










Transformer模型详解
2017 年,Google 在论文 《Attention is All you need》 中提出了 Transformer 模型,其使用 Self-Attention 结构取代了在 NLP 任务中常用的 RNN 网络结构。相比 RNN 网络结构,其最大的优点是可以并行计算。本文将从模型总体结构、自注意力机制(Self-Attention)详解、多头注意力机制这三部分来介绍Transformer的具体实现。
1
模型总体结构
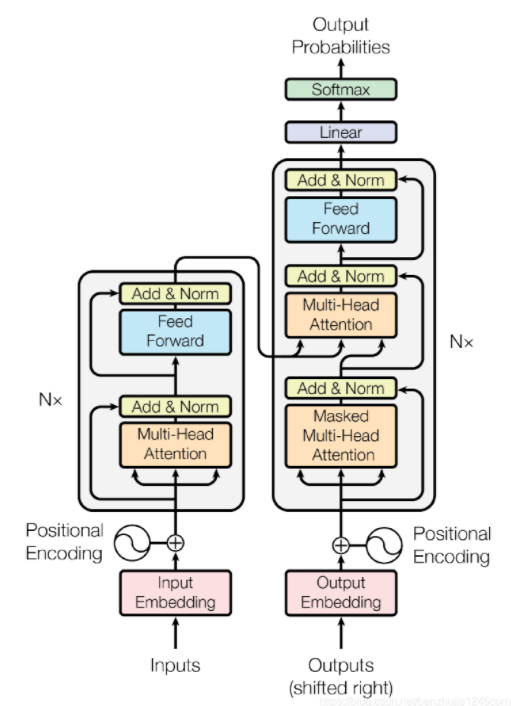
图一 Transformer 模型架构
1.1 编码器
图一的左边是编码器,将输入部分首先进行位置编码(Positional Encoding),表示序列中词顺序的方法,论文中有6层编码,每个编码器的结构都是相同的,但是它们使用不同的权重参数。每层由多头注意力机制(自注意力机制的完善)和全连接前馈网络组成。除此之外,每个编码器的每个子层(Self-Attention 层和 FFN 层)都有一个残差连接,再执行一个层标准化操作(图中的Add&Norm)。第一个编码器的输入是一个序列,最后一个编码器的输出是一组注意力向量 Key 和 Value。

图二 编码器内部结构
1.2 解码器
图一的右边是解码器,解码器的结构与编码器类似,但在Self-Attention层和FFN层之间多了 Encoder-Decoder Attention 层。编码器输出的向量Key、Value将在每个解码器的 Encoder-Decoder Attention 层被使用,这有助于解码器把注意力集中在输入序列的合适位置。Encoder-Decoder Attention 层的工作原理和多头自注意力机制类似。不同之处是:Encoder-Decoder Attention 层使用前一层的输出构造 Query 矩阵,而 Key 和 Value 矩阵来自于编码器栈的输出。Mask 表示掩码,它对某些值进行掩盖,使其在参数更新时不产生效果。

