







1.环境
jdk1.8
elasticsearch-7.5.2(这是JDK8能支持的最高版本)
2.数据准备
批量上传数据,将自动新建索引库movie,指定索引id和字段title(内容为电影名称)。
PUT _bulk
{ "index" : { "_index" : "movie", "_id" : "1" } }
{ "title": "Gone with the wind" }
{ "index" : { "_index" : "movie", "_id" : "2" } }
{ "title": "Titanic" }
{ "index" : { "_index" : "movie", "_id" : "3" } }
{ "title": "Forrest Gump" }
{ "index" : { "_index" : "movie", "_id" : "4" } }
{ "title": "The Wizard of Oz" }3.搜索评分分析
搜索标题包含The的电影,语句如下
post /movie/_search
{
"query":{
"match":{
"title":"The"
}
}
}搜索结果如下:
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 0.58446556,
"hits" : [
{
"_index" : "movie",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.58446556,
"_source" : {
"title" : "Gone with the wind"
}
},
{
"_index" : "movie",
"_type" : "_doc",
"_id" : "4",
"_score" : 0.58446556,
"_source" : {
"title" : "The Wizard of Oz"
}
}
]
}
}
从上面我们可以看到最高评分(max_score)为0.58446556,其中内容有2条,分别为Gone with the wind(ID为1)、The Wizard of Oz(ID为4),它们的评分一样都是0.58446556,这是为什么呢?
ES 5.0 之前,默认的相关性算分采用的是 TF-IDF,而之后则默认采用 BM25。BM25的算法公式如下,es7.5.2中的评分理论就是来源于此。(下面公式先简单了解下,看不懂没关系)
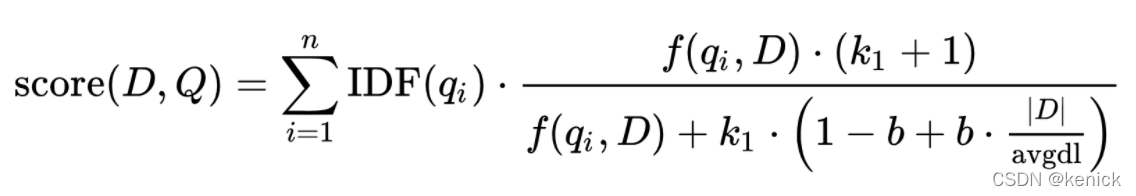
使用下面语句分析,搜索电影标题中包含The的结果时,为什么ID为1的评分为0.58446556?
POST /movie/_explain/1
{
"query":{
"match":{
"title":"The"
}
}
}结果如下,explanation中的value(0.58446556)就是评分计算结果,它的值为 boost * idf * tf。
{
"_index" : "movie",
"_type" : "_doc",
"_id" : "1",
"matched" : true,
"explanation" : {
"value" : 0.58446556,
"description" : "weight(title:the in 0) [PerFieldSimilarity], result of:",
"details" : [
{
"value" : 0.58446556,
"description" : "score(freq=1.0), product of:",
"details" : [
{
"value" : 2.2,
"description" : "boost",
"details" : [ ]
},
{
"value" : 0.6931472,
"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details" : [
{
"value" : 2,
"description" : "n, number of documents containing term",
"details" : [ ]
},
{
"value" : 4,
"description" : "N, total number of documents with field",
"details" : [ ]
}
]
},
{
"value" : 0.38327524,
"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details" : [
{
"value" : 1.0,
"description" : "freq, occurrences of term within document",
"details" : [ ]
},
{
"value" : 1.2,
"description" : "k1, term saturation parameter",
"details" : [ ]
},
{
"value" : 0.75,
"description" : "b, length normalization parameter",
"details" : [ ]
},
{
