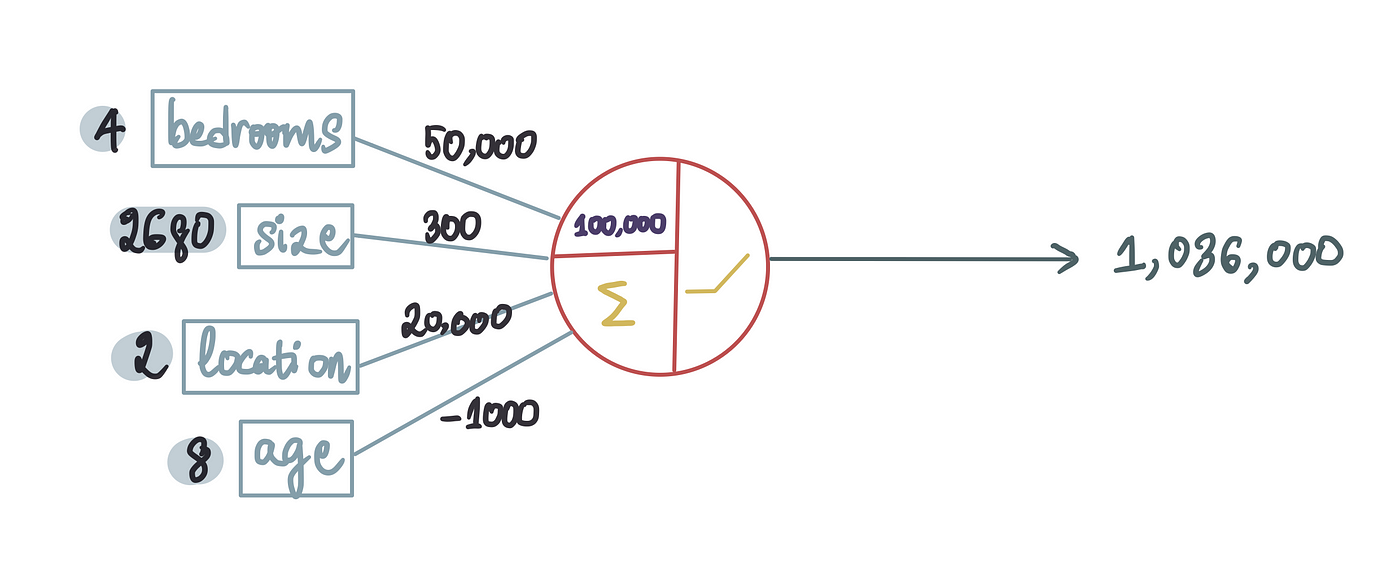
但当我们将其与实际房价进行比较时,不幸的是,175 万美元的预测结果并不理想。我们差了 714,000 美元。哎呀。
如果我们将剩下的房屋输入到这个简单的模型中,我们将获得以下预测价格:

我们可以看到,预测的价格都非常不准确。这表明我们的模型不是很有效,考虑到其不够复杂,这是可以理解的。它只由一个神经元组成。就像人类的大脑一样,只有当神经元协作时,它们才能做出更有影响力的决策并以更高的复杂度处理数据。
让我们退一步思考一下,是否有更直观的方法来解决这个问题。也许有一种方法可以通过考虑不同特征之间的相互作用来增强我们的预测。也许两个特征的组合比单独的单个特征更重要?
例如,卧室和面积的组合可能很有价值。较小的房子可能有很多房间,会让人感觉拥挤,从而降低对买家的吸引力,导致价格降低。同样,年龄和位置的组合也很重要。在城市地区,较新的房屋往往更贵,而在农村地区,买家可能更喜欢老房子的魅力,这可以提高它们的价值。农村地区的老房子也可能装修得更精致。此外,位置、面积和卧室的组合也很有趣。在郊区和农村地区,较小的房子有更多的卧室可能并不受欢迎。然而,在城市地区,人们更喜欢靠近城市工作,同时又有足够的空间供家人居住,只要有足够的卧室,他们可能愿意为较小的房子支付更多的钱。
可能性是无穷无尽的,考虑所有不同的组合非常具有挑战性。幸运的是,这正是我们利用多个神经元的力量的地方。与生物神经元协作做出更好决策的方式类似,人工神经元也会协同工作以实现同一目标。
让我们通过添加两个神经元来使我们的简单神经网络更加强大。这将创建一个类似蜘蛛网的结构:

在这种情况下,所有输入都被输入到 3 个神经元中的每一个。由于我们有输入进入 3 个神经元,并且我们知道每个输入都与一个权重相关联,因此总共会有 12 个(= 4 * 3)不同的权重。为了将它们分开,让我们引入一些符号。
权重用w_ij表示,其中i是神经元编号,j是输入。例如,这个突出显示的权重...
