









Transformer
一、RNN编码器-解码器架构****
********序列到序列模型(Seq2Seq):Seq2Seq模型的目标是将一个输入序列转换成另一个输出序列,这在多种应用中都具有广泛的实用价值,例如语言建模、机器翻译、对话生成等。
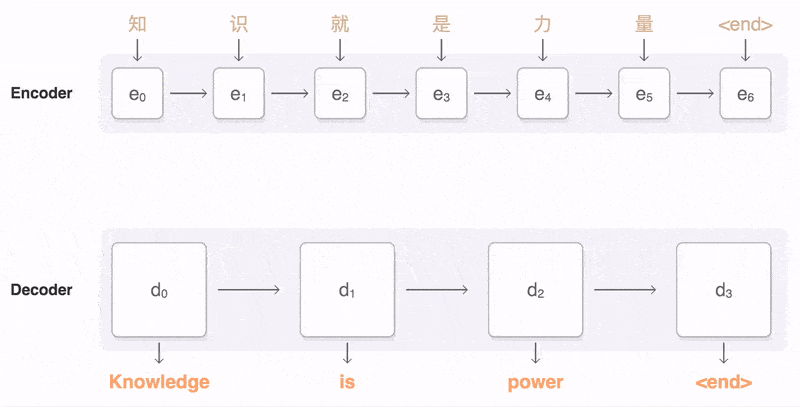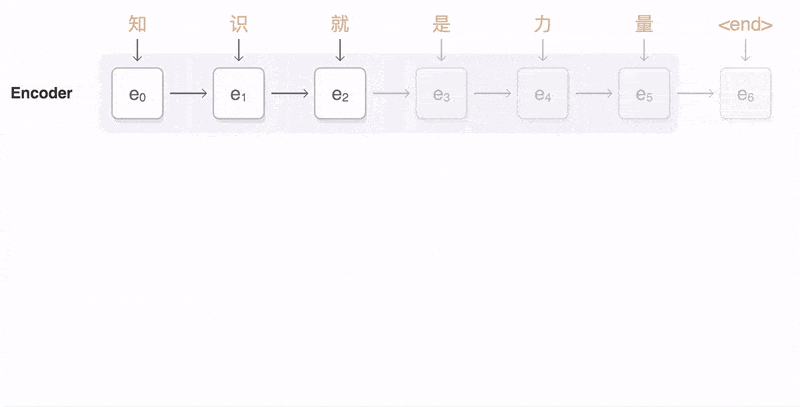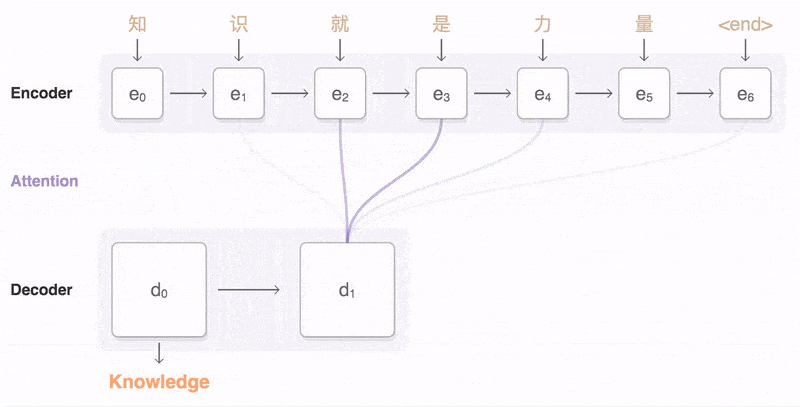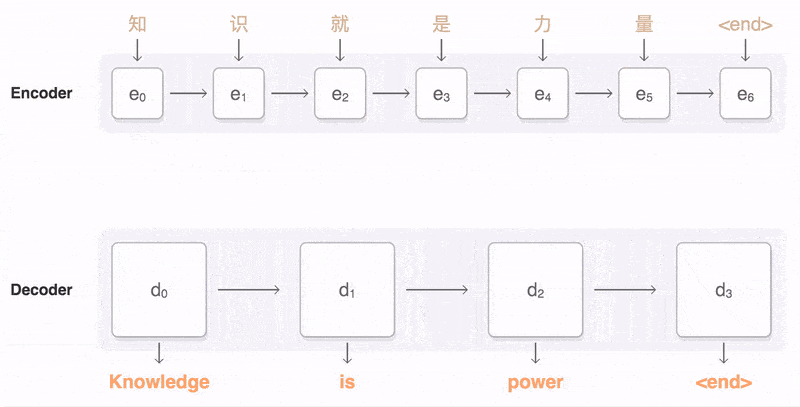
Seq2Seq
**RNN编码器-解码器架构:**Transformer出来之前,主流的序列转换模型都基于复杂的循环神经网络(RNN),包含编码器和解码器两部分。当时表现最好的模型还通过注意力机制将编码器和解码器连接起来。
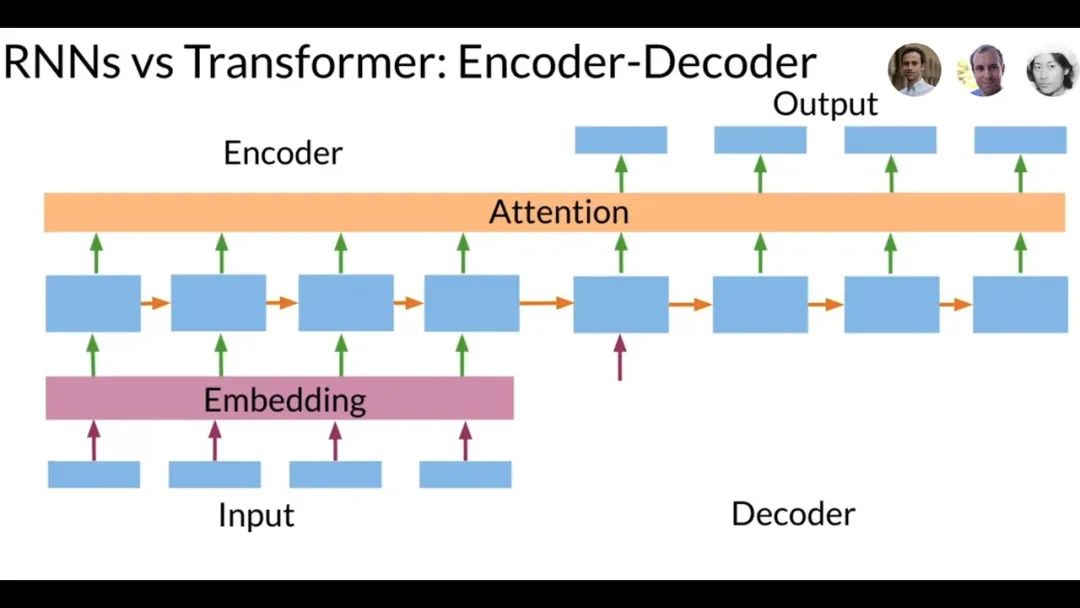
Transformer vs RNN
在Seq2Seq框架中,RNN的作用主要体现在两个方面:编码和解码。