图三 解码器结构
1.3 全连接层与softmax
最后是一个线性层(全连接层Linear)和Softmax层,将解码器输出的向量在全连接层中映射到一个更长的向量,这个向量被称为 logits 向量。现在假设我们的模型有 10000 个英文单词(模型的输出词汇表)。因此 logits 向量有 10000 个数字,每个数表示一个单词的分数。然后,Softmax 层会把这些分数转换为概率(把所有的分数转换为正数,并且加起来等于 1)。最后选择最高概率所对应的单词,作为这个时间步的输出。
1.4 正则化操作
为了提高 Transformer 模型的性能,在训练过程中,使用了以下的正则化操作:
Dropout。对编码器和解码器的每个子层的输出使用 Dropout 操作,是在进行残差连接和层归一化之前。词嵌入向量和位置编码向量执行相加操作后,执行 Dropout 操作。Transformer 论文中提供的参数 P d r o p = 0.1 。
Label Smoothing(标签平滑)。Transformer 论文中提供的参数 ϵ l s = 0.1 。
2
自注意力机制
2.1 向量创建
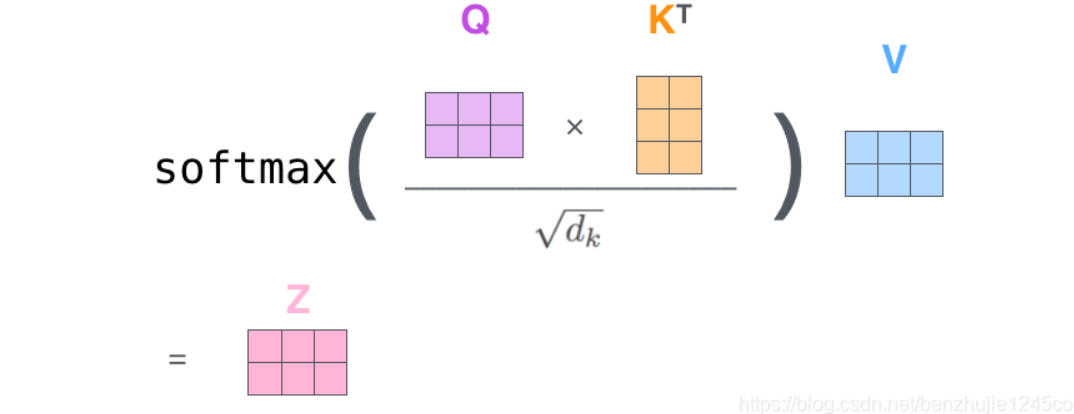
如图四所示,输入Thingking和Machines两个的单词,将其转化为词向量(512)(X1与X2),然后通过该词向量与三个权重矩阵向量(WQ,WK Wv)相乘创建得到三个向量(Query 向量、Key 向量和 Value 向量),图五为矩阵相乘形式。
在这里插入图片描述
图四