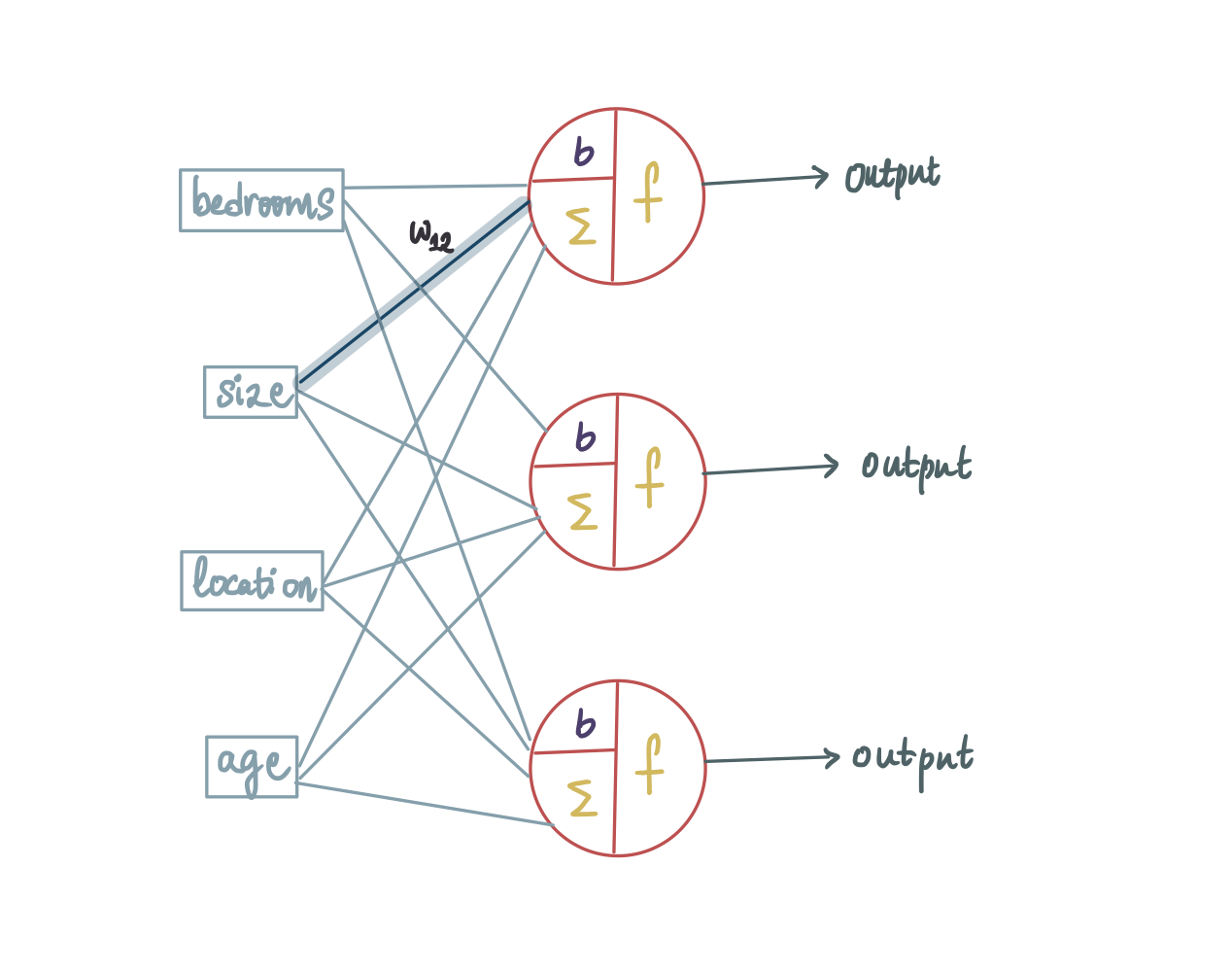
...标记为 w₁₂,因为它是第一个神经元的第二个输入。这个突出显示的输入...

…标记为 w₃₄,因为它是第 3 个神经元的第 4 个输入。同样,这是所有标记的权重:
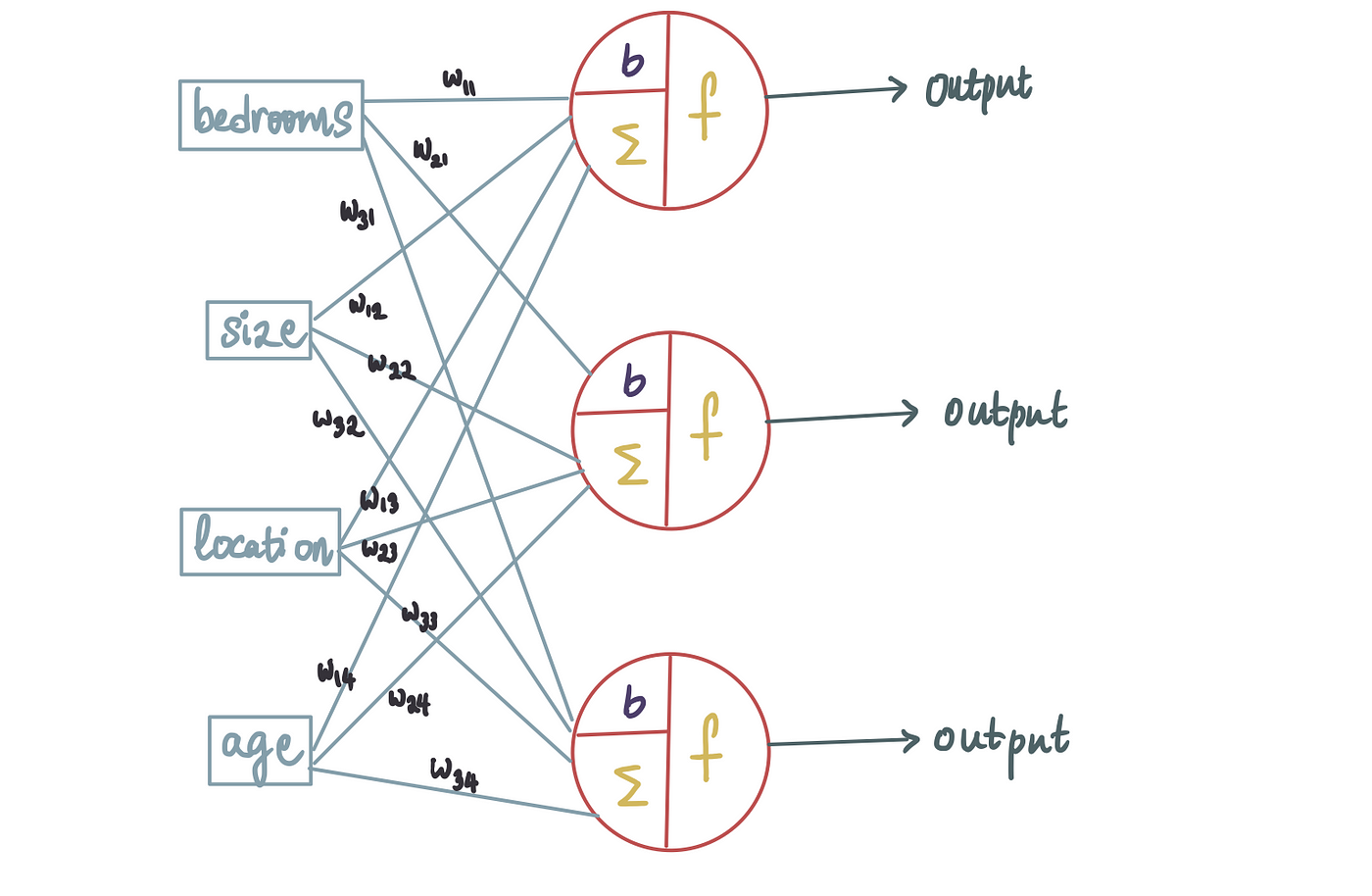
这些权重可以取任意值,在训练过程中确定。
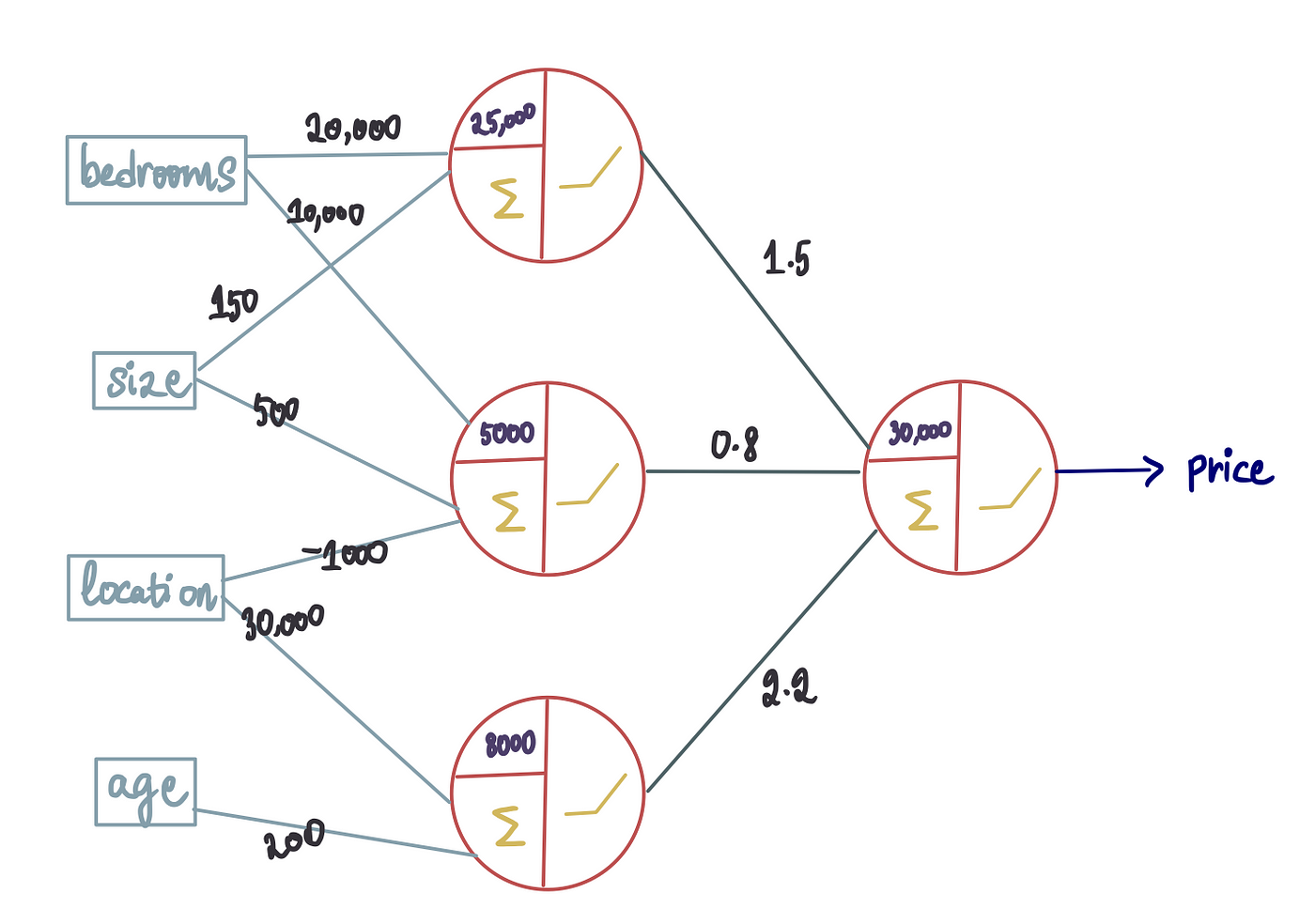
假设我们的神经网络训练过程确定只有卧室和尺寸特征与神经元 1 相关,而其他 2 个特征不予考虑,那么进入第一个神经元的位置和年龄的权重将为 0。类似地,假设只有卧室、尺寸和位置对第二个神经元很重要,而年龄被忽略,因此进入第二个神经元的年龄的权重为 0。同时,第三个神经元仅将位置和年龄视为重要特征,而卧室和尺寸的权重为 0。