****编码器:****RNN接收输入序列,并逐个处理序列中的元素(如单词、字符或时间步),同时更新其内部状态以捕获序列中的依赖关系和上下文信息。这种内部状态,通常被称为“隐藏状态”,能够存储并传递关于输入序列的重要信息。
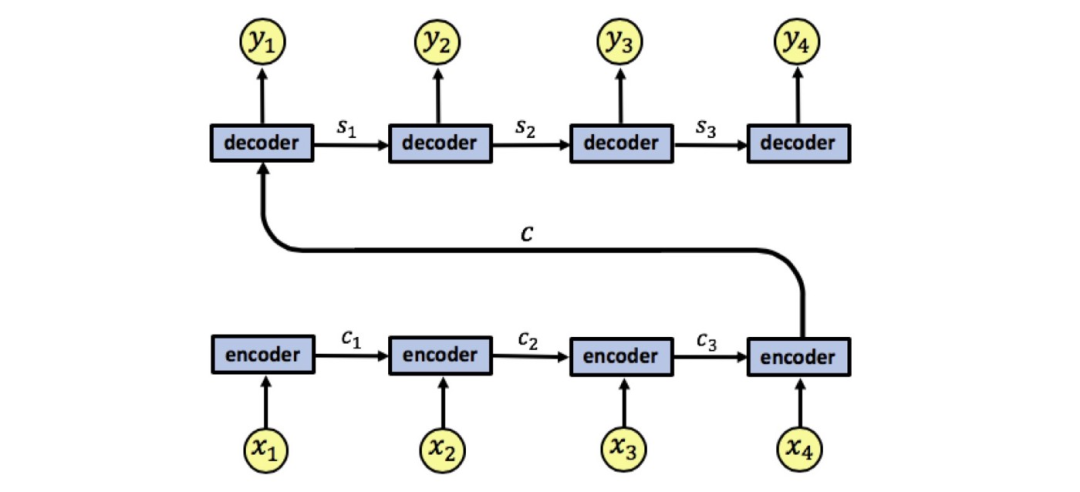
RNN编码器-解码器架构
解码器:RNN使用编码阶段生成的最终隐藏状态(或整个隐藏状态序列)作为初始条件,生成输出序列。在每一步中,解码器RNN都会根据当前状态、已生成的输出和可能的下一个元素候选来预测下一个元素。
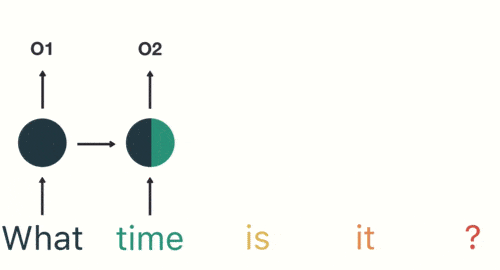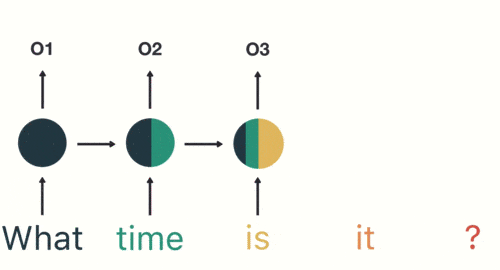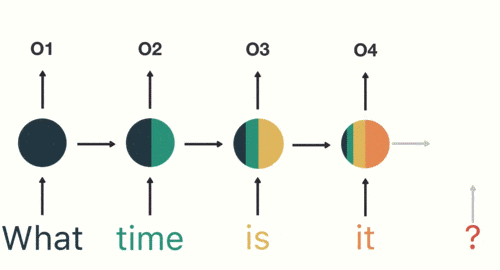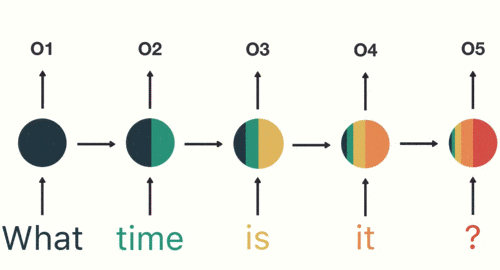
因此,循环神经网络(RNN)、特别是长短时记忆网络(LSTM)和门控循环单元网络(GRU),已经在序列建模和转换问题中牢固确立了其作为最先进方法的地位。
