







题目
Deep Biaffine Attention for Neural Dependency Parsing
论文:https://arxiv.org/pdf/1611.01734.pdf
代码:https://github.com/tdozat/Parser-v1
https://github.com/bamtercelboo/PyTorch_Biaffine_Dependency_Parsing
作者
Timothy Dozat
Stanford University 斯坦福大学
Christopher D. Manning
Stanford University 斯坦福大学
摘要
主是是研究依存句法分析方法。
解决基于图的依存句法分析两个问题:
1、哪两个节点连依存弧;
2、弧的标签是什么;
提出了biaffifine classififiers去预测arcs及它的labels;
模型
提出的模型是基于论文【3】【4】【5】进行的修改。
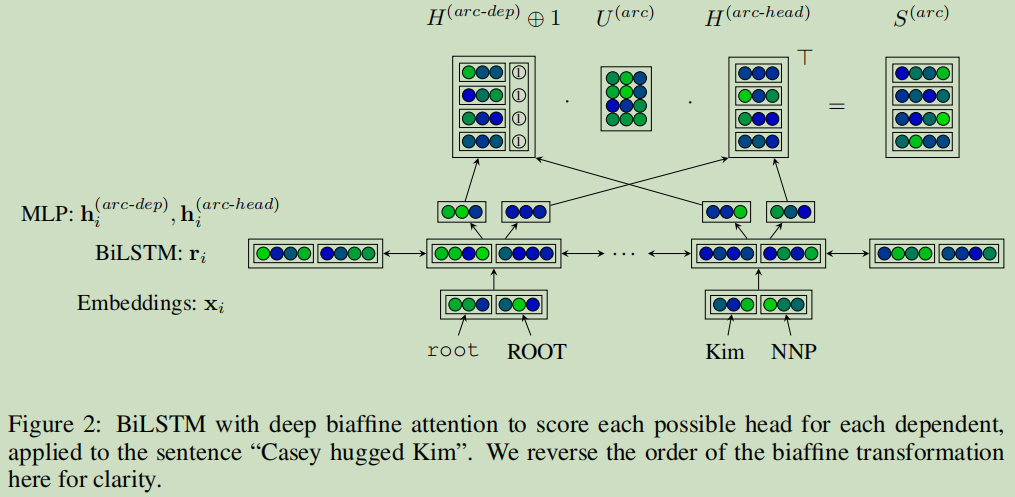
第一点,模型使用了biaffine attention,而不是bilinear 或 传统的基于MLP attetion;
第二点,使用了biaffifine依赖标签分类器;
第三点,在应用Biaffine变换之前,我们将降维MLP应用于每个递归输出向量r_i;
从上图可以看出输入为词与词性向量拼接后的向量;经过bi-LSTM获得r_i; r_i经过两个MLPs,计算得到两隐变量h_arc-dep,h_arc-head; 最后一层h_arc-head还拼接了一个单位向量,利用U进行仿射变换,最后得到S,即arc分数矩阵,具体的公式理解如下:
biaffine并不是双线性(bilinear)或MLP机制,它使用一个仿射变换在单个LSTM输出状态r预测所有类别上的得分,提出的双仿射注意力机制(Biaffine Attention)可以看成为传统的仿射分类器:

基于上式改进为:
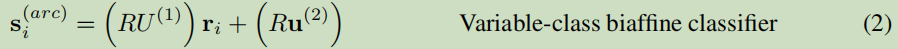
W采用多层LSTM堆叠计算后的结果,维度变为(d x d),b参数数也变成(d x 1)的向量;
由于句子中的词数是不定的,可是又要给每个词一个分数,这是一个不定类别分分类问题,上式(1)显然是满足不了,本文采用了两个MPLs来解决这个问题,把式(4)式(5)代入式(2)就得到最终的式(6):
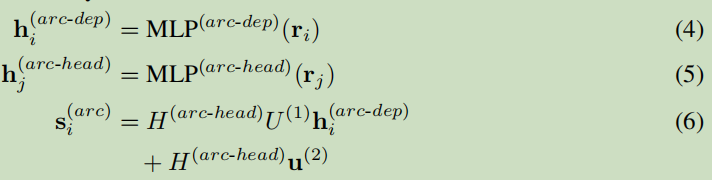
它的作用是使数据进行降维输出处理,可以对LSTM进行降维,然后输入到仿射层,避免过拟合。
双仿射分类器使用双线性层,比传统使用两层线性层和一个非线性激活单元的MLP网络更简单。同时,arc双仿射分离器对两种概率直接建模:
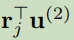 ,结点j接受任意依赖的先验概率;
,结点j接受任意依赖的先验概率;
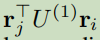 ,结点j接受单词i依赖的概率;
,结点j接受单词i依赖的概率;
使用另一个label双仿射分类器预测单词与其头结点间的依赖标签:
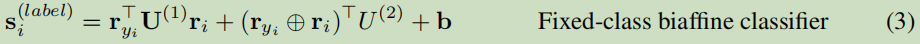
U的维度为mxdxd的高维张量(m是标签个数,d是biaffine的输入维度);
arc分类器是不定类别分类器,类别数与序列长度有关,label分类器是固定类别分类器,类别数等于所有可能的依存关系数。
实验
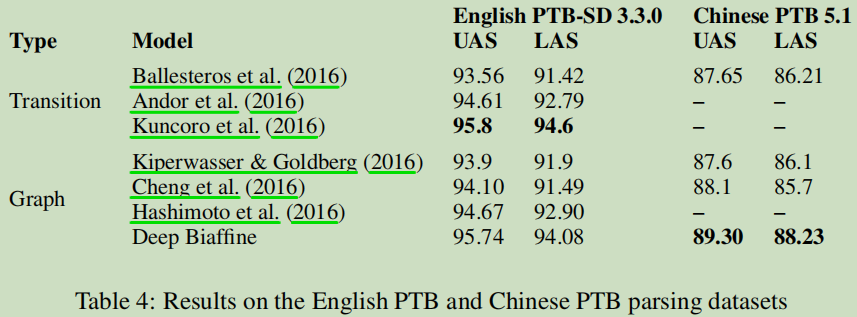
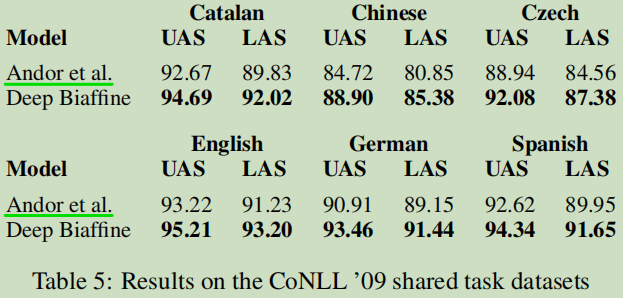
总结
相关知识点
引用【2】的一段话来补充一下对句法分析相关概念的理解:
句法分析(syntactic parsing)是NLP中的关键技术之一,通过对输入的文本句子进行分析获取其句法结构。句法分析通常包括三种:
(1)句法结构分析(syntactic structure parsing),又称短语结构分析(phrase structure parsing)、成分句法分析(constituent syntactic parsing)。作用是识别出句子中的短语结构以及短语之间的层次句法关系。
(2)依存关系分析,又称依存句法分析(dependency syntactic parsing),简称依存分析(denpendency parsing),作用是识别句子中词与词之间的相互依存关系。
(3)深层文法句法分析,即利用深层文法,例如词汇化树邻接文法(Lexicalized Tree Adjoining Grammar, LTAG)、词汇功能文法(Lexical Functional Grammar,LFG)、组合范畴文法(Combinatory Categorial Grammar,CCG)等, 对句子进行深层的句法以及语义分析。
Dependency Parsing 主要有两种方法:Transition-based 和 Graph-based。
例如句子“他给我一台美丽的高性多CPU电脑。”,通过LTP进行句法分析,句法分析结果:
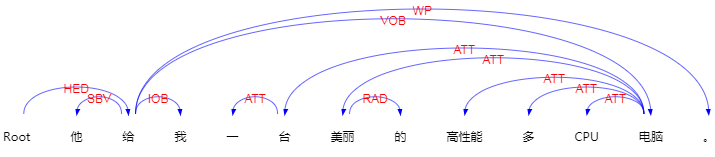
语义依赖结果:
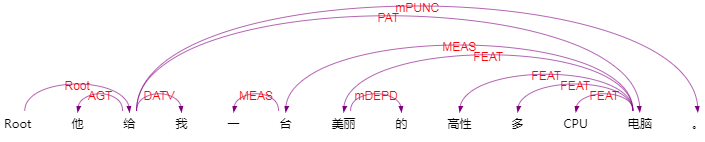
可以按照这个箭头建成一棵依存树。
相关技术
Transition-based
Chen & Manning (2014) 第一次把神经网络引入到Transition-based中去。—陈丹奇的这篇有有影响力( A fast and accurate dependency parser using neural
networks);
接下来,Weiss et al. (2015),Andor et al. (2016) ,使用beam search与条件随场损伯目标去做讨论这个话题;
接着,Dyer et al. (2015) ,(Kuncoro et al., 2016) ,通过建立句法结构分析的方法而不采用LSTM的方法去处理;
Transition-based parsing方法不可以使用机器学习直接预测边,而只是去预测transition算法的操作。
Graph-based
可以对某些边赋予概率或权重,然后构建maximum spaning tree (MST) ;
Kiperwasser & Goldberg (2016)提出neural graph-based parser;
Hashimoto et al. (2016)在多任务中包含了graph-based dependency parser;
Cheng et al. (2016)提出graph-based neural dependency parser;
参考
【1】Deep Biaffine Attention for Neural Dependency Parsing,http://www.hankcs.com/nlp/parsing/deep-biaffine-attention-for-neural-dependency-parsing.html
【2】Deep Biaffine Attention for Dependency Parsing,https://zhuanlan.zhihu.com/p/71553871
【3】Eliyahu Kiperwasser and Yoav Goldberg. Simple and accurate dependency parsing using bidirectional LSTM feature representations. *Transactions of the Association for Computational Linguistics, 4:313–327, 2016.
【4】Kazuma Hashimoto, Caiming Xiong, Yoshimasa Tsuruoka, and Richard Socher. A joint many-task model: Growing a neural network for multiple nlp tasks. arXiv preprint arXiv:1611.01587, 2016.
【5】 Hao Cheng, Hao Fang, Xiaodong He, Jianfeng Gao, and Li Deng. Bi-directional attention with agreement for dependency parsing. arXiv preprint arXiv:1608.02076, 2016.
happyprince.https://blog.csdn.net/ld326/article/details/115012759














 287
287











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}