最终的神经网络看起来将会像这样:

类似地,训练过程也会产生最佳偏差值。因此,让我们继续在这里添加它们(我们还删除权重 = 0 的输入,以使图表更具可读性):
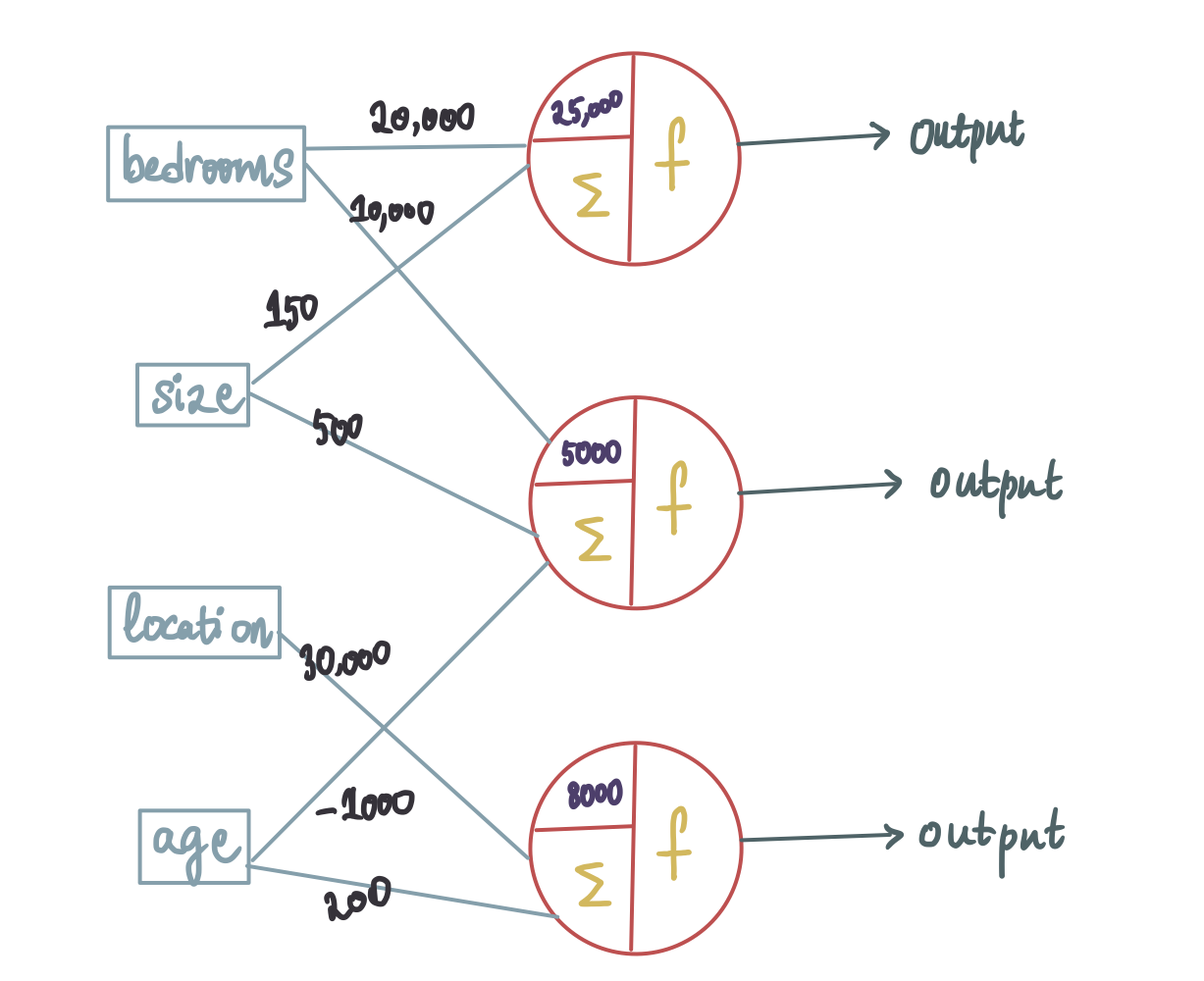
你可能注意到了一件奇怪的事情:这里有 3 个输出。但是,我们只想要一个输出,即预测价格。因此,我们需要找到一种方法将 3 个神经元的输出合并为一个。为此,让我们在前面添加另一个神经元。

结构与之前的相同,但不是将 4 个特征作为输入送入神经元,而是将之前神经元的输出用作新神经元的输入。
术语 segue:每一层都经过编号,输入层通常标记为 0。最后一层称为输出层,而位于输入层和输出层之间的任何层都被视为隐藏层。