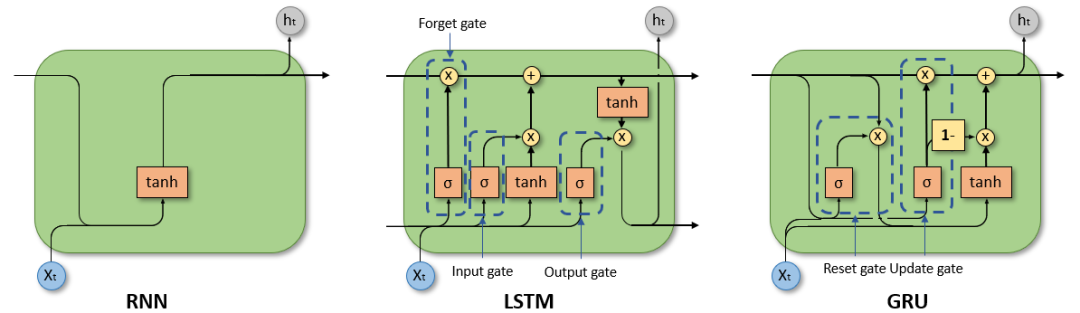
RNN LSTM GRU
同时,RNN存在一个显著的缺陷:处理长序列时,会存在信息丢失。
编码器在转化序列**x1, x2, x3, x4**为单个向量**c**时,信息会丢失。因为所有信息被压缩到这一个向量中,处理长序列时,信息必然会丢失。
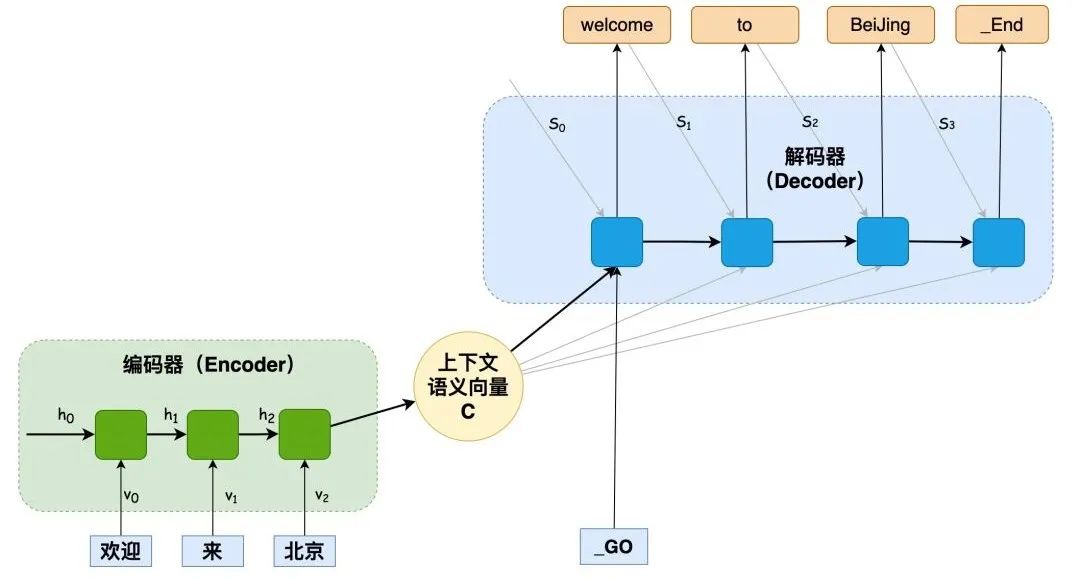
RNN编码器-解码器架构
二、Transformer总体架构_****_
**Transformer起源:******Google Brain 翻译团队通过论文《Attention is all you need》提出了一种全新的简单网络架构——****Transformer,它完全基于注意力机制,摒弃了循环和卷积操作。

注意力机制是全部所需
************注意力机制:************一种允许模型在处理信息时专注于关键部分,忽略不相关信息,从而提高处理效率和准确性的机制。它模仿了人类视觉处理信息时选择性关注的特点。

注意力机制