"value" : 4.0,
"description" : "dl, length of field",
"details" : [ ]
},
{
"value" : 2.75,
"description" : "avgdl, average length of field",
"details" : [ ]
}
]
}
]
}
]
}
}
其中boost为权重因子,它受es默认值和查询boost影响,当查询时未指定boost时,查询时boost值为1,评分时的boost为1*默认boost值(2.2,这个值暂时还不清楚是如何计算出来的),如果查询时指定boost为3,这时计算时boost值将为 3 * 2.2 = 6.6。查询时boost详细信息请参看官网查询时权重提升 | Elasticsearch: 权威指南 | Elastic。
idf的计算为 log(1 + (N - n + 0.5) / (n + 0.5)),其中N为文档中带有title字段的数量(文档中可以不带title),在这里为所有文档数量4;n为带有当前查询关键字的文档数量,这里为2;idf = log(1+(4-2+0.5)/(2+0.5))=0.69314718055994530941723212145818(注意这里的log对数计算未指定底数,其实用的就是e,在计算器上为In)。
tf的计算为 freq / (freq + k1 * (1 - b + b * dl / avgdl)),详细解读如下:
freq: 关键字在当前文档中出现的次数,就是The 在文档1(Gone with the wind)中出现的次数,这里为1;
k1:饱和值(控制非线性词频率归一化),这里为默认1.2,可进行调节(除非你非常清楚该字段含义和影响,以及你的业务使用情况,否则不建议调节);
b:控制文档长度对于分数的惩罚力度,这里默认为0.75,如果b较大,则文档长度相对于平均长度的影响更大,可进行调节(根据业务和数据整体情况进行优化)。
dl:字段长度,Elasticsearch中字段长度的实现是基于Term数量的(而不是字符长度之类的),这里可以简单理解为单词数量(4个)。
avgdl:平均字段长度,所有字段长度/文档数量,这里为所有单词数量/4=11/4=2.75。
tf的计算结果为 freq / (freq + k1 * (1 - b + b * dl / avgdl)) = 1 / (1 + 1.2 * ( 1 - 0.75 + 0.75*4/2.75)) = 0.38327526132404181184668989547038(后半部分有点误差,这跟除不尽四舍五入有关)。
最终的score计算为: boost * idf * tf = 2.2 * 0.6931472 * 0.38327524 = 0.5844655507577216。
4.算法调节
4.1 指定字段的相似性算法
对于一些不需要分词和全文搜索的字段(如图片路径、热门元素、手机号码等),可以指定字段的相似性算法(如简单的boolean算法),不需要使用默认的BM25算法,存储索引和在这些字段上搜索将更快。
delete movie
PUT /movie
PUT /movie/_mapping
{
"properties": {
"title": {
"type": "text",
"similarity": "boolean"
}
}
}在不做任何配置,默认的情况下我们可以使用以下三种相似度评分算法:
- BM25:Okapi BM 25算法。在Elasticearch和Lucene中默认使用的算法。
- classic: 在7.0.0中标记为过时。基于TF/IDF 算法,以前在Elasticearch和Lucene中的默认值。
- boolean:一个简单的布尔相似度算法,当不需要全文排序时可以使用,并且分数应该只基于查询项是否匹配。布尔相似度给查询一个简单的分数,等价于设置的Query Boost。
关于相似性算法对于存储索引时的空间(硬盘和内存)占用测试(对比默认BM25和boolean)。
默认BM25算法测试,执行下面代码,不要进行任何的搜索(搜索会导致底层部分缓存,增加内存占用)。
delete movie
PUT _bulk
{ "index" : { "_index" : "movie", "_id" : "1" } }
{ "title": "Gone with the wind" }
{ "index" : { "_index" : "movie", "_id" : "2" } }
{ "title": "Titanic" }
{ "index" : { "_index" : "movie", "_id" : "3" } }
{ "title": "Forrest Gump" }
{ "index" : { "_index" : "movie", "_id" : "4" } }
{ "title": "The Wizard of Oz" }执行下面代码,可以看到后面的结果,movie索引库被分配到了两个节点上(一主一备),docs.count都是4(数据条目),segment大小为3.5kb,segment内存为1270byte。
get /_cat/segments/movie?v