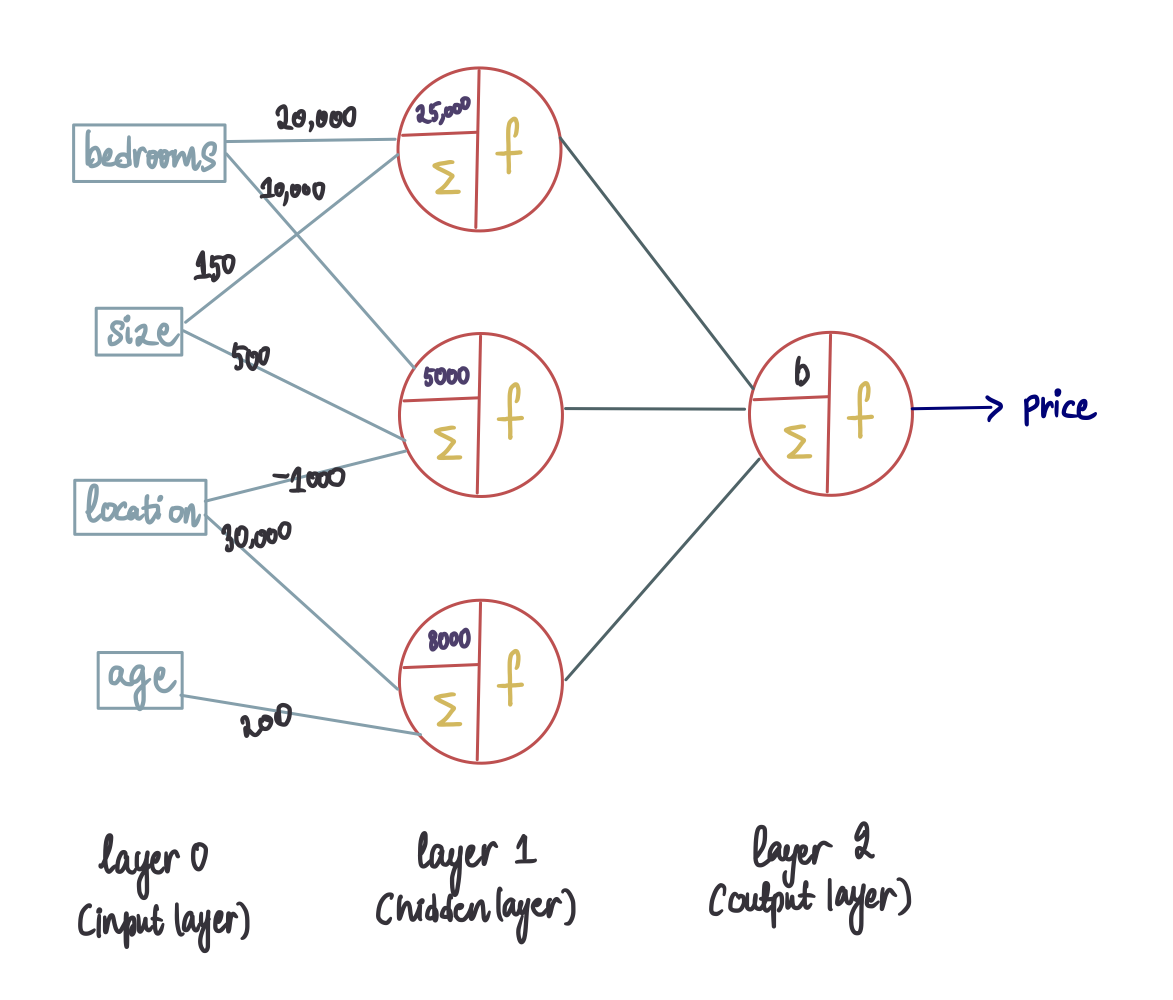
请记住,每个输入都伴随着相应的权重。因此,即使这些新神经元的输入也会有权重,这些权重也可以在训练过程中估算出来。新的偏差也将在训练过程中确定。因此,新的神经网络(假设它经过充分训练)将具有以下最佳值:
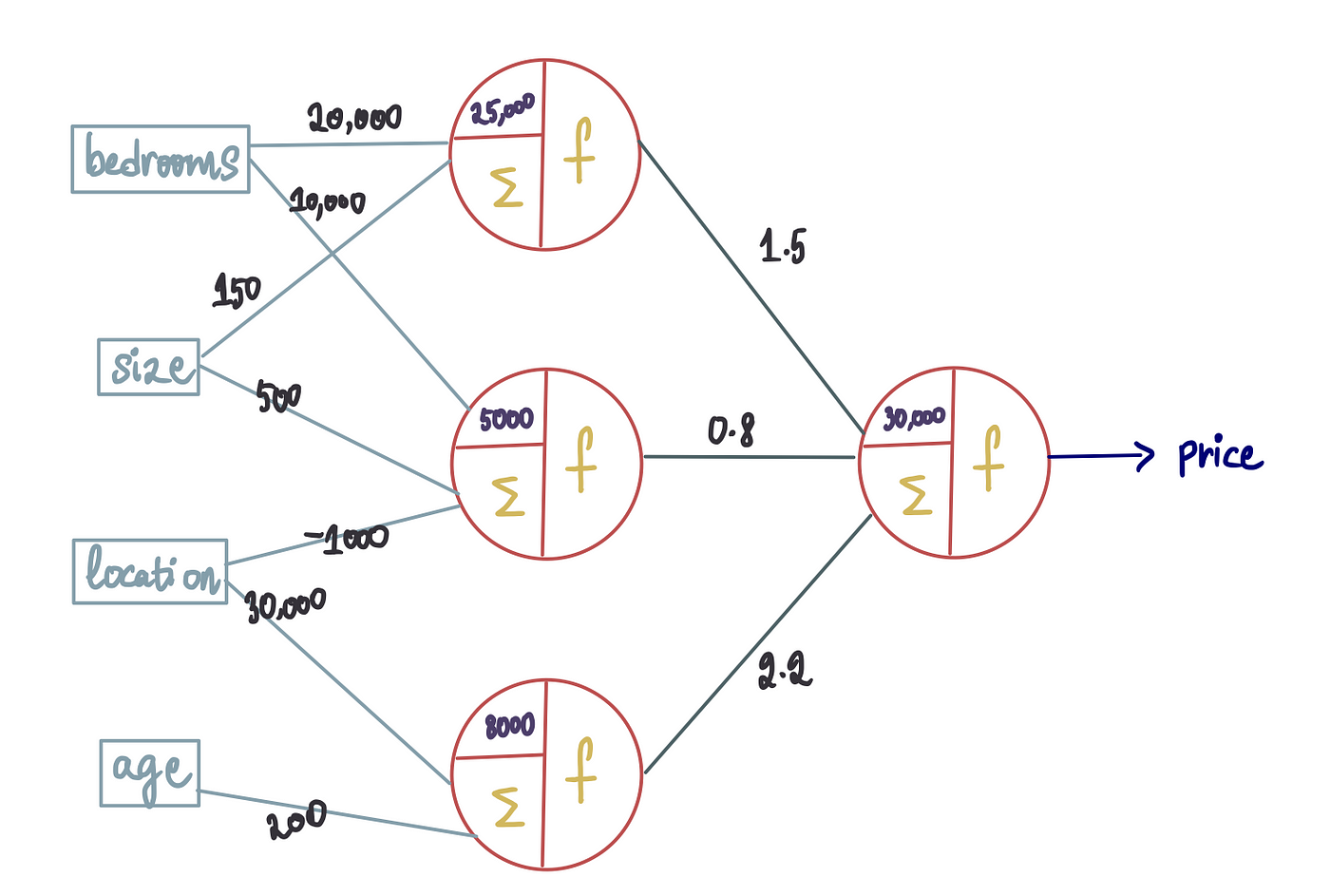
现在让我们讨论激活函数。在这种情况下,我们将所有激活函数设置为等于整流函数。通常,我们可以根据要解决的问题灵活地选择不同的激活函数。但是,由于整流函数是常用函数,我们现在就使用它。
注意:通常,同一层会具有相同的激活函数。
好的,终于到了有趣的部分。我们用所有最佳偏差和权重值训练了我们的神经网络。现在是时候试用一下这个宝贝,看看它在预测房价方面表现如何。