当人类的视觉机制识别一个场景时,通常不会全面扫描整个场景,而是根据兴趣或需求集中关注特定的部分,如在这张图中,我们首先会注意到动物的脸部,正如注意力图所示,颜色更深的区域通常是我们最先注意到的部分,从而初步判断这可能是一只狼。

注意力机制
**注意力计算Q、K、V:**注意力机制通过查询(Q)匹配键(K)计算注意力分数(向量点乘并调整),将分数转换为权重后加权值(V)矩阵,得到最终注意力向量。
注意力分数是量化注意力机制中信息被关注的程度,反映了信息在注意力机制中的重要性。
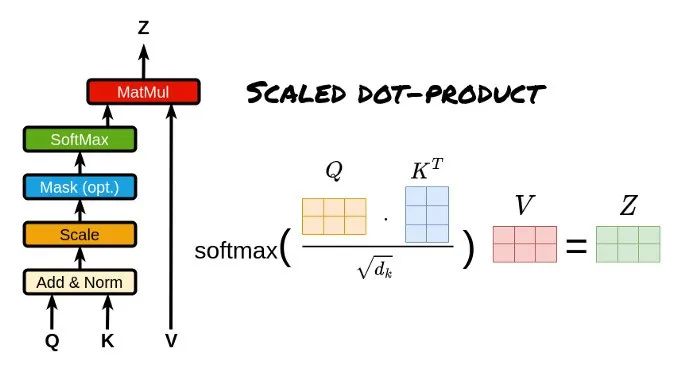
Q、K、V计算注意力分数
Transformer本质:****************Transformer是一种基于自注意力机制的深度学习模型,为了解决RNN无法处理长序列依赖问题****而设计的。****

Transformer vs RNN
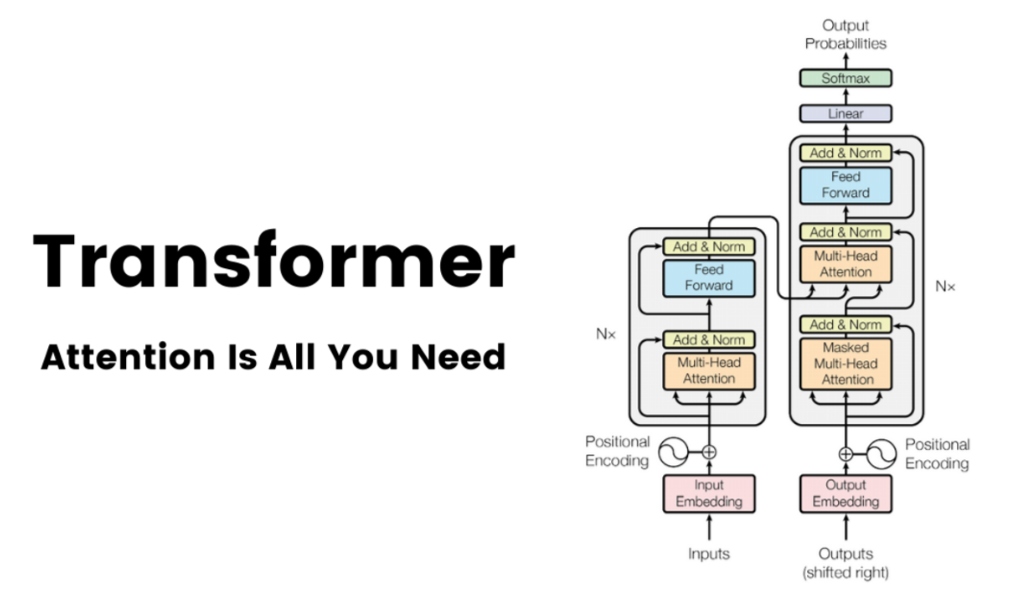
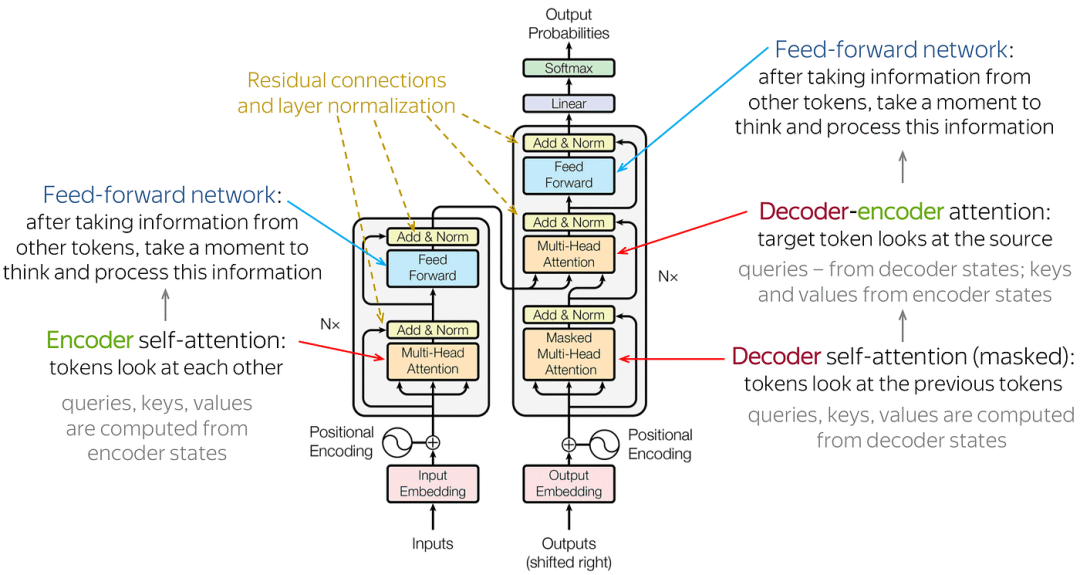