index shard prirep ip segment generation docs.count docs.deleted size size.memory committed searchable version compound
movie 0 p 172.18.xx.xx _0 0 4 0 3.5kb 1270 false true 8.3.0 true
movie 0 r 172.18.xx.xx _0 0 4 0 3.5kb 1270 true true 8.3.0 true
执行下面代码找到movie索引库的uuid, 从下图中可以看到uuid为LmVeHIe3Q_GWyMIOrS2EHA。
get /movie
{
"movie" : {
"aliases" : { },
"mappings" : {
"properties" : {
"title" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
},
"settings" : {
"index" : {
"creation_date" : "1640744371924",
"number_of_shards" : "1",
"number_of_replicas" : "1",
"uuid" : "LmVeHIe3Q_GWyMIOrS2EHA",
"version" : {
"created" : "7050299"
},
"provided_name" : "movie"
}
}
}
}执行下面命令,可以看到movie分片占用硬盘空间为3763byte(3.9kb,无数据时为230b)。
GET _cat/shards/movie?v
index shard prirep state docs store ip node
movie 0 p STARTED 4 3.9kb 172.18.xx.xx node-3
movie 0 r STARTED 4 3.9kb 172.18.xx.xx node-6到es movie所在节点的机器上,找到es数据存储目录,找到索引库的物理存储路径:/home/elk/es/cluster/data/nodes/0/indices/LmVeHIe3Q_GWyMIOrS2EHA/0/index。执行du命令,可以看到该索引库占硬盘大小约为20kb(有些是索引库的固定占用,跟数据无关)。
[root@iZwz982lz6444cwmn40t61Z index]# pwd
/home/elk/es/cluster/data/nodes/0/indices/LmVeHIe3Q_GWyMIOrS2EHA/0/index
[root@iZwz982lz6444cwmn40t61Z index]# du -h --max-depth=1 .
20K .汇总一下,BM25算法下4条数据(批量执行的json大小,约253byte),es的segment size为3.5KB,硬盘大小(es记录为3763byte,实际占用20kb),内存约为1270byte(段内存大小)。
boolean算法,执行下面代码,指定相似度算法为similarity,并批量添加相同数据。
delete movie
PUT /movie
PUT /movie/_mapping
{
"properties": {
"title": {
"type": "text",
"similarity": "boolean"
}
}
}
PUT _bulk
{ "index" : { "_index" : "movie", "_id" : "1" } }
{ "title": "Gone with the wind" }
{ "index" : { "_index" : "movie", "_id" : "2" } }
{ "title": "Titanic" }
{ "index" : { "_index" : "movie", "_id" : "3" } }
{ "title": "Forrest Gump" }
{ "index" : { "_index" : "movie", "_id" : "4" } }
{ "title": "The Wizard of Oz" }使用相同统计方法,得到es的segment size为3KB,硬盘大小(es记录为3046byte,实际占用20kb),内存约为1014byte(段内存大小)。
对比使用不同相似度算法的数据,可以发现BM25算法下,索引的segment的大小比boolean算法大了3.5-3.0=0.5kb=512byte,硬盘大小大了3763-3046=717byte,内存大小大了1270-1014=256byte,而实际数据大小还不到253byte。按照4万条数据来估算,使用BM25算法一个字段就比boolean硬盘大了6.83MB,内存大了2.44MB,按照10个字段(观察实际生产环境,在没优化前大约有30个字段)来算则是68.3/24.4MB,再按照一主一备来算,则为136.6/48.8MB;反过来理解,在优化不必要字段的相似度算法后,数据越大、节点越多,节省的硬盘、内存空间越多,搜索速度自然会更快。
4.2 BM25算法调节
关于BM25算法理论,可参考



















 2026
2026

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