图五 矩阵形式
2.2 计算注意力分数
计算注意力分数,假设我们正在计算这个例子中第一个词 “Thinking” 的自注意力。我们需要根据 “Thinking” 这个词,对句子中的每个词都计算一个分数。这些分数决定了我们在编码 “Thinking” 这个词时,需要对句子中其他位置的每个词放置多少的注意力。这些分数,是通过计算 “Thinking” 的 Query 向量和需要评分的词(这里是Thingking和Machines)的Key向量点积得到的。如果我们计算句子中第一个位置词的注意力分数,则第一个分数是 q 1和 k 1的点积,第二个分数是 q 1和k2的点积。(如图六所示)
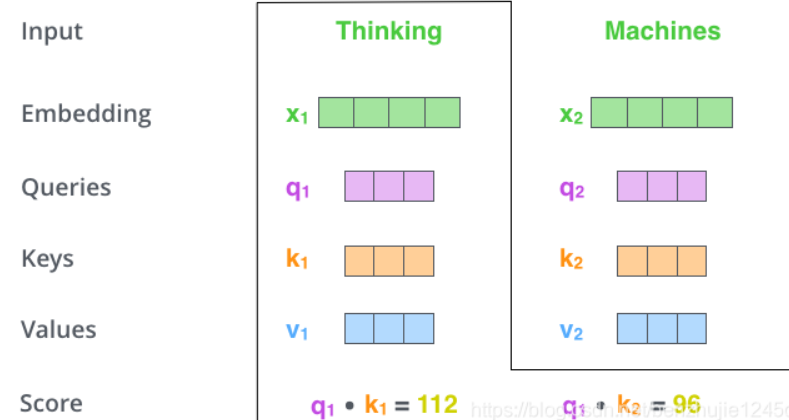
图六
2.3 注意力分配
将这些分数进行 Softmax 操作。Softmax 将分数进行归一化处理,使得它们都为正数并且和为 1。然后将每个 Softmax 分数分别与每个 Value 向量相乘。这种做法背后的直觉理解是:对于分数高的位置,相乘后的值就越大,我们把更多的注意力放在它们身上;对于分数低的位置,相乘后的值就越小,这些位置的词可能是相关性不大,我们就可以忽略这些位置的词。(如图七所示)最后将得到的向量进行加权求和,就得到了自注意力层的输出。整个过程如图八所示。
图七
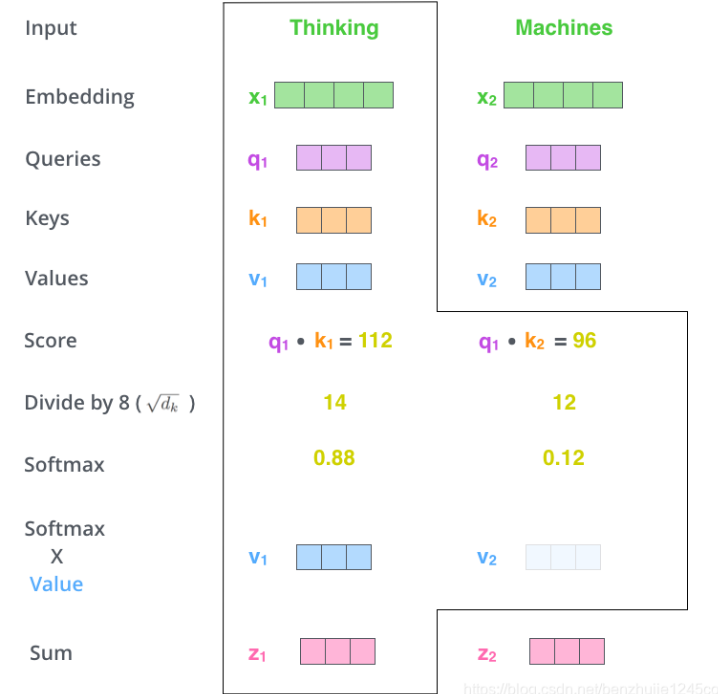
图八 自注意力机制流程示范图
3
多头注意力机制
在 Transformer 论文中,通过添加一种多头注意力机制,进一步完善了自注意力层。具体做法:首先,通过 h 个不同的线性变换对 Query、Key 和 Value 进行映射;然后,将不同的 Attention 拼接起来;最后,再进行一次线性变换。基本结构如图九所示。

图九 多头注意力机制基本结构
在多头注意力下,我们为每组注意力单独维护不同的 Query、Key 和 Value 权重矩阵,从而得到不同的 Query、Key 和 Value 矩阵。如下图所示。
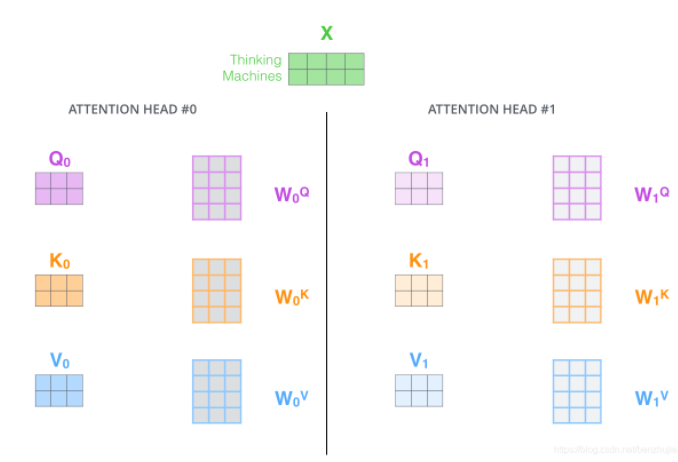
按照上面的方法,使用不同的权重矩阵进行 8 次自注意力计算,就可以得到 8 个不同的 Z 矩阵。由于输入前馈网络时,只允许一个矩阵进入,于是将得到的8个矩阵拼接后与权重矩阵W0相乘,最后得到输出矩阵Z。如下图所示。

那么到这里本次分享就结束了,感谢大家的观看,欢迎大家在下方评论区交流讨论,下次分享再会!
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。















 1175
1175

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