********Transformer总体架构:********Transformer也遵循编码器-解码器总体架构,使用堆叠的自注意力机制和逐位置的全连接层,分别用于编码器和解码器,如图中的左半部分和右半部分所示。
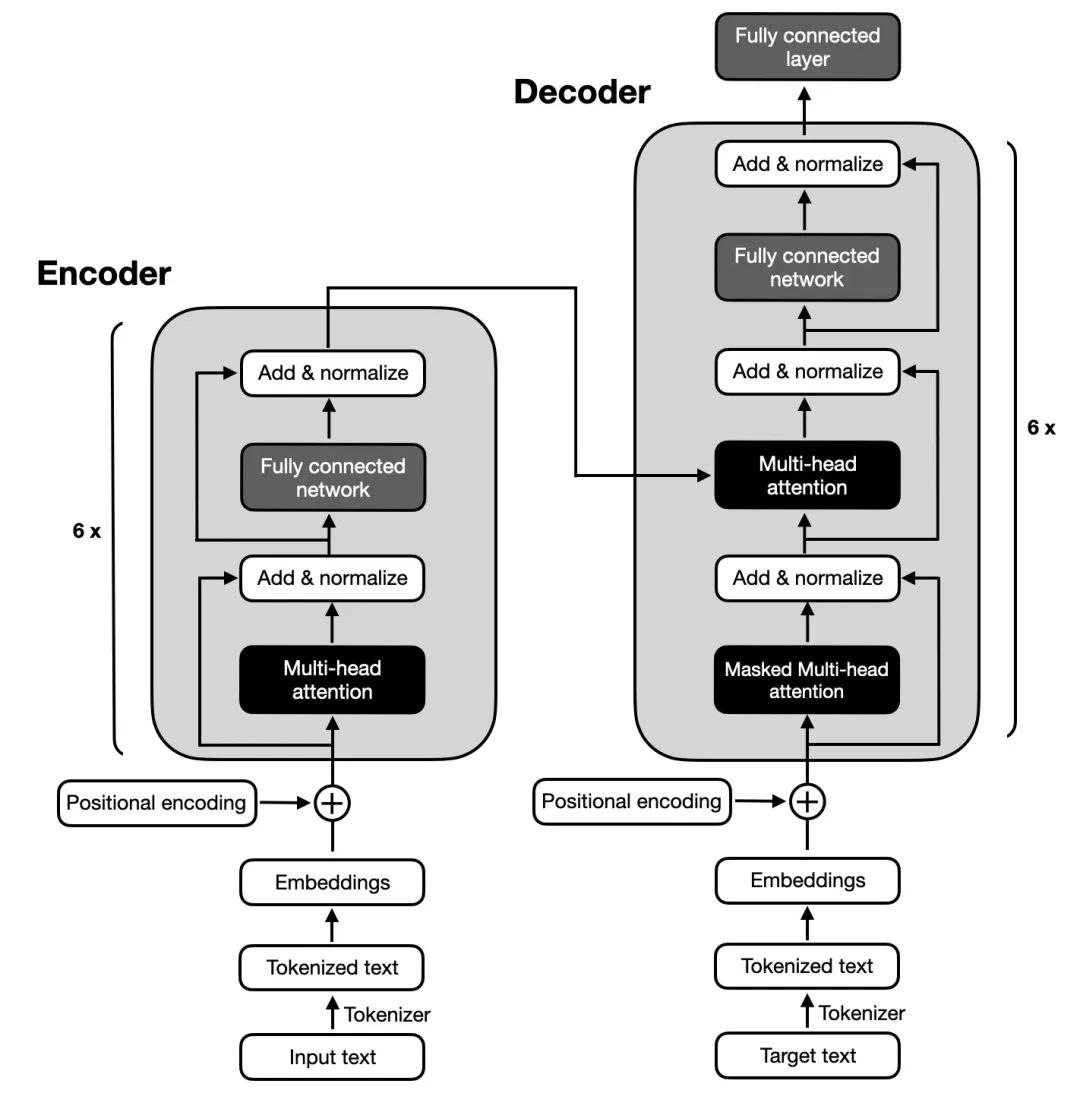
Transformer的架构
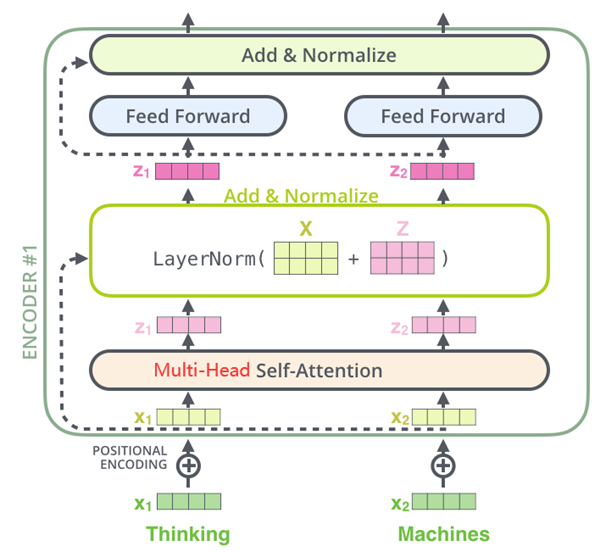
- **Encoder编码器:**Transformer的编码器由6个相同的层组成,每个层包括两个子层:一个多头自注意力层和一个逐位置的前馈神经网络。在每个子层之后,都会使用残差连接和层归一化操作,这些操作统称为Add&Normalize。这样的结构帮助编码器捕获输入序列中所有位置的依赖关系。
Encoder(编码器)架构
- **Decoder解码器:**Transformer的解码器由6个相同的层组成,每层包含三个子层:**掩蔽自注意力层、Encoder-Decoder注意力层和逐位置的前馈神经网络。**每个子层后都有残差连接和层归一化操作,简称Add&Normalize。这样的结构确保解码器在生成序列时,能够考虑到之前的输出,并避免未来信息的影响。
