







最近学习了点python爬虫,现在写一个实战演示记录一下学习历程!
我开发Python用的IDE是JetBrains公司的PyCharm,该IDE非常方便实用。
第一步:直接复制想要爬取的网页的源代码下来放到python的工程目录下的source.ext文件。
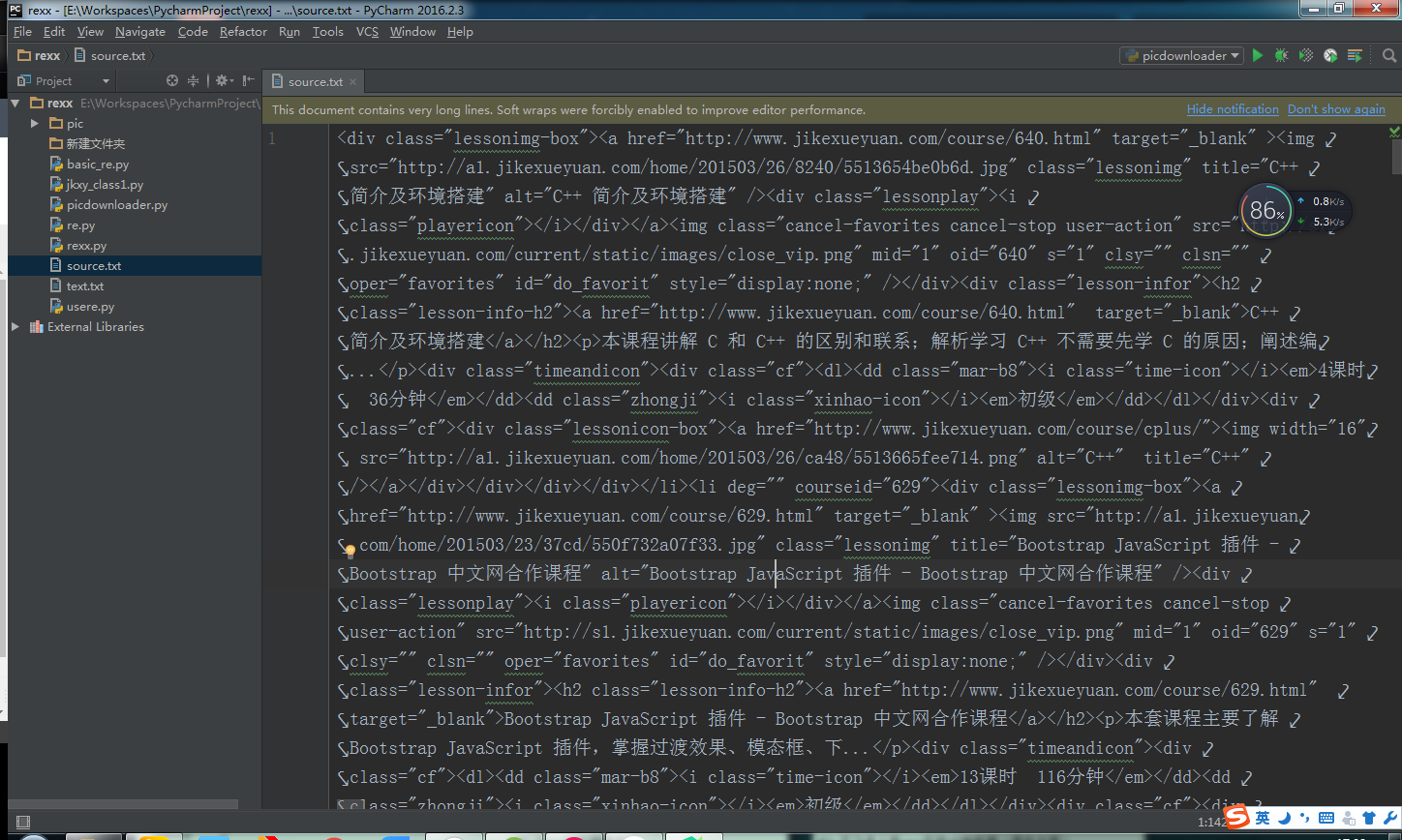
第二步:分析所要爬取得内容
由于想要爬取得内容是图片,所以仔细看源码,可以看到如下:

那么正则表达式为:’img src=”(.*?)” class=”lessonimg”’
获取图片的地址如下代码:
pic_url = re.findall('img src="(.*?)" class="lessonimg"',html,re.S)第三步:新建一个Py文件,编码如下:
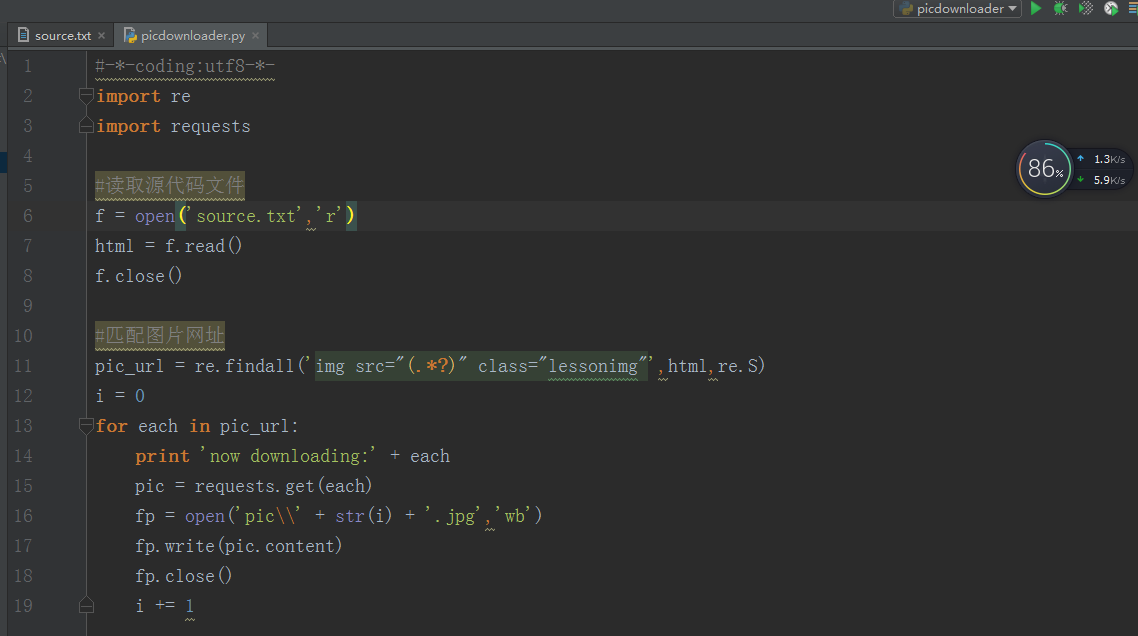
代码实现原理以及步骤:
1. 引入相关处理库(正则相关处理、请求库)
2. 读取源文件
3. 正则匹配图片网址
4. 循环遍历下载图片到本地
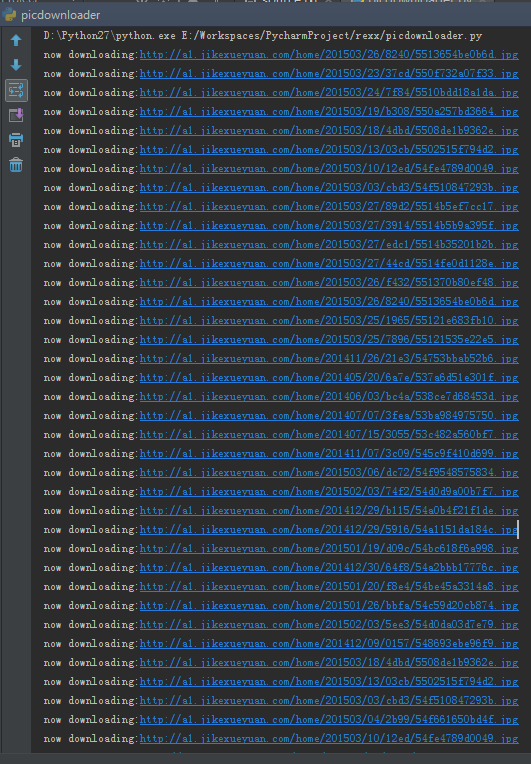
py脚本执行结果:
爬取到本地文件夹的图片:

ps:爬虫也不是一直会顺利的,有时候正则表达式没有写好也会出错,另外有的网站有设置反爬虫机制,这时候就需要在爬虫代码中加上 反-反爬虫机制啦。















 2008
2008

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









