







 本文介绍了Mueller-Muller算法,一种基于判决反馈的低复杂度定时误差检测方法,适用于单倍采样率。重点讲解了其工作原理、常见实现、敏感性分析以及选择样本数据的重要性。算法的公式(7)及其变体被详细讨论,以及为何滚降系数对精度的影响。
本文介绍了Mueller-Muller算法,一种基于判决反馈的低复杂度定时误差检测方法,适用于单倍采样率。重点讲解了其工作原理、常见实现、敏感性分析以及选择样本数据的重要性。算法的公式(7)及其变体被详细讨论,以及为何滚降系数对精度的影响。
1.Mueller-Muller 算法简介
Mueller-Muller 算法是一种非数据辅助,基于判决反馈,实现复杂度低,广泛应用于实际工程中的一种定时误差检测算法。Mueller-Muller 算法最大的特点是工作于单倍采样率下,每个码元仅需要一个采样点即可提取出定时误差。
2. Mueller - Muller 算法常见实现方式
Mueller-Muller 算法是单倍采样率下基于判决反馈的定时误差提取算法,所以,一般的实现方式如图1所示:
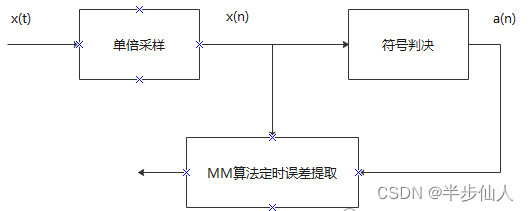
图示 1
假设采样数据判决为符号
,采样数据
判决为符号
,n表示第n时刻。则, Mueller-Muller 算法定时误差输出为:
(1)
其实现电路图如下图所示(最左边方框表示符号判决):
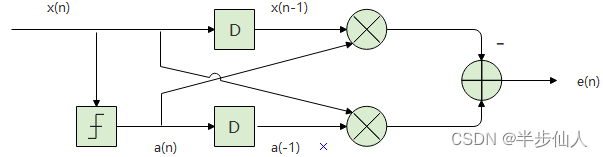
图示 2
根据Mueller论文的推导,也可以替换为
。此外,也可以将
替代为
。具体的使用方法需要结合工程实际情况来选择。
3. Mueller - Muller 算法原理
假设T为符号周期(单个码元持续时间), 表示输入码元符号,h(t)表示系统响应,则输入信号可以表示为:
(2)
令表示在(0,T]范围内的采样时刻,则在
时刻对x(t)的采样值为:
(3)
记 ,
,
。
则对(1)求期望:
(4)
其中,
(5)
因为数据是随机数,
是确定的数据,求期望实际是对
求期望。(5)式中不带噪声项,因为这里假设噪声均值为0。因为数据比特是互相独立的,所以有:
. (6)
上式中假设了数据是归一化数据。 所以
。同理,
。则有定时误差函数:
(7)
(7)式就是 Mueller-Muller算法的本质。(1)式是它的一种基于判决的近优实现方式。
4. 基于公式(7)的Mueller - Muller 算法的理解
公式(7)成立的一般前提是系统冲激响应偶对称。如图所示:
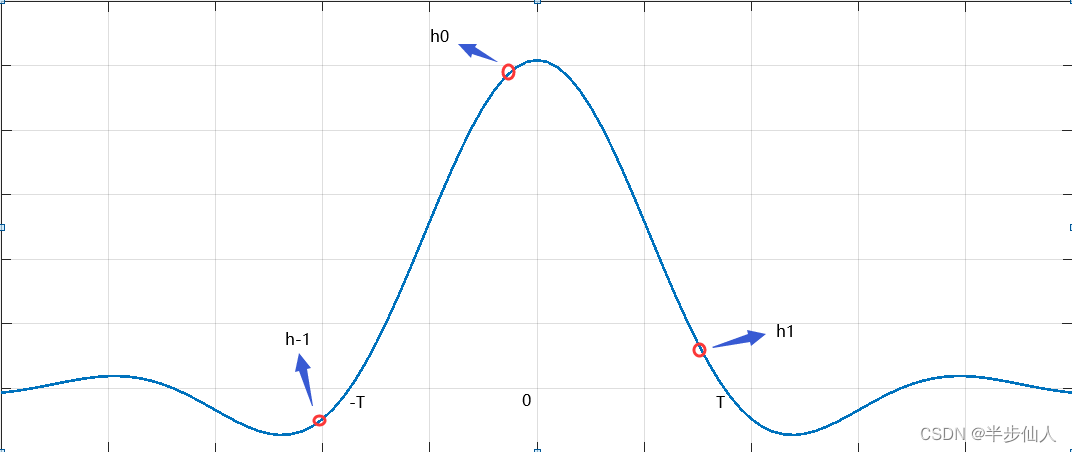
图 3
当 时,采样时刻超前于最佳采样时刻,当
时,采样时刻落后于最佳采样时刻,当时
,采样时刻为最佳采样时刻。此时的定时误差函数
为关于原点的奇函数。如下图所示:
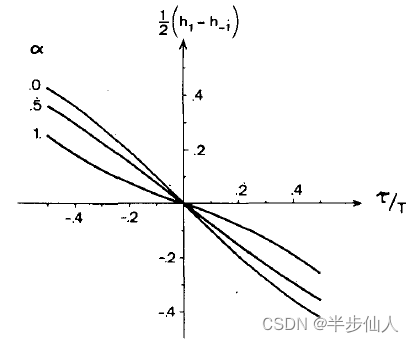
图4
图4中,分别展示了不同滚降系数(0,0.5,1.0)下的升余弦响应的误差函数曲线。随着滚降系数的减小,定时误差函数的斜度越大,定时误差越灵敏。有别于其他鉴相算法,Mueller-Muller 算法是滚降系数越小越好。
我们在第二小节提到,公式(1)是公式(7)的近优实现,公式(1)的期望就是公式(7),也就是平均意义上公式(1)和公式(7)相等。那么,公式(1)相对于公式(7)的偏离度是多少 呢?我们可以用公式(1)的方差来衡量。公式(1)的方差有:
(8)
从公式(8)可以看出,公式(1)的准确度取决于系统噪声、主抽头前后两个符号干扰、剩余符号间干扰以及系统符号调制方式。这是一个很矛盾的公式,鉴相结果受符号间干扰,又依靠前后两个符号的干扰。所以,一般鉴相和均衡会同时做,或者某一项启动后,立马启动另一项。
5. 一般的Mueller - Muller 算法
一般的Mueller - Muller定时误差提取公式为:
(9)
实现方式是:
(10)
其中,为i时刻接收样本。适当选取
,可以使公式(10)的期望为公式(9), 方差最小或接近最小。
根据Mueller的建议:
(1)系统响应为偶对称时,定时误差提取公式为公式(7);
(2)系统响应为奇对称时,定时误差提取公式为:
(11)
(3)系统相位失真比较严重时,定时误差公式为:
(12)
(4) 不建议使用更多项的来提取误差函数。因为在估计
时,如果对
判决错误,会导致误差传播,使得鉴相不准确。
此外,在不少论文中,还使用了其他的定时误差提取公式。
【参考资料】
[1] K. Mueller and M. Muller, Timing Recovery in Digital Synchronous Data Receivers, IEEE Transactions on Communications, vol. COM-24, no. 5, pp. 516-531, May 1976.
[2] Mueller and Muller Timing Synchronization Algorithm - Wireless Pi
思考题:
1. 为什么Mueller - Muller算法对相位噪声更敏感?
2.样本数据从何处取比较合适?
3. 为什么可以将 替换为
?

















 785
785

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