让我们再次将我们第一栋房子的特征传递到这个神经网络中。
我们将通过强调每个步骤中激活的输入和神经元来阐明该过程。

步骤 1 — 第一个神经元
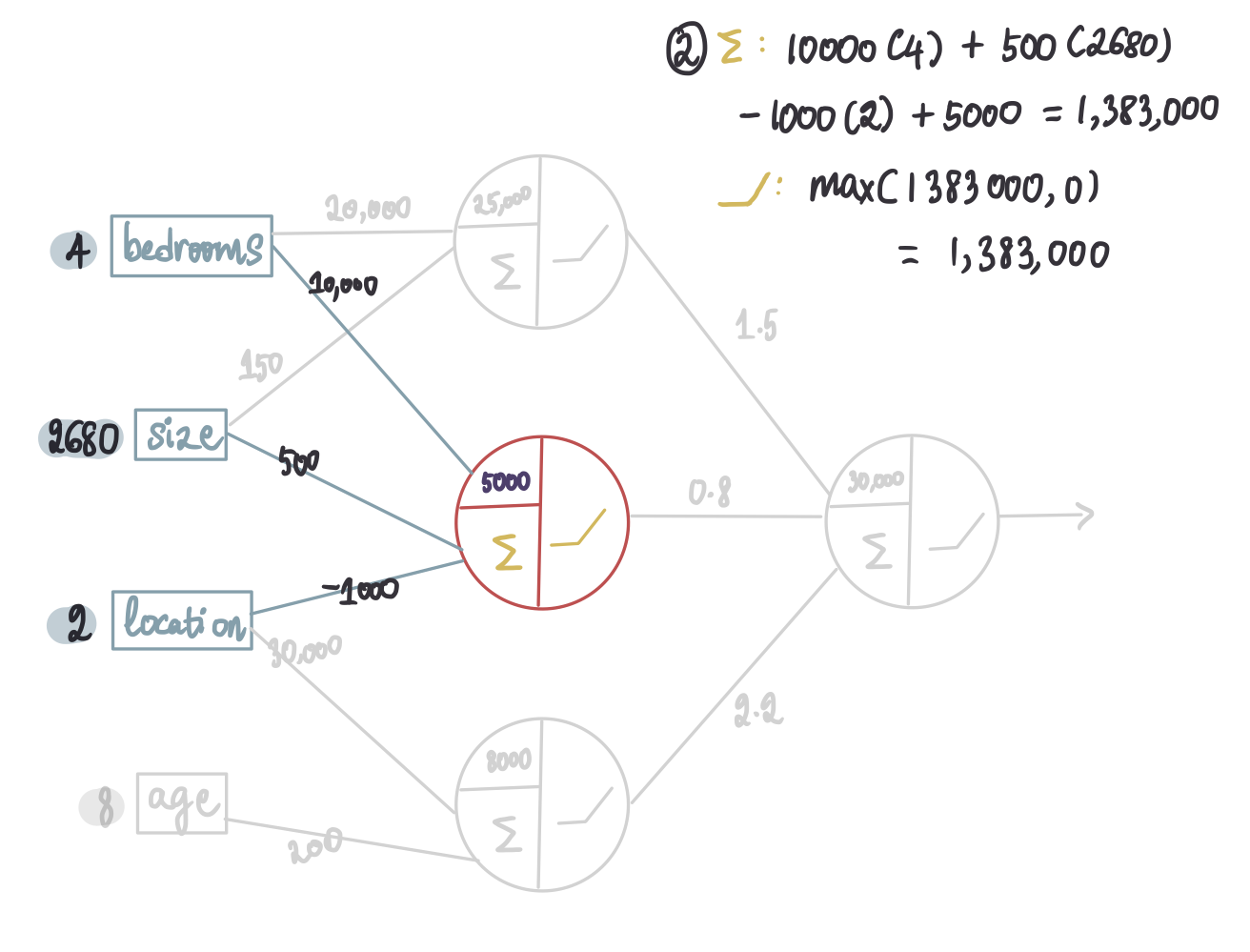
步骤 2 — 第二个神经元

步骤 3 — 第三个神经元
最后,使用隐藏层的输出并将它们传递到输出层:
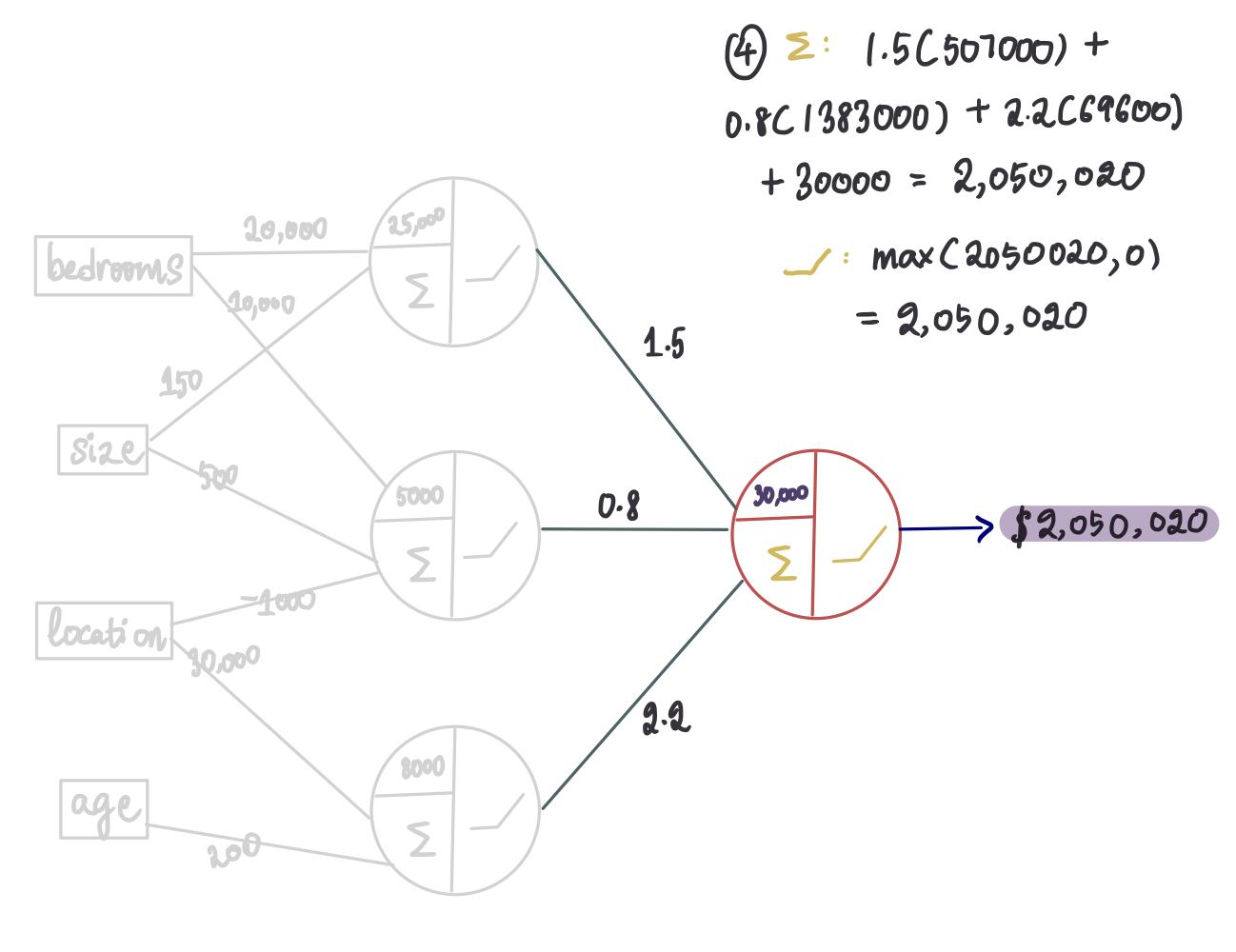
步骤 4 — 最终神经元
这就是我们使用神经网络获得输出的方法!传递输入以获得输出的过程称为前向传播。
我们将对其余房屋重复相同的过程:

让我们将这些新的预测价格与仅使用一个神经元的神经网络做出的旧预测价格进行比较。
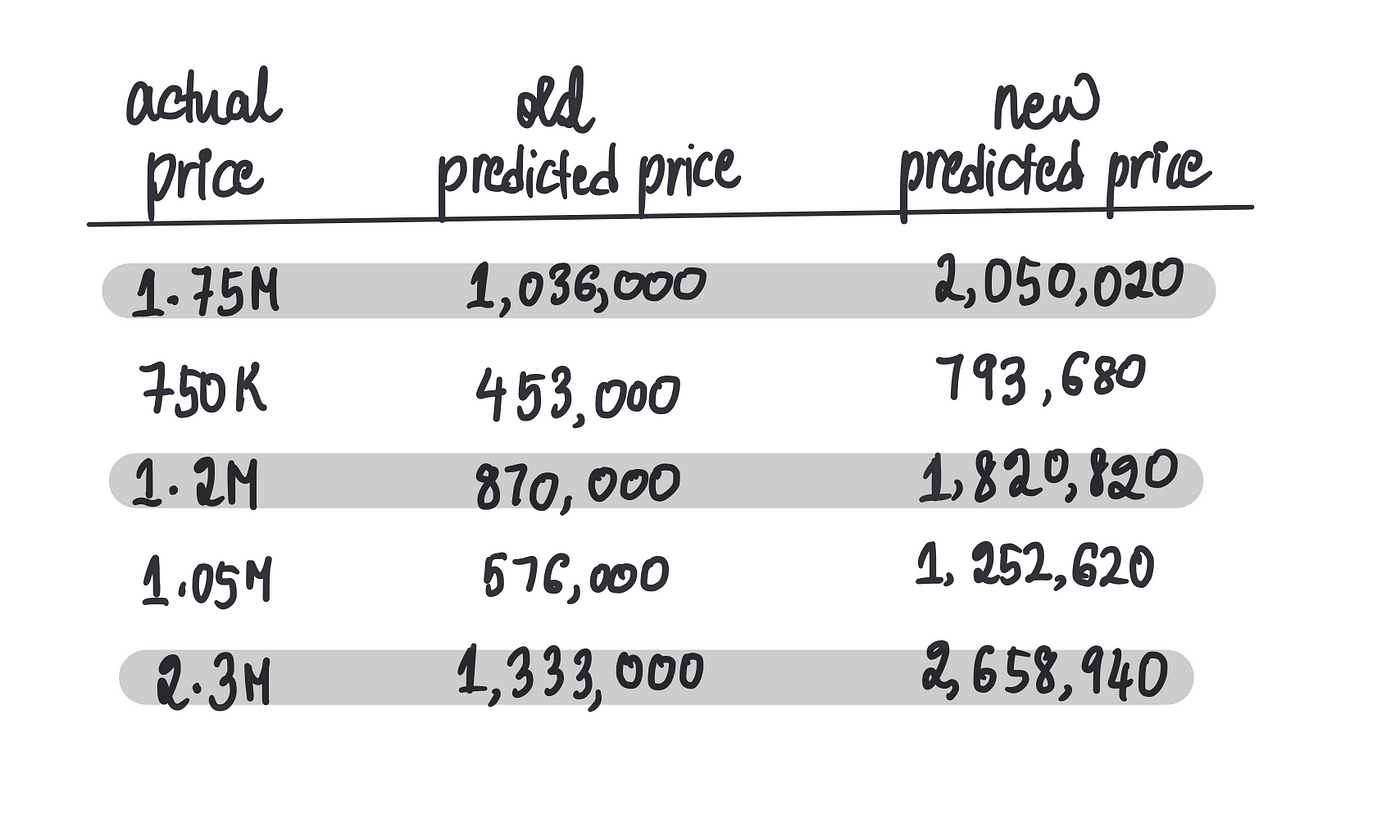