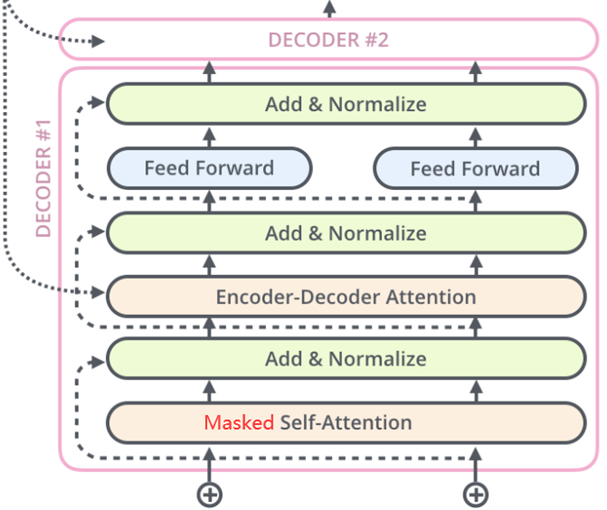
Decoder(解码器)架构
**************Transformer核心组件:******Transformer模型包含输入嵌入、位置编码、多头注意力、残差连接和层归一化、带掩码的多头注意力以及前馈网络等组件。
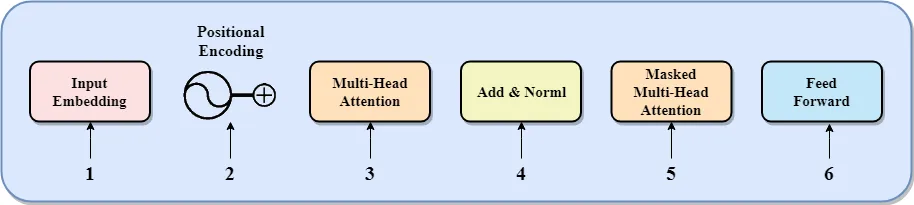
Transformer的核心组件
-
输入嵌入:将输入的文本转换为向量,便于模型处理。
-
位置编码:给输入向量添加位置信息,因为Transformer并行处理数据而不依赖顺序。
-
多头注意力:让模型同时关注输入序列的不同部分,捕获复杂的依赖关系。
-
残差连接与层归一化:通过添加跨层连接和标准化输出,帮助模型更好地训练,防止梯度问题。
-
带掩码的多头注意力:在生成文本时,确保模型只依赖已知的信息,而不是未来的内容。
-
前馈网络:对输入进行非线性变换,提取更高级别的特征。
Transformer的核心组件