从肉眼观察,似乎新的预测结果比旧的预测结果更好。但是如果我们想找到一个数字来量化我们的预测与实际值的偏差,该怎么办?
这时成本函数就派上用场了。成本函数告诉我们预测结果与实际价格的偏差有多大。根据预测类型,我们可以使用不同的成本函数。但对于这个问题,我们将使用均方误差 (MSE) 函数。MSE 允许我们 a) 测量预测结果与实际价格的偏差,以及 b) 比较不同模型的预测结果。
它计算预测房价与实际房价之差的平方的平均值。从数学上来说:
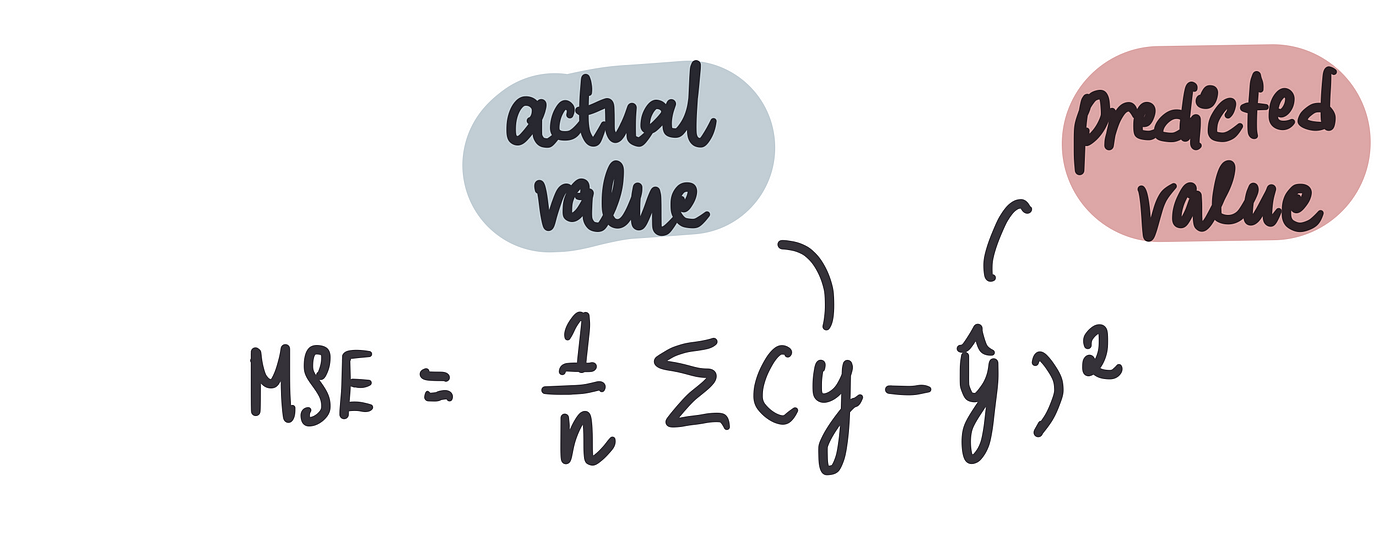
术语衔接:通常将实际价格表示为“y”,将预测价格表示为“y hat”(这样表示是因为“y”顶部的小符号看起来像一顶帽子)