****************Transformer数据流转:**********可以概括为四个阶段,Embedding(嵌入)、Attention(注意力机制)、MLPs(多层感知机)和Unembedding(从模型表示到最终输出)。
**
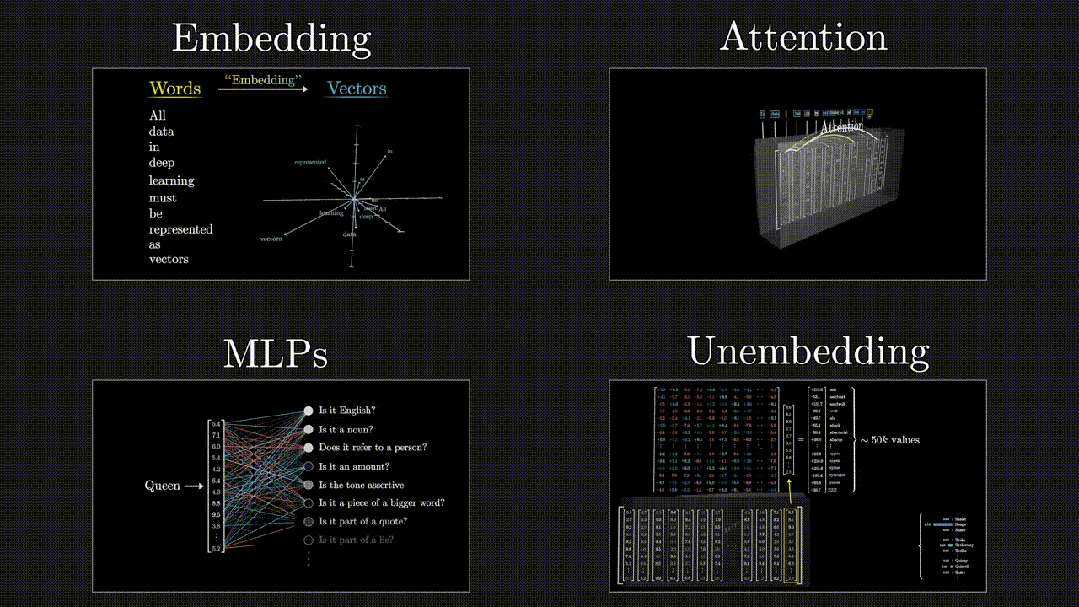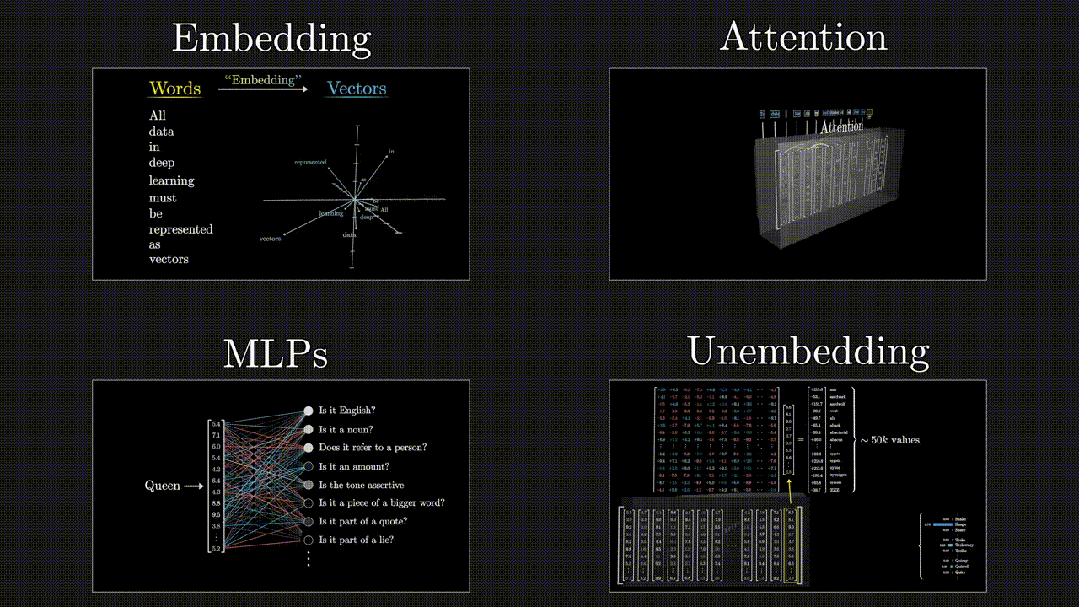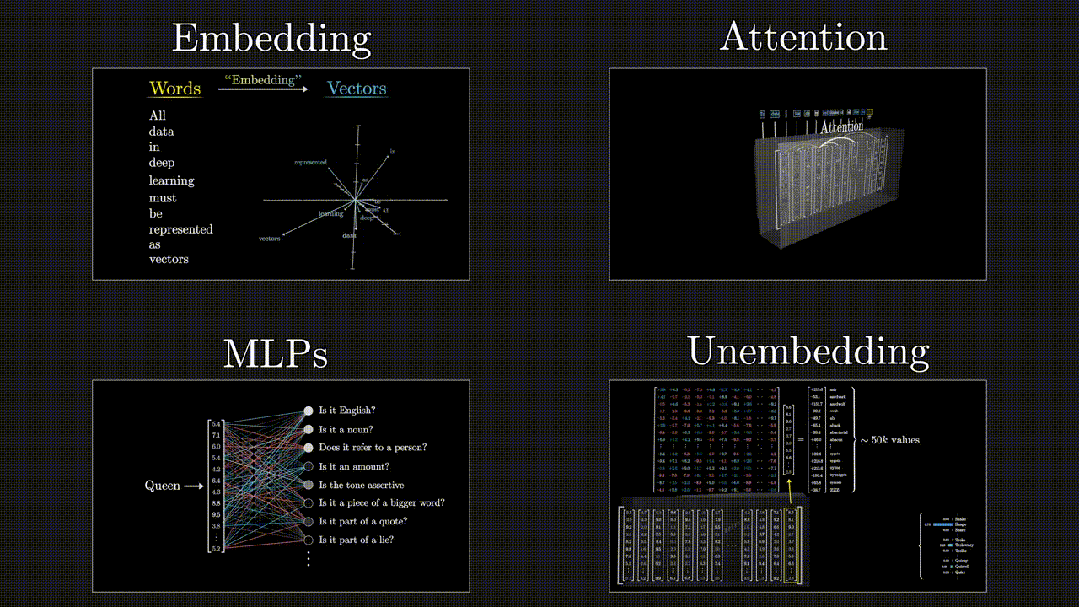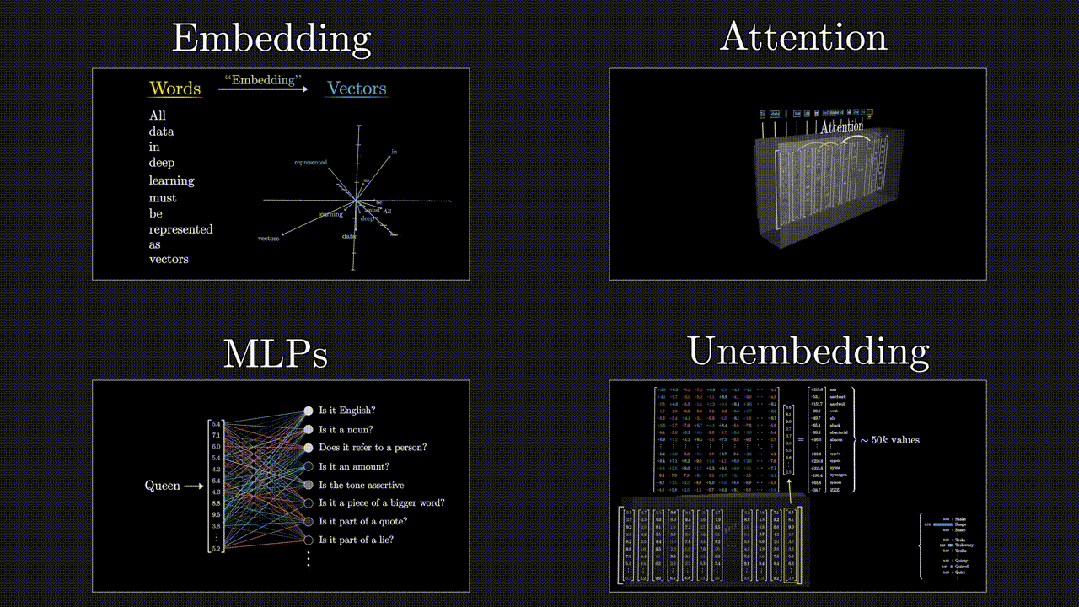
Embedding -> Attention -> MLPs -> Unembedding
**
************Transformer注意力层:************在Transformer架构中,有3种不同的注意力层(Self Attention自注意力、Cross Attention 交叉注意力、Causal Attention因果注意力)
-
****编码器中的自注意力层(Self Attention layer):****编码器输入序列通过Multi-Head Self Attention(多头自注意力)计算注意力权重。
-
****解码器中的交叉注意力层(Cross Attention layer):****编码器-解码器两个序列通过Multi-Head Cross Attention(多头交叉注意力)进行注意力转移。
-
****解码器中的因果自注意力层(Causal Attention layer):****解码器的单个序列通过Multi-Head Causal Self Attention(多头因果自注意力)进行注意力计算
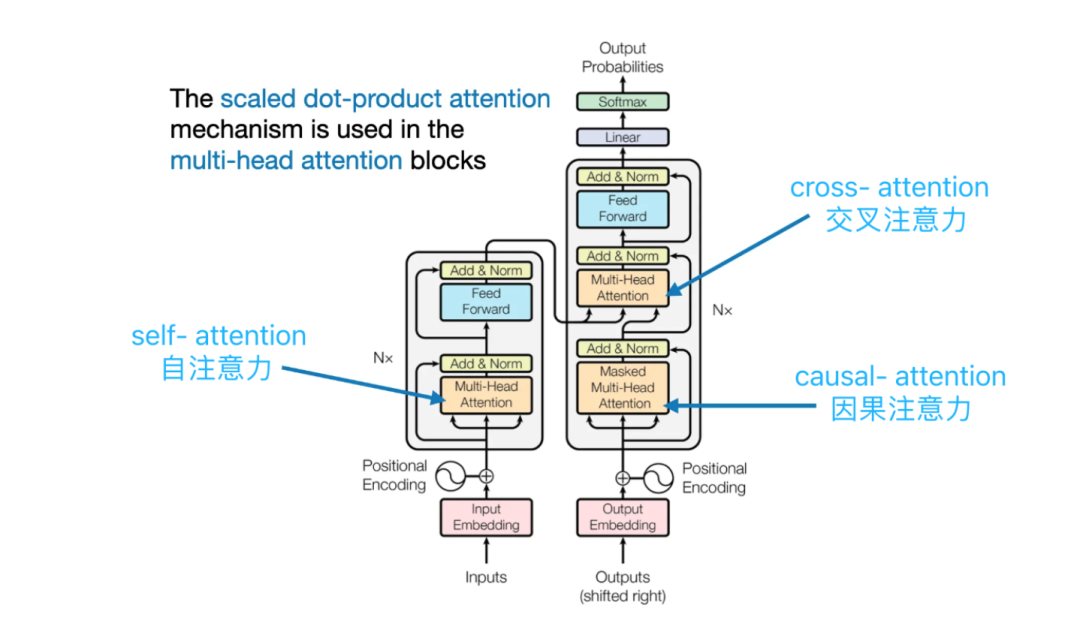
Transformer注意力层
**
神经网络算法 - 一文搞懂Transformer中的三种注意力机制
本文转自 https://mp.weixin.qq.com/s/DenAOo2flPF3S9NSB4qe-Q,如有侵权,请联系删除。
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。















 5771
5771

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