目标是最小化 MSE。MSE 越接近 0,我们的模型预测价格的效果就越好。
因此,使用此公式,我们可以计算旧的单神经元模型的 MSE,如下所示:
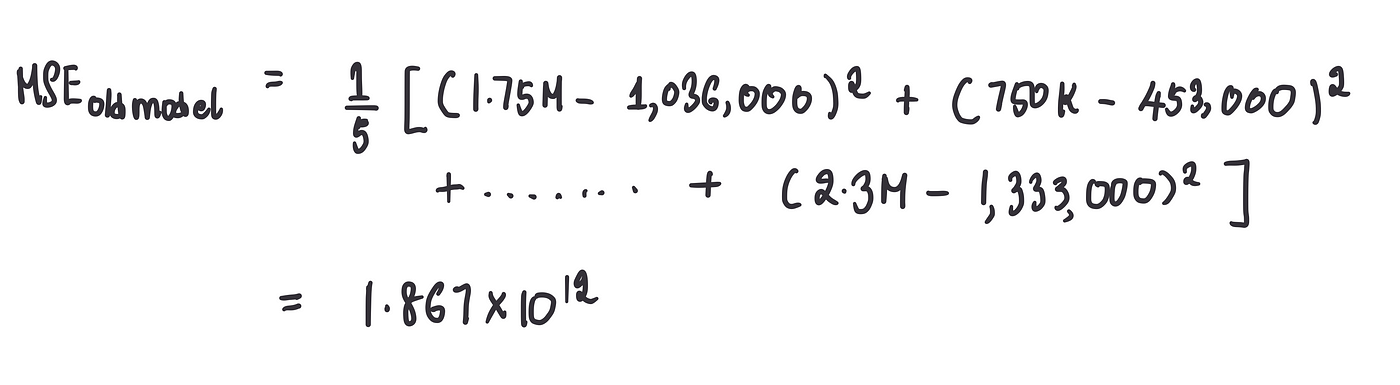
呃……这个数字太难看了。这只能证明我们的第一个模型非常糟糕(咳咳,太糟糕了)。
类似地,新的、更复杂的模型的 MSE:

仍然很糟糕,但至少比之前的 MSE 好一点。
但我们可以考虑创建一个更好的模型。
一种方法是在现有层中添加更多神经元,以提高预测能力。就像这样:
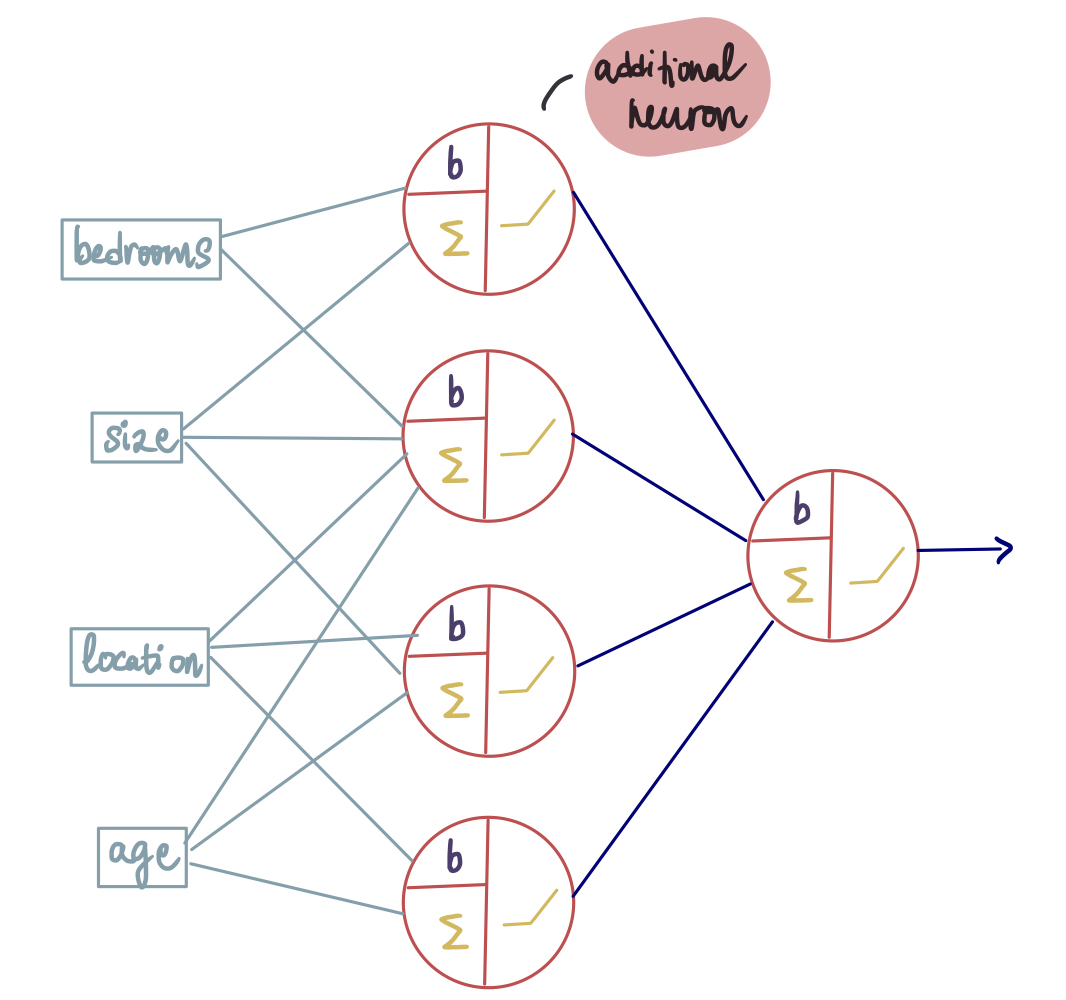
在隐藏层中添加了第四个神经元
或者我们可以添加一个全新的隐藏层:

增加了第二个隐藏层,有 3 个神经元
或者,我们可以在不同的层放置不同的激活函数:

如您所见,可能性是无穷无尽的。我们可以调整神经网络的复杂性以满足我们的特定需求。这些不同的可能性称为神经网络架构。我们可以自定义层数、每层的神经元和激活函数以适应我们试图解决的数据和问题,使其根据需要变得简单或复杂。
现在我们了解了神经网络的工作原理,下一篇文章(现在开始)将重点介绍如何学习最佳偏差和权重值,即训练过程!
感谢关注雲闪世界。(亚马逊aws和谷歌GCP服务协助解决云计算及产业相关解决方案)
订阅频道(https://t.me/awsgoogvps_Host)
TG交流群(t.me/awsgoogvpsHost)















 738
738











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